本文对应项目版本:
v0.0.6
在 v0.0.5 里,我已经把项目的单 Tool Calling 闭环跑通了:模型能发起 tool_calls,服务端能校验参数、执行工具,前端也能把 reasoning / tool / text 三类内容分开渲染。
但我很快意识到,单 Tool 能跑通,并不意味着系统已经具备了"多能力扩展"的基础。
v0.0.6 我真正想解决的问题不是"再接两个小功能",而是把当前项目从单 Tool 验证版 升级成一个可扩展的多 Tool Runtime:
- 服务端不再只围着一个工具转
- 新增工具不需要继续把主流程越写越重
- 前端能稳定展示不同类型的工具调用
- 多轮上下文不至于随着能力变多而越来越失控
这篇文章就记录一下,这一版我是怎么把 calculator 扩展成 calculator + datetime + text-transform,以及在这个过程中做了哪些设计取舍、踩了哪些坑。
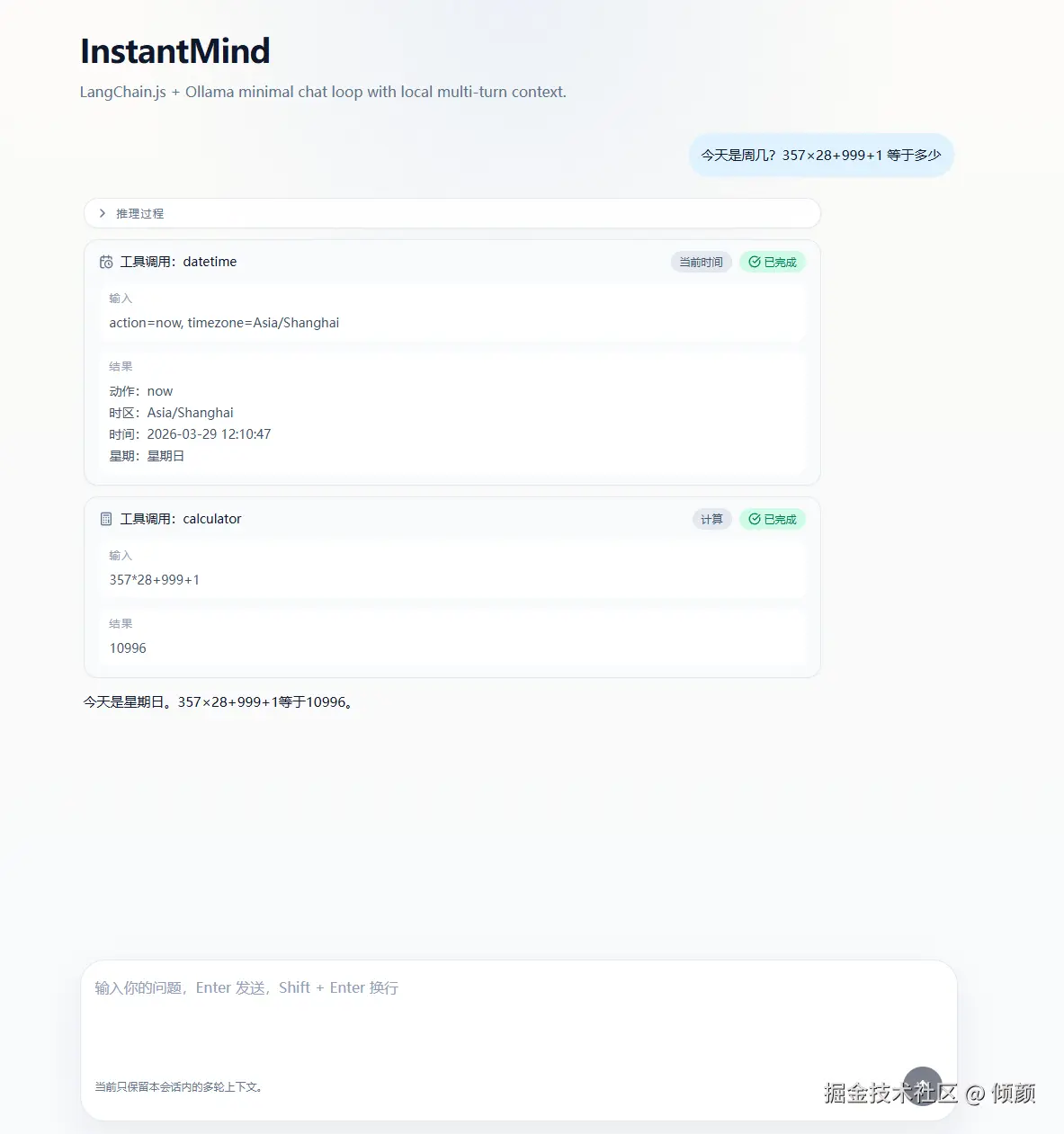
为什么 v0.0.6 不直接做 Agent
这版最开始其实也有一个很自然的诱惑:既然已经有 Tool Calling 了,是不是下一步应该直接做 Agent、Skill、MCP?
最后我没有这么做,原因很简单:
v0.0.5验证的是"单 Tool 可行"v0.0.6更值得验证的是"多 Tool Runtime 能不能站住"- 如果这时直接进入 Agent Loop、Skill 编排或者 MCP 接入,问题会一下子混在一起
所以我给 v0.0.6 定的边界非常明确:
- 只做多 Tool Runtime
- 只接入 3 个工具
- 不引入新的重型运行时
- 优先把注册、校验、执行、展示和上下文管理收稳
也就是说,这版的重点不是"能力平台化",而是"运行时工程化"。
这版具体做了什么
先把本版范围说清楚。
本次接入的 3 个工具分别是:
calculatordatetimetext-transform
它们分别代表了三类不同能力:
calculator:确定性数值计算datetime:确定性时间与日期处理text-transform:结构化文本转换与提取
配套完成的核心能力还有:
- Tool Registry 重构
- 前端多 Tool 卡片展示
- 最近
N=8轮上下文窗口 - 一轮回归测试清单与结果记录
这几个点加在一起,才构成了这一版真正的主题:
v0.0.6的重点不是多了两个 Tool,而是项目第一次具备了可继续生长的多 Tool Runtime 骨架。
总体架构:先稳 Runtime,再谈上层能力
这一版的主链路还是延续前面的设计,只是运行时从"单 Tool"升级成了"多 Tool"。
text
用户输入
-> 前端页面
-> /api/chat
-> chat-service
-> Tool Registry
-> LangChain ChatOllama
-> tool calling / tool execution
-> NDJSON stream
-> useChatStream
-> reasoning / tool / text 展示这个架构里,我刻意保留了几件事:
- 继续用
LangChain.js + Ollama - 继续保留自定义
NDJSON协议 - 继续保留
useChatStream - 继续保留
Markdown + typed parts + Streamdown
原因是这版的关键不是推翻已有结构,而是在已有结构里把 Runtime 层做扎实。
多 Tool 真正难的不是"接入",而是 Runtime 设计
接一个 Tool 和管理多个 Tool,完全不是一回事。
单 Tool 时,很多问题都还不明显:
- 工具定义写在一个文件里没关系
- 主流程里偶尔写一点工具特判也能接受
- 前端只展示一种 Tool 卡片也还说得过去
但工具一旦从 1 变成 3,问题就会立刻变得具体:
- 工具怎么注册?
- 每个工具的 schema 放哪?
- 参数归一化由谁负责?
- 不同工具的展示信息从哪来?
- 错误路径怎么统一处理?
- 新增一个 Tool 时,主运行时能不能尽量不改?
这也是为什么我把这一版最核心的升级点放在了 Tool Registry 上。
Tool Registry:这版最关键的工程升级
如果只看表面,这版像是在"新增两个 Tool";但从工程角度看,更重要的是我先把 Tool 组织方式重构了。
我最后采用的是一种轻插件化思路:
- 每个 Tool 都是独立能力单元
- 每个 Tool 自己携带 schema、归一化逻辑、展示配置和执行逻辑
- Runtime 只依赖统一接口,不依赖具体 Tool 的内部细节
这并不是重型插件系统,不涉及动态安装、插件市场或热插拔。它更像是:
Tool 是插件单元,Registry 是插件容器,Runtime 是插件调度层。
关键代码:统一的 Tool 定义接口
这段代码解决的问题是:让不同类型的工具,都能被 Runtime 用同一种方式注册和调度。
ts
export interface ChatToolDefinition<TArgs = unknown> {
name: string
tool: StructuredToolInterface
schema: ZodType<TArgs>
normalizeArgs?: (args: unknown) => unknown
formatInput?: (args: TArgs) => string
formatOutput?: (result: unknown) => string
getDisplayConfig?: (args: TArgs) => ToolDisplayConfig
resultIsAuthoritative?: boolean
isAvailable?: () => boolean
}这里我最在意的是 4 个字段:
schema:决定这个 Tool 的输入边界normalizeArgs:把模型生成的参数做轻量归一化getDisplayConfig:给前端 Tool 卡片提供统一展示信息resultIsAuthoritative:标记某个工具的结果是否应该被视为高优先级事实来源
也就是说,Registry 不是"把几个 Tool 放进数组里"这么简单,而是在为 Runtime 建立一个足够稳定的契约层。
关键代码:Registry 聚合入口
这段代码解决的问题是:新增 Tool 时,主运行时尽量不需要改。
ts
import { calculatorToolDefinition } from './calculator-tool'
import { datetimeToolDefinition } from './datetime-tool'
import { createChatToolRegistry, type ChatToolDefinition } from './registry'
import { textTransformToolDefinition } from './text-transform-tool'
const chatToolDefinitions: ChatToolDefinition[] = [
calculatorToolDefinition,
datetimeToolDefinition,
textTransformToolDefinition,
]
export const chatToolRegistry = createChatToolRegistry(chatToolDefinitions)这个设计带来的直接收益是:
- 新增 Tool 原则上只需要"新增文件 + 注册"
chat-service不再需要知道每个 Tool 的内部细节- 后续往
Skill / MCP / Agent方向演进时,也有一个比较清晰的能力层基础
为什么是 calculator、datetime、text-transform
这 3 个工具并不是随便挑的。
calculator:确定性数值工具
calculator 延续自 v0.0.5,它的价值不是"做个计算器",而是作为多 Tool Runtime 里的基准工具:
- 输入输出边界非常清楚
- 结果是确定性的
- 很适合验证
tool_calls -> schema -> execution -> tool result这条链路
同时,它也让我确认了一件事:
Tool 结果正确,不代表最终回答一定正确。
因为即使 calculator 算对了,模型在第二阶段组织答案时,仍然有可能把内容写歪。所以这类确定性工具,最终还需要"结果优先"策略兜底。
datetime:确定性时间工具
datetime 是这版最有代表性的新增 Tool。
它覆盖的能力包括:
- 当前时间
- 日期加减
- 星期判断
之所以选它,是因为这类问题非常真实,又特别容易暴露 Tool Calling 的稳定性问题。比如:
- "现在是什么时候"
- "明天是星期几"
- "后天是几号"
这类问题本质上都应该优先走工具,但实际运行里,模型有时会自己脑补推断,甚至说"我无法获取当前日期"。这也让我更清楚地看到:
Prompt 能提高命中率,但不能替代 Runtime 兜底。
text-transform:文本转换工具
text-transform 是这一版里我很喜欢的一个选择。
它不是继续做"闲聊能力",而是验证另一类 Tool 设计方式:一个 Tool 下有多个 action。
我给它收的第一版 action 是:
markdown-to-textextract-linksextract-code-blocksjson-pretty
它的价值在于:
- 让 Runtime 不再只面向"单功能工具"
- 提前验证"一 Tool 多 action"的 schema 设计
- 为后续 Skill 提供更自然的基础能力组件
服务端 Runtime:重点不是能不能调 Tool,而是能不能稳定调对 Tool
多 Tool 之后,chat-service 的职责就不只是"把模型流透给前端"了。
它现在要负责:
- 创建统一模型配置
- 基于当前可用工具集合挂载 Tool 能力
- 处理 planning / retry / final 三段生成
- 校验
tool_calls - 执行 Tool
- 输出
tool-start / tool-end / tool-error - 决定哪些 Tool 结果具有更高优先级
关键代码:统一模型接入层
这段代码解决的问题是:Runtime 不再按问题类型人工分流,而是按当前可用工具集合决定是否挂载 Tool 能力。
ts
function createBaseModel(request: ChatRequest, deps: ChatServiceDependencies) {
return new ChatOllama({
model: request.options?.model ?? deps.defaultModel,
baseUrl: deps.baseUrl ?? process.env.OLLAMA_BASE_URL ?? 'http://127.0.0.1:11434',
temperature: request.options?.temperature ?? 0.3,
numPredict: request.options?.maxTokens,
think: request.options?.enableReasoning,
streaming: true,
})
}
const baseModel = createBaseModel(request, deps)
const activeTools = chatToolRegistry.listActive()
const toolBoundModel =
activeTools.length > 0 ? baseModel.bindTools(activeTools.map(toolDefinition => toolDefinition.tool)) : null这个判断的价值在于:
- 它不是"普通模型"和"工具模型"两套业务分叉
- 而是一个基础模型接入层,在运行时决定是否挂工具能力
这比继续往 chat-service 里堆问题类型判断,要干净得多。
关键代码:显式校验 tool call 参数
这段代码解决的问题是:模型输出并不可信,tool call 参数不能直接执行。
ts
const normalizedArgs = toolDefinition.normalizeArgs
? toolDefinition.normalizeArgs(toolCall.args)
: toolCall.args
const parsedArgs = toolDefinition.schema.safeParse(normalizedArgs)
if (!parsedArgs.success) {
toolErrors.push({
id: toolCall.id,
toolName: toolCall.name,
input: formatToolInput({
...toolCall,
args: normalizedArgs,
}),
message: createToolValidationErrorMessage(toolCall, parsedArgs.error),
})
continue
}
validatedToolCalls.push({
...toolCall,
args: parsedArgs.data,
})这一步很关键,因为它把 Tool Calling 从"模型说了算"拉回到了"运行时有边界"。
关键代码:非法 tool call 不再静默 finish
这段代码解决的问题是:当模型生成的全是非法 tool_call 时,前端至少要收到明确的错误,而不是无声结束。
ts
if (toolCalls.length === 0) {
writeToolValidationErrors(validationResult.toolErrors, writeChunk)
writeChunk({
type: 'finish',
})
return
}这是这一版回归测试里修掉的一个很重要的问题。之前如果模型只给出非法 tool_call,服务端会直接 finish,前端看起来像"只思考、不回答、也不报错",排查体验非常差。
前端:现在渲染的不是字符串,而是工具事件流
进入多 Tool 之后,前端最大的变化不是"多了几个卡片",而是消费内容的方式变了。
useChatStream 现在处理的是一串结构化事件:
startreasoning-*tool-*text-*finisherror
这意味着前端不再只是拼接一段字符串,而是在消费整个运行时状态变化。
关键代码:按 chunk 消费 NDJSON 流
这段代码解决的问题是:把服务端输出的结构化 NDJSON 流稳定转成前端状态更新。
ts
async function consumeNdjsonStream(
stream: ReadableStream<Uint8Array>,
onChunk: (chunk: ChatStreamChunk) => void
) {
const reader = stream.getReader()
const decoder = new TextDecoder()
let buffer = ''
while (true) {
const { done, value } = await reader.read()
if (done) {
break
}
buffer += decoder.decode(value, { stream: true })
const lines = buffer.split('\n')
buffer = lines.pop() ?? ''
for (const line of lines) {
const trimmedLine = line.trim()
if (!trimmedLine) {
continue
}
const parsedChunk = chatStreamChunkSchema.safeParse(JSON.parse(trimmedLine))
if (!parsedChunk.success) {
throw new Error('Invalid chat stream chunk.')
}
onChunk(parsedChunk.data)
}
}
}关键代码:最近 N 轮上下文窗口
这段代码解决的问题是:前端保留完整聊天记录,但只把最近窗口回传给模型,减少历史噪音。
ts
const MAX_CONTEXT_TURNS = 8
function getRecentContextWindow(messages: MindMessage[]): MindMessage[] {
const systemMessages = messages.filter(message => message.role === 'system')
const conversationalMessages = messages.filter(message => message.role !== 'system')
const recentMessages: MindMessage[] = []
let userTurnCount = 0
for (let index = conversationalMessages.length - 1; index >= 0; index -= 1) {
const message = conversationalMessages[index]
recentMessages.unshift(message)
if (message.role === 'user') {
userTurnCount += 1
if (userTurnCount >= MAX_CONTEXT_TURNS) {
break
}
}
}
return [...systemMessages, ...recentMessages]
}这里我没有一上来做摘要记忆,而是先固定 N = 8。原因很简单:
- 实现简单
- 行为稳定
- 容易测试
- 方便版本对比
对当前阶段来说,这是一个非常划算的工程折中。
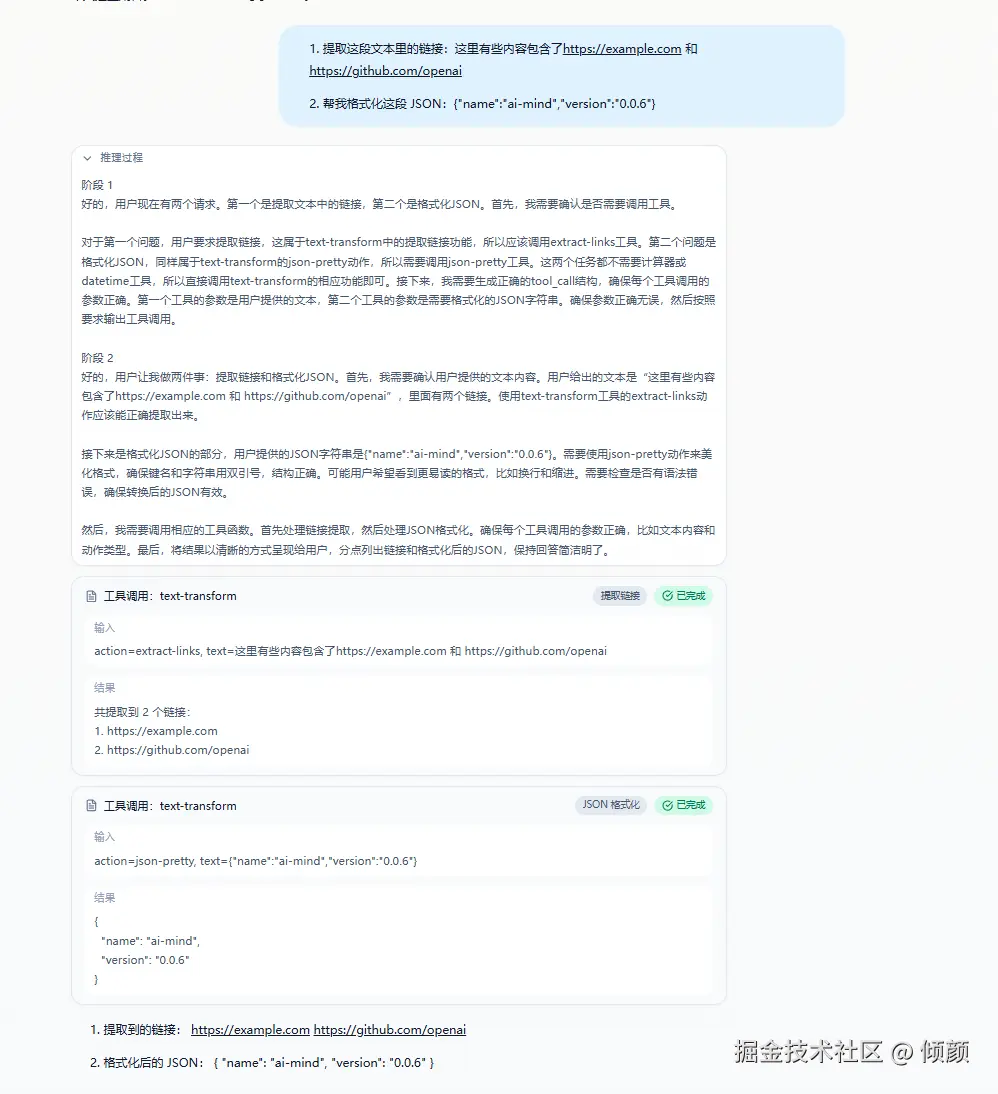
这版最值得记录的几个坑
这篇文章如果只写"最终方案",其实会显得太平。v0.0.6 真正有价值的地方,恰恰在于它暴露了多 Tool Runtime 里的很多真实问题。
1. 多 Tool 不等于模型会稳定选 Tool
这版最明显的现象是:
calculator相对比较稳datetime在"当前时间 / 相对日期"上并不稳定text-transform在非法 JSON 边界输入上也会绕开 Tool
这说明一个很现实的问题:
Tool 变多以后,系统的难点会从"能不能调 Tool",转成"能不能稳定地调对 Tool"。
2. Prompt 很重要,但真的有上限
这一版我对 prompt 做了不少收紧,尤其是时间类问题:
- 明确当前时间要走
datetime - 明确相对日期要优先调工具
- 明确不能说"我无法获取当前日期"
这些约束确实有帮助,但实践下来我也越来越确定:
Prompt 可以提高命中率,但不能替代 Runtime。
尤其是:
- 相对日期
- 非法 JSON
这类边界问题,一旦只靠 prompt,收益会越来越接近上限。
3. 非法 tool call 的静默 finish
这个问题前面已经提过,但我觉得很值得单独记录。
因为它特别像真实工程里那种"功能看起来没挂,但体验非常差"的问题:
- 服务端没有崩
- 前端也没有明显异常
- 但整条对话就像凭空断掉了一样
这种问题不把 Runtime 的错误链路补清楚,后面会非常难调。
4. 版本边界控制本身也是设计能力
这一版做完以后,我反而更确信一件事:
知道什么时候不做,比知道还能做什么更重要。
因为如果这版继续往下扩:
- Agent Loop
- Skill Runtime
- MCP 接入
那整篇文章和整版工程都会失焦。
回归测试:这版到底稳到了什么程度
这一版我没有只凭"感觉能跑"就结束,而是把回归测试清单和实际回归结果单独整理成了文档。
重点验证了几类场景:
- 普通问答
calculatordatetimetext-transform- 多轮上下文
- 非法
tool_call - 一轮失败后下一轮是否受影响
当前可以认为比较稳定的部分:
- 普通问答直答
calculatortext-transform正常输入路径- 非法
tool_call的服务端错误透传
还没有完全收稳的部分:
datetime的当前时间 / 相对日期问题text-transform(json-pretty)的非法 JSON 边界输入
这也恰好说明了这版的真实状态:
多 Tool Runtime 骨架已经成型,但某些工具边界还在逼近"单靠 Prompt 不够"的上限。
当前版本已经完成什么,还没有完成什么
如果给 v0.0.6 一个比较准确的状态定义,我会说:
方案已经基本实现完成,版本进入收口和打磨阶段。
已完成
- 多 Tool Runtime
- Tool Registry
calculatordatetimetext-transform- 前端多 Tool 展示
- 最近
N=8轮上下文窗口 - 回归测试清单与结果记录
还没做
- Skill 系统
- MCP 接入
- Agent Loop
- 长期记忆
- 并行工具调度
这不是缺陷,而是我刻意保留的版本边界。
下一步路线:从 Runtime 走向更高层能力
这版做完之后,后面的演进路线已经比之前清楚很多了。
我现在更倾向于把后续能力理解成一条逐步演进链:
- Tool:原子能力
- Skill:能力模板
- MCP:外部能力接入标准
- Agent:调度这些能力完成任务的运行时
从这个角度看,v0.0.6 的价值并不只是多了两个 Tool,而是它第一次把这条演进链的底座打得比较像样了。
最后总结
这版真正完成的,不是"多接了两个工具",而是让项目第一次具备了可继续演进的多 Tool Runtime 骨架。
它解决的是一组更底层、也更长期的问题:
- Tool 怎么注册
- Tool 怎么校验
- Tool 怎么执行
- Tool 怎么展示
- 多轮上下文怎么控制
而这些问题一旦理顺,后面无论是继续扩 Tool,还是往 Skill / MCP / Agent 走,都会自然很多。
项目地址
GitHub:[github.com/HWYD/ai-min...](https://link.juejin.cn?target=https%3A%2F%2Fgithub.com%2FHWYD%2Fai-mind%2Freleases%2Ftag%2Fv0.0.6 "https://github.com/HWYD/ai-mind/releases/tag/v0.0.6")
如果这篇文章或这个项目对你有帮助,欢迎点个 Star 支持一下。
后续我也会继续按版本节奏,把它往 Skill、MCP、Agent 的方向一点点推进下去。