TL;DR
- 场景:大数据平台元数据散落各子系统,缺乏统一治理方案
- 结论:Apache Atlas 提供集中化元数据管理、数据血缘追踪与分类标签体系
- 产出:Atlas 1.2.0 编译安装完整流程,支持 Hive/HBase/Kafka 等数据源元数据采集

版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| Atlas 元数据采集 | ✅ 已验证 | 支持 Hive、HBase、Sqoop、Kafka、Storm |
| 数据血缘分析 | ✅ 已验证 | 支持表级/字段级血缘追踪 |
| Tagging 分类 | ✅ 已验证 | 基于标签的访问控制 |
| JanusGraph 图引擎 | ✅ 已验证 | Atlas 1.0+ 采用 JanusGraph |
| HBase 元存储 | ✅ 已验证 | HBase 1.1.2 集成 |
| Solr 索引引擎 | ✅ 已验证 | Solr 5.5.1 索引存储 |
| 编译构建 | ✅ 已验证 | Maven 2GB 内存优化编译 |
| REST API | ✅ 已验证 | 提供元数据管理 REST 接口 |
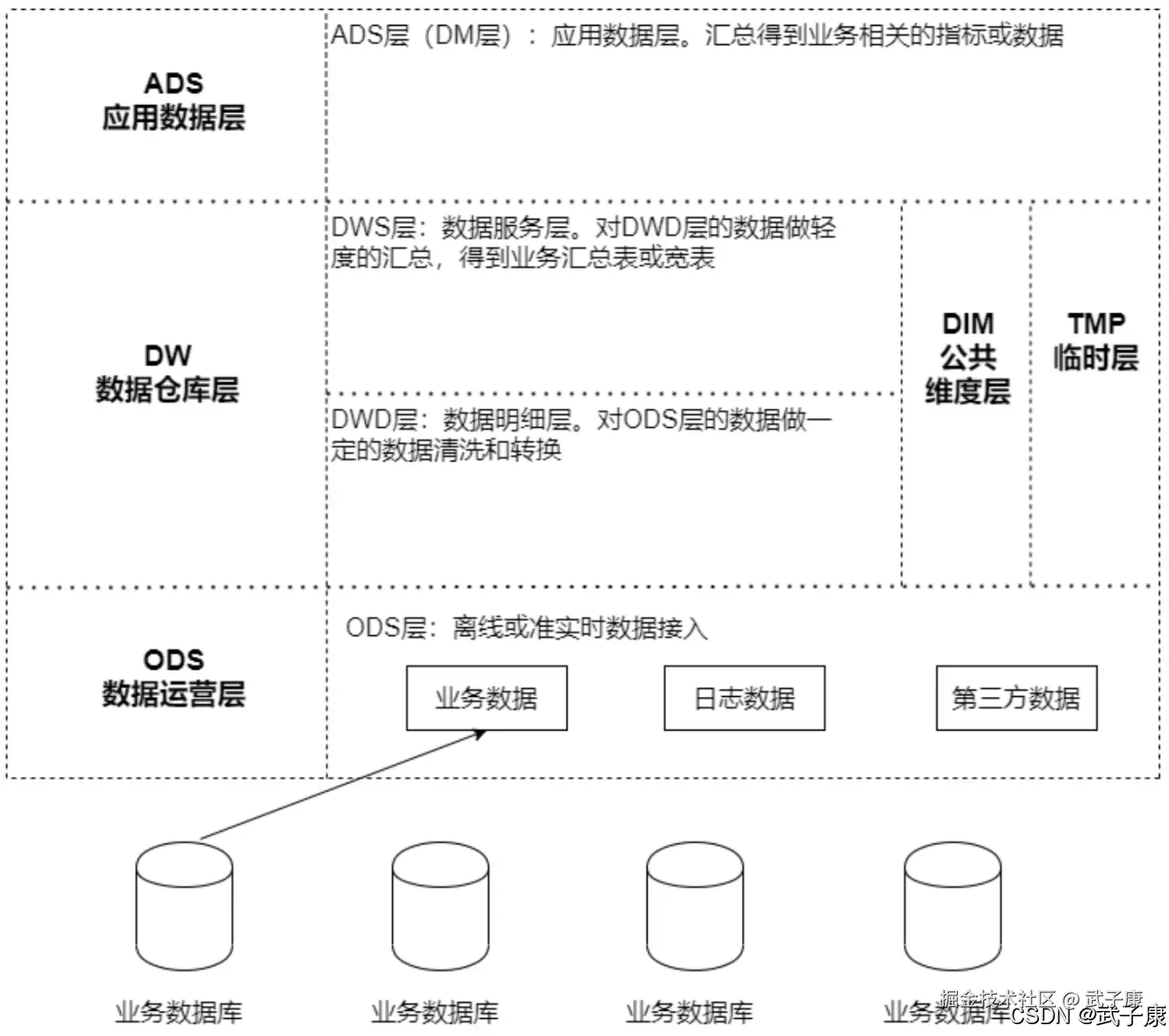
数据仓库元数据管理
元数据(MetaData)狭义的解释是用来描述数据的数据。广义来看,除了业务逻辑直接读写处理的那些业务数据,所有其他用来维持整个系统运转所需的信息、数据都可以叫做元数据,如数据库中表的Schema信息,任务的血缘关系,用户和脚本、任务的权限映射关系信息等。
管理元数据的目的,是为了让用户能够更高效的使用数据,也是为了平台管理人员能更加有效的做好数据的维护管理工作。
但通常这些元数据信息是散落在平台的各个系统,各种流程中,它们的管理也可能或多或少可以通过各种子系统自身的工具,方案或者流程逻辑来实现。
元数据管理平台很重要的一个功能就是信息的收集,至于收集哪些信息,取决于业务的需求和需要解决的目标问题。
元数据管理平台还需要考虑如何恰当的形式对这些元数据信息进行展示,进一步的,如何将这些元数据信息通过服务的形式提供给周边上下游系统来使用,真正帮助大数据平台完成质量管理的闭环工作。
应该收集那些信息,没有绝对的标准,但是对大数据开发平台来说,常见的元数据元数据信息包括:
- 表结构信息
- 数据的空间存储,读写记录,权限归属和其他各类统计信息
- 数据的血缘关系信息
- 数据的业务属性信息
数据血缘关系
血缘信息或者叫Lineage的血统信息是什么,简单的说就是数据之间的上下游来源去向关系,数据从哪里来到哪里去,如果一个数据有问题,可以根据血缘根据上下游排查,看看到底在哪个环节出了问题。
此外,也可以通过数据的血缘关系,建立起生产这些数据的任务之间的依赖关系,进而辅助调度系统的工作调度,或者用来判断一个失败或错误的任务可能对哪些下游数据造成了影响等等。
分析数据的血缘关系看起来简单,但真的要做起来,并不容易,因为数据的来源多种多样,加工数据的手段,所使用的计算框架可能也各不相同,此外也不是所有的系统天生都具备获取相关信息的能力。而针对不同的系统,血缘关系具体能够分析到的粒度可能也不一样,有些可以做到表级别,有些甚至可以做到字段级别。
以Hive表为例,通过分析Hive脚本的执行计划,是可以做到相对精确的定位出字段级别的数据血缘关系的,而如果是一个MapReduce任务生成的数据,从外部来看,可能就只能通过分析MR任务输出的LOG日志信息来粗略判断目录级别的读写关系,从而间接推导数据的血缘依赖关系了。
数据的业务属性信息
业务属性有哪些呢?如一张表的统计口径信息,这张表干什么的呀用的,各个字段的具体统计方式,业务描述,业务标签,脚本逻辑的历史变迁记录,变迁原因,此外还包括对应的数据表格是谁负责开发的,具体数据业务部门归属等。数据的业务属性信息,首先是为业务服务的,它的采集和展示也就需要尽可能的和业务环境融合,只有这样才能真正发挥这部分元数据信息的作用。
很多一段时间内,市面上都没有成熟的解决方案,直到2015年,Hortonworks坐不住了,约了一众小伙伴公司倡议:开始整个数据治理方案,包含数据分类、集中策略引擎、数据血缘、安全和生命周期管理功能的Atlas!
(类似项目:2016年Linkdin新开源了whereHows)
Atlas简介
Atlas是Hadoop平台元数据框架:
Atlas是一组可扩展的核心基础治理服务,使企业能够有效,高效的满足Hadoop中合规性要求,并能与整个企业数据生态系统集成
Apache Atlas为组织提供了开放的元数据管理和治理功能,以建立数据资产的目录,对这些资产进行分类和治理,并为IT团队、数据分析团队提供围绕这些数据资产的协作功能。
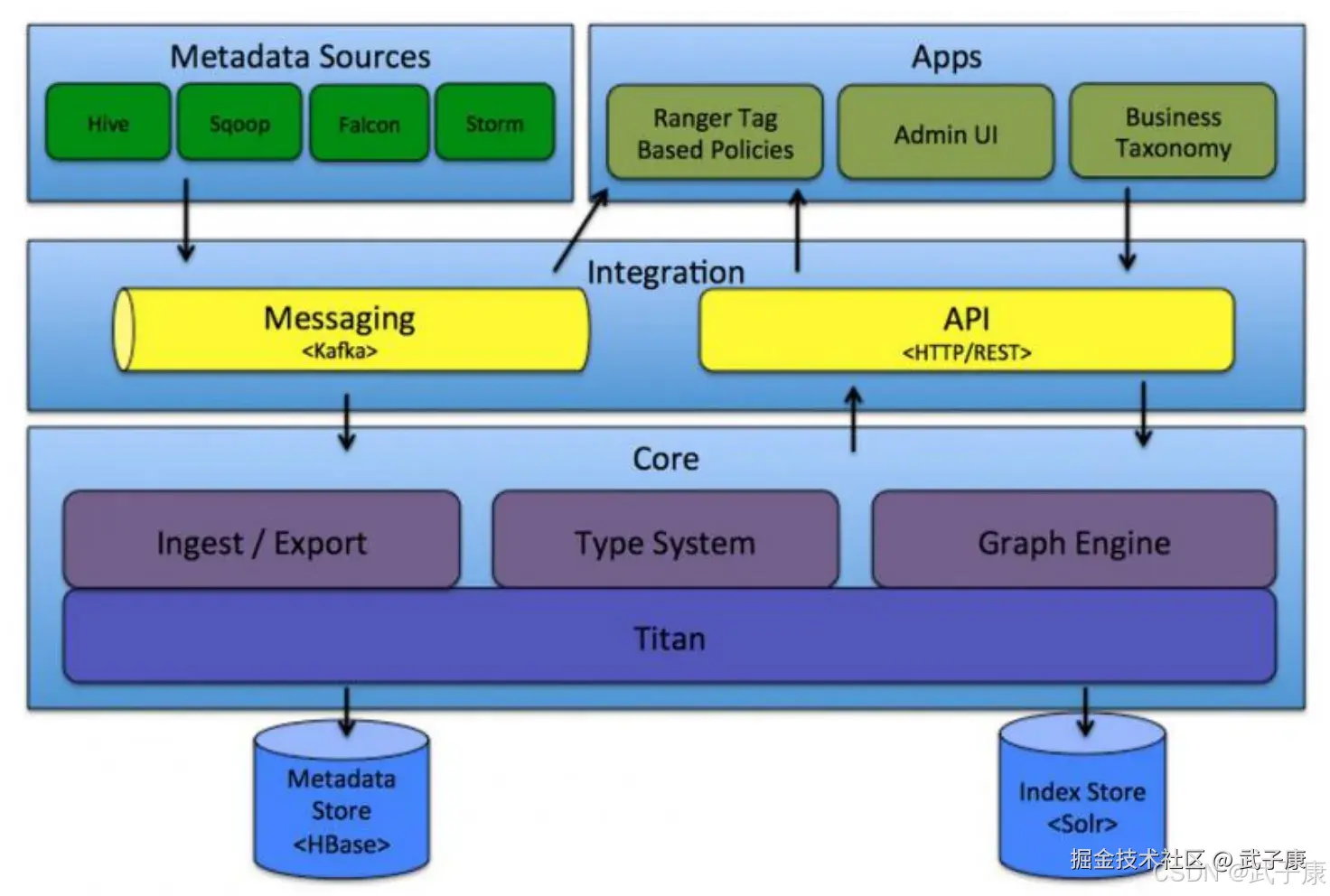
Altas由元数据的收集,存储和查询展示三部分核心组件组成,此外,还会有一个管理后台对整体元数据的采集流程以及元数据格式定义和服务的部署等各项内容进行配置管理。
Altas包括以下组件:
- Core,Atlas功能核心组件,提供元数据的获取与导出(Ingets、Export)、类型系统(Type System)、元数据存储索引查询等核心功能
- Integration,Atlas对外集成模块,外部组件的元数据通过该模块将元数据给Altas管理
- MetastoreSource,Atlas支持的元数据数据源,以插件的形式提供,当前支持从以下来源提取和管理元数据:(Hive、HBase、Sqoop、Kafka、Storm)
- Applications,Altas的上层应用,可以用来查询由Atlas管理的元数据类型和对象
- Graph Engine(图计算引擎),Atlas使用图模型管理元数据对象,图数据库提供了极大的灵活性,并能有效处理元数据对象之间的关系,除了管理图对象之外,图计算引擎还为元数据对象创建适当的索引,以便进行高效的访问,在Atlas 1.0之前采用Titan作为图存储引擎,从1.0开始采用JanusGraph作为图存储引擎,JanusGraph底层又分为两块:Metadata Store,采用HBase存储Atlas管理元数据。IndexStore采用Solr存储元数据的索引,便于高效搜索。
核心功能
元数据管理
Atlas 支持对 Hadoop 生态系统(如 HDFS、Hive、HBase、Kafka、Spark 等)中的数据资产进行集中管理。
提供了 REST API 和 Web UI,方便用户管理和查询元数据。
数据分类(Tagging)
允许用户为数据资产打标签,用于数据分类、搜索和权限控制。
支持基于标签的访问控制,帮助确保敏感数据的安全。
数据血缘分析
提供详细的数据血缘图,用于追踪数据从源头到最终使用的整个流转过程。
支持向前和向后追踪,帮助识别数据的上下游影响。
数据影响分析
通过数据血缘关系,可以分析数据的修改如何影响下游系统。
帮助团队提前评估和规避因数据变更带来的潜在风险。
数据审计
记录对元数据的所有操作,包括创建、修改和删除,提供全面的审计日志。
支持合规性需求,例如 GDPR、CCPA 等数据保护法规。
可扩展性
Atlas 提供了可扩展的元模型,用户可以根据需要定义自定义的元数据模型。
支持插件式架构,可以与各种数据源和处理工具集成。
搜索和发现
提供高级搜索功能,用户可以根据名称、标签或属性快速找到相关数据资产。
支持全文检索,帮助用户更高效地发现数据。
框架的架构
Atlas 的架构主要由以下几个部分组成:
元数据存储层
使用关系型数据库(如 PostgreSQL 或 MySQL)存储元数据。
提供高效的查询和管理能力。
服务层
提供一组 REST API 和 GraphQL API,用于与 Atlas 交互。
负责元数据的存储、检索、分类和血缘追踪。
索引和搜索
使用搜索引擎(如 Apache Solr 或 Elasticsearch)来索引元数据,支持高效的搜索和检索。
集成层
提供与 Hadoop 生态系统(如 Hive、HBase、Kafka 等)的无缝集成能力。
支持使用 Hook 和 Bridge 将第三方工具的元数据同步到 Atlas。
用户界面
提供基于 Web 的用户界面,用户可以通过直观的操作管理和浏览元数据。
安装配置
安装依赖
- Maven(安装)
- HBase(压缩包)
- Solr(压缩包)
- Atlas(编译)
官方只提供了源码,没有提供二进制的安装版本,所以需要编译。
解压配置
目前节点是:h122.wzk.icu 节点:
shell
cd /opt/software
tar zxvf apache-atlas-1.2.0-sources.tar.gz
cd apache-atlas-sources-1.2.0/执行结果如下图所示:

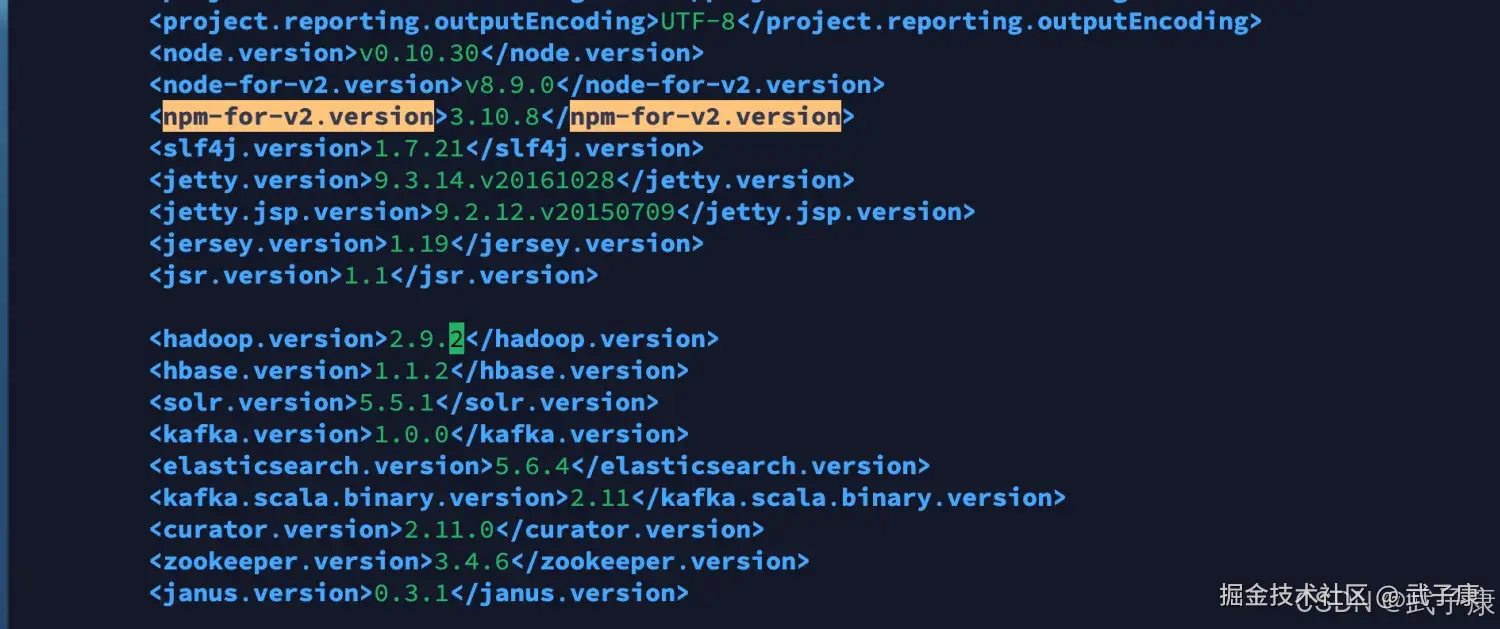
修改 pom.xml
shell
vim pom.xml
# 修改如下的内容
645 <npm-for-v2.version>3.10.8</npm-for-v2.version>
652 <hadoop.version>2.9.2</hadoop.version>修改结果如下所示:
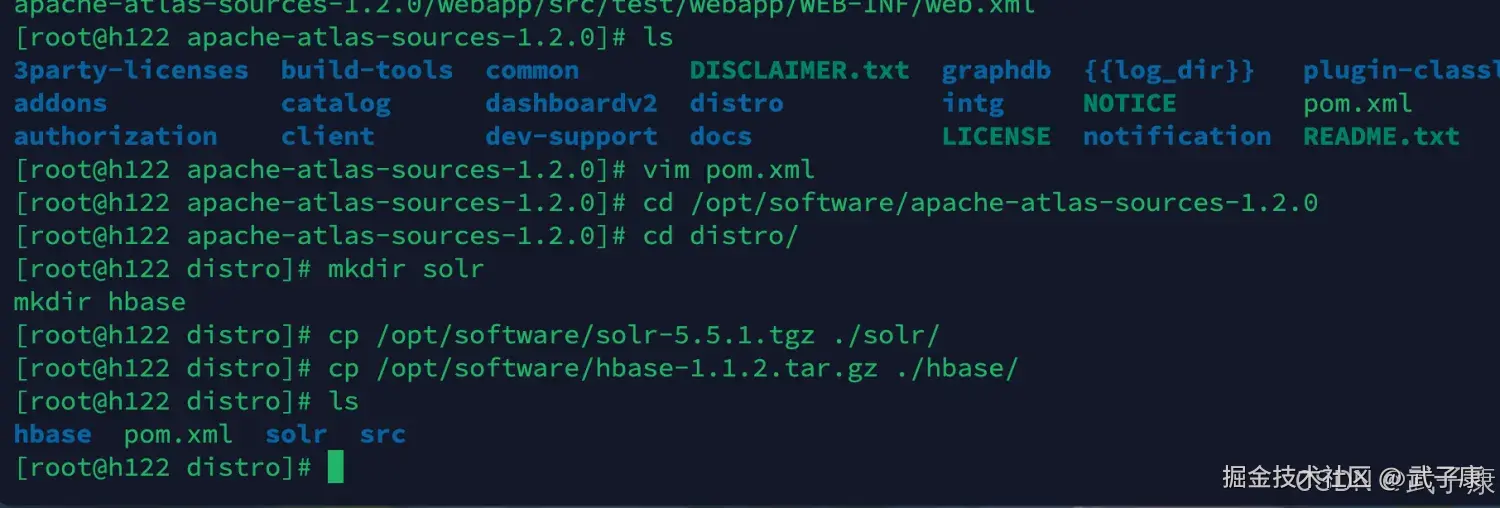
拷贝依赖
将HBase、Solr这些拷贝到对应的目录中,如果不拷贝这些包,会自动下载,但是包大下载速度慢,所以需要提前下载完,拷贝到对应的目录里:
shell
cd /opt/software/apache-atlas-sources-1.2.0
# 创建目录
cd distro/
mkdir solr
mkdir hbase
# 拷贝软件包
cp /opt/software/solr-5.5.1.tgz ./solr/
cp /opt/software/hbase-1.1.2.tar.gz ./hbase/操作过程如下所示:
编译源码
shell
cd /opt/software/apache-atlas-sources-1.2.0
export MAVEN_OPTS="-Xms2g -Xmx2g"
mvn clean -DskipTests package -Pdist,embedded-hbase-solr编译过程大约需要 600MB 的Jar包,很慢需要耐心等待:
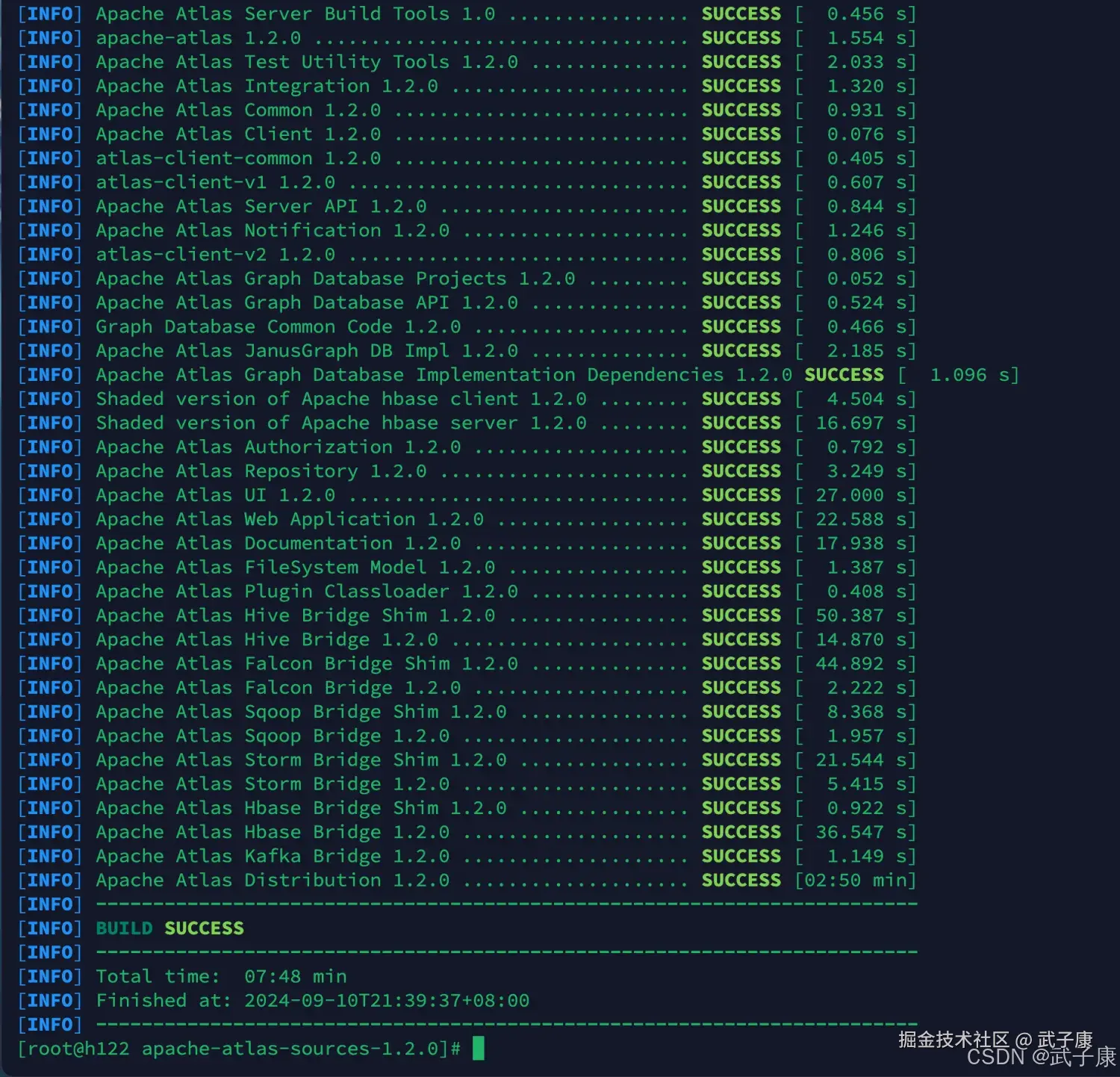
编译结束后,编译结果在:
shell
cd /opt/software/apache-atlas-sources-1.2.0/distro/target可以看到对应的文件:
shell
apache-atlas-1.2.0-bin.tar.gz编译结果如下所示:
5. 错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| Maven 编译 OOM | 内存分配不足,默认堆太小 | 观察编译日志 GC 情况 | 增加 MAVEN_OPTS="-Xms2g -Xmx2g" |
| 依赖下载慢/超时 | 网络问题,官方源下载慢 | 观察 Maven 下载进度 | 提前下载 HBase/Solr 包到 distro 对应目录 |
| 编译失败 pom.xml 报错 | hadoop.version 版本冲突 | 检查 pom.xml 第 652 行 | 修改为 <hadoop.version>2.9.2</hadoop.version> |
| npm 构建失败 | npm 版本不兼容 | 检查 pom.xml 第 645 行 | 修改为 <npm-for-v2.version>3.10.8</npm-for-v2.version> |
| Atlas 启动无响应 | HBase/Solr 未启动 | 检查依赖服务状态 | 确保 HBase 1.1.2 和 Solr 5.5.1 先启动 |
| 元数据采集不到 | Hook 未正确配置 | 检查 Kafka/Hive Hook 日志 | 配置 Hook 并重启对应服务 |