
前言
上一篇我们已经详细讲解了RAG的总体流程和第一步:文件解析
那么接下来我们来深入研究文本分片与向量化
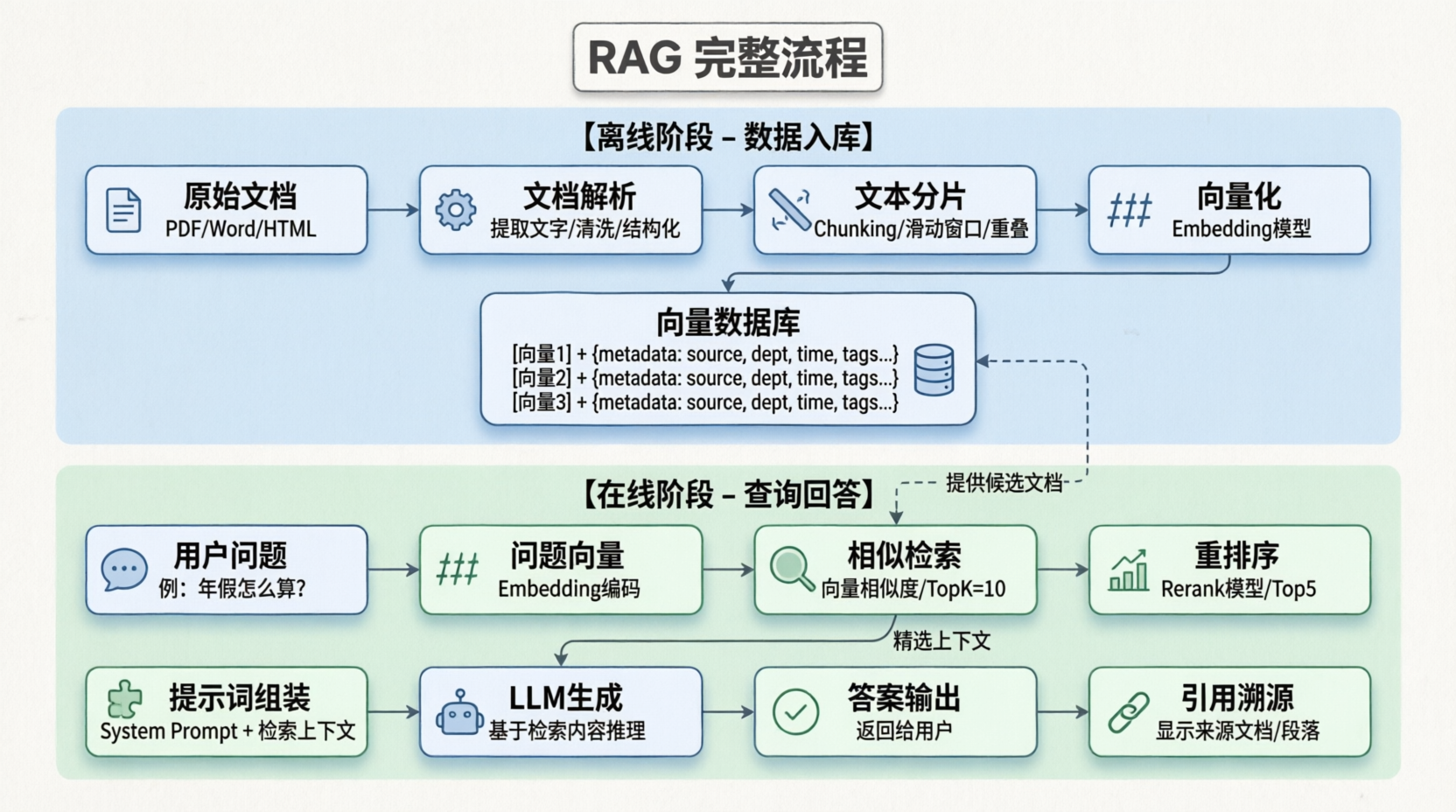
一、为什么要分片(Chunking)?
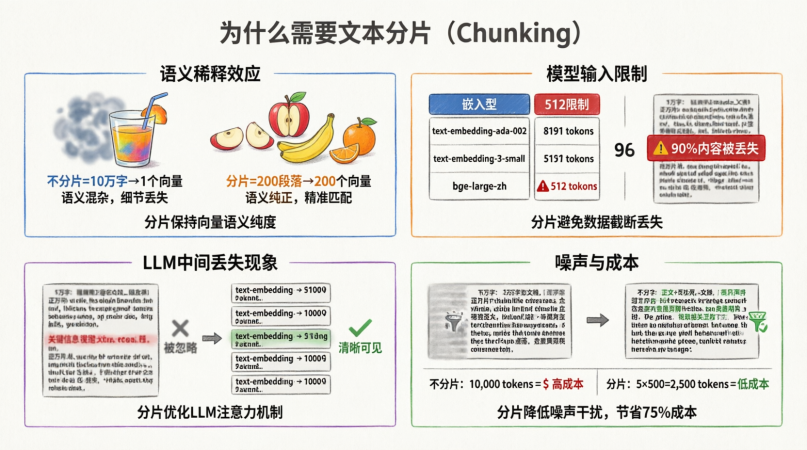
1.1 向量语义的"稀释效应" (Semantic Dilution)
原理 :Embedding 模型将文本映射为一个固定长度的向量(如 1536 维)。这个向量本质上是文本所有语义的加权平均。
- 场景 A(不分片) :一本 10 万字的员工手册 -> 1 个向量。
- 结果:这个向量代表了"手册的整体氛围",但丢失了"年假具体几天"的细节。向量空间中的位置会偏向"中心",与任何具体问题的相似度都不高。
- 比喻:把"苹果、香蕉、橘子、冰箱、电视"全部榨成一杯果汁。你再也尝不出苹果的味道了。
- 场景 B(分片) :手册切成 200 个段落 -> 200 个向量。
- 结果:其中有一个向量专门代表"年假政策"。当用户问"年假"时,能精准匹配到这个向量。
- 比喻:水果切块。想吃苹果就捞苹果块。
结论 :分片是为了保持向量语义的纯度 (Semantic Purity)。文本越短,向量代表的意图越单一,检索越精准。
1.2 Embedding 模型的输入硬限制 (Input Limit)
事实:所有的 Embedding 模型都有最大输入长度限制。
| 模型 | 最大输入 Tokens | 后果 |
|---|---|---|
| text-embedding-ada-002 | 8191 | 超过部分会被截断 (Truncated) |
| text-embedding-3-small | 8191 | 超过部分会被截断 |
| bge-large-zh | 512 | 超过部分会被截断 (注意!很多中文模型限制较小) |
风险:如果你不分片,直接送入 1 万字的文档给限制 512 的模型:
- 报错:API 直接返回 Error。
- 静默失败:模型只计算前 512 个 Token,后面 9000 字完全被忽略。你的知识库实际上丢失了 90% 的内容。
结论 :分片是为了适配模型物理限制,防止数据丢失。
1.3 LLM 的"中间丢失"现象 (Lost in the Middle)
研究发现 :LLM 在处理长上下文时,对开头 和结尾 的信息记忆最深,对中间的信息容易忽略。
- 不分片 :检索返回 5 万字的文档给 LLM。关键信息在第 2 万字处。
- 结果:LLM 大概率忽略关键信息,产生幻觉。
- 分片 :检索返回 5 个 1000 字的片段。关键信息在某一片段的开头。
- 结果:LLM 能清晰看到关键信息。
结论 :分片是为了优化 LLM 的注意力机制,提高生成质量。
1.4 噪声抑制与成本 (Noise & Cost)
- 噪声:文档中包含大量无关内容(页眉、页脚、免责声明)。不分片会将噪声与正文一起向量化,干扰检索。
- 成本 :LLM 按 Token 收费。
- 不分片:每次问答输入 10,000 Tokens -> 成本高,速度慢。
- 分片:每次问答输入 5 x 500 Tokens = 2,500 Tokens -> 成本低,速度快
二、主流分片策略
我们将策略分为naive (朴素)、 heuristic (启发式)和 semantic (语义式)三类。
2.1 固定长度分片 (Fixed-Size Chunking)
算法逻辑:
python
def fixed_chunk(text, size):
return [text[i:i+size] for i in range(0, len(text), size)]深度分析:
- 优点:计算复杂度 O(n),速度最快,实现最简单。
- 缺点 : 语义破坏者 。
- 例子 :
size=10。文本"我喜欢吃苹果"。 - 切片 1:"我喜欢吃"
- 切片 2:"苹果"
- 如果用户搜"喜欢吃苹果",向量匹配度会下降,因为语义被切断了。
- 中文灾难:可能在汉字中间切断(如果是按字节),或在词语中间切断。
- 例子 :
- 适用场景 : 几乎不推荐用于 RAG。仅适用于日志分析或对语义不敏感的场景。
2.2 递归字符分片 (Recursive Character Chunking) ------ 工业界标准
算法逻辑 : 维护一个分隔符列表 separators = ["\n\n", "\n", " ", ""]。
- 尝试用
separators[0](\n\n) 分割文本。 - 如果分割后的片段长度 <=
chunk_size,保留。 - 如果片段长度 >
chunk_size,对该片段递归使用separators[1](\n) 分割。 - 以此类推,直到用完所有分隔符。
- 如果最后还太大,强制按字符切断。
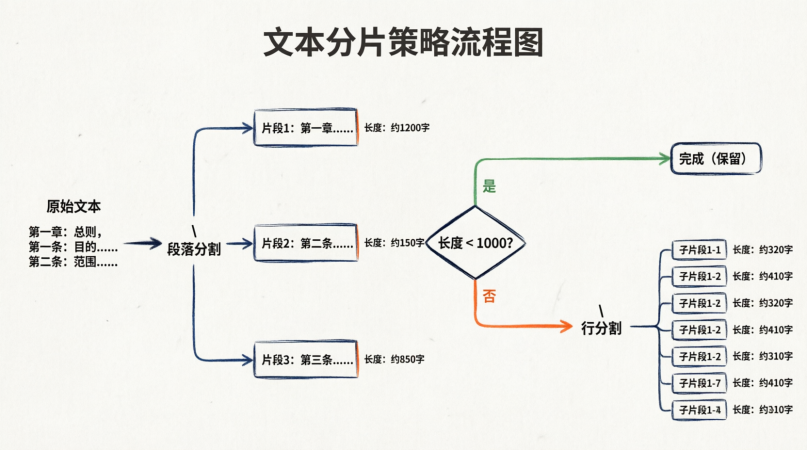
深度分析:
- 优点 : 语义保持最好。优先保留段落,其次保留句子。符合人类阅读习惯。
- 缺点:计算稍慢(递归),需要调整分隔符列表。
- 适用场景 : 90% 的通用 RAG 场景(文档、手册、文章)。
- Spring AI 实现 :
RecursiveCharacterTextSplitter。
2.3 语义分片 (Semantic Chunking)
算法逻辑:
- 将文本按句子分割。
- 计算每个句子的 Embedding。
- 计算相邻句子的余弦相似度。
- 如果相似度低于阈值(如 0.5),说明语义发生了跳跃,在此处切断。
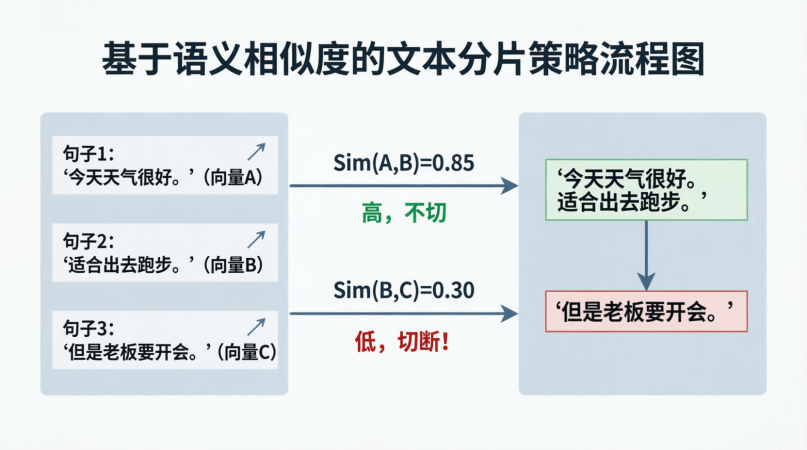
深度分析:
- 优点 : 语义连贯性最强。保证每个 Chunk 内部话题一致。
- 缺点 : 成本极高。需要预先计算所有句子的 Embedding。如果文档更新,需要重新计算所有。
- 适用场景: 高质量知识库、对精度要求极高、预算充足的场景。
- Spring AI 实现 :需自定义
DocumentTransformer实现此逻辑。
2.4 父子分片 (Parent-Child / Small-to-Big)
算法逻辑: 建立两层索引。
- Parent Chunk:大块文本(如 2000 字),包含完整上下文。
- Child Chunk:小块文本(如 200 字),用于检索。
- 关联:Child 记录 Parent 的 ID。
检索流程:
- 用户查询 -> 匹配到 Child Chunk (因为小,向量准)。
- 系统通过 ID 找到对应的 Parent Chunk。
- 将 Parent Chunk 发送给 LLM 生成答案。
深度分析:
- 优点 : 解决了"检索准"与"上下文足"的矛盾。检索用小块(精准),生成用大块(完整)。
- 缺点:存储成本增加(存两份),逻辑复杂。
- 适用场景: 复杂文档、法律合同、技术文档(需要上下文才能理解)。
- Spring AI 实现 :需在 Metadata 中维护
parent_id映射。
2.5 结构感知分片 (Structure-Aware Chunking)
算法逻辑: 根据文件本身的结构标记进行切分。
- Markdown :按
#,##,###标题切分。 - Code :按
class,function,def切分。 - HTML :按
<p>,<div>,<table>标签切分。
深度分析:
- 优点:天然符合文档逻辑。代码检索必用。
- 缺点:依赖文件格式解析器的质量。
- 适用场景: 代码库检索 (Code RAG)、技术文档 (Markdown)。
- Spring AI 实现 :
MarkdownTextSplitter,LanguageSpecificSplitter。
三、分片参数调优物理课
这是最核心的部分。参数不是拍脑袋决定的,是有物理意义的。
3.1 Chunk Size (分片大小)
单位陷阱:
- Characters (字符):Spring AI 默认单位。中文 1 字=1 字符。
- Tokens (词元):LLM 和 Embedding 模型的实际计算单位。
- 换算率 :
- 英文:1 Token ≈ 4 字符。
- 中文:1 Token ≈ 1.5 字符 (约 0.6-0.8 个汉字)。
- 警告 :如果你设置
chunk_size=1000(字符),对于 Embedding 模型可能是 600 Tokens,对于 LLM 可能是 600 Tokens。但如果模型限制是 512 Tokens,你就超了!
调优指南:
| 场景 | 推荐 Size (字符) | 推荐 Size (Tokens) | 物理依据 |
|---|---|---|---|
| FAQ / 问答对 | 256 - 512 | 100 - 250 | 问题通常很短,需要精准匹配,避免噪声。 |
| 通用文档 | 512 - 1024 | 250 - 500 | 平衡点。既能容纳完整段落,又不至于语义稀释。 |
| 法律/合同 | 1024 - 2048 | 500 - 1000 | 条款之间逻辑紧密,需要更多上下文才能理解。 |
| 代码文件 | 512 - 1024 | 250 - 500 | 按函数切分,通常一个函数在这个范围。 |
调优方法:
- 下限:不能小于 Embedding 模型的最小有效输入(通常无限制,但太短无意义)。
- 上限:不能超过 Embedding 模型的最大输入(如 512/8191 Tokens)。
- 测试 :如果检索结果太碎(只返回半句话),调大 。如果检索结果包含太多无关段落,调小。
3.2 Chunk Overlap (重叠大小)
物理意义 :防止边界效应 (Boundary Effect)。
Chunk重叠的核心原因主要是我们的文件的内容被分割,导致关键词被分割成俩部分,导致语义被破坏使得我们prompt的相似度太低,从而降低检索质量

调优指南:
- 推荐比例 :Chunk Size 的 10% - 20%。
- 示例:Size=1000, Overlap=200。
- 极端情况 :
- 如果文档中有很多跨段落的引用(如"见上文"),增大 Overlap 到 30%。
- 如果存储成本敏感,减小 Overlap 到 10%。
- 警告:Overlap 太大会导致向量库冗余,检索时出现大量重复内容,干扰 LLM。
3.3 Separators (分隔符优先级)
物理意义:定义"语义单元"的边界。
英文默认 :["\n\n", "\n", " ", ""] 中文优化:中文没有空格,必须加入标点符号。
推荐中文分隔符列表:
java
List.of(
"\n\n", // 1. 段落 (最高优先级)
"\n", // 2. 换行
"。", "!", "?", // 3. 句子结束 (中文特有)
";", ";", // 4. 分句
",", ",", // 5. 逗号
" ", // 6. 空格 (兼容英文)
"" // 7. 强制字符 (保底)
)调优技巧:
- 如果文档是代码 :优先按
\n,{,}分。 - 如果文档是Markdown :优先按
#,##,\n\n分。 - 如果文档是日志 :优先按
\n(行) 分。
四、分片调优方法论 (Methodology)
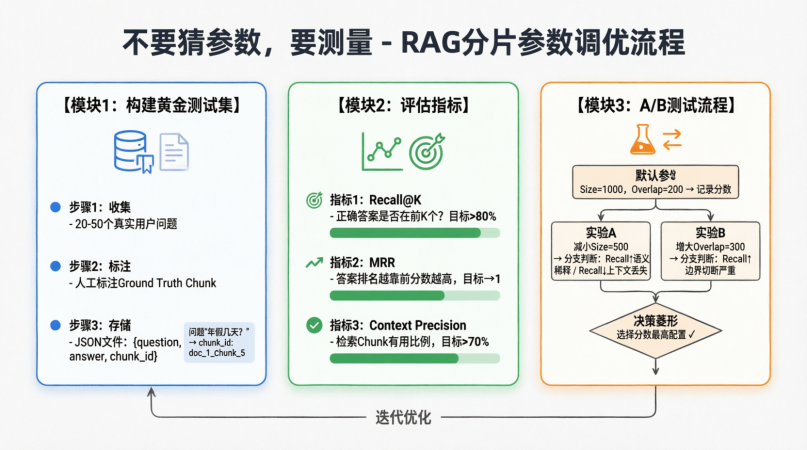
不要猜参数,要测量。
4.1 构建黄金测试集 (Golden Dataset)
这是调优的基石。
- 收集:挑选 20-50 个真实用户问题。
- 标注 :人工阅读文档,标注出每个问题对应的正确文档片段 (Ground Truth Chunk) 。
- 问题:"年假几天?" -> 正确 Chunk ID:
doc_1_chunk_5
- 问题:"年假几天?" -> 正确 Chunk ID:
- 存储:保存为 JSON 文件。
4.2 评估指标 (Metrics)
运行不同的分片参数配置,对比以下指标:
- Recall@K (召回率) :
- 定义:正确答案所在的 Chunk,是否出现在检索结果的前 K 个中?
- 公式:
正确命中的问题数 / 总问题数 - 目标:> 80%
- MRR (平均倒数排名) :
- 定义:正确答案排得越靠前,分数越高。
- 目标:越接近 1 越好。
- Context Precision (上下文精度) :
- 定义:检索到的 Chunk 中,有多少比例是真正有用的?
- 目标:> 70%
4.3 A/B 测试流程
- baseline:使用默认参数 (Size=1000, Overlap=200)。运行测试集,记录分数。
- 实验 A :减小 Size (500)。运行测试集。
- 如果 Recall 上升 -> 说明之前太大,语义稀释。
- 如果 Recall 下降 -> 说明之前合适,现在太碎,上下文丢失。
- 实验 B :增大 Overlap (300)。运行测试集。
- 如果 Recall 上升 -> 说明之前边界切断严重。
- 决策:选择分数最高的配置。
总结
本文咱们介绍了chunking的原因、策略和调优等,chunking是我们工程化agent项目中必须考虑的问题!下一篇我们讲解:Embedding!
