论文:
Qwen: https://arxiv.org/abs/2309.16609
Qwen-vl: https://arxiv.org/pdf/2308.12966
qwen2: https://arxiv.org/pdf/2407.10671
qwen2-vl: https://arxiv.org/pdf/2409.12191
Qwen2.5:https://arxiv.org/abs/2412.15115
qwen2.5-vl: https://arxiv.org/pdf/2502.13923
qwen3: https://arxiv.org/pdf/2505.09388
qwen3-vl: https://arxiv.org/pdf/2511.21631
代码 :https://github.com/QwenLM/Qwen2-VL
1、为什么要做这个研究(理论走向和目前缺陷) ?
qwen系列的持续迭代。
2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
模型架构几乎未改动,主要是数据和后训练技巧上有些优化。预训练数据由qwen2的7万亿增加到18万亿,训练技巧上,先训短数据,再训长数据,以对长上下文更好的支持。
3、发现了什么(总结结果,补充和理论的关系)?
qwen2.5相对qwen2模型优化不大,性能能分别对标GPT-4o-mini和GPT-4o。
摘要
qwen2.5相对qwen2在预训练后后训练阶段有较大优化。在预训练阶段数据规模从qwen2的7万亿token增加到18万亿。后训练阶段,实现了sft之后进行离线DPO强化学习和在线GRPO强化学习(从deepseek学来的)。
预训练数据规模变化如图:
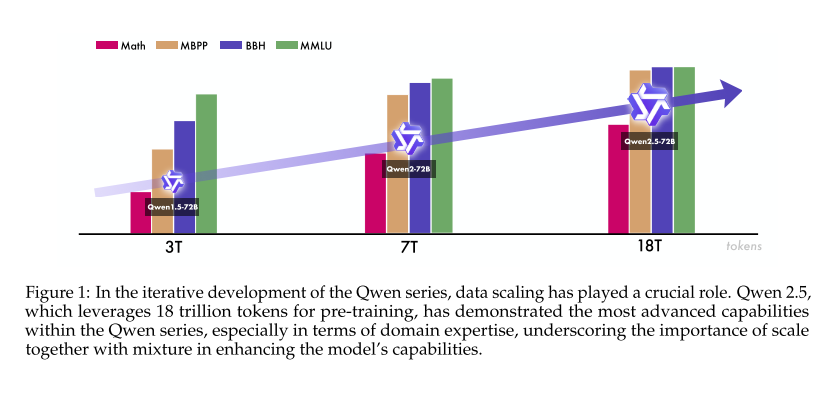
1 引言
全参数模型参数规模(0.5B, 1.5B, 3B, 7B,14B, 32B, and 72B)。此外还有MoE模型(命名为Qwen2.5-Turbo和Qwen2.5-Plus,只提供API服务),性能分别对标GPT-4o-mini和GPT-4o。
主要贡献:
模型参数范围 :除了qwen2的0.5B, 1.5B, 7B, and 72B外,增加了3B, 14B和32B。
数据 :预训练数据从7万亿token->18万亿token。
更长上下文推理:2K token->8k token。私有模型Qwen2.5-Turbo支持1m token的上下文推理。
2 架构 & 分词器
架构同qwen2, 也使用了组查询注意力(GQA,即多个query对应同一个key和value)。沿用了qwen1.5 MoE中的共享专家和专用专家的设计2 架构 & 分词器(后续在qwen3中去掉了共享专家,只保留专用专家)。分词器沿用的了qwen的词汇表和分词器(BPE),但是在词汇表中增加了一些专有token,原来只有3个专有token,现在增加到22个。
3 预训练
3.1 预训练数据
过滤低质量数据,增加数学和代码数据到预训练数据里,利用大模型合成高质量数据,不同领域的数据均衡。
3.2 超参数的缩放规律研究
即确定不同参数量、不同结构(MoE或全参数)、不同预训练数据量的模型该在训练时使用多大的batch size和学习率。没有细说
3.3 长上下文预训练
预训练的初始阶段限制最长上下文使用4096token,预训练的最后阶段拓展到32,768,以提升训练效率和长上下文效果。
4 后训练
和qwen2后训练相比有两大不同。1)sft数据规模更大。2)RL分成了两个阶段,离线RL即DPO,和在线RL,即GRPO。
4.1 监督微调SFT
制作SFT数据时有如下关键增强
1)qwen2.5可以最大生成8192个token,而一般的只能生成2000个token。2)引入链式思考数据,增强逻辑推理能力。3)增加新的github上的问答数据。4)用LLM生成指令跟随数据,并添加一些验证机制保证数据质量,添加到SFT数据中。5)结构化数据理解。6)逻辑推理,7)多语言能力,用一个翻译模型把一种常用语言数据翻译成多种不常用语言数据来训练。8)通过丰富各种各样的系统指令,提升系统指令的重要性。9)用一个专家模型给回复打分,确保制作sft数据时回复的高质量。
最终生成了超过100万条SFT数据。
4.2 离线强化学习
离线强化学习(DPO)需要提前准备训练数据,比较适合那些有标准答案但是很难用奖励模型评估回答好坏的任务。共计准备了15w的训练数据对。
4.3 在线强化学习
需要训练一个奖励模型,训练奖励模型的数据来源有两个:开源数据和私有数据。
4.4 长上下文微调
后训练SFT阶段用的用例主要是长上下文的,且也是分两阶段训练的,第一阶段主要是短数据,第二阶段是长短数据混合的,主要是为了保证对于简单任务回答高效,而对难的任务回答详细。
后训练强化学习时用的数据都是短数据,主要是因为用长数据很耗资源且奖励模型在长句评判上表现也不太好。
5 评估
预训练和后训练模型都进行了评估,且需要用n-gram算法保证评估集中不能有和训练集中相似的数据。
5.1 基础模型(预训练模型)
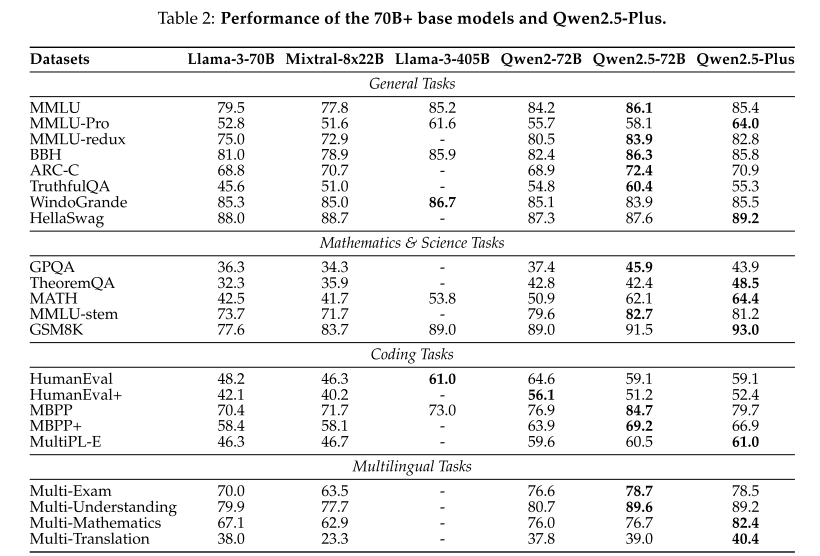
5.2 指令微调模型
5.2.1 公开Benchmark评估
5.2.2 私有数据评估
5.2.3 奖励模型
当前对奖励模型的评估仍没有有效的方法,大多还是用Reward Bench来评估,但在这个bench上指标高并不代表奖励模型一定好,也可能过拟合。
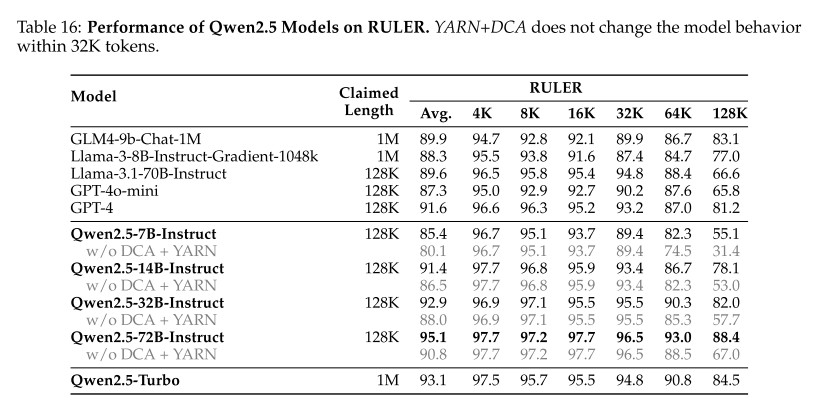
5.2.4 长上下文能力
可以看出即使用了YARN和DCA等方法,但当输入想下文长度过长时,性能仍会大幅下降。
6 结论
Qwen2.5模型架构上几乎没改动,但是预训练数据规模由7万亿增加到18万亿,后训练上增加了一些技巧,SFT+offline RL(DPO) + online RL(GRPO),先短数据训,再长数据训等。