论文链接:https://www.mdpi.com/2076-3417/16/5/2495
ResearchGate 页面 (可关注作者动态): Wenxuan Dong's Research
github:https://github.com/487697136/AMSRAG/tree/main

本文针对异构查询场景 下传统 RAG 固定流水线无法兼顾效率与证据覆盖的问题,提出AMSRAG 框架 ,以查询复杂度 + 置信度双信号为核心,实现检索路径动态调度与多源证据自适应融合,在开放域问答任务上实现效果与效率的平衡。
目录
[1.1. RAG 的价值与局限](#1.1. RAG 的价值与局限)
[2.1 查询复杂度建模与置信度估计](#2.1 查询复杂度建模与置信度估计)
[2.3.置信度感知 RRF(CA-RRF)](#2.3.置信度感知 RRF(CA-RRF))
[3.1 数据准备](#3.1 数据准备)
摘要(Abstract)
| 项目 | 内容 |
|---|---|
| 问题 | 传统 RAG 使用固定检索生成流程,面对不同复杂度和不同证据需求的查询时,难以平衡答案质量与检索效率。 |
| 方案 | 提出 AMSRAG (自适应多源 RAG)框架,融合 查询复杂度感知 与 置信度感知。 |
| 核心能力 | 1. 利用预训练模型对查询复杂度进行分类,结合置信度校准,指导检索路径动态调度与融合权重调整。 2. 实现 分层路径选择 + 跨源加权,可控平衡答案质量与检索效率。 |
| 实验结果 | - 复杂度分类器:准确率 85.9%,Macro-F1 85.4%,置信度校准后 ECE 仅 1.9%。- 相比固定流水线 RAG,答案准确率与检索相关性显著提升。- 高置信度的简单查询减少冗余检索,低置信度复杂查询提升证据覆盖。 |
| 贡献 | 为异构查询下的 RAG 提供 自适应能力与资源效率优化的新方法。 |
1.引言(Introduction)
1.1. RAG 的价值与局限
- 价值:缓解大模型知识过时、幻觉问题,支持跨文档推理(代表:FiD、RETRO、GraphRAG、DPR)。
- 局限 :固定流水线,对简单 / 复杂查询用同一策略,要么浪费资源,要么证据不足。
1.2.现有研究的不足
- 查询复杂度与自适应路由
- 从规则特征走向语义建模(Self-RAG、Adaptive-RAG),但仅单阶段切换;
- 缺乏复杂度建模→置信度校准→端到端调度的完整框架;
- 模型预测置信度未校准,分布偏移时路由不稳定。
- 多源信息与置信度融合
- 传统融合(RRF、线性加权)是静态权重,未结合查询复杂度;
- 置信度校准仅用于单源修正,未实现复杂度 + 置信度联合动态融合。
本文核心解决 3 个问题
- 如何将复杂度与置信度转化为可解释、可控制的调度变量?
- 如何设计渐进式多源检索,平衡效率与证据覆盖?
- 如何构建复杂度 - 置信度 - 融合决策一体化框架?
2.方法(Methods)
查询 Q → 复杂度分类器 C → 自适应路由 R → 多源检索器池 RS → 置信度感知融合引擎 CAF → 答案生成
- 核心:以 **(复杂度类别 c, 校准置信度 α)** 双信号控制全流程。
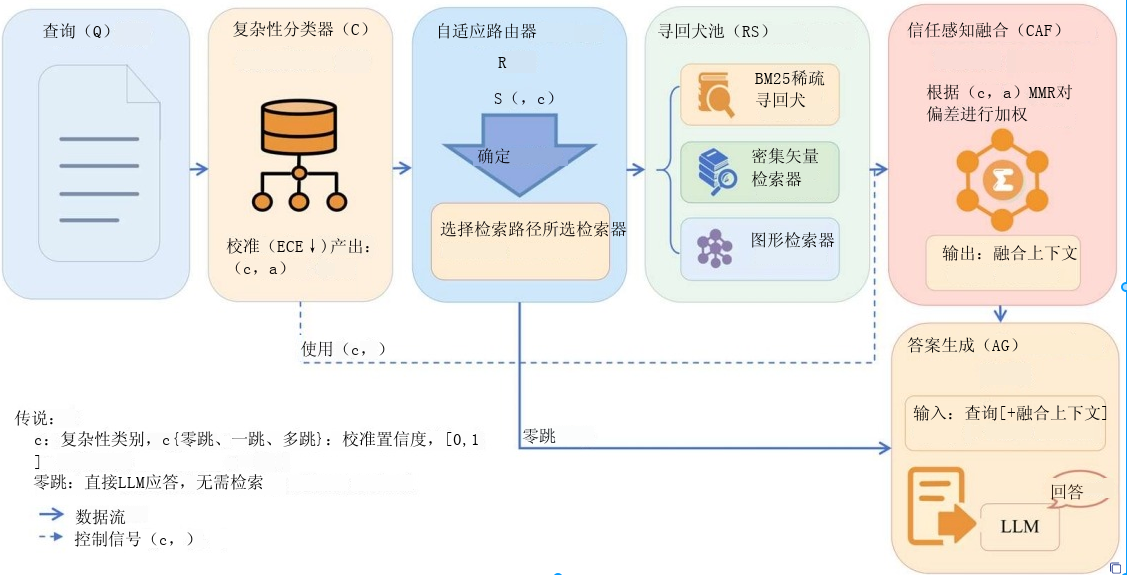
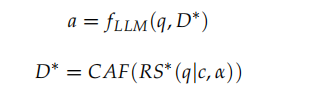
- 给定查询 q,
- 复杂度分类器 C 输出一对(c,a),其中 c 表示预测的查询复杂度类别,α 代表校准后的置信度。
- 在这一联合信号的指导下,检索控制器 R 动态激活子集
以执行检索并构建候选证据集。
- 随后,CAF 模块根据复杂度和置信度信号对跨源结果进行加权并约束其多样性,生成融合上下文
。
- 最后,大语言模型基于查询和融合证据生成最终答案
2.1 查询复杂度建模与置信度估计
复杂度三级分类(按证据需求)
- 零跳(zero-hop):模型内部知识可直接回答,无需检索;
- 一跳(one-hop):需单条外部证据;
- 多跳(multi-hop):需跨实体 / 跨文档多证据推理。
基于 ModernBERT 的分类器
- 输入查询→CLS 向量→线性层→softmax 输出三类概率;
- 取最大概率为预测类别ĉ ,对应概率为原始置信度 α;
- 训练用PEFT 高效微调 ,后用温度缩放校准置信度,降低 ECE。
为自动判定查询复杂度类别,本文训练了一个基于 ModernBERT 的分类模型。ModernBERT 是 BERT 架构的改进版本,它同时提升了表征能力和计算效率,尤其适用于对具有大语义跨度的查询进行建模。
给定输入查询 q,模型首先通过编码器获取句子级表征向量
,并通过线性分类层将其映射到三个复杂度类别的概率分布:
其中
表示查询 q 属于复杂度类别 c 的预测概率;
W 和 b 为分类层的参数;
c 为概率最大类别对应的预测标签;
α 为对应类别的概率,经后处理后作为校准后的置信度。
训练过程中,分类器采用参数高效微调(PEFT)技术,后续实验中还给出了分类器的准确率和置信度校准结果。
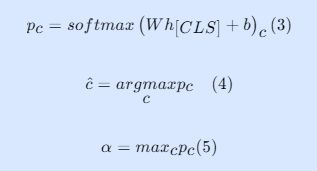
2.2.渐进式多源检索策略
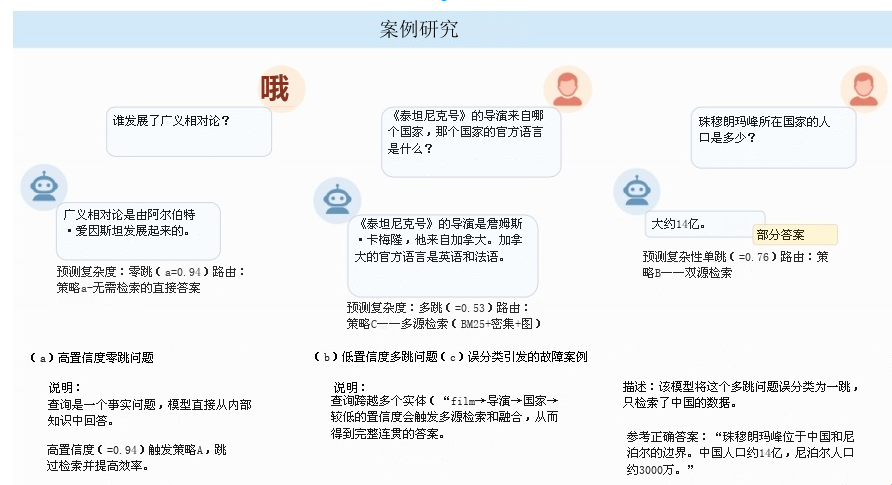
按置信度阈值 θₕ(高)、θₗ(低) 分 3 条路径,从简到繁、按需激活检索器:
- 策略 A(高置信度 α≥θₕ)
- 仅激活最优检索器;零跳查询直接 LLM 回答,不检索,极致提效。
- 策略 B(中置信度 θₗ≤α<θₕ)
- 并行激活稠密 + 稀疏两个互补检索器,平衡语义覆盖与精度。
- 策略 C(低置信度 α<θₗ 或 多跳)
- 同时激活语义、关键词、图检索,多源冗余确保证据完整。
鲁棒性设计
- 置信度缓冲机制:分类边界模糊时,优先选更全面的检索路径 ,避免信息缺失。
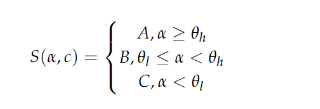
RRF 指 Reciprocal Rank Fusion(互惠排名融合),是信息检索(IR)领域常用的一种多源检索结果融合方法。它的核心思想是:
- 输入:多个检索源(不同搜索引擎、不同模型或不同索引)针对同一查询产生的排序列表(ranked lists)。
- 融合方法 :给每个检索结果一个分数,计算方式是互惠排名(reciprocal rank)加权求和:
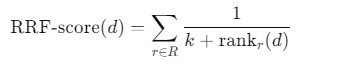
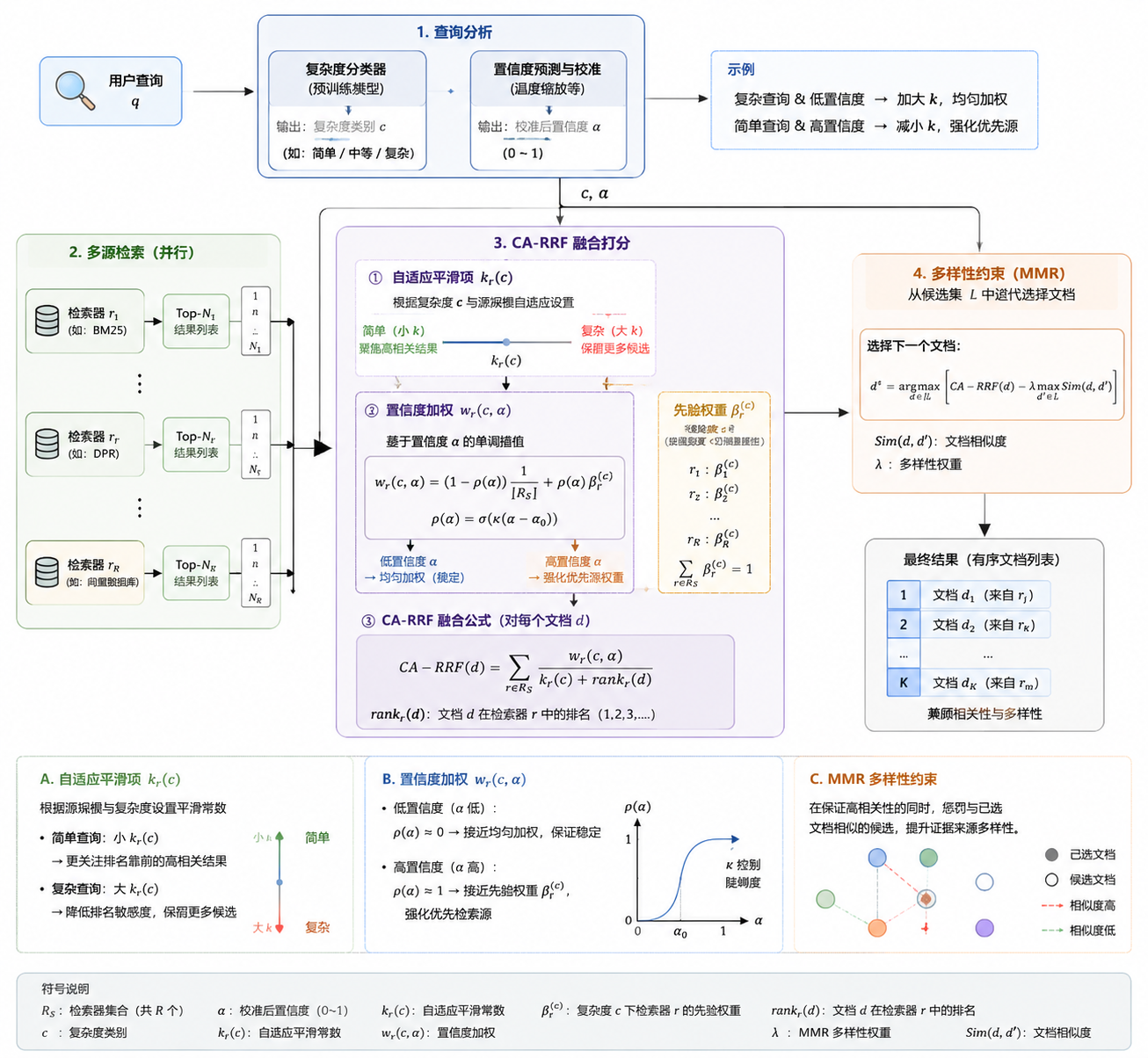
2.3.置信度感知 RRF(CA-RRF)
传统 RRF 缺陷
- 平等对待所有检索源,固定平滑系数,不考虑查询复杂度与源差异,易冗余、多样性差。
CA-RRF 改进
- 把复杂度 c、置信度 α 融入融合公式:
- 自适应平滑项 kᵣ(c):简单查询用小 k,聚焦高相关结果;复杂查询用大 k,保留更多候选;
- 置信度加权 wᵣ(c,α):低置信度→均匀加权保稳定;高置信度→强化优先检索源权重;
- MMR 多样性约束:去重,提升证据来源多样性。




3.实验(Experiment)
3.1 数据准备
- 数据集:MS MARCO(事实单跳)、HotpotQA(多跳推理),覆盖全场景;
- 标注:GPT-4 辅助标注 + 人工校验,保证标签可靠;
- 划分:训练集 / 校准集 / 测试集 = 8:1:1,超参数在校准集确定。

超参数设置
- 路由阈值:θₕ=0.90,θₗ=0.60;
- 融合参数:κ=2.0,α₀=0.5,MMR 的 λ=0.5。
3.2.复杂度分类器评估
- 指标:准确率、Macro-F1、ECE(期望校准误差)、RAA(置信度校正准确率);
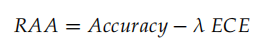
- 结果 :ModernBERT 最优→Acc 85.9%、Macro-F1 85.4%、ECE 1.9%;
- 混淆矩阵:多跳识别最准(94.4%),零跳 / 一跳易混淆(错误多为 "向上误判",仅增延迟,不损答案质量);
- 校准效果:温度缩放后 ECE 从 7.7%→1.9%,置信度与实际准确率高度对齐。
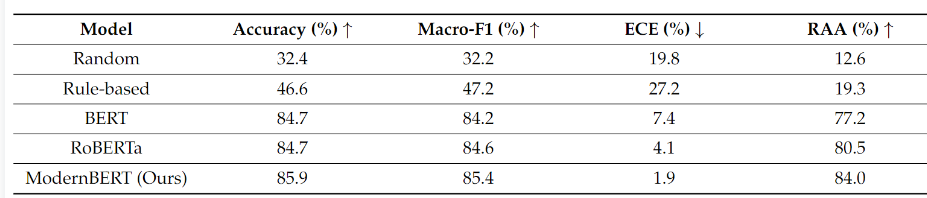
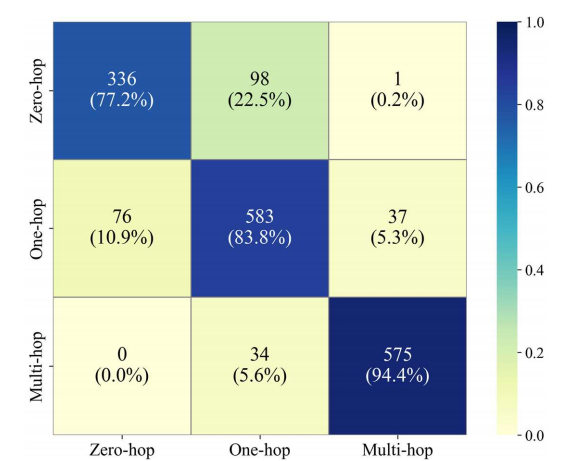

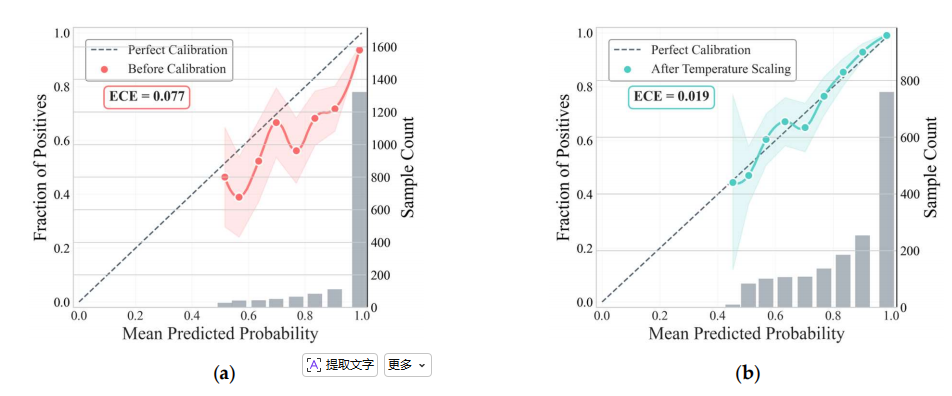
3.3.端到端问答实验
-
基线:固定流水线 RAG、Self-RAG、Adaptive-RAG;
-
指标 :EM、F1(答案准确率)、nDCG@5(检索相关性)、延迟(效率

交集 预测答案∩参考答案\text{预测答案} \cap \text{参考答案}预测答案∩参考答案 是 预测答案和参考答案共有的元素数量。
在 NLP 问答任务中:
- 词元级(token-level) :
- 元素 = 词元(token),通常是经过分词或子词拆分后的最小单元。
- 中文可以按 字符或分词 ,英文通常按 wordpiece/token。
- 交集计算就是:预测答案和参考答案中 相同的词元数量。
- 举例(中文字符级) :
- 预测答案:
南堡凹陷→ 4 个字符- 参考答案:
南堡凹陷东营组→ 7 个字符- 交集 =
南堡凹陷→ 4 个字符- Precision = 4 / 4 = 100%
- Recall = 4 / 7 ≈ 57%


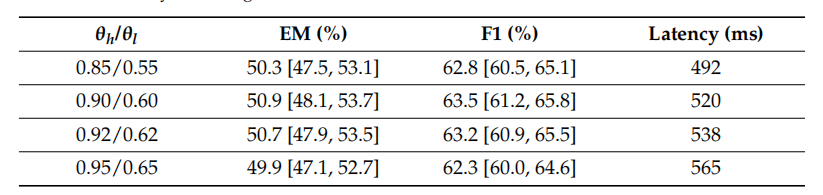
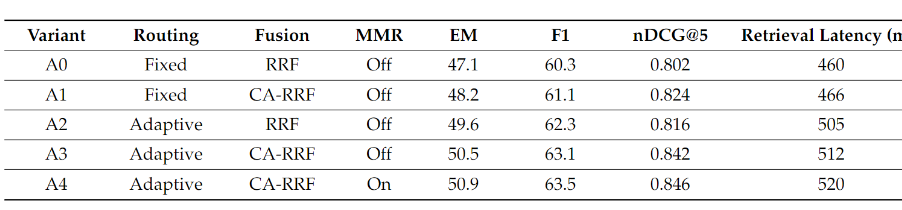
消融实验: