写在前面
平均负载是一个可以大致反应系统压力的一个很重要的指标,所以,我们可以将其作为一个重要的参考指标,来加入到日常的监控中。当发现其有异常时,可以再进一步定位到底是哪里出现了问题。
本文就一起来看下平均负载相关的内容。
1:基础内容介绍
1.1:如何看平均负载
通过top命令或者是uptime都可以,以uptime为例:
dongyunqi@dongyunqi:~$ uptime
09:21:54 up 22:32, 7 users, load average: 0.00, 0.01, 0.0009:21:54 up 22:32, 7 users的含义是当前时间,系统运行时间,系统登陆用户数。
load average: 0.00, 0.01, 0.00就是平均负载信息,分别表示最近一分钟,五分钟,十五分钟的平均负载情况。可以从这个三个值的的变化来推断系统的压力变化:
1:如果三个值都比较高,说明系统最近压力都比较大
2:如果最近一分钟高,但是最近五分钟,十五分钟低,说明系统最近压力比较大,可能是临时的
3:如果是最近一分钟低,最近五分钟,十五分钟高,则说明系统压力在减小所以从不同的值可以推断出不同的系统压力变化情况。
1.2:什么是平均负载?
平均负载是处于活跃状态的进程数,这里活跃状态进程包含如下:
1:正在运行状态的进程
会消耗CPU资源
2:等待运行状态的进程
无空闲的CPU资源,不会消耗CPU资源
3:处于不可打断状态的进程
如正在进行IO操作的进程,如果打断可能造成进程和磁盘数据不一致,不会消耗CPU资源所以平均负载就是对于处于以上状态的进程数量的描述。可参考下图:
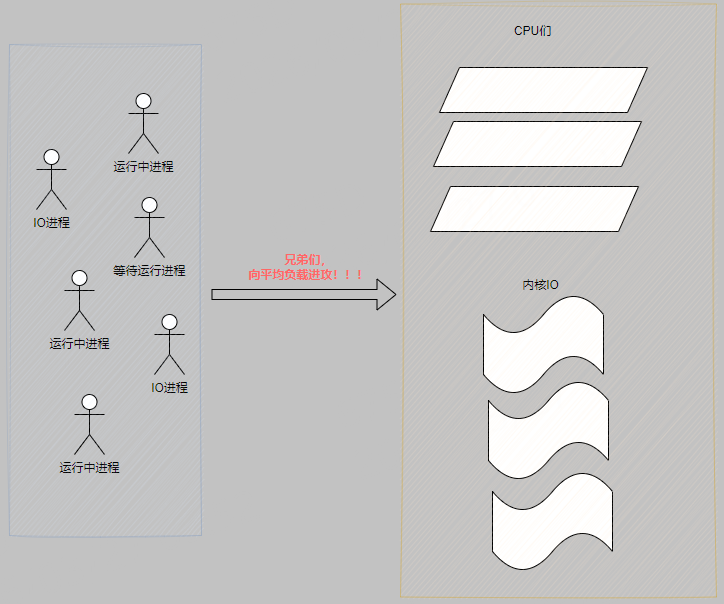
其实,我们也可以看出来,平均负载和CPU利用率是不能划的等号的。如2,3会会造成平均负载升高,但是对CPU利用率影响却很小。
接下来我们通过场景演练,来分别验证下真实性。
2:测试场景演练
这里我们需要用到stress和sysstat包,预先安装apt install stress sysstat(我的测试环境是Ubuntu系统,其他系统使用对应安装命令即可,工具是通用的)。
2.1:验证正在运行状态的进程(CPU密集型进程)
模拟正在运行的状态,一个CPU利用率到达百分之百:
root@dongyunqi:/home/dongyunqi/study# stress --cpu 1 --timeout 600
stress: info: [107449] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd运行后一段时间执行watch -d uptime:
Every 2.0s: uptime dongyunqi: Fri Mar 27 10:25:38 2026
10:25:38 up 23:36, 7 users, load average: 0.88, 0.35, 0.13
Every 2.0s: uptime dongyunqi: Fri Mar 27 10:25:40 2026
10:26:02 up 23:37, 7 users, load average: 0.91, 0.39, 0.15
Every 2.0s: uptime dongyunqi: Fri Mar 27 10:27:04 2026
10:27:04 up 23:38, 7 users, load average: 1.01, 0.53, 0.22可以看到负载在不断的变大了。 此时来看下CPU的利用率:
dongyunqi@dongyunqi:~$ mpstat -P ALL 5
Linux 6.8.0-106-generic (dongyunqi) 03/27/2026 _x86_64_ (1 CPU)
10:28:20 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10:28:25 AM all 99.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:28:25 AM 0 99.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00
^C
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 99.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 0 99.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00ALL表示监控所有的CPU,5表示5秒钟输出一组数据。
%usr列可以看到CPU利用率接近百分之百了。那么到底是哪个进程到底CPU这么高呢:
dongyunqi@dongyunqi:~$ pidstat -u 5 1 # 间隔5秒,输出一组数组
Linux 6.8.0-106-generic (dongyunqi) 03/27/2026 _x86_64_ (1 CPU)
10:30:53 AM UID PID %usr %system %guest %wait %CPU CPU Command
10:30:59 AM 0 104131 0.00 0.19 0.00 0.00 0.19 0 kworker/u256:0-events_power_efficient
10:30:59 AM 0 107417 0.00 0.19 0.00 0.00 0.19 0 kworker/0:0-events
10:30:59 AM 0 107450 96.32 0.00 0.00 1.16 96.32 0 stress
10:30:59 AM 1000 107455 0.19 0.00 0.00 0.19 0.19 0 watch
10:30:59 AM 1000 107966 0.00 0.19 0.00 0.39 0.19 0 pidstat
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 104131 0.00 0.19 0.00 0.00 0.19 - kworker/u256:0-events_power_efficient
Average: 0 107417 0.00 0.19 0.00 0.00 0.19 - kworker/0:0-events
Average: 0 107450 96.32 0.00 0.00 1.16 96.32 - stress
Average: 1000 107455 0.19 0.00 0.00 0.19 0.19 - watch
Average: 1000 107966 0.00 0.19 0.00 0.39 0.19 - pidstat可以看到是stress进程。
2.2:验证不可打断状态的进程(IO密集型进程)
执行命令模拟高IO操作:
root@dongyunqi:/home/dongyunqi/study# stress -i 1 --hdd 1 --timeout 600
stress: info: [108603] dispatching hogs: 0 cpu, 1 io, 0 vm, 1 hddwatch -d uptime一下:
Every 2.0s: uptime dongyunqi: Fri Mar 27 10:39:14 2026
10:39:14 up 23:50, 7 users, load average: 1.50, 0.68, 0.48看下CPU和IO wait:
dongyunqi@dongyunqi:~$ mpstat -P ALL 5 3
Linux 6.8.0-106-generic (dongyunqi) 03/27/2026 _x86_64_ (1 CPU)
10:40:49 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10:40:54 AM all 0.00 0.00 5.15 94.42 0.00 0.43 0.00 0.00 0.00 0.00
10:40:54 AM 0 0.00 0.00 5.15 94.42 0.00 0.43 0.00 0.00 0.00 0.00
10:40:54 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10:40:59 AM all 0.22 0.00 29.35 70.22 0.00 0.22 0.00 0.00 0.00 0.00
10:40:59 AM 0 0.22 0.00 29.35 70.22 0.00 0.22 0.00 0.00 0.00 0.00
...可以看到iowait很高,CPU不高。也进一步验证了CPU和平均负载不等价的正确性。
看下是哪个进程导致的IO高:
# 间隔5秒后输出一组数据,-u表示CPU指标
$ pidstat -u 5 1
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:42:08 UID PID %usr %system %guest %wait %CPU CPU Command
13:42:13 0 104 0.00 3.39 0.00 0.00 3.39 1 kworker/1:1H
13:42:13 0 109 0.00 0.40 0.00 0.00 0.40 0 kworker/0:1H
13:42:13 0 2997 2.00 35.53 0.00 3.99 37.52 1 stress
13:42:13 0 3057 0.00 0.40 0.00 0.00 0.40 0 pidstat可以看到是stress进程。
2.3:验证等待运行状态的进程(IO密集型进程,但大于CPU数,即大量进程的场景)
模拟4个进程场景:
root@dongyunqi:/home/dongyunqi/study# stress -c 4 --timeout 600
stress: info: [109931] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hddwatch -d uptime查看平均负载:
Every 2.0s: uptime dongyunqi: Fri Mar 27 11:29:15 2026
11:29:15 up 1 day, 40 min, 7 users, load average: 3.69, 1.92, 1.84
...看下CPU争抢情况:
dongyunqi@dongyunqi:~$ pidstat -u 5 1
Linux 6.8.0-106-generic (dongyunqi) 03/27/2026 _x86_64_ (1 CPU)
11:34:13 AM UID PID %usr %system %guest %wait %CPU CPU Command
11:34:19 AM 1000 3169 0.00 0.19 0.00 0.00 0.19 0 sshd
11:34:19 AM 0 108685 0.00 0.37 0.00 0.19 0.37 0 kworker/0:3-events
11:34:19 AM 0 109932 23.19 0.00 0.00 71.24 23.19 0 stress
11:34:19 AM 0 109933 23.19 0.00 0.00 71.24 23.19 0 stress
11:34:19 AM 0 109934 23.38 0.00 0.00 71.61 23.38 0 stress
11:34:19 AM 0 109935 23.01 0.00 0.00 70.32 23.01 0 stress
11:34:19 AM 1000 110479 0.19 0.19 0.00 0.37 0.37 0 pidstat
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 1000 3169 0.00 0.19 0.00 0.00 0.19 - sshd
Average: 0 108685 0.00 0.37 0.00 0.19 0.37 - kworker/0:3-events
Average: 0 109932 23.19 0.00 0.00 71.24 23.19 - stress
Average: 0 109933 23.19 0.00 0.00 71.24 23.19 - stress
Average: 0 109934 23.38 0.00 0.00 71.61 23.38 - stress
Average: 0 109935 23.01 0.00 0.00 70.32 23.01 - stress
Average: 1000 110479 0.19 0.19 0.00 0.37 0.37 - pidstat可以看到4个stress进程争抢一个CPU,%wait的值也很高,在70%+。