目录
一、大小端字节序和字节序判断
首先我们知道,整数的二进制表现方法有三种:原码、反码、补码
在内存中整数是以二进制补码的形式进行存储的
我们来看一串代码:
cpp
#include <stdio.h>
int main()
{
int a = 0x11223344;
return 0;
}a中存的是十六进制的11223344,因为是正数,所以他的原反补码相同,虽然在内存中会把这串数字换算为二进制的形势存储,但是当我们调试时,会以十六进制形势展示出来,所以我们看到的它的原反补码都是11223344,让我们在调试中看看:
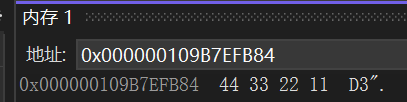
可以看到,在内存中我们存储的时候,是倒着存储的,这是为什么呢?这就要讲到一个知识点:大小端字节序,上面这个是小端存储模式
1.1大小端字节序存储模式
为什么会有大小端存储模式呢?
因为当超过一个字节的数据在内存中存储时,我们就肯定会有存储顺序的问题,当一个字节的时候,我们就不用考虑顺序,因为就一个字节,直接放着就好了,但超过一个字节时,例如上述代码的0x11223344,我们就需要考虑,是直接存储11223344,还是要倒过来存储44332211,这个在不同的CPU架构有不同的设计,是在硬件生产的时候就已经固定好的,我们分为大端字节序存储和小端字节序存储,字节序意思就是按单个字节来存储,按【单个字节】为单位排顺序
-
x86/x64 架构 日常电脑、笔记本的 Intel/AMD CPU 都是这个架构,默认小端序 ,也是你现在电脑的模式。 示例数据
0x11223344,内存低地址开始存:44 33 22 11。 -
ARM 架构 手机、单片机、部分嵌入式设备用的架构。 早期多为大端序 ,现在很多新款 ARM 支持切换,但嵌入式场景仍常用大端。 大端规则:
0x11223344,内存低地址开始存:11 22 33 44。
然后我们要了解一个知识点,一个整数例如0x11223344,我们从左到右看分别是从高位到低位,我们可以这样理解,比如123,右边的3是个位,中间的2是十位,左边的1是百位,百位肯定比个位大,所以左边是高位,右边是低位,了解这个过后,我们再来看看大小端的存储模式
大端存储模式:是指数据的低位字节内容保存在内存的高地址处,而数据的高位字节内容,保存在内存的低地址处
小端存储模式:是指数据的低位字节内容保存在内存的低地址处,而数据的高位字节内容,保存在内存的高地址处
1.2练习(含大小端字节序判断)
(1)练习一
设计一个小程序来判断当前机器的字节序。(10分)--百度笔试题
方法一:
cpp
#include <stdio.h>
int main()
{
int i = 1;
if (*((char*)&i) == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
}我们找到i的地址,并且强制类型转换为char*类型,接着解引用,访问其第一个字节的内容,我们知道i=1,在内存中存储用十六进制表示时是00 00 00 01,如果是大端存储,那依然是00 00 00 01,我们解引用访问第一个字节得到的结果就是0;但如果是小端存储,得到的就是01 00 00 00
方法二:
cpp
#include <stdio.h>
//判断大小端函数
int check_sys()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;
}
//主函数
int main()
{
if (check_sys() == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
}我们创建了个匿名(联合体/共用体),里面有两个成员分别是int i和char c,然后创建了个联合体变量un,总体思路是,因为这个联合体总共大小为4个字节,我们给int i赋值为1,char c不赋值,再以un.c作为返回值返回,un.c访问的就是这个联合体占用内存的第一个字节,int i=1用十六进制表示出来00 00 00 01,如果un.c等于00,那就是大端存储,如果un.c等于01,那就是小端存储
(2)练习二
代码输出的结果是啥?
cpp
#include <stdio.h>
int main()
{
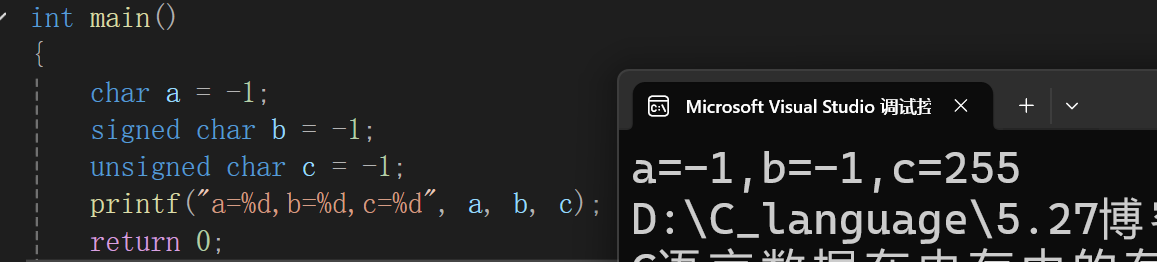
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}下面我们首先看两张图:
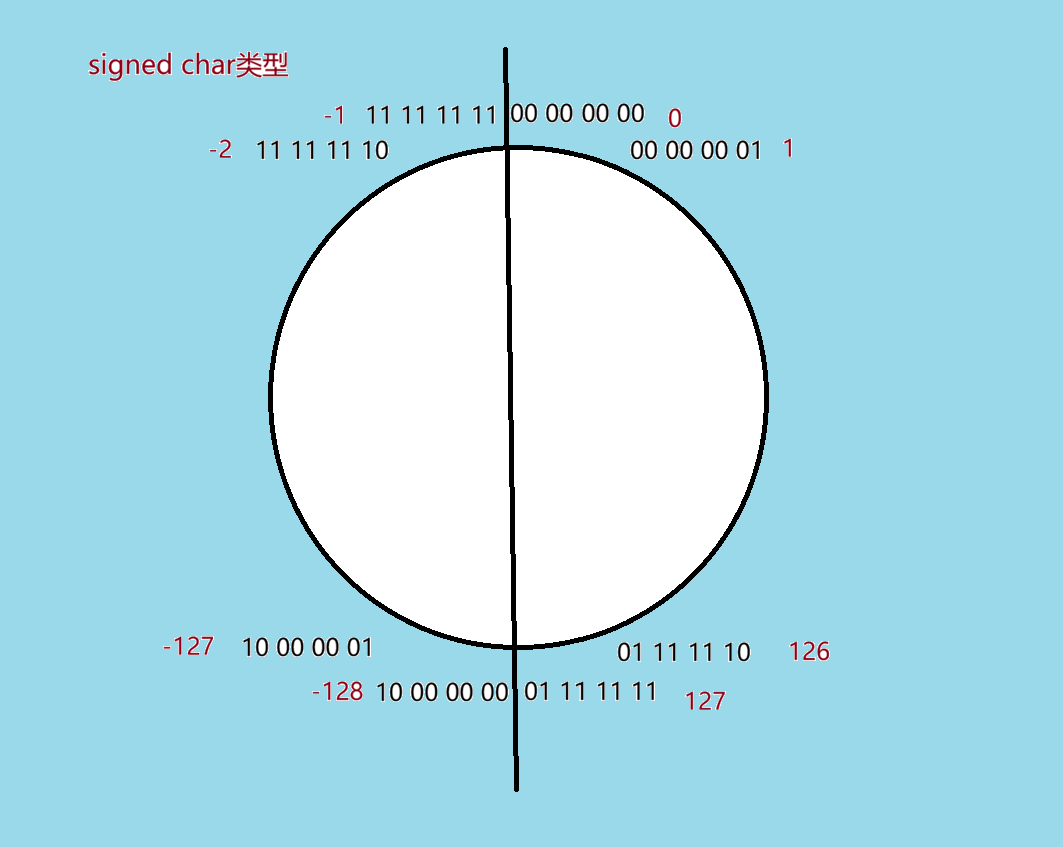
当char是signed类型时,我们可以把char的取值想象成一个圆,里面存的是补码,右半圆从上往下顺时针方向开始,分别是从0~127,接着左半圆从下往上顺时针起,分别是 -128 ~ -1,接着又回到0,1,2......,所以128就等于-128,129就等于-127,所以假如当我们存入signed char i=135时,其实就是(135-128)+(-128),i的值其实就是-121,因为赋值 135 ,超过了最大值 127 ,会自动溢出回负数
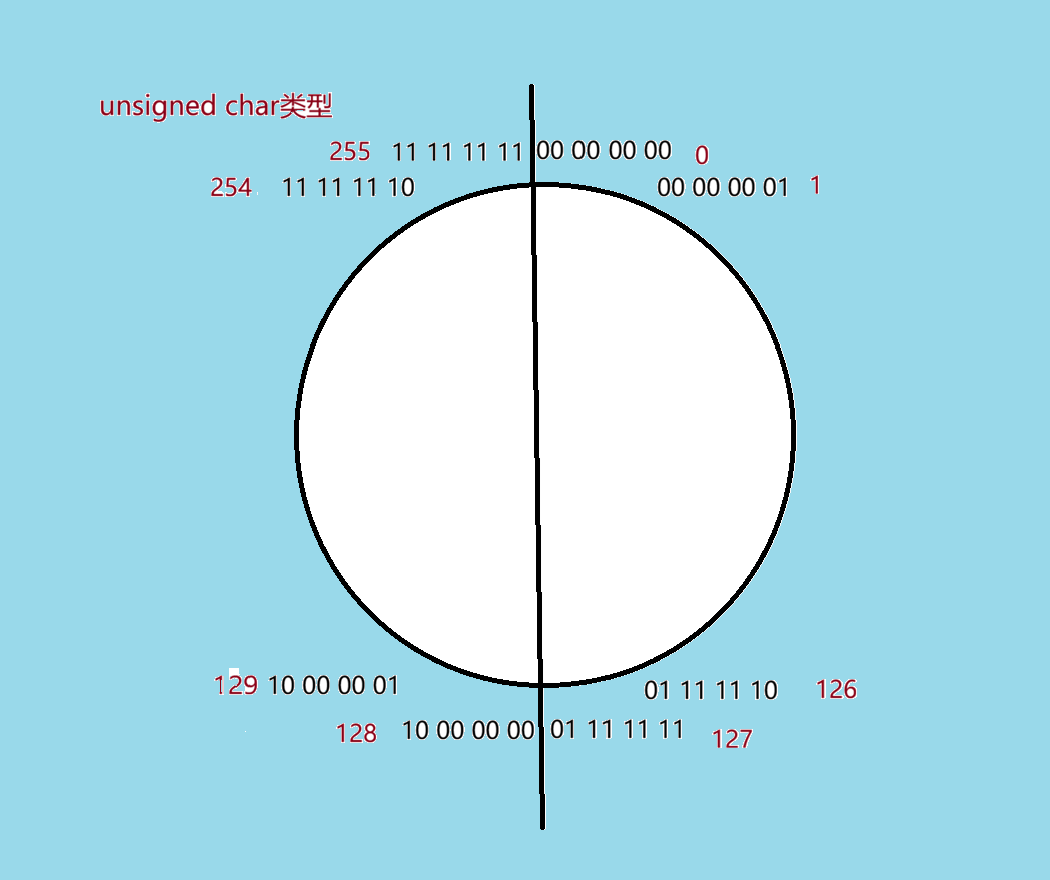
这个就是unsigned char类型的图,和上述规则很像,但这里的补码是无符号位的,所以从顺时针开始,一直从0~255,255是char类型的最大值,当char i=256时,其实i就是0了,会自动换算成0,char i=257时,i就是2,所以假如当我们存入unsigned char i=268时,其实就是268-255=13,i的值其实就是13,因为赋值268,超过了最大值 255 ,会自动溢出回正数数
总结:
signed char类型取值(-128~127)
unsigned char类型取值(0~255)
所以我们现在再去看上述的代码 char a= -1和signed char b=-1,因为有符号char类型的取值是**(-128~127),所以**它们的值就是-1,但unsigned char c=-1的取值是255,根据上述的图就能看出来,-1就是255,-2就是254
运行截图:
(3)练习三
代码输出的结果是啥?
代码一:
cpp
#include <stdio.h>
int main()
{
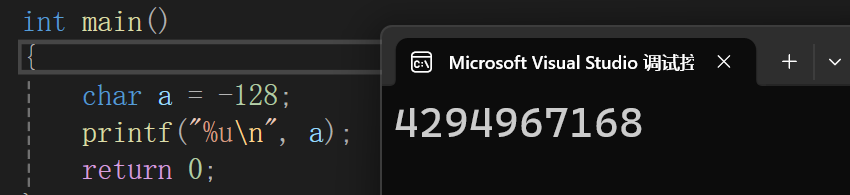
char a = -128;
printf("%u\n", a);
return 0;
}因为a是char类型,占一个字节,八个bit位,所以-128的补码是10000000,当char类型的值进行传参或运算时,首先要进行整型提升,有符号数高位补符号位,变成11111111 11111111 11111111 10000000,再以%u的形式打印,也就是以无符号整型打印,那么全部都是有效位,无符号位,11111111 11111111 11111111 10000000的值就是4294967168
运行截图:
代码二:
cpp
#include <stdio.h>
int main()
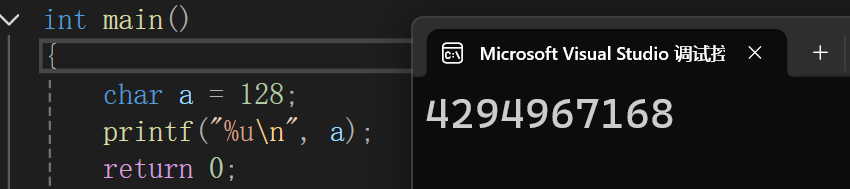
{
char a = 128;
printf("%u\n", a);
return 0;
}因为此时的char在VS中是有符号类型的char,所以可以看我们练习二中的signed char类型的图,里面存128会溢出变成-128,就等于我们存的是char a=-128,所以就和上述一样了,打印的是4294967168
运行截图:
(4)练习四
代码输出的结果是啥?
cpp
#include <stdio.h>
#include <string.h> // 必须加,否则 strlen 用不了
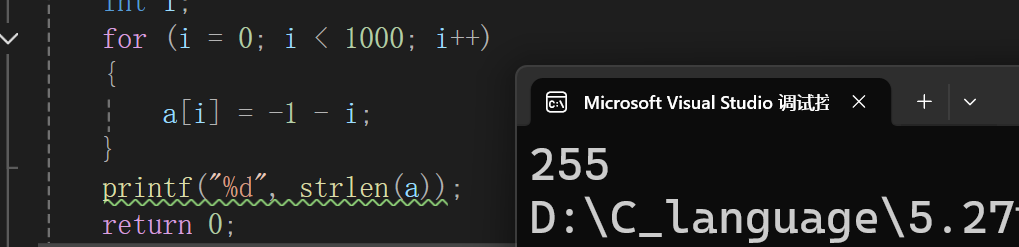
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}此题目就是想求char类型的数组a,从-1开始往下递减,什么时候递减到ai的值为'\0',然后统计'\0'之前的字符个数,这是个有符号的char类型数据,我们结合练习二signed的图可以知道,-1一直递减到-128后,-129就是127,然后从127一直递减到0,-1到-128,一共有128个数,127到1,一共有127个数,所以'\0'之前就一共有128+127=255个数,会打印255
运行截图:
(5)练习五
代码输出的结果是啥?
代码一:
cpp
#include <stdio.h>
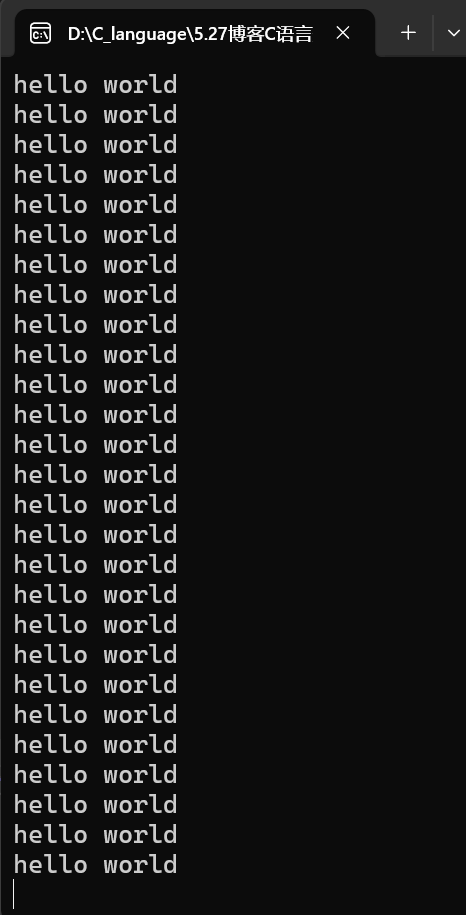
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}因为i是unsigned char类型,范围是0~255,所以当for (i = 0; i <= 255; i++),当i=256时,char类型装不下了,会溢出重新变为0,到511.....时又会变成0,所以这个for循环是个死循环,会一直打印"hello world\n"
运行截图:
代码二:
cpp
#include <stdio.h>
#include <windows.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
Sleep(300);
}
return 0;
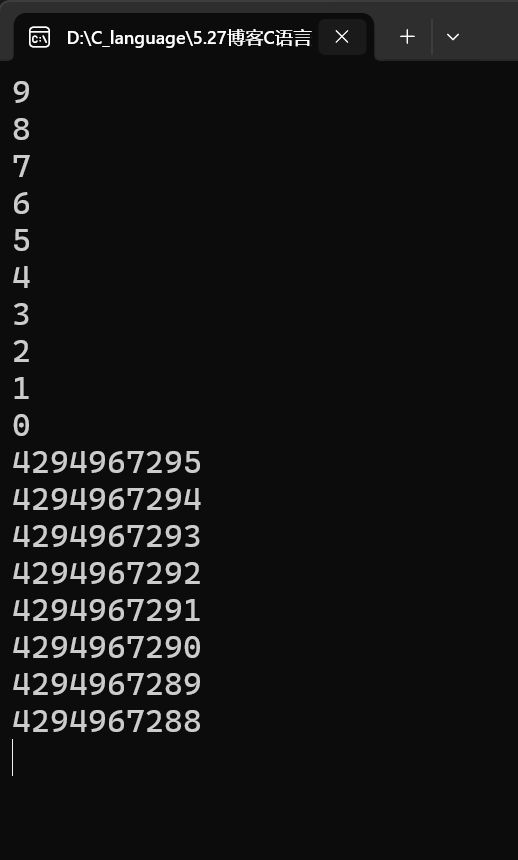
}因为i是unsigned int类型,我们已知了unsigned char类型的规律,unsigned int和unsigned char的规律一样,就是范围不一样,int的范围更大,但我们for (i = 9; i >= 0; i--),i减到-1时,会溢出变为4294967295(unsigned int类型的最大值),i减到-100时,溢出变为巨大的正数.....,所以unsigned int 永远 ≥ 0,所以会死循环打印
运行截图:
(6)练习六
代码输出的结果是啥?
cpp
#include <stdio.h>
//X86环境 ⼩端字节序
int main()
{
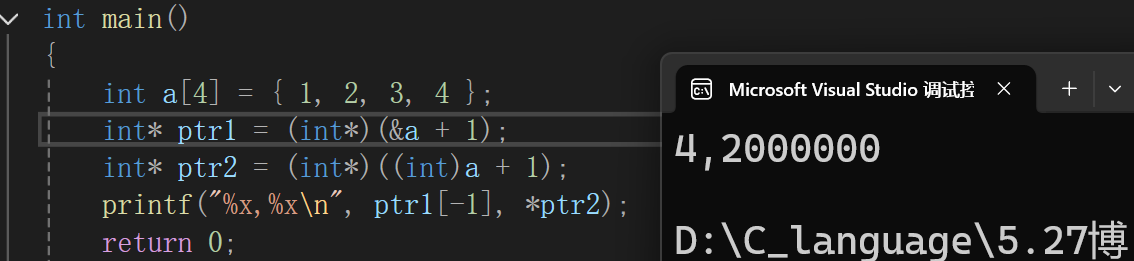
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x\n", ptr1[-1], *ptr2);
return 0;
}int* ptr1 = (int*)(&a + 1),这串代码是将整个数组a的地址取了出来,+1跳过了整个数组,指向a4,然后我们强制类型转化为int*类型, 当ptr1-1时,也就是*(ptr1-1),因为ptr1是int*类型,减1减一个整型,到a3的位置,用%x打印出的结果就是4
int* ptr2 = (int*)((int)a + 1),a是数组首元素的地址,转化为int类型加1,也就是整型+1,跳过一个字节,我们再强制类型转化为int*类型,不转系统也会帮我们主动转,将(int*)((int)a + 1)的结果存入指针变量ptr2中,首字符在内存中存储的是01 00 00 00,接着a1存储的是02 00 00 00,它们在内存中是连续存储的,也就是10 00 00 00 02 00 00 00,当我们(int*)((int)a + 1)时,我们说了跳一个字节,然后我们再*ptr2,解引用访问四个字节,此时访问的就是00 00 00 02,因为是小端存储,所以真实的补码是02 00 00 00,用%x打印出的结果就是2000000
运行截图:
二、浮点数在内存中的存储
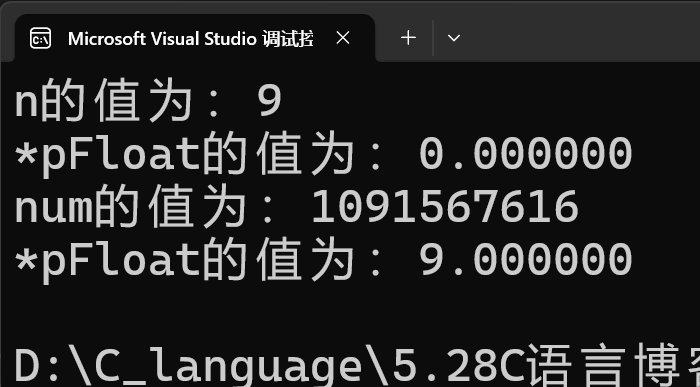
我们首先来看一串代码:这串代码的结果是什么?
cpp
#include <stdio.h>
int main()
{
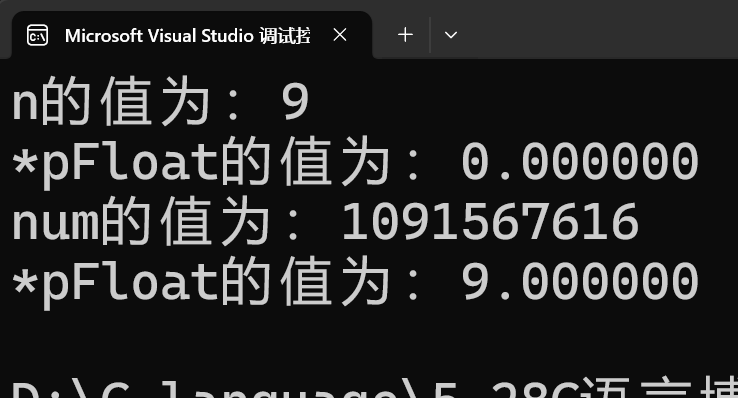
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}运行截图:
上面的代码中,num 和 *pFloat 在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别这么大?这时候我们就要了解一下浮点数在内存中存储的知识了
2.1浮点数的存储
根据 IEEE(电气和电子工程师协会)754 标准规定,任意⼀个二进制浮点数V可以表示成下面的形式:
代表的是该浮点数的符号位,当s等于0时,V为正数;当s等于1时,V为负数
举个例子:十进制的-5.125,二进制为-101.001,以上面这种形式来呈现,相当于(-1)¹ × 1.01001 × 2²,得到的S就等于1,M等于1.01001,E等于2
IEEE 754 规定:
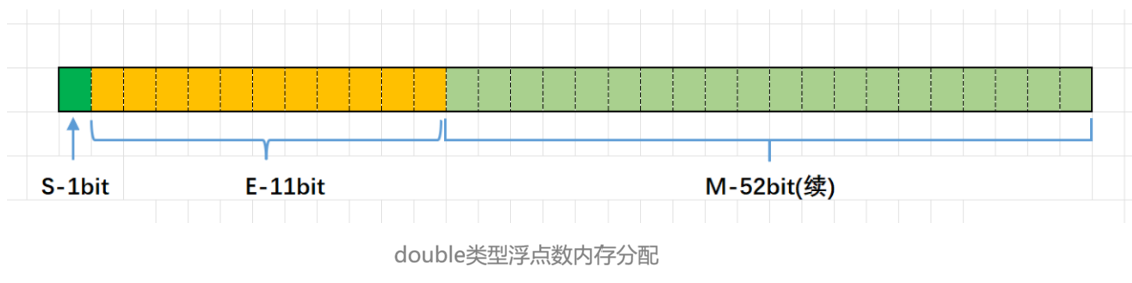
对于 32 位的浮点数,最高的 1 位存储符号位 S,接着的 8 位存储指数 E,剩下的 23 位存储有效数字 M
对于 64 位的浮点数,最高的 1 位存储符号位 S,接着的 11 位存储指数 E,剩下的 52 位存储有效数字 M

2.2浮点数存储的过程
那浮点数,具体在内存中是怎么存储的呢?
S:S只占一个符号位,正数存0,负数存1
但IEEE 754标准对有效数字M 和指数E,还有一些特别规定
我们就以十进制的-5.125为例子,在float类型中,看看具体存在内存中是怎么存储的
M的规定:我们知道M表示的是有效数字,在计算机内部存储时,默认这个数的第一位总是1,是以1.xxxxxxx的形式储存的,所以我们会将前面的1.舍去,这样做的好处是,我们可以存储多一位有效数字,本来如果将1放进来,我们M的23个空间就只能存储23个有效数字,现在将1舍去,我们就可以存多一个有效数字,最后在计算时会主动把舍去的1.加上,不够有效数字时会往后补0,这样其实我们就能存的是24位有效数字;同样道理,那么如果是在64位下,存的就是53位有效数字
例如-5.125,它的M是1.01001,在内存上就会存0100 1000 0000 0000 0000 000,最后拿出来时会自动添1. 也就是1.01001000 0000 0000 0000 000
E的规定:E的规定就比较复杂,首先E是一个unsigned类型,是一个无符号数,它占8个bit位,所以可以表示的数的范围是0~255;如果E占11位,它的取值范围就是0~2047,但我们知道,在浮点数用科学计数法表示时,指数是可以出现负数的,例如存0.25,它的二进制表示是0.01,我们用科学计数法表示就是1.0 × 2⁻²,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023,比如当我们在8位的E中,存E=-2时,我们是先将-2+127=125,将这个125换算成二进制存储在这8位中,E就等于01111101
2.3浮点数取数的过程
指数E从内存中取出还可以再分成三种情况:
(1)E不全为0或不全为1
此时指数E的计算值减去127(或1023),就可以得到真实指数的值,再看符号位S和将M前面加上1.就能取出我们原本的数
例如0.5f在内存中是这样存储的:0 01111110 00000000000000000000000
01111110是它的8位指数位,换算成十进制为126,126-127等于-1,所以E就等于-1,符号位为0,所以S就等于0,后面的M加上1.就是1.00000000000000000000000,简写为1.0,所以最终这个数的科学计数法表示就是(-1)⁰ × 1.0 × 2⁻¹
(2)E为全0
浮点数的指数E就等于1-127(或者1-1023),这是IEEE 754 人为规定的,所以当E为全0时,8位的E真实值其实就是-126,11位的E真实值其实就是-1022;然后有效数字M不再加上1.而是还原为0.xxxxxx这样的小数。这样做是为了表示±0,以及接近于0的很小的数字
比如0 00000000 00100000000000000000000,此时E为00000000,是全0,E的真实值是-126,S为0,M为00100000000000000000000,前面添上0.为0.00100000000000000000000,简写为0.001,所以此数的科学计数法表示就是(-1)⁰ × 0.001 × 2⁻¹²⁶,这是一个非常小的数,无限接近于0的数,所以当我们E为全0时,我们的目的就是为了表示±0,或者无限接近于0的很小的数字
(3)E为全1
比如0 11111111 00010000000000000000000,此时E为11111111,是全1,E为全1时不再计算指数与M数值,只判断 2 种特殊情况
- M 全 0 → 无穷大
- M不全为 0 → NaN(非数值)
此处M等于00010000000000000000000,不为全0,所以此数表示NaN,全拼叫Not a Number,意思是非数值, 专门标记非法、无意义的运算结果,此处S无意义
如果M为全0,表示无穷大时: S 有效:S=0 是正无穷 ,S=1 是负无穷
2.4题目解析
接下来让我们再回看这个代码:
cpp
#include <stdio.h>
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}**printf("n的值为:%d\n", n):**会以整型的视角去打印数字9,正常打印
**printf("*pFloat的值为:%f\n", *pFloat):**int n=9,我们取出n的地址,并强制类型转化为float*类型,存入字符指针变量pFloat中,n在内存中存储的二进制补码是00000000 00000000 00000000 00001001,此时我们访问*pFloat,就是以浮点数的视角来看待这串补码,那就是0 00000000 00000000000000000001001,S=0,M=00000000000000000001001,最重要的E=00000000,E为全0,真实值为-126,所以这串补码会被翻译成一个无限接近于0的数字:0.00000000000000000001001 × 2⁻¹²⁶,当我们将*pFloat用%f打印时,只显示前六位小数,所以printf("*pFloat的值为:%f\n", *pFloat)会打印出0.000000
**printf("*pFloat的值为:%f\n", *pFloat):**当我们将*pFloat = 9.0,将n的值改成9.0时,其实是以浮点数的方式,将9.0存入了n的内存中,9.0的二进制补码是1001.0,用科学计数法表示是1.001 × 2³,S就等于0,E等于3+127=130,存储的是130的补码,为10000010,最后M等于0010 0000 0000 0000 0000 000,所以我们此浮点数9.0在内存中以二进制形式存储的是0 10000010 0010 0000 0000 0000 0000 000,当我们以%d形式打印时,其实就是把它重新以整型的视角去看待为 01000001 00010000 00000000 00000000,这是一个很大的数,最高位为符号位0,为正数,剩下的1000001 00010000 00000000 00000000转化为十进制是1091567616,所以我们printf("num的值为:%d\n", n)会打印出1091567616
**printf("*pFloat的值为:%f\n", *pFloat):**这串代码就是将*pFloat在内存中以二进制形式存储的0 10000010 0010 0000 0000 0000 0000 000,以浮点数的规则取出并打印,取出后的数就是9.0,%f要打印六位小数,所以是9.000000
下面我们来再看一遍运行截图,来验证我们分析的结果:
感谢大家的观看,新人求互三,关注我必回关!下章见