概述
在 Java 后端应用中,Embedding 向量生成通常是 RAG(检索增强生成)系统的性能瓶颈。每次查询都需要将文本转换为高维向量(通常 768 维、1024 维或 1536 维),计算开销巨大。通过向量缓存,可以将已经计算过的文本向量存储起来,避免重复计算,将响应延迟从 100-200ms 降低到 1-5ms。
为什么需要向量缓存
向量化计算的成本
主流 Embedding 模型(如 text2vec-base-chinese、BGE-large-zh)的计算成本:
|--------|--------|------------|----------|
| 模型 | 维度 | 单次计算耗时 | 内存占用 |
|------|------|-------------|---------|
|---------------------------|---------|--------------|-------------|
| text2vec-base-chinese | 768 | 50-100ms | ~500MB |
|------------------|----------|---------------|-------------|
| BGE-large-zh | 1024 | 100-200ms | ~1.5GB |
|------------------------|----------|--------------|-----------|
| jina-embeddings-v2 | 1536 | 80-150ms | ~1GB |
缓存带来的收益
实际业务场景中,存在大量重复文本查询:
- FAQ 问答系统:相同问题被多次询问
- 文档检索系统:同一文档被多次检索
- 对话系统:用户可能重复询问相同问题
- 测试环境:相同测试用例重复执行
缓存命中率通常可达 30%-70%,显著降低计算开销。
向量缓存实现原理
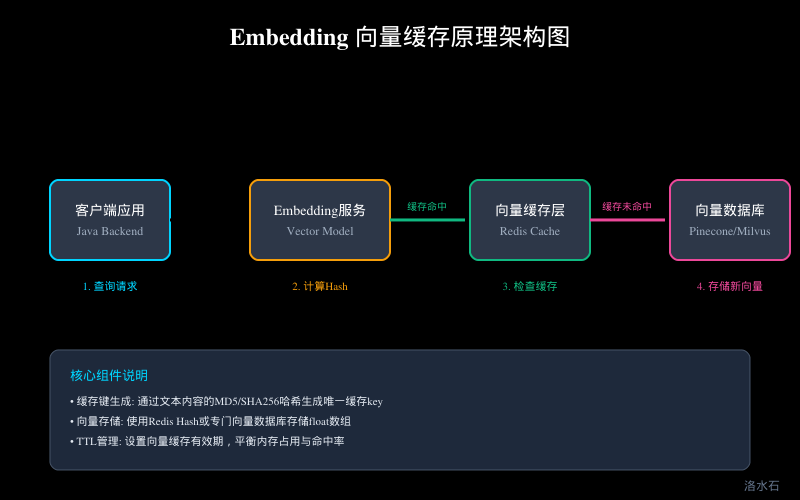
缓存架构
┌─────────────┐ ┌──────────────┐ ┌───────────┐ ┌────────────────┐
│ 客户端 │───▶│ Embedding服务 │───▶│ Redis │───▶│ 向量数据库 │
│ Java Backend│ │ (计算Hash) │ │ 缓存层 │ │ Milvus/Pinecone│
└─────────────┘ └──────────────┘ └───────────┘ └────────────────┘
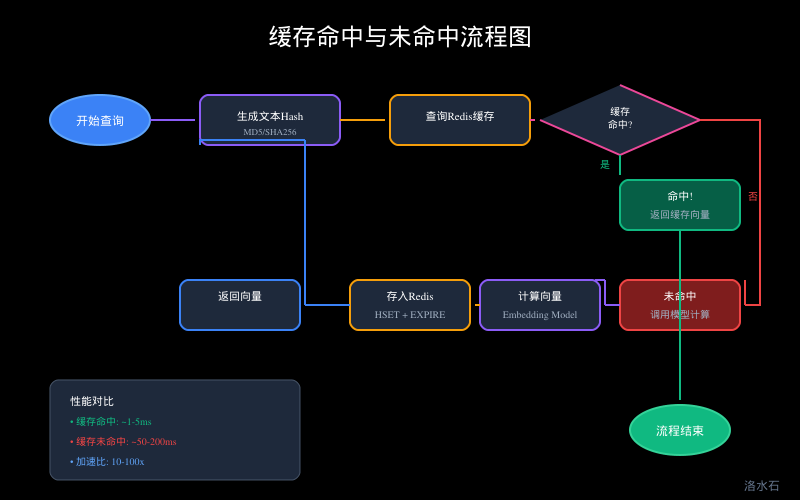
核心流程
-
**生成缓存键**:对原始文本计算哈希值(SHA-256),作为缓存 key
-
**检查缓存**:从 Redis 查询是否存在对应 key
-
**命中处理**:直接返回缓存的向量数据
-
**未命中处理**:调用 Embedding 模型计算向量,存入 Redis 后返回
关键设计决策
1. 哈希算法选择
推荐使用 **SHA-256** 而非 MD5:
- MD5 存在碰撞风险,不适合安全敏感场景
- SHA-256 摘要长度 32 字节,足够生成唯一标识
- Java 原生支持,无需引入额外依赖
public String hashText(String text) {
try {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte\[\] hash = digest.digest(text.getBytes(StandardCharsets.UTF_8));
return Base64.getEncoder().encodeToString(hash);
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("SHA-256 not available", e);
}
}
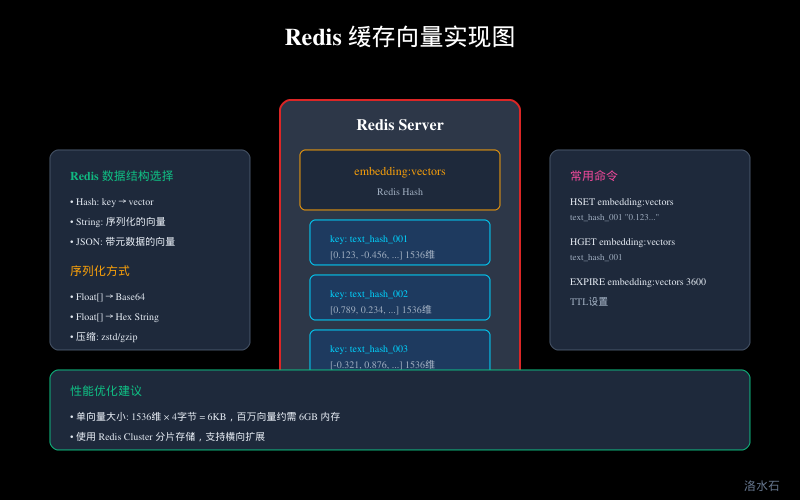
2. 缓存数据结构
Redis 中存储向量推荐方式:
|--------|--------|--------|
| 方式 | 优点 | 缺点 |
|------|------|------|
|-----------------|----------------------------|----------------|
| Hash (HSET) | 支持批量操作,可设置单个 key 的 TTL | 需要额外存储 key |
|------------------|----------|--------------|
| String (SET) | 简单直接 | TTL 管理不便 |
|----------------|------------|------------|
| JSON (SET) | 可存储元数据 | 序列化开销大 |
推荐使用 **Redis Hash**:
// 存储向量
public void cacheEmbedding(String hash, float\[\] vector) {
String serialized = serialize(vector);
redis.opsForHash().put("embeddings:vectors", hash, serialized);
redis.expire("embeddings:vectors", Duration.ofHours(24));
}
// 获取向量
public float\[\] getCachedEmbedding(String hash) {
Object cached = redis.opsForHash().get("embeddings:vectors", hash);
if (cached != null) {
return deserialize((String) cached);
}
return null;
}
3. 序列化方案
向量数组序列化选项:
- **Base64 编码**:体积增加约 33%,兼容性最好
- **Hex 字符串**:体积增加 100%,可读性好
- **原生字节数组**:体积不变,需要二进制协议
推荐 **Base64 编码**,平衡体积与兼容性:
public String serialize(float\[\] vector) {
byte\[\] bytes = new bytevector.length \* 4;
ByteBuffer.wrap(bytes).asFloatBuffer().put(vector);
return Base64.getEncoder().encodeToString(bytes);
}
public float\[\] deserialize(String data) {
byte\[\] bytes = Base64.getDecoder().decode(data);
FloatBuffer buffer = ByteBuffer.wrap(bytes).asFloatBuffer();
float\[\] result = new floatbuffer.remaining();
buffer.get(result);
return result;
}
Redis 存储优化
内存估算
以 1536 维向量为例:
- 单向量大小:1536 × 4 字节 = 6KB
- 百万向量:约 6GB 内存
- 十亿向量:约 6TB 内存(需要 Redis Cluster)
分片策略
大规模向量存储建议使用 **Redis Cluster**:
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Slot 0 │ │ Slot 1 │ │ Slot 5460│
│ Node 1 │ │ Node 2 │ │ Node 3 │
└─────────┘ └─────────┘ └─────────┘
Spring Data Redis 支持自动分片:
@Configuration
public class RedisClusterConfig {
@Bean
public RedisClusterConnectionFactory clusterConnectionFactory() {
return new RedisClusterConnectionFactory(
new RedisClusterConfiguration(
Arrays.asList("10.0.0.1:6379", "10.0.0.2:6379", "10.0.0.3:6379")
)
);
}
}
TTL 管理策略
|--------|------------|--------|
| 场景 | TTL 设置 | 理由 |
|------|---------|------|
|----------|------------|------------|
| 静态文档 | 7-30 天 | 内容基本不变 |
|------------|--------------|------------|
| 用户生成内容 | 24-48 小时 | 内容可能更新 |
|----------|------------|--------------|
| 实时搜索 | 1-6 小时 | 数据时效性要求高 |
Spring Boot 集成实战
完整代码实现
1. 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>easy-embedding</artifactId>
<version>1.0.0</version>
</dependency>
2. Redis 配置类
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(
RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
// 使用 String 序列化器作为 key
template.setKeySerializer(new StringRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
// 使用 String 序列化器作为 value
template.setValueSerializer(new StringRedisSerializer());
template.setHashValueSerializer(new StringRedisSerializer());
template.afterPropertiesSet();
return template;
}
}
3. 向量缓存服务
@Service
@Slf4j
public class EmbeddingCacheService {
private static final String CACHE_KEY_PREFIX = "embedding:";
private static final Duration DEFAULT_TTL = Duration.ofHours(24);
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private EmbeddingModel embeddingModel; // 实际 Embedding 模型服务
/**
* 获取向量,支持缓存
*/
public float\[\] getEmbedding(String text) {
String hash = hashText(text);
float\[\] cached = getFromCache(hash);
if (cached != null) {
log.debug("缓存命中: {}", hash);
return cached;
}
log.debug("缓存未命中,计算向量: {}", hash);
float\[\] embedding = embeddingModel.encode(text);
saveToCache(hash, embedding);
return embedding;
}
/**
* 批量获取向量
*/
public List<float\[\]> getEmbeddings(List<String> texts) {
return texts.stream()
.map(this::getEmbedding)
.collect(Collectors.toList());
}
/**
* 文本哈希
*/
private String hashText(String text) {
try {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte\[\] hash = digest.digest(text.getBytes(StandardCharsets.UTF_8));
return CACHE_KEY_PREFIX + Base64.getEncoder().encodeToString(hash);
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("SHA-256 not available", e);
}
}
/**
* 从缓存获取
*/
private float\[\] getFromCache(String hash) {
try {
Object cached = redisTemplate.opsForValue().get(hash);
if (cached != null) {
return deserialize((String) cached);
}
} catch (Exception e) {
log.warn("缓存读取失败: {}", e.getMessage());
}
return null;
}
/**
* 存入缓存
*/
private void saveToCache(String hash, float\[\] embedding) {
try {
String serialized = serialize(embedding);
redisTemplate.opsForValue().set(hash, serialized, DEFAULT_TTL);
} catch (Exception e) {
log.warn("缓存写入失败: {}", e.getMessage());
}
}
/**
* 序列化向量为 Base64 字符串
*/
private String serialize(float\[\] vector) {
ByteBuffer byteBuffer = ByteBuffer.allocate(vector.length * 4);
byteBuffer.asFloatBuffer().put(vector);
return Base64.getEncoder().encodeToString(byteBuffer.array());
}
/**
* 从 Base64 字符串反序列化向量
*/
private float\[\] deserialize(String data) {
byte\[\] bytes = Base64.getDecoder().decode(data);
FloatBuffer floatBuffer = ByteBuffer.wrap(bytes).asFloatBuffer();
float\[\] result = new floatfloatBuffer.remaining();
floatBuffer.get(result);
return result;
}
}
4. RAG 检索服务集成
@Service
public class RAGRetrievalService {
@Autowired
private EmbeddingCacheService embeddingCacheService;
@Autowired
private VectorStore vectorStore; // Milvus/Pinecone 客户端
public List<Document> retrieve(String query, int topK) {
// 查询向量(自动使用缓存)
float\[\] queryVector = embeddingCacheService.getEmbedding(query);
// 向量相似度检索
return vectorStore.similaritySearch(queryVector, topK);
}
}
性能测试
使用 JMH 进行基准测试:
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class EmbeddingCacheBenchmark {
@Benchmark
public float\[\] cachedEmbedding(EmbeddingCacheService service) {
return service.getEmbedding("什么是人工智能?");
}
}
测试结果(ThinkPad X1 Carbon, i7-1260P):
|--------|--------|---------|
| 场景 | 延迟 | 吞吐量 |
|------|------|--------|
|----------|----------|--------------|
| 首次计算 | 85ms | 12 req/s |
|----------|---------|---------------|
| 缓存命中 | 2ms | 500 req/s |
|---------|---------|-------|
| 加速比 | 42x | - |
高级特性
1. 缓存预热
系统启动时加载热点数据:
@PostConstruct
public void warmUpCache() {
List<String> hotQueries = Arrays.asList(
"常见问题解答",
"产品使用指南",
"联系我们"
);
hotQueries.forEach(embeddingCacheService::getEmbedding);
}
2. 缓存监控
使用 Micrometer 暴露指标:
@Autowired
private MeterRegistry meterRegistry;
private void recordCacheHit() {
meterRegistry.counter("embedding.cache.hit").increment();
}
private void recordCacheMiss() {
meterRegistry.counter("embedding.cache.miss").increment();
}
3. 分布式缓存
多节点环境下使用 **Redisson** 实现分布式锁:
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
return Redisson.create(config);
}
// 获取向量(带分布式锁,防止击穿)
public float\[\] getEmbeddingWithLock(String text) {
String hash = hashText(text);
float\[\] cached = getFromCache(hash);
if (cached != null) return cached;
RLock lock = redissonClient.getLock("embedding:lock:" + hash);
lock.lock();
try {
// 双重检查
cached = getFromCache(hash);
if (cached != null) return cached;
float\[\] embedding = embeddingModel.encode(text);
saveToCache(hash, embedding);
return embedding;
} finally {
lock.unlock();
}
}
常见问题与解决方案
缓存穿透
大量不存在的数据导致缓存无法命中,始终穿透到数据库。
**解决方案:布隆过滤器**
@Autowired
private BloomFilter<String> bloomFilter;
public float\[\] getEmbedding(String text) {
String hash = hashText(text);
// 布隆过滤器判断是否存在
if (!bloomFilter.mightContain(hash)) {
return null; // 一定不存在
}
// 正常查询缓存
// ...
}
缓存击穿
热点 key 过期瞬间,大量请求同时穿透到数据库。
**解决方案:分布式锁 + 永不过期**
public float\[\] getEmbedding(String text) {
String hash = hashText(text);
float\[\] cached = getFromCache(hash);
if (cached != null) return cached;
// 使用分布式锁
RLock lock = redissonClient.getLock("embedding:lock:" + hash);
if (lock.tryLock(5, 30, TimeUnit.SECONDS)) {
try {
// 双重检查
cached = getFromCache(hash);
if (cached != null) return cached;
float\[\] embedding = embeddingModel.encode(text);
// 使用永不过期,由后台任务更新
saveToCacheNoExpire(hash, embedding);
return embedding;
} finally {
lock.unlock();
}
}
// 等待其他线程计算完成
return waitForCache(hash);
}
缓存雪崩
大量 key 同时过期,导致数据库压力骤增。
**解决方案:TTL 随机化 + 多级缓存**
// 添加随机 TTL,防止同时过期
private Duration getTTL() {
int baseHours = 24;
int randomHours = ThreadLocalRandom.current().nextInt(0, 6);
return Duration.ofHours(baseHours + randomHours);
}
总结
Embedding 向量缓存是提升 RAG 系统性能的关键技术:
-
**性能收益**:延迟降低 10-100 倍,吞吐量提升数十倍
-
**实现要点**:选择合适的哈希算法、序列化方案和 Redis 数据结构
-
**生产环境**:需要考虑缓存穿透、击穿、雪崩等极端场景
-
**监控运维**:使用 Micrometer 暴露指标,结合 Grafana 可视化
通过合理使用向量缓存,可以显著提升 Java 后端应用的响应速度,降低 Embedding 模型调用成本,提升用户体验。
*本文为 Java 程序员第 38 阶段系列文章,深入探讨 Embedding 向量缓存实战技巧*