Spring AI Alibaba + Ollama+Embedding向量化项目完整指南
SpringBoot+LangChain4j+Ollama+RAG(检索增强生成)实现私有文档向量化检索回答:
https://blog.csdn.net/badao_liumang_qizhi/article/details/160443735
Spring AI Alibaba + Ollama Function Calling 项目完整指南:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/161597924
基于上述示例,在此基础上添加**文本向量化(Embedding)**功能。
注:
实现
1. 修改 application.yml --- 添加 Embedding 模型配置
server:
port: 885
logging:
level:
com.badao: debug
org.springframework.ai: debug
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: qwen2.5
temperature: 0.7
embedding:
options:
model: nomic-embed-text⚠️ 注意:你需要先在 Ollama 中拉取 embedding 模型,执行:
bashollama pull nomic-embed-text也可以换成其他 embedding 模型,如
bge-m3、mxbai-embed-large等。
2. 新建 EmbeddingService --- 文本向量化服务
java
package com.badao.ai.service;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Service
public class EmbeddingService {
private final EmbeddingModel embeddingModel;
public EmbeddingService(EmbeddingModel embeddingModel) {
this.embeddingModel = embeddingModel;
}
/**
* 将单段文本转换为向量(浮点数组)
*/
public float[] embed(String text) {
return embeddingModel.embed(text);
}
/**
* 将多段文本批量转换为向量,返回完整响应
*/
public EmbeddingResponse embedForResponse(List<String> texts) {
return embeddingModel.embedForResponse(texts);
}
/**
* 计算两段文本的余弦相似度
*/
public double cosineSimilarity(String text1, String text2) {
float[] vec1 = embed(text1);
float[] vec2 = embed(text2);
return cosineSimilarity(vec1, vec2);
}
/**
* 计算两个向量的余弦相似度
*/
public static double cosineSimilarity(float[] vec1, float[] vec2) {
double dotProduct = 0.0;
double norm1 = 0.0;
double norm2 = 0.0;
for (int i = 0; i < vec1.length; i++) {
dotProduct += vec1[i] * vec2[i];
norm1 += vec1[i] * vec1[i];
norm2 += vec2[i] * vec2[i];
}
if (norm1 == 0 || norm2 == 0) {
return 0.0;
}
return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));
}
/**
* 批量文本相似度分析:返回两两之间的相似度矩阵
*/
public Map<String, Object> batchSimilarity(List<String> texts) {
int n = texts.size();
List<float[]> vectors = new ArrayList<>();
for (String text : texts) {
vectors.add(embed(text));
}
List<List<Double>> matrix = new ArrayList<>();
for (int i = 0; i < n; i++) {
List<Double> row = new ArrayList<>();
for (int j = 0; j < n; j++) {
if (i == j) {
row.add(1.0);
} else {
row.add(cosineSimilarity(vectors.get(i), vectors.get(j)));
}
}
matrix.add(row);
}
return Map.of(
"texts", texts,
"dimension", vectors.get(0).length,
"similarityMatrix", matrix
);
}
}3. 新建 EmbeddingController --- REST API 控制器
java
package com.badao.ai.controller;
import com.badao.ai.service.EmbeddingService;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
@RestController
public class EmbeddingController {
private final EmbeddingService embeddingService;
public EmbeddingController(EmbeddingService embeddingService) {
this.embeddingService = embeddingService;
}
/**
* 单文本向量化
*/
@GetMapping("/ai/embed")
public Map<String, Object> embed(@RequestParam(value = "text", defaultValue = "Hello World") String text) {
float[] vector = embeddingService.embed(text);
return Map.of(
"text", text,
"dimension", vector.length,
"vectorPreview", previewVector(vector, 10)
);
}
/**
* 两文本相似度计算
*/
@PostMapping("/ai/embed/similarity")
public Map<String, Object> similarity(@RequestBody Map<String, String> request) {
String text1 = request.getOrDefault("text1", "");
String text2 = request.getOrDefault("text2", "");
float[] vec1 = embeddingService.embed(text1);
float[] vec2 = embeddingService.embed(text2);
double similarity = EmbeddingService.cosineSimilarity(vec1, vec2);
return Map.of(
"text1", text1,
"text2", text2,
"similarity", Math.round(similarity * 10000.0) / 100.0,
"dimension", vec1.length
);
}
/**
* 批量文本相似度分析
*/
@PostMapping("/ai/embed/batch-similarity")
public Map<String, Object> batchSimilarity(@RequestBody Map<String, Object> request) {
@SuppressWarnings("unchecked")
List<String> texts = (List<String>) request.get("texts");
if (texts == null || texts.isEmpty()) {
texts = List.of("苹果", "香蕉", "电脑", "笔记本");
}
return embeddingService.batchSimilarity(texts);
}
/**
* 批量文本向量化(完整响应)
*/
@PostMapping("/ai/embed/batch")
public Map<String, Object> batchEmbed(@RequestBody Map<String, Object> request) {
@SuppressWarnings("unchecked")
List<String> texts = (List<String>) request.get("texts");
if (texts == null || texts.isEmpty()) {
texts = List.of("Hello", "World");
}
EmbeddingResponse response = embeddingService.embedForResponse(texts);
List<Map<String, Object>> results = response.getResults().stream()
.map(r -> Map.<String, Object>of(
"index", r.getIndex(),
"dimension", r.getOutput().size(),
"vectorPreview", previewVector(toFloatArray(r.getOutput()), 10)
))
.toList();
return Map.of(
"texts", texts,
"model", "ollama-nomic-embed-text",
"results", results
);
}
private static List<Float> previewVector(float[] vector, int maxElements) {
int limit = Math.min(vector.length, maxElements);
List<Float> preview = new java.util.ArrayList<>();
for (int i = 0; i < limit; i++) {
preview.add(Math.round(vector[i] * 10000f) / 10000f);
}
return preview;
}
private static float[] toFloatArray(List<Double> list) {
float[] arr = new float[list.size()];
for (int i = 0; i < list.size(); i++) {
arr[i] = list.get(i).floatValue();
}
return arr;
}
}4. 新建 embedding-test.html --- 前端可视化测试页面
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>文本向量化 (Embedding) 测试</title>
<style>
* { margin: 0; padding: 0; box-sizing: border-box; }
body {
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
background: linear-gradient(135deg, #0f2027 0%, #203a43 50%, #2c5364 100%);
min-height: 100vh;
display: flex;
justify-content: center;
padding: 20px;
}
.container {
max-width: 900px;
width: 100%;
}
h1 {
color: #fff;
text-align: center;
margin-bottom: 5px;
font-size: 28px;
}
.subtitle {
color: #aaa;
text-align: center;
margin-bottom: 25px;
font-size: 14px;
}
.card {
background: rgba(255,255,255,0.05);
backdrop-filter: blur(10px);
border: 1px solid rgba(255,255,255,0.1);
border-radius: 16px;
padding: 25px;
margin-bottom: 20px;
}
.card h2 {
color: #4fc3f7;
margin-bottom: 15px;
font-size: 18px;
}
.section-label {
color: #aaa;
font-size: 13px;
margin-bottom: 8px;
}
textarea, input[type="text"] {
width: 100%;
padding: 14px;
background: rgba(255,255,255,0.08);
border: 1px solid rgba(255,255,255,0.2);
border-radius: 10px;
color: #e0e0e0;
font-size: 15px;
resize: vertical;
font-family: inherit;
transition: border-color 0.3s;
}
textarea:focus, input:focus {
outline: none;
border-color: #4fc3f7;
}
textarea { min-height: 70px; }
.row {
display: flex;
gap: 12px;
}
.row > div { flex: 1; }
button {
background: linear-gradient(135deg, #4fc3f7 0%, #0288d1 100%);
color: white;
border: none;
padding: 14px 30px;
border-radius: 10px;
font-size: 15px;
cursor: pointer;
transition: transform 0.2s, opacity 0.2s;
margin-top: 12px;
}
button:hover { transform: translateY(-2px); }
button:active { transform: translateY(0); }
button:disabled { opacity: 0.5; cursor: not-allowed; }
.btn-outline {
background: transparent;
border: 2px solid #4fc3f7;
color: #4fc3f7;
}
.btn-outline:hover {
background: rgba(79,195,247,0.15);
}
.btn-row {
display: flex;
gap: 10px;
flex-wrap: wrap;
}
.quick-btn {
background: rgba(79,195,247,0.15);
border: 1px solid rgba(79,195,247,0.3);
color: #4fc3f7;
padding: 8px 14px;
border-radius: 8px;
cursor: pointer;
font-size: 13px;
transition: all 0.3s;
}
.quick-btn:hover {
background: rgba(79,195,247,0.3);
border-color: #4fc3f7;
}
.result-box {
background: rgba(0,0,0,0.3);
border-radius: 10px;
padding: 18px;
margin-top: 15px;
min-height: 60px;
}
.result-box .label {
color: #4fc3f7;
font-size: 13px;
margin-bottom: 8px;
}
.result-value {
color: #e0e0e0;
font-size: 14px;
word-break: break-all;
line-height: 1.6;
}
.similarity-score {
font-size: 42px;
font-weight: bold;
text-align: center;
padding: 20px;
background: linear-gradient(135deg, #4fc3f7, #00e676);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
}
.loading { color: #888; font-style: italic; }
table {
width: 100%;
border-collapse: collapse;
margin-top: 10px;
}
th, td {
padding: 10px 12px;
text-align: center;
border: 1px solid rgba(255,255,255,0.1);
color: #ccc;
font-size: 13px;
}
th {
background: rgba(79,195,247,0.15);
color: #4fc3f7;
}
.high-sim { color: #00e676; }
.mid-sim { color: #ffeb3b; }
.low-sim { color: #ff5252; }
</style>
</head>
<body>
<div class="container">
<h1>🔢 文本向量化 (Embedding)</h1>
<p class="subtitle">基于 Spring AI + Ollama · 模型: nomic-embed-text</p>
<!-- 单文本向量化 -->
<div class="card">
<h2>📌 1. 单文本向量化</h2>
<p class="section-label">输入文本,获取其向量表示(展示前10维)</p>
<div class="btn-row" style="margin-bottom: 12px;">
<span class="quick-btn" onclick="setSingleText('人工智能正在改变世界')">🤖 AI主题</span>
<span class="quick-btn" onclick="setSingleText('今天天气真不错,适合出去散步')">🌤️ 日常对话</span>
<span class="quick-btn" onclick="setSingleText('Java是一门面向对象的编程语言')">💻 编程语言</span>
<span class="quick-btn" onclick="setSingleText('苹果是一种很健康的水果')">🍎 水果</span>
</div>
<textarea id="singleText" placeholder="请输入要向量化的文本...">人工智能正在改变世界</textarea>
<button onclick="doEmbed()">🔍 向量化</button>
<div class="result-box" id="singleResult">
<span class="loading">等待向量化...</span>
</div>
</div>
<!-- 文本相似度比较 -->
<div class="card">
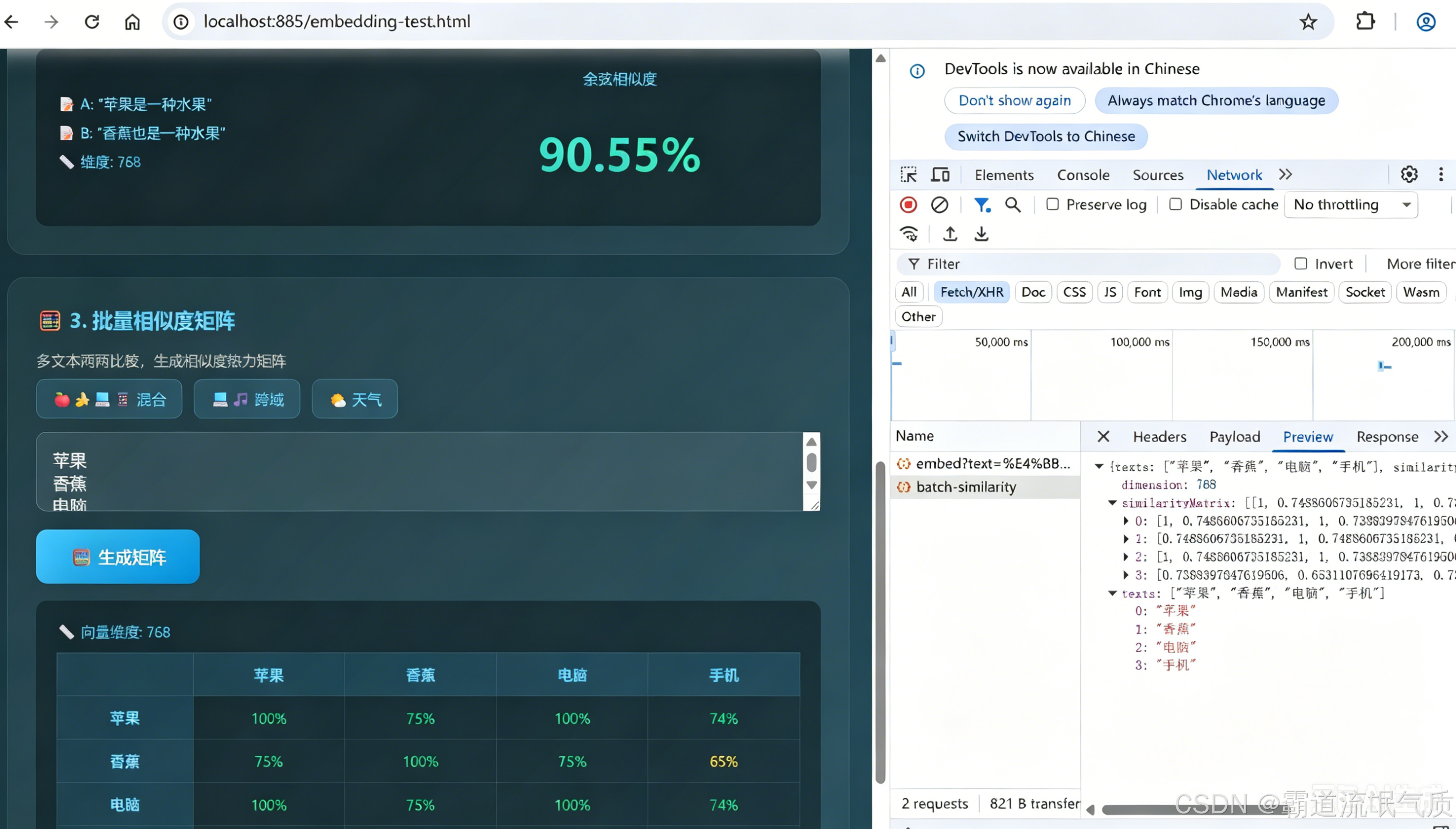
<h2>📊 2. 两文本相似度比较</h2>
<p class="section-label">比较两段文本的语义相似度(余弦相似度 0~100%)</p>
<div class="btn-row" style="margin-bottom: 12px;">
<span class="quick-btn" onclick="setPair('苹果是一种水果', '香蕉也是一种水果')">🍎🍌 同义</span>
<span class="quick-btn" onclick="setPair('今天天气真好', '今天是个晴天')">🌤️ 近义</span>
<span class="quick-btn" onclick="setPair('我喜欢吃苹果', '电脑需要更新系统')">🍎💻 无关</span>
<span class="quick-btn" onclick="setPair('Java编程语言', 'Python编程语言')">☕🐍 相似</span>
</div>
<div class="row">
<div>
<p class="section-label">文本 A</p>
<textarea id="textA" placeholder="输入文本A...">苹果是一种水果</textarea>
</div>
<div>
<p class="section-label">文本 B</p>
<textarea id="textB" placeholder="输入文本B...">香蕉也是一种水果</textarea>
</div>
</div>
<button onclick="doSimilarity()">📐 计算相似度</button>
<div class="result-box" id="similarityResult">
<span class="loading">等待计算...</span>
</div>
</div>
<!-- 批量相似度矩阵 -->
<div class="card">
<h2>🧮 3. 批量相似度矩阵</h2>
<p class="section-label">多文本两两比较,生成相似度热力矩阵</p>
<div class="btn-row" style="margin-bottom: 12px;">
<span class="quick-btn" onclick="setBatch('苹果,香蕉,电脑,手机')">🍎🍌💻📱 混合</span>
<span class="quick-btn" onclick="setBatch('Java,Python,C++,钢琴,小提琴')">💻🎵 跨域</span>
<span class="quick-btn" onclick="setBatch('晴天,下雨,多云,暴风雪')">🌤️ 天气</span>
</div>
<textarea id="batchText" placeholder="每行一个文本,或逗号分隔...">苹果
香蕉
电脑
手机</textarea>
<button onclick="doBatchSimilarity()">🧮 生成矩阵</button>
<div class="result-box" id="batchResult">
<span class="loading">等待计算...</span>
</div>
</div>
</div>
<script>
function setSingleText(text) { document.getElementById('singleText').value = text; }
function setPair(a, b) {
document.getElementById('textA').value = a;
document.getElementById('textB').value = b;
}
function setBatch(text) {
document.getElementById('batchText').value = text.split(',').join('\n');
}
function getColorForScore(score) {
if (score >= 0.7) return 'high-sim';
if (score >= 0.4) return 'mid-sim';
return 'low-sim';
}
async function doEmbed() {
const text = document.getElementById('singleText').value.trim();
if (!text) { alert('请输入文本'); return; }
const box = document.getElementById('singleResult');
box.innerHTML = '<span class="loading">⏳ 正在向量化...</span>';
try {
const resp = await fetch('/ai/embed?text=' + encodeURIComponent(text));
const data = await resp.json();
box.innerHTML = `
<div class="label">📝 文本: "${data.text}"</div>
<div class="label">📏 向量维度: ${data.dimension}</div>
<div class="label">🔢 前10维: [${(data.vectorPreview||[]).join(', ')}]</div>
`;
} catch (e) {
box.innerHTML = `<span style="color:#ff5252;">❌ 错误: ${e.message}</span>`;
}
}
async function doSimilarity() {
const text1 = document.getElementById('textA').value.trim();
const text2 = document.getElementById('textB').value.trim();
if (!text1 || !text2) { alert('请输入两段文本'); return; }
const box = document.getElementById('similarityResult');
box.innerHTML = '<span class="loading">⏳ 正在计算相似度...</span>';
try {
const resp = await fetch('/ai/embed/similarity', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ text1, text2 })
});
const data = await resp.json();
const cls = getColorForScore(data.similarity / 100);
box.innerHTML = `
<div style="display:flex;gap:20px;align-items:center;">
<div style="flex:1">
<div class="label">📝 A: "${data.text1}"</div>
<div class="label">📝 B: "${data.text2}"</div>
<div class="label">📏 维度: ${data.dimension}</div>
</div>
<div style="flex:1;text-align:center;">
<div class="label">余弦相似度</div>
<div class="similarity-score ${cls}">${data.similarity}%</div>
</div>
</div>
`;
} catch (e) {
box.innerHTML = `<span style="color:#ff5252;">❌ 错误: ${e.message}</span>`;
}
}
async function doBatchSimilarity() {
const raw = document.getElementById('batchText').value.trim();
if (!raw) { alert('请输入文本列表'); return; }
const texts = raw.split(/[\n,,]+/).map(s => s.trim()).filter(s => s.length > 0);
const box = document.getElementById('batchResult');
box.innerHTML = '<span class="loading">⏳ 正在批量计算(可能需要几秒)...</span>';
try {
const resp = await fetch('/ai/embed/batch-similarity', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ texts })
});
const data = await resp.json();
const matrix = data.similarityMatrix || [];
let html = `<div class="label">📏 向量维度: ${data.dimension}</div>`;
html += '<table><tr><th></th>';
data.texts.forEach(t => html += `<th>${t}</th>`);
html += '</tr>';
for (let i = 0; i < matrix.length; i++) {
html += `<tr><th>${data.texts[i]}</th>`;
for (let j = 0; j < matrix[i].length; j++) {
const score = Math.round(matrix[i][j] * 100);
const cls = getColorForScore(matrix[i][j]);
html += `<td class="${cls}">${score}%</td>`;
}
html += '</tr>';
}
html += '</table>';
box.innerHTML = html;
} catch (e) {
box.innerHTML = `<span style="color:#ff5252;">❌ 错误: ${e.message}</span>`;
}
}
doEmbed();
</script>
</body>
</html>改造总结
| 文件 | 操作 | 说明 |
|---|---|---|
application.yml |
修改 | 新增 spring.ai.ollama.embedding.options.model: nomic-embed-text |
EmbeddingService.java |
新建 | 封装 EmbeddingModel,提供单文本/批量向量化、余弦相似度计算 |
EmbeddingController.java |
新建 | 4 个 REST 接口:单文本向量化、两文本相似度、批量相似度矩阵、批量向量化 |
embedding-test.html |
新建 | 3 个可视化测试模块:单文本向量化、两文本比较、批量矩阵 |
使用步骤:
- 拉取 embedding 模型 :
ollama pull nomic-embed-text - 启动项目 :运行
SpringAiDemoApplication或双击一键启动.bat - 访问测试页面 :
http://localhost:885/embedding-test.html - 原有功能 不受影响,
function-call-test.html依然可用
API 接口一览:
GET /ai/embed?text=xxx--- 单文本向量化POST /ai/embed/similarity--- 两文本余弦相似度POST /ai/embed/batch-similarity--- 批量相似度矩阵POST /ai/embed/batch--- 批量文本向量化
5、原有pom保持不变
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
</parent>
<groupId>com.badao.ai</groupId>
<artifactId>spring-ai-ollama-functioncall</artifactId>
<version>1.0</version>
<properties>
<java.version>17</java.version>
<spring-ai.version>1.0.0-M6</spring-ai.version>
<spring-ai-alibaba.version>1.0.0-M6.1</spring-ai-alibaba.version>
</properties>
<dependencies>
<!-- Spring Boot Web Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI Ollama Starter(提供 ChatClient.Builder 和 Ollama 支持) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<!-- Spring AI Alibaba(提供 @Tool 注解支持,排除 DashScope 自动配置) -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-core</artifactId>
<version>${spring-ai-alibaba.version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
</project>6、测试效果