一.CDDFUSE简介
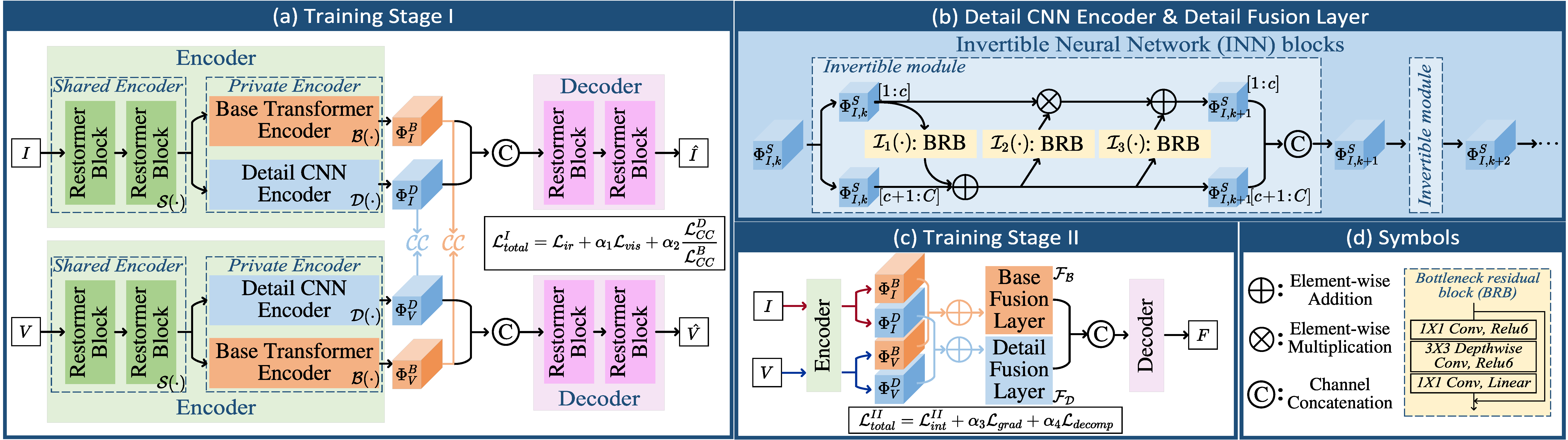
CDDFuse(Correlation-Driven Dual-Branch Feature Decomposition) 是一种面向红外与可见光图像融合的深度学习模型,核心思想是通过特征分解与相关性建模 ,在不同模态之间实现更有效的信息融合。该方法采用双分支编码结构,将输入图像分别分解为基础特征(Base Feature)和细节特征(Detail Feature):前者主要包含全局结构与低频信息,后者则强调纹理与边缘等高频信息。在融合阶段,模型利用相关性驱动机制对两类特征进行自适应整合,从而在保留红外显著目标的同时增强可见光的细节表达。最终,通过解码器重建融合图像,使结果在对比度、结构完整性和细节清晰度方面达到较优平衡。该模型在多种红外-可见光融合任务中表现出良好的鲁棒性和视觉质量,同时也为后续面向检测等高层任务的融合方法提供了有效基础。
二.CDDFUSE复现
(1)环境配置
这是环境配置,根据自己的电脑(有无显卡?版本)来安装,这是最低的版本,注意Kornia必须一致。
我这里给一串命令:
conda create -n cddfuse python=3.8.10 -y
conda activate cddfuse
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 -i https://pypi.org/simple -f https://download.pytorch.org/whl/torch_stable.html
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple einops==0.4.1 kornia==0.2.0 numpy==1.21.5 opencv-python==4.5.3.56 scikit-image==0.19.2 scikit-learn==1.1.3 scipy==1.7.3 tensorboardX==2.5.1 timm==0.4.12 h5py tqdm matplotlib环境配置好后,我们打开代码,这里我们只讲如何使用它预训练的模型去跑我们自己的图片,如果需要训练复现实验数据的按照如下步骤:
这里我们看到预训练模型已经在model文件夹里了

我们根据代码写一个test代码来跑自己的数据:
import os
import numpy as np
import torch
from net import Restormer_Encoder, Restormer_Decoder, BaseFeatureExtraction, DetailFeatureExtraction
from utils.img_read_save import img_save, image_read_cv2
# ================== 配置 ==================
ckpt_path = r"E:\multfusio\MMIF-CDDFuse-main\models\CDDFuse_IVF.pth"
test_folder = r"E:\multfusio\MMIF-CDDFuse-main\dataes" # 你的数据路径
test_out_folder = r"E:\multfusio\MMIF-CDDFuse-main\result" # 输出路径
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
os.makedirs(test_out_folder, exist_ok=True)
# ================== 去掉module前缀函数 ==================
def remove_module_prefix(state_dict):
new_state_dict = {}
for k, v in state_dict.items():
if k.startswith("module."):
k = k[7:] # 去掉 "module."
new_state_dict[k] = v
return new_state_dict
# ================== 加载模型 ==================
Encoder = Restormer_Encoder().to(device)
Decoder = Restormer_Decoder().to(device)
BaseFuseLayer = BaseFeatureExtraction(dim=64, num_heads=8).to(device)
DetailFuseLayer = DetailFeatureExtraction(num_layers=1).to(device)
ckpt = torch.load(ckpt_path, map_location=device)
Encoder.load_state_dict(remove_module_prefix(ckpt['DIDF_Encoder']))
Decoder.load_state_dict(remove_module_prefix(ckpt['DIDF_Decoder']))
BaseFuseLayer.load_state_dict(remove_module_prefix(ckpt['BaseFuseLayer']))
DetailFuseLayer.load_state_dict(remove_module_prefix(ckpt['DetailFuseLayer']))
Encoder.eval()
Decoder.eval()
BaseFuseLayer.eval()
DetailFuseLayer.eval()
print("✅ Model loaded successfully!")
# ================== 推理 ==================
with torch.no_grad():
ir_dir = os.path.join(test_folder, "ir")
vi_dir = os.path.join(test_folder, "vi")
for img_name in os.listdir(ir_dir):
ir_path = os.path.join(ir_dir, img_name)
vi_path = os.path.join(vi_dir, img_name)
if not os.path.exists(vi_path):
print(f"⚠️ 缺少VIS: {img_name}")
continue
# === 读取 ===
data_IR = image_read_cv2(ir_path, mode='GRAY')
data_VIS = image_read_cv2(vi_path, mode='GRAY')
if data_IR.shape != data_VIS.shape:
print(f"⚠️ 尺寸不一致: {img_name}")
continue
# === 转tensor ===
data_IR = data_IR[np.newaxis, np.newaxis, ...] / 255.0
data_VIS = data_VIS[np.newaxis, np.newaxis, ...] / 255.0
data_IR = torch.FloatTensor(data_IR).to(device)
data_VIS = torch.FloatTensor(data_VIS).to(device)
# === 前向 ===
feature_V_B, feature_V_D, _ = Encoder(data_VIS)
feature_I_B, feature_I_D, _ = Encoder(data_IR)
feature_F_B = BaseFuseLayer(feature_V_B + feature_I_B)
feature_F_D = DetailFuseLayer(feature_V_D + feature_I_D)
data_Fuse, _ = Decoder(data_VIS, feature_F_B, feature_F_D)
# === 归一化 ===
data_Fuse = (data_Fuse - torch.min(data_Fuse)) / (torch.max(data_Fuse) - torch.min(data_Fuse) + 1e-8)
# === 转numpy ===
fi = np.squeeze((data_Fuse * 255).cpu().numpy()).astype(np.uint8)
# === 保存(同名)===
save_name = os.path.splitext(img_name)[0]
img_save(fi, save_name, test_out_folder)
print(f"✔ {img_name}")
print("🎉 Done!")注意改成自己的路径(电脑要有显卡,否则需要改为cpu版本)注意自己数据集的格式: