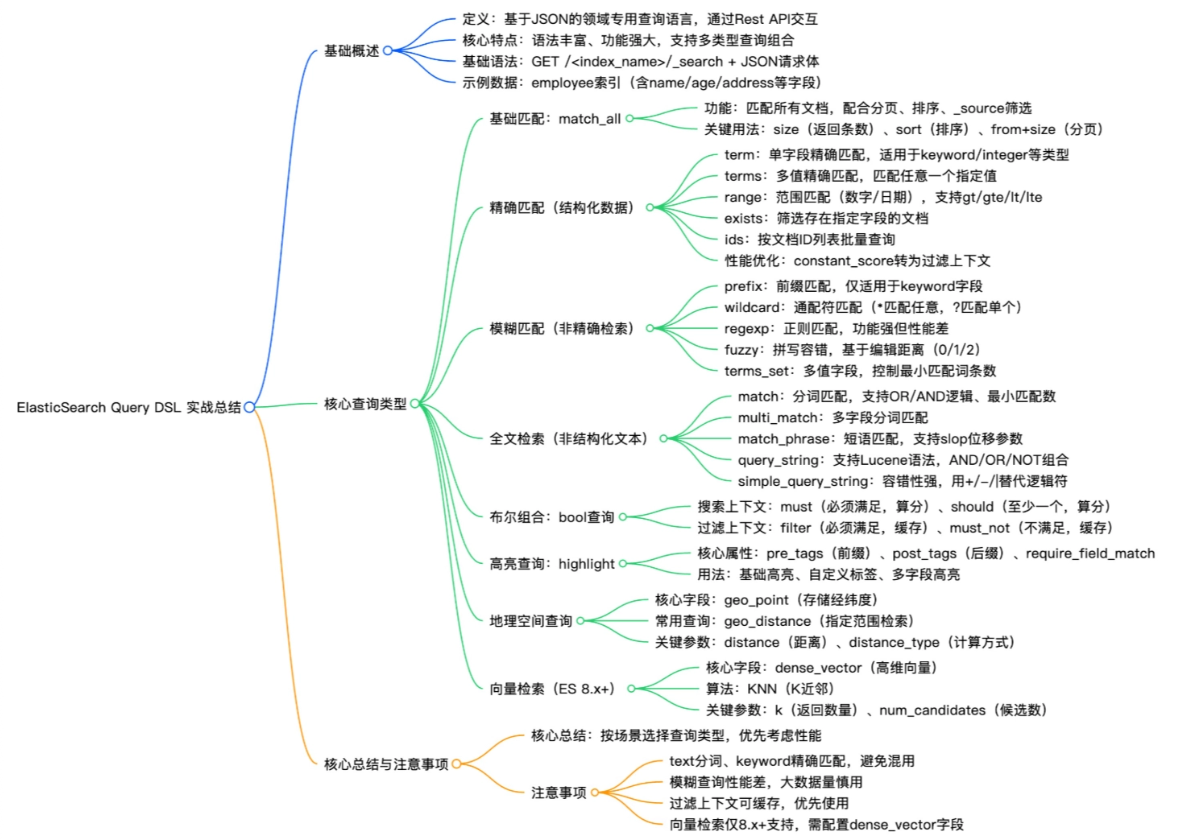
本文基于 ElasticSearch 8.x 版本,详细总结 Query DSL(Domain Specified Language,领域专用语言)的核心用法、各类查询场景及实操技巧。Query DSL 是 ES 中最强大的检索方式,通过 Rest API 传递 JSON 格式请求体与 ES 交互,支持精确匹配、全文检索、布尔组合等多种复杂查询,兼顾功能性与实操性,同时配套思维导图梳理知识框架,助力开发者快速掌握并灵活运用 Query DSL 完成各类检索需求。
Query DSL (Domain Specific Language)是 ElasticSearch 最强大、最灵活的查询方式。它通过 JSON 格式请求体 与 ES 交互,支持 精确匹配、全文检索、布尔组合、高亮、地理查询、KNN 向量检索 等复杂场景,是生产环境中必备的核心技能。
本文系统梳理 Query DSL 的核心语法、分类体系、实战示例与性能要点,并配套知识框架,助你快速上手并高效应用。
一、Query DSL 基础概述
1.1 什么是 Query DSL?
- 定义 :ES 提供的基于 JSON 的领域专用查询语言
- 优势 :
- ✅ 支持复杂条件组合(如
bool嵌套) - ✅ 可控制排序、分页、高亮、字段筛选
- ✅ 兼容结构化(keyword/int)与非结构化(text)数据
- ✅ 支持复杂条件组合(如
- 对比 URL 查询:功能更强大、表达更清晰、可维护性更高
💡 核心思想 :"查询即代码" ------ 用声明式 JSON 构建任意复杂检索逻辑。
1.2 示例数据准备(employee 索引)
为统一演示,先创建测试索引:
json
// 1. 删除旧索引
DELETE /employee
// 2. 创建索引 + 映射
PUT /employee
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": { "type": "keyword" },
"sex": { "type": "integer" },
"age": { "type": "integer" },
"address": {
"type": "text",
"analyzer": "ik_max_word",
"fields": { "keyword": { "type": "keyword" } }
},
"remark": {
"type": "text",
"analyzer": "ik_smart",
"fields": { "keyword": { "type": "keyword" } }
}
}
}
}
// 3. 批量插入数据(略,见原文)⚠️ 关键设计 :
address和remark使用 **多字段(multi-field)**,.keyword用于精确匹配,text用于全文检索。
二、核心查询类型详解(按场景分类)
2.1 基础匹配:match_all
匹配所有文档,常用于分页、排序、字段筛选等基础操作。
🔧 常用技巧:
| 功能 | 示例 |
|---|---|
| 限制返回字段 | "_source": ["name", "age"] |
| 不返回源数据 | "_source": false |
| 分页 | "from": 0, "size": 10 |
| 排序 | "sort": [{ "age": "desc" }] |
json
GET /employee/_search
{
"query": { "match_all": {} },
"_source": ["name", "address"],
"from": 0,
"size": 5,
"sort": [{ "age": { "order": "desc" } }]
}2.2 精确匹配(结构化数据)
适用于 ID、状态、枚举、数值、日期 等不分词字段。
✅ 2.2.1 term:单值精确匹配
- 仅用于 keyword / integer / date 等类型
- text 字段需用
.keyword后缀
json
// 正确:使用 keyword
{ "term": { "address.keyword": "广州白云山公园" } }
// 错误:直接查 text 字段(会被分词,结果不可控)
{ "term": { "address": "广州白云山公园" } }💡 性能优化 :用
constant_score+filter避免算分,启用缓存:
json
{ "constant_score": { "filter": { "term": { "name": "张三" } } } }✅ 2.2.2 terms:多值匹配(IN 查询)
json
{ "terms": { "remark.keyword": ["java assistant", "java architect"] } }✅ 支持数组字段:只要包含任一值即匹配。
✅ 2.2.3 range:范围查询
json
// 年龄区间
{ "range": { "age": { "gte": 25, "lte": 28 } } }
// 日期范围(支持相对时间)
{ "range": { "created_at": { "gte": "now-2y" } } }📅 常用时间表达式:
now-1d(1 天前)now-1w(1 周前)now-1M(1 月前)now-1y(1 年前)
✅ 2.2.4 exists / ids
exists:检查字段是否存在且非空ids:按文档 ID 批量召回
json
{ "exists": { "field": "remark" } }
{ "ids": { "values": ["1", "2"] } }2.3 模糊匹配(谨慎使用!)
⚠️ 性能开销大,避免在高并发或大数据量场景使用。
| 类型 | 说明 | 示例 |
|---|---|---|
prefix |
前缀匹配 | "address.keyword": { "value": "广州白云" } |
wildcard |
通配符(*、?) |
"address.keyword": "*州*公园" |
regexp |
正则表达式 | "remark": "java.*" |
fuzzy |
拼写容错(编辑距离) | "address": { "value": "白运山", "fuzziness": 1 } |
🔥 严重警告:
- 避免
xxx开头的通配符(全索引扫描)- 正则越复杂,性能越差
- 优先考虑 ngram 或 edge_ngram 分词器替代
✅ 2.3.5 terms_set:多值字段最小匹配数
适用于标签、技能等场景:
json
{
"terms_set": {
"tags": {
"terms": ["喜剧", "动作", "科幻"],
"minimum_should_match": 2
}
}
}2.4 全文检索(非结构化文本)
对
text字段进行分词后匹配,计算相关性得分(_score)。
✅ 2.4.1 match:基础分词匹配
- 默认 OR 逻辑(匹配任一分词)
- 可设
operator: "and"或minimum_should_match
json
// OR 逻辑(默认)
{ "match": { "address": "广州公园" } }
// AND 逻辑
{ "match": { "address": { "query": "广州公园", "operator": "and" } } }
// 至少匹配2个词
{ "match": { "address": { "query": "广州 白云 公园", "minimum_should_match": 2 } } }✅ 2.4.2 multi_match:多字段检索
json
{
"multi_match": {
"query": "长沙 java",
"fields": ["address", "remark"]
}
}✅ 2.4.3 match_phrase:短语匹配
- 要求词条顺序一致
slop控制允许的词序位移
json
// 严格匹配"广州白云山"
{ "match_phrase": { "address": "广州白云山" } }
// 允许"广州"和"云山"之间有2个词间隔
{ "match_phrase": { "address": { "query": "广州云山", "slop": 2 } } }✅ 2.4.4 query_string vs simple_query_string
| 类型 | 特点 | 适用场景 |
|---|---|---|
query_string |
支持完整 Lucene 语法(AND/OR/NOT) | 高级用户、后台管理 |
simple_query_string |
容错强,忽略语法错误,用 +` |
-` |
json
// query_string(注意:运算符必须大写!)
{ "query_string": { "query": "赵六 AND 橘子洲" } }
// simple_query_string(更安全)
{ "simple_query_string": { "query": "广州 + 公园" } }2.5 布尔组合:bool 查询(重中之重!)
几乎所有复杂查询都依赖
bool组合
四大子句:
| 子句 | 作用 | 上下文 | 是否算分 | 是否缓存 |
|---|---|---|---|---|
must |
必须满足 | 搜索上下文 | ✅ 是 | ❌ 否 |
should |
至少满足一个(可设最小数量) | 搜索上下文 | ✅ 是 | ❌ 否 |
filter |
必须满足 | 过滤上下文 | ❌ 否 | ✅ 是 |
must_not |
必须不满足 | 过滤上下文 | ❌ 否 | ✅ 是 |
🔧 最佳实践:
- 高频过滤条件 → 用
filter - 全文检索条件 → 用
must/should - 组合示例:
json
{
"bool": {
"must": [
{ "match": { "remark": "java" } }
],
"filter": [
{ "term": { "sex": 1 } },
{ "range": { "age": { "gte": 25 } } }
],
"must_not": [
{ "term": { "name": "张龙" } }
]
}
}2.6 高亮查询(highlight)
提升用户体验,标红匹配关键词。
json
{
"query": { "match": { "address": "广州" } },
"highlight": {
"pre_tags": ["<span style='color:red'>"],
"post_tags": ["</span>"],
"fields": { "address": {} }
}
}✅ 多字段高亮:设
"require_field_match": false
2.7 地理空间查询(geo_distance)
- 字段类型:
geo_point - 查询方式:
json
{
"query": {
"bool": {
"filter": {
"geo_distance": {
"distance": "10km",
"location": { "lat": 39.9159, "lon": 116.3945 }
}
}
}
}
}🌍 参数说明:
distance_type:arc(地球弧长,更准)或plane(平面,更快)
2.8 向量检索(KNN,ES 8.x+)
用于图像、语义、推荐等 AI 场景。
步骤:
- 字段类型:
dense_vector(指定dims) - 查询使用
knn根节点(**不是 query 内部!**)
json
GET /image-index/_search
{
"knn": {
"field": "image-vector",
"query_vector": [-5, 10, -12],
"k": 10,
"num_candidates": 100
},
"fields": ["title"]
}⚙️ 参数调优:
k:返回 top-K 相似结果num_candidates:候选集大小(越大越准,越慢)
三、核心总结与避坑指南
✅ 核心总结
| 维度 | 关键点 |
|---|---|
| 查询分类 | 精确(term)、全文(match)、模糊(wildcard)、组合(bool)、特殊(geo/KNN) |
| 性能关键 | 过滤上下文(filter)可缓存,避免模糊查询,合理使用 keyword |
| 字段设计 | text 用于搜索,keyword 用于聚合/精确匹配 |
| ES 8.x 新特性 | 原生 KNN 向量检索,简化 AI 应用集成 |
⚠️ 高频注意事项(必看!)
- text 字段不能直接用于 term 查询!必须用
.keyword - 模糊查询(prefix/wildcard/regexp)性能极差,慎用!
- bool 查询中,filter/must_not 不算分、可缓存,优先用于筛选条件
- match_phrase 依赖分词结果,若分词不合理,需调整 analyzer 或 slop
- KNN 查询使用
knn根节点,而非query内部 - simple_query_string 比 query_string 更适合生产环境(容错强)
🎯 最后建议:
Query DSL 是 ES 的"查询引擎",但不是万能 SQL。
对于 超复杂 JOIN、事务、强一致性 场景,仍需结合传统数据库使用。