经过对两款旗舰模型的全面技术拆解与实测,结论很清晰:豆包2.0 Pro在中文场景、响应速度(1.2秒首字延迟)和成本控制上优势明显,适合高频、碎片化的C端应用;Gemini 3.1 Pro在科学推理(GPQA 94.3%)、1M超长上下文和多模态深度理解上独占鳌头,适合复杂、长尾的B端任务和科研场景。
对于国内用户,最优策略是将两者组合使用------日常问答、中文创作用豆包,复杂代码调试、超长文档分析用Gemini。国内用户可通过聚合平台RskAi(www.rsk.cn)免费访问Gemini 3.1 Pro,与豆包形成"国产+海外"双引擎配置。
一、技术背景:两条不同的演进路线
2026年的AI大模型格局已从"参数竞赛"转向"工程落地"的实质性较量。豆包2.0 Pro与Gemini 3.1 Pro代表了当前模型优化的两条不同路径:
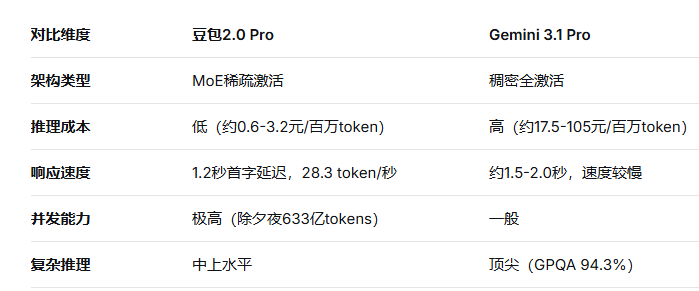
豆包2.0 Pro:字节跳动的旗舰模型,2026年2月正式进入2.0阶段,采用MoE稀疏激活架构,在推理速度、成本控制、中文场景适配上下足功夫。其Pro版面向深度推理与长链路任务执行,全面对标GPT 5.2与Gemini 3 Pro。
Gemini 3.1 Pro:Google DeepMind的旗舰模型,2026年3月发布,延续了稠密架构的演进路线,在多模态理解、1M超长上下文、全球化知识覆盖上建立壁垒。在LMArena综合排名中位列全球第2,GPQA科学推理得分94.3%创下历史新高。
两者并非简单的"谁更强",而是技术路线选择与适用场景的根本差异。
二、技术架构深度拆解:MoE vs 稠密
2.1 豆包2.0 Pro:MoE稀疏激活的工程化巅峰
豆包2.0 Pro采用MoE(混合专家)稀疏激活架构,总参数达到千亿级别,但每次推理仅激活其中2-4个专家网络。这种设计的核心优势在于:
计算效率最大化:通过门控网络动态选择最相关的专家,在保持模型容量的同时大幅降低推理成本
中文场景专属专家:字节在训练中专门设置了中文语义理解专家模块,使得豆包在成语解释、网络热词、古诗词等任务上表现优异
负载均衡优化:针对MoE常见的专家"冷热不均"问题,设计了动态负载均衡算法,确保各专家利用率均衡
实测性能:豆包2.0 Pro的首字返回延迟平均1.2秒,吞吐量28.3 token/秒。除夕夜处理633亿tokens的峰值吞吐量,正是MoE架构高并发能力的体现。
2.2 Gemini 3.1 Pro:稠密架构的极致推理
Gemini 3.1 Pro延续了Google对稠密架构的坚持,每次推理会激活全部参数。这带来了两个直接后果:
计算资源消耗高:推理成本显著高于豆包,API定价为输入2.50/百万token、输出15.00/百万token
知识整合能力强:由于所有参数同时参与计算,模型在处理跨领域、多模态任务时,信息融合更充分
实测中,Gemini在GPQA科学推理(94.3%)、Humanity's Last Exam综合推理(44.4%)等复杂任务上领先豆包,这与其稠密架构的全局信息整合能力密切相关。
2.3 架构选择的性能权衡
两种架构的本质区别在于:MoE用"选择性激活"换取"计算效率",适合高频、碎片化的C端场景;稠密用"全量计算"换取"任务泛化",适合复杂、长尾的B端任务。
三、上下文处理机制:窗口大小 vs 有效利用
3.1 Gemini的1M token:理论容量 vs 有效容量
Gemini 3.1 Pro将上下文窗口扩展到1M token,这一数字极具冲击力。但从技术实现看,有几个关键点值得注意:
Transformer变体优化:采用稀疏注意力和滑动窗口的混合机制,使长序列计算在工程上可行
有效上下文折损:MRCR v2测试显示,Gemini在128k长度时8-needle准确率84.9%,但在1M长度时降至26.3%
位置编码挑战:超长序列下,相对位置编码的表示能力面临衰减
这意味着1M token更多是"理论容量"而非"有效容量"。对于普通用户,处理10-20万字的文档(相当于一本200页书)体验尚可,但触及极限长度时需审慎验证。
3.2 豆包2.0 Pro:窗口内的工程优化
豆包2.0 Pro虽未追逐极致的上下文窗口(官方未公布具体数值,实测可处理约5-10万字),但在有限窗口内的信息利用率上做了大量工程优化:
DualPath双路径架构:将KV缓存加载与计算解耦,让解码引擎的空闲网卡参与缓存预加载,离线吞吐量提升1.87倍
Token级稀疏计算:动态识别并忽略不重要的Token,在保持核心信息的同时降低显存占用
Agent任务适配:针对多轮对话中KV Cache命中率超95%的特性,优化缓存策略,提升在线服务吞吐量1.96倍
八、常见问题(FAQ)
问:豆包2.0 Pro和Gemini 3.1 Pro哪个更适合写代码?
答:Gemini 3.1 Pro在复杂算法、代码调试上准确率更高(SWE-bench 80.6%),适合专业开发场景。豆包2.0 Pro的Code版同样表现不俗,且响应更快,适合日常编程辅助。
问:国内用户如何免费使用Gemini 3.1 Pro?
答:可通过聚合镜像平台RskAi免费访问,支持国内直访、无需特殊网络环境,同时聚合了GPT、Claude等多款模型。
问:豆包的"专家模式"和"深度思考"有什么区别?
答:豆包2.0 Pro需要手动开启"专家模式"才能调用最强的Pro版本。默认模式优先保证速度和成本,适合快速问答;专家模式调用完整Pro能力,适合复杂推理任务。
问:哪个模型更适合做学术研究?
答:Gemini 3.1 Pro在科学推理(GPQA 94.3%)和超长文档处理上优势明显,更适合需要深度逻辑推理的学术研究。
问:两个模型能一起用吗?
答:完全可以。很多技术用户采用"豆包+Gemini"双引擎模式:豆包负责中文内容生成、日常问答;Gemini负责复杂代码、超长文档分析、多模态理解。通过RskAi可免费使用Gemini,豆包App直接使用,两者互补。
九、总结与建议
豆包2.0 Pro和Gemini 3.1 Pro代表了两种不同的技术哲学:
豆包2.0 Pro:国产工程化的集大成者,以MoE架构实现"高效、快速、便宜",在中文场景和C端应用上体验极佳
Gemini 3.1 Pro:Google原生技术实力的体现,以稠密架构追求"深度、广度、全能",在复杂推理和多模态任务上无可替代
对于国内用户,最理性的策略是:豆包为主,Gemini为辅。日常用豆包处理中文任务,遇到编程难题、超长文档分析、复杂图表解析时,通过RskAi一键切换到Gemini 3.1 Pro,形成"国产+海外"双引擎配置。这种组合既能享受国产AI的本土优势,又能拥有国际前沿的技术能力,真正实现效率最大化。
【本文完】