在正式进入 LangChain & LangGraph AI 应用开发 之前,我们必须先把地基打牢------大语言模型(LLM)是整个 AI 应用框架的核心引擎,不懂 LLM,再强大的框架也只是空中楼阁。
这篇文章不搞玄学、不堆术语,用最贴近开发者的视角,把大语言模型的本质、训练逻辑、核心能力、主流选型、接入方式一次性讲透。它既是 AI 入门,也是你后续写 LangChain 程序、做 RAG、搭建智能体 Agent 的必备理论基础。
一、先分清:传统模型 vs 大语言模型 LLM
很多刚接触 AI 开发的人容易混淆"模型"和"大模型",我们先把边界划清。
1. 什么是普通 AI 模型?
可以把模型理解为一个经过训练的规则工厂。
它从大量标注数据中学习固定规律,只擅长单一、特定任务,能力边界非常清晰。
典型特点:
-
任务专一:只能做一件事(识别猫、预测天气、情感分类)
-
依赖标注数据:必须有"标准答案"才能训练
-
参数规模小:规则简单,复杂度低
-
通用性差:换个任务就要重新训练
比如识别图片中的猫、判断评论好坏、预测股价,都属于这类专用模型。
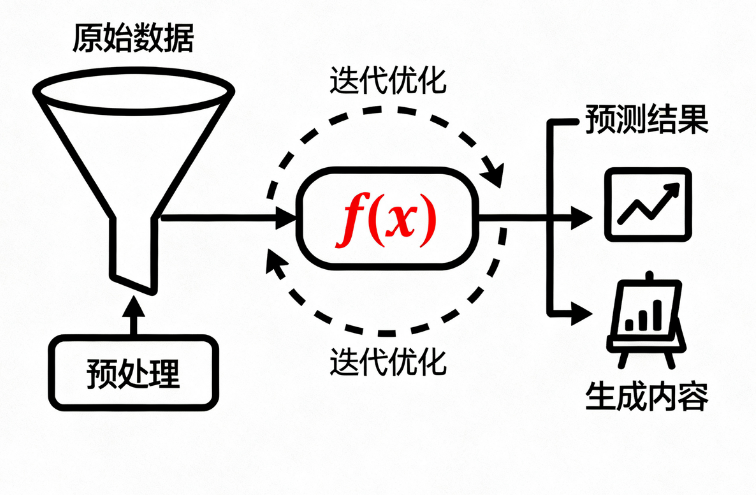
2. 什么是大语言模型(LLM)?
大语言模型是基于深度神经网络、参数达到数十亿~万亿级别 ,通过海量无标注文本自监督训练而成的通用语言理解与生成系统。
它不是为某一个任务设计,而是学会了人类语言的底层规律:语法、逻辑、常识、知识关联、上下文意图,甚至情感与风格。
简单说:
专用模型 = 专科工具
大语言模型 = 通用大脑
这也是为什么 LangChain 这类框架能存在------只有通用 LLM,才能被编排、组合、扩展成复杂 AI 应用。
二、LLM 最核心的 3 个底层原理(开发必懂)
作为应用开发者,你不需要从头训模型,但必须理解它为什么能听懂、会思考、能生成。
1. 神经网络:LLM 的"硬件基础"
神经网络是模仿人脑神经元工作的多层决策系统,由海量参数(虚拟神经元)构成。
-
每层负责提取不同信息
-
层与层之间传递特征
-
训练过程就是自动调整参数权重
最终形成一套能理解语言、推理逻辑的复杂流水线。
参数越多,模型的"记忆容量""理解深度""推理能力"通常越强------这也是我们选择 7B、14B、70B 等不同规模模型的依据。
神经⽹络:⼀个极其⾼效的"团队⼯作流程"或"条件反射链"。
例如教⼀个小朋友识别猫:
不会只给⼀条规则(⽐如"有胡⼦就是猫"),因为兔⼦也有胡⼦。
我们会让他看很多猫的图⽚,他⼤脑⾥的视觉神经会协同⼯作:有的神经元负责识别"尖⽿朵",
有的负责识别"胡须", 有的负责识别"⽑茸茸的尾巴"。 这些神经元⼀层层地传递和组合信息,最后⼤脑综合判断:"这是猫!"

2. 自监督学习:LLM 的"学习方式"
大模型最厉害的地方,是不需要人工逐句标注。
它的训练方式就是海量完形填空:
-
随机遮住文本中的一个词
-
让模型根据上下文预测这个词
-
重复亿万次,自动掌握语言规律
相当于自己给自己当老师,从互联网所有文本中自学语法、逻辑、知识。这也是 LLM 能做到大规模、低成本训练的关键。


3. 语言模型本质:下一个词预测
不管多强大的 LLM,核心任务都一样:
根据上文,预测下一个最合理的词。
我们看到的写文章、聊天、写代码、解数学题,本质都是一个词接一个词生成的结果。
理解这一点,你后续写提示词、调参、做 LangChain 输出控制会豁然开朗。

三、大语言模型的 4 大核心能力(决定 AI 应用上限)
LLM 之所以能支撑 LangChain 复杂应用,靠的是这 4 种能力:
1. 语言理解与生成:AI 应用的交互基础
能精准理解自然语言意图,同时高质量输出:
-
文案创作、邮件、报告、摘要
-
翻译、润色、对话、角色扮演
-
识别语气、情感、隐含需求
这是所有 AI 助手、聊天机器人、智能客服的基础。
2. 知识整合与问答:你的实时知识库
LLM 训练数据覆盖海量书籍、网页、文献,相当于可对话的压缩互联网。
-
解释科学原理
-
对比历史/哲学/技术
-
提供行业常识与思路
结合 LangChain 的 RAG 能力,还能接入私有知识,变成企业专属知识库。
3. 逻辑推理与代码生成:开发者最强辅助
LLM 不只擅长"文科",更具备强逻辑能力:
-
解数学题、逻辑推理、多步骤计算
-
生成 Python/Java/SQL 等代码
-
自动审查、优化、解释代码
这也是 AI 编程工具(Cursor、Codeium)的底层支撑。
4. 多模态理解:打通文本、图像、语音
新一代 LLM 已经突破纯文本限制:
-
看图理解、图文对话
-
图像生成、设计描述
-
语音转文字、文字转语音
为 LangGraph 多模态智能体提供了基础能力。

四、主流 LLM 大盘点:开发该怎么选?
做 LangChain 开发,选对模型事半功倍。这里给大家一份实用选型清单:
1. 闭源商用模型(稳定、易用、适合快速开发)
-
GPT-5 / GPT-4o:长上下文、强推理、综合能力最强
-
Gemini 3.1 Pro:多模态标杆,适合图文混合任务
-
通义千问 Qwen2.5-72B:中文极强,结构化输出稳定
-
DeepSeek R1:逻辑与数学强,代码友好
2. 开源模型(可本地部署、隐私安全、低成本)
-
DeepSeek-R1 系列:开源免费,推理接近闭源模型
-
Qwen 系列:阿里开源,中文优秀,支持本地部署
-
Llama 3 / Gemma:英文强,适合海外场景
-
ChatGLM:老牌开源中文模型,轻量化友好
开发建议:
原型阶段用商用 API;正式上线/隐私敏感用开源模型本地部署。
五、LLM 的 3 种接入方式
LangChain 本身不创造模型,只负责编排调用模型。所以你必须先懂 LLM 怎么接入。

1. API 远程调用(最常用)
直接调用厂商云端服务:
-
申请 API Key
-
用 HTTP 或 SDK 发送请求
-
快速、稳定、无需硬件
适合:快速开发、中小规模、无硬件资源的团队
2. 开源模型本地部署(隐私优先)
把模型下载到本地/私有云运行:
-
使用 Ollama、LM Studio、vLLM 等工具
-
数据不离开内网,安全可控
-
长期大规模使用成本更低
适合:金融、政务、企业内部私有应用
3. SDK 封装调用(开发更简洁)
是 API 的封装版,比如 OpenAI Python SDK,代码更简洁易维护。
LangChain 内部已经对主流 SDK 做了高度封装,你只需要简单配置即可使用。
六、原生 LLM 的局限:为什么我们需要 LangChain?
讲到这里,必须点出一个关键事实:
直接用原生 LLM,做不出复杂企业级应用。
原生 LLM 有 4 个致命短板:
-
上下文长度有限:塞不进长篇文档、整本知识库
-
无实时私有知识:训练数据过时,不懂你的业务数据
-
只能一问一答:无法完成多步骤复杂任务
-
输出不可控:格式不稳定,容易出错
而 LangChain & LangGraph 的价值,就是解决这些问题:
-
用 RAG 给模型外挂知识库
-
用链(Chain)编排多步骤任务
-
用智能体(Agent)实现自主规划
-
用工具调用扩展模型能力(搜索、计算、数据库)
可以说:
LLM 是大脑,LangChain 是手脚与神经系统。

七、本篇总结
这篇文章是你进入 LangChain 世界的第一课:
-
LLM 是通用语言大模型,和传统专用模型完全不同
-
它靠神经网络 + 自监督学习实现强大能力
-
具备语言、知识、推理、多模态四大核心能力
-
开发可选择 API / 本地部署 / SDK 三种接入方式
-
原生 LLM 有局限,必须靠 LangChain 框架扩展成真正应用