前言
Claude Code凭借强大的代码理解、编辑与执行能力,成为AI研发工程师的高效工具,但多数使用者仅停留在功能调用层面,对其底层架构尤其是核心控制层Harness知之甚少。作为Claude Code架构师,本文将从项目架构视角,拆解其核心文件构成,深度解析Harness的本质与实现逻辑,解答「如何用确定性代码约束概率性LLM」的核心问题,同时结合工程化实践,梳理架构设计的痛点与解决方案,为AI Agent的工程化落地提供参考。

一、背景:LLM时代,AI Code工具的架构挑战
大语言模型(LLM)的出现让代码智能工具迎来爆发,但LLM本身是概率推理引擎------它能根据输入生成大概率合理的结果,却无法保证100%的确定性,更不具备原生的文件操作、命令执行、会话管理能力。
Anthropic推出的Claude模型作为底层大脑,仅能实现「文本输入-下一个词的概率计算」的核心功能,为了将其打造成可落地的Claude Code工具,需要在模型之上搭建多层架构,解决能力扩展 与风险控制两大核心问题:
- 能力扩展:让Claude拥有读文件、执行命令、上网、记忆会话的能力;
- 风险控制:约束LLM的灵活性,避免其执行危险命令、违反项目规范,保证工具使用的安全性与合规性。
在此背景下,Claude Code形成了「七层蛋糕」的分层架构,而Harness作为核心控制层,成为连接LLM能力与工程化落地的关键,也是整个项目架构的灵魂。
Claude Code整体分层架构(Mermaid图)
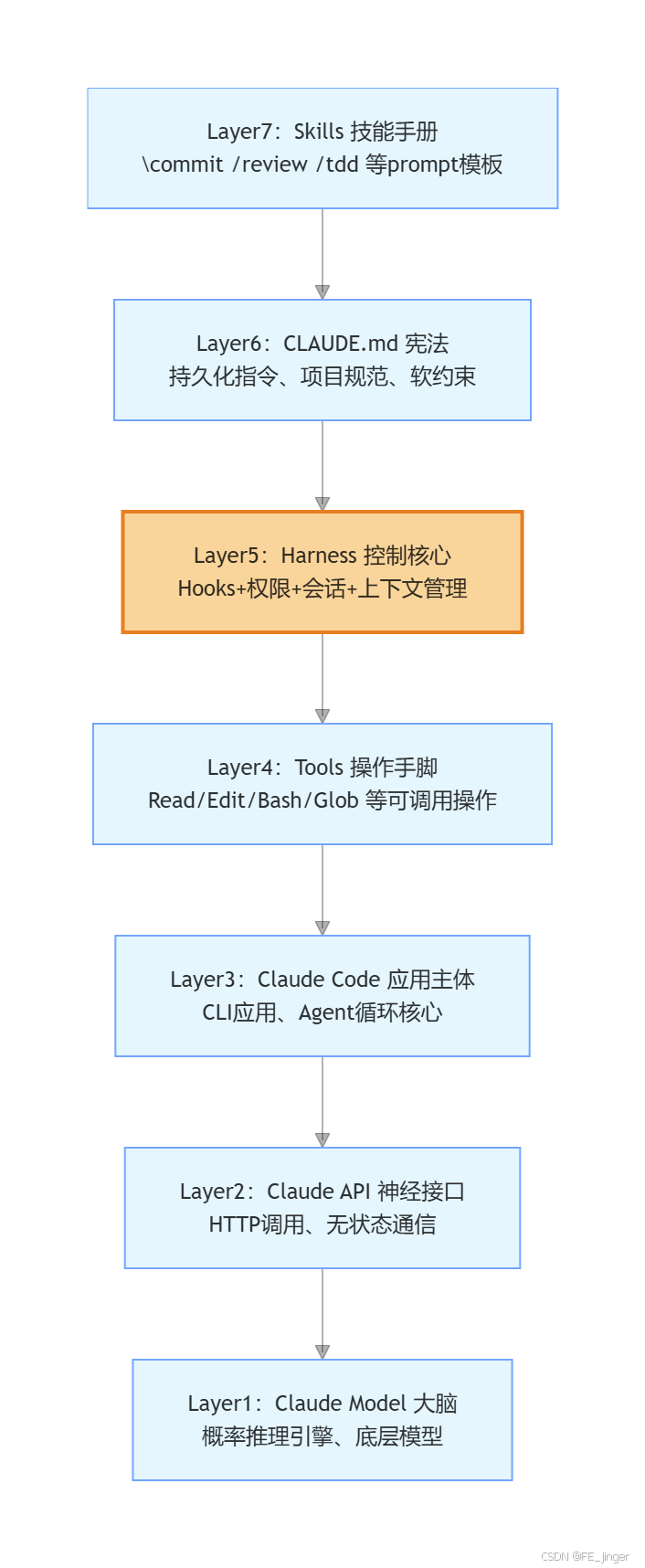
注:橙色标注为核心控制层Harness,是本文解析的重点。
二、痛点:无控制的LLM工具,高效却危险
在Harness出现之前,早期的AI Code工具直接基于LLM API做简单的能力封装,暴露出一系列工程化痛点,也是Claude Code架构设计必须解决的核心问题:
1. LLM的概率性导致规则执行不严谨
通过prompt向LLM下达的规则(如「禁止使用cat命令」「不准执行rm -rf」),在长对话、上下文压缩场景下,遵守率仅85%-95%。对于生产环境,1%的违规概率都可能导致数据丢失、系统崩溃,软约束无法满足工程化的合规要求。
2. 能力扩展与风险控制的矛盾
LLM的价值在于灵活性 ,能处理开发者未预料到的代码问题;但灵活性同时带来不可控性,LLM可能随意执行高危命令、修改核心文件,完全放开则工具危险,完全锁死则工具失去智能性,难以找到平衡。
3. 会话与上下文管理的混乱
LLM本身是无状态的,无法记忆上一轮对话,且上下文窗口有长度限制。长对话中若无法自动压缩上下文、保存会话检查点,会导致工具「断片」,无法完成复杂的代码调试、项目重构等长周期任务。
4. 工程化落地的效率与成本问题
直接使用大模型(Opus)处理所有任务,会导致token成本飙升(Opus价格是Haiku的60倍);硬编码的规则修改需要重启服务,无法热更新;工具调用的无拦截流程,会导致执行效率低、卡顿明显。
5. 核心文件职责不清晰,架构可维护性差
若未对配置文件、控制文件、操作文件做分层设计,会出现「规则写在prompt里、约束散在代码中」的问题,项目迭代时修改成本高,难以规模化落地。
三、实现:Claude Code项目架构全解析
Claude Code的架构实现围绕「分层解耦、软硬结合、确定性控制 」三大原则展开,核心分为核心文件构成 、Harness的本质与定位 、Harness核心实现 、一次请求的完整执行流程四部分,从文件到层,从层到流程,实现对LLM的全链路控制。
(一)Claude Code核心文件构成
Claude Code的项目文件围绕七层架构做模块化设计,核心文件可分为配置文件 、控制文件 、应用核心文件 、工具集文件四大类,各文件与架构层一一对应,职责清晰、解耦性强,以下为核心文件及作用:
| 文件类型 | 核心文件 | 对应架构层 | 核心作用 |
|---|---|---|---|
| 配置文件 | CLAUDE.md | Layer6 | 项目「宪法」,写入持久化指令、编码规范、禁止事项,实现prompt级软约束 |
| settings.json | Layer5 | Harness的核心配置文件,定义Hooks脚本、权限规则、模型路由策略,支持热更新 | |
| skills.yaml/.md | Layer7 | 技能手册,封装/tdd//review等prompt模板,实现知识注入 | |
| 控制文件 | harness.py | Layer5 | Harness的核心实现文件,封装Hooks、权限、会话、上下文管理的核心逻辑 |
| context_manager.py | Layer5 | 上下文压缩与管理的子模块,隶属于Harness | |
| session_manager.py | Layer5 | 会话检查点、恢复的子模块,隶属于Harness | |
| 应用核心文件 | claude_code_cli.py | Layer3 | Claude Code的CLI应用入口,实现Agent循环(输入→拼装prompt→调API→执行工具→循环) |
| agent_cycle.py | Layer3 | Agent循环的核心逻辑,处理用户输入与模型输出的交互 | |
| 工具集文件 | tools.py | Layer4 | 封装Read/Edit/Bash/Glob等可调用工具,提供LLM的「手脚」 |
| bash_tool.py/read_tool.py | Layer4 | 各工具的独立实现,解耦工具集逻辑 | |
| 接口文件 | claude_api_client.py | Layer2 | Claude API的调用客户端,实现HTTP无状态通信 |
核心设计亮点:所有控制规则与业务逻辑解耦,配置文件与代码文件分离,如Harness的规则通过settings.json配置,无需修改harness.py即可更新约束策略,支持热更新,提升工程化可维护性。
(二)Harness的本质与定位:不是功能,是全链路控制体系
很多开发者将Harness理解为一个「功能模块」,这是典型的认知偏差。Harness是Claude Code中所有控制机制的统称,是架设在Claude Code应用与工具集之间的「安检门」,也是连接软约束(CLAUDE.md)与硬执行(Tools)的核心桥梁。
从架构定位看:
- Claude Model是大脑(概率推理);
- Claude Code是身体(Agent循环应用);
- Tools是手脚(具体操作);
- Harness是方向盘+安全带+仪表盘(确定性控制)。
其核心哲学是:用确定性的代码逻辑,约束概率性的LLM模型,让LLM的灵活性在可控范围内发挥,既保证能力,又规避风险。
(三)Harness的核心实现:四大机制+三大Hook检查站
Harness的核心实现围绕四大控制机制 展开,同时通过三大Hook检查站将控制逻辑嵌入到Claude Code的全执行流程中,实现「事前拦截、事中控制、事后处理」的全链路管控,也是Harness作为「控制核心」的关键。
1. Harness四大核心控制机制(Mermaid图)
Harness 核心控制机制
Hooks 钩子机制
生命周期脚本拦截
Permissions 权限机制
allow/deny/ask白名单规则
Context Manager
上下文管理
自动压缩裁剪
Session Manager
会话管理
检查点/恢复
注:蓝色标注为Harness最核心的机制------Hooks钩子机制。
四大机制的具体作用与实现要点:
| 机制 | 核心作用 | 实现要点 | 一句话总结 |
|---|---|---|---|
| Hooks | 在生命周期事件上执行自定义脚本,实现拦截/放行 | 定义三个检查站,脚本返回exit 0=放行,exit 2=拦截+提示 | 每次Claude想用工具,先过我这关 |
| Permissions | 对工具/命令做权限控制 | 基于白名单设计,白名单之外的操作一律拦截,支持ask模式(询问用户后执行) | 非白名单,零执行 |
| Context Manager | 解决上下文窗口溢出问题 | 基于语义分析自动压缩长对话,保留核心信息,裁剪冗余内容 | 快超窗口?我来裁剪 |
| Session Manager | 解决LLM无状态问题 | 定时保存会话检查点,断连后可恢复对话状态,记录操作日志 | 聊到一半断了?我帮你接上 |
2. Harness三大Hook检查站:嵌入全流程的确定性拦截
Hooks是Harness的核心,其通过三个生命周期检查站,将控制逻辑嵌入到Claude Code的关键执行节点,实现对用户输入、工具调用、工具执行结果的全链路管控,也是「代码级强制约束」的核心体现。
三大检查站的执行节点与作用:
| 检查站 | 执行时间 | 核心作用 | 工程化实操示例 |
|---|---|---|---|
| UserPromptSubmit | 用户按下回车,输入还未发给模型时 | 预处理用户输入,注入上下文(如搜索相关代码),过滤无效输入 | 用户要求修复auth.py,提前搜索auth.py的相关代码,拼接到prompt中 |
| PreToolUse | 模型决定调用某个工具/命令,还未执行时 | 检查工具/命令的安全性、合规性,拦截违规操作 | 拦截以cat/rm -rf开头的Bash命令,返回「请用Read工具代替」 |
| PostToolUse | 工具执行完成,结果还未返回给模型时 | 处理执行结果,如压缩长结果、过滤敏感信息、记录审计日志 | Bash执行结果有1000行,自动压缩为核心关键信息,再返回给模型 |
核心实现思路 :在settings.json中为每个Hook配置自定义脚本,harness.py加载配置并在对应节点执行脚本,脚本采用退出码机制实现拦截/放行,与LLM的概率性完全解耦,保证100%的执行确定性。
3. Harness与其他层的协同:软硬结合,层层约束
Harness并非孤立存在,其与CLAUDE.md、Skills、Tools形成协同体系,实现「软约束引导+硬约束兜底」的分层控制,这也是Claude Code架构设计的智慧所在:
- CLAUDE.md(立法):告诉LLM「你应该这样做」,是prompt级的强建议,让LLM理解规则意图,主动配合;
- Harness(执法):告诉LLM「你必须这样做」,是代码级的强制约束,兜底防绕过,保证规则100%执行;
- Skills(知识):告诉LLM「该怎么做好」,是prompt模板的知识注入,让LLM按规范使用工具;
- Tools(操作):为LLM提供可调用的操作集,Harness对操作集做权限与拦截控制。
CLAUDE.md与Harness的核心差异对比:
| 维度 | CLAUDE.md | Harness Hook |
|---|---|---|
| 控制逻辑 | 你应该这样做 | 你必须这样做 |
| 控制力 | 建议(prompt级) | 强制(代码级) |
| 可绕过性 | 是(模型可能忘记/忽略) | 否(退出码硬拦截,100%生效) |
| 工程化定位 | 立法 | 执法 |
(四)Claude Code一次请求的完整执行流程
以「修复auth.py的登录bug」为例,结合核心文件与Harness的控制逻辑,梳理Claude Code一次请求的全链路执行流程,清晰看到Harness在其中的三次核心介入:
用户输入:修复auth.py的登录bug
Skills层:无特定命令,跳过
CLAUDE.md层:注入system prompt「调试用假设驱动+二分法」
Harness层-UserPromptSubmit:搜索auth.py相关代码,注入上下文
Claude Code层:拼装messages,调用claude_api_client.py请求API
循环:模型继续推理,重复「调用工具-Harness检查-执行工具」
Harness层-PreToolUse:检查命令安全性,放行
Tools层:执行Bash命令,返回搜索结果
Harness层-PostToolUse:压缩长结果,过滤冗余
模型推理完成:输出bug修复方案与总结,返回给用户
核心结论:Claude Code的每一次操作,都绕不开Harness的控制,Harness是整个应用的「守门人」,也是实现确定性控制的关键。
(五)Harness工程化落地的关键实现要点
作为架构师,在实现Harness时,需兼顾安全性、效率、成本、可维护性,以下为四大核心工程化实现要点:
- 双层保险原则:核心规则(如禁止rm -rf)必须同时配置在CLAUDE.md和Harness Hook中,软约束引导+硬约束兜底,保证100%合规;
- Hook脚本性能优化:Hook脚本理想执行时间<50ms,超过200ms用户会感知到卡顿,需避免在Hook中执行耗时操作(如大文件搜索);
- 模型路由成本优化:在Harness层实现模型路由策略,简单任务(如代码搜索、文件读取)调用小模型(Haiku),复杂推理(如bug修复、重构)调用大模型(Opus),可实现数量级的成本降低;
- 声明式配置优于命令式硬编码:将Harness的规则配置在settings.json/YAML等声明式配置文件中,与harness.py的核心逻辑解耦,支持热更新,无需重启服务即可修改规则。
四、总结与进展
(一)架构核心总结
Claude Code的架构设计,本质是为概率性的LLM搭建一套工程化的确定性控制体系,其核心亮点可总结为三句话:
- 分层解耦,层层赋能:七层架构从底层模型到顶层技能,每一层都有明确的职责,底层提供能力,中层实现扩展,顶层完成控制,解耦性强,可维护性高;
- 软硬结合,刚柔并济:以CLAUDE.md、Skills为软约束,实现意图引导;以Harness为硬约束,实现代码级强制,在灵活性与可控性之间找到最优平衡;
- 控制核心,落地关键:Harness不是一个简单的功能模块,而是Claude Code的控制灵魂,其四大机制+三大Hook,实现了对LLM的全链路确定性控制,也是AI Code工具从「实验室」走向「生产环境」的关键。
Claude Code核心组件的定位与本质,可通过一张表清晰理解:
| 组件 | 本质 | 控制力 | 架构类比 |
|---|---|---|---|
| Claude Model | 概率推理引擎 | 无 | 大脑 |
| Claude API | HTTP通信接口 | 无 | 神经 |
| Claude Code | Agent循环应用 | 执行层 | 身体 |
| Tools | 可调用的操作集 | 被动 | 手脚 |
| Harness | 控制面(Hooks+权限+会话) | 强制 | 方向盘+安全带 |
| CLAUDE.md | 写入prompt的规则集 | 强建议 | 宪法 |
| Skills | prompt模板集 | 建议 | 技能手册 |
(二)当前进展与未来方向
目前Claude Code的Harness层已实现基础控制能力 (Hooks、权限、上下文、会话管理),并在企业环境中落地了工程化增强特性:声明式配置、模型路由、成本预算、审计日志,成为AI Agent大规模使用的基础设施。
从架构师的视角,Claude Code及Harness的未来发展方向围绕**「更精准的控制、更低的成本、更灵活的扩展」**展开:
- Harness策略引擎化:将Harness从「控制机制集」升级为「策略引擎」,支持可视化配置规则、动态调整控制策略,降低开发者的使用门槛;
- 多模型协同的智能路由:在Harness层实现更智能的模型路由,结合任务复杂度、token消耗、执行效率做动态决策,实现成本与效果的最优平衡;
- Hook生态化:开放Harness的Hook接口,支持开发者自定义开发Hook脚本,形成生态化的控制规则库,适配不同行业、不同项目的个性化需求;
- 端到端的审计与溯源:在Harness层强化审计日志能力,实现对所有操作的端到端溯源,支持违规操作的回溯与分析,满足企业级的合规要求。
(三)给开发者的实践建议
根据不同的使用阶段,为Claude Code开发者提供针对性的Harness与架构实践建议,实现从「基础使用」到「极致定制」的进阶:
- 入门阶段:先写好CLAUDE.md,这是投入产出比最高的一步,无需懂代码,只需将项目规范、编码习惯、禁止事项写清楚,实现基础的软约束;
- 进阶阶段:学习settings.json的Hooks配置,从简单的PreToolUse Hook开始(如拦截高危Bash命令),体会「5行脚本胜过50行prompt规则」的确定性控制;
- 企业阶段:在Harness层建设策略引擎,实现声明式配置、模型路由、成本预算、审计日志的一体化,将Harness打造成AI Agent大规模落地的核心基础设施。
后记
AI工程化的核心,从来不是让模型变得更强,而是让对模型的控制变得更精准。Claude Code的架构设计,尤其是Harness层的确定性控制体系,为LLM的工程化落地提供了一个优秀的参考范式。
在LLM时代,开发者不仅要学会使用AI工具,更要理解其底层架构,掌握「用代码约束模型」的能力。而Harness作为Claude Code的隐藏Boss,正是我们解锁AI Code工具极致能力的关键钥匙。