目录
- [Whisper 模型架构详解](#Whisper 模型架构详解)
-
- 一、概述
- 二、整体架构
- [三、Encoder 架构](#三、Encoder 架构)
-
- [3.1 输入处理](#3.1 输入处理)
- [3.2 卷积预处理](#3.2 卷积预处理)
- [3.3 位置编码](#3.3 位置编码)
- [3.4 Encoder Layer 结构](#3.4 Encoder Layer 结构)
- [3.5 Encoder 输出](#3.5 Encoder 输出)
- [四、Decoder 架构](#四、Decoder 架构)
-
- [4.1 输入处理](#4.1 输入处理)
- [4.2 Token 嵌入与位置编码](#4.2 Token 嵌入与位置编码)
- [4.3 Decoder Layer 结构](#4.3 Decoder Layer 结构)
- [4.4 因果掩码(Causal Mask)](#4.4 因果掩码(Causal Mask))
- [五、Attention 机制](#五、Attention 机制)
-
- [5.1 多头注意力实现](#5.1 多头注意力实现)
- [5.2 Attention 计算流程](#5.2 Attention 计算流程)
- [5.3 Cross-Attention 机制](#5.3 Cross-Attention 机制)
- 六、模型变体
-
- [6.1 主要模型类](#6.1 主要模型类)
- [6.2 WhisperForConditionalGeneration](#6.2 WhisperForConditionalGeneration)
- [6.3 WhisperForAudioClassification](#6.3 WhisperForAudioClassification)
- 七、模型规模配置
- 八、特殊技术
-
- [8.1 SpecAugment](#8.1 SpecAugment)
- [8.2 LayerDrop](#8.2 LayerDrop)
- [8.3 推测解码(Speculative Decoding)](#8.3 推测解码(Speculative Decoding))
- [8.4 Encoder 冻结](#8.4 Encoder 冻结)
- 九、数据流总结
- 十、关键代码位置
- 参考资料
Whisper 模型架构详解
一、概述
Whisper 是 OpenAI 发布的自动语音识别(ASR)模型,采用经典的 Encoder-Decoder Transformer 架构。该模型通过在大规模多语言音频数据上进行弱监督训练,实现了强大的语音识别、语音翻译、语言识别等功能。
二、整体架构
Whisper 模型的整体架构遵循标准的 Seq2Seq Transformer 设计:
音频输入 → 特征提取 → Encoder → Decoder → 文本输出核心组件:
| 组件 | 功能 |
|---|---|
| Encoder | 将音频特征编码为高层语义表示 |
| Decoder | 基于编码器输出生成文本序列 |
| Projection Layer | 将隐藏状态映射到词汇表维度 |
三、Encoder 架构
3.1 输入处理
Encoder 的输入是 80维 Log-Mel Spectrogram 特征:
python
# 配置参数
num_mel_bins: int = 80 # Mel频谱的频率维度
max_source_positions: int = 1500 # 最大输入序列长度3.2 卷积预处理
音频特征首先经过两层 1D 卷积:
python
# 第一层卷积
conv1 = nn.Conv1d(num_mel_bins, embed_dim, kernel_size=3, padding=1)
# 输出:保持时间维度不变,将80维特征映射到embed_dim
# 第二层卷积
conv2 = nn.Conv1d(embed_dim, embed_dim, kernel_size=3, stride=2, padding=1)
# 输出:时间维度减半(stride=2),进行下采样每层卷积后使用 GELU 激活函数:
python
inputs_embeds = nn.functional.gelu(self.conv1(input_features))
inputs_embeds = nn.functional.gelu(self.conv2(inputs_embeds))3.3 位置编码
Whisper Encoder 使用 正弦位置编码(Sinusoidal Positional Embeddings):
python
def sinusoids(length: int, channels: int, max_timescale: float = 10000):
"""生成正弦位置编码"""
log_timescale_increment = math.log(max_timescale) / (channels // 2 - 1)
inv_timescales = torch.exp(-log_timescale_increment * torch.arange(channels // 2))
scaled_time = torch.arange(length).view(-1, 1) * inv_timescales.view(1, -1)
return torch.cat([scaled_time.sin(), scaled_time.cos()], dim=1)位置编码是 预计算且不可学习 的:
python
self.embed_positions = nn.Embedding(self.max_source_positions, embed_dim)
self.embed_positions.requires_grad_(False) # 固定位置编码3.4 Encoder Layer 结构
每个 Encoder Layer 包含两个子模块:
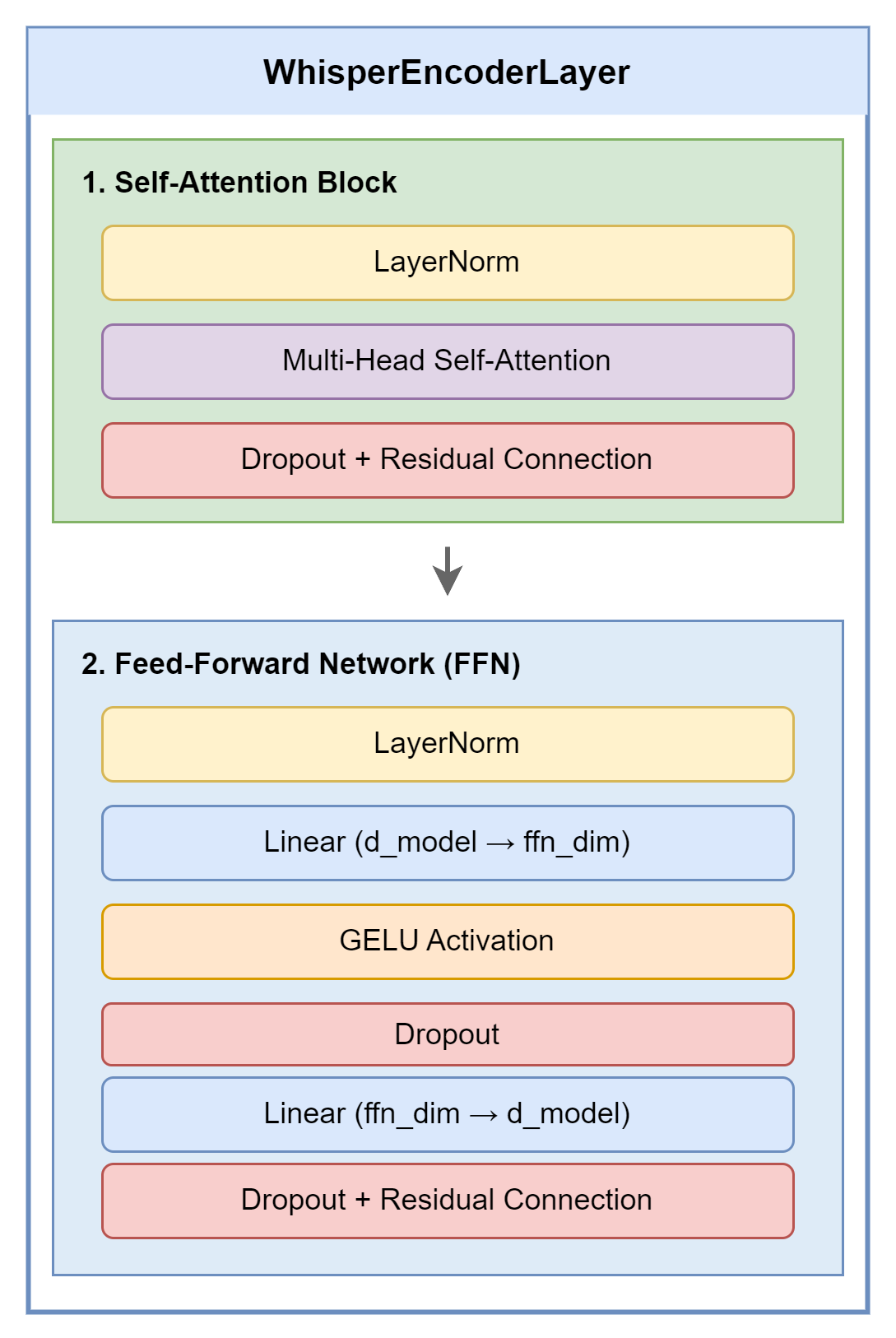
代码实现:
python
class WhisperEncoderLayer(GradientCheckpointingLayer):
def __init__(self, config: WhisperConfig):
self.embed_dim = config.d_model
# Self-Attention
self.self_attn = WhisperAttention(
embed_dim=self.embed_dim,
num_heads=config.encoder_attention_heads,
dropout=config.attention_dropout,
)
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
# Feed-Forward Network
self.fc1 = nn.Linear(self.embed_dim, config.encoder_ffn_dim)
self.fc2 = nn.Linear(config.encoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
self.activation_fn = ACT2FN[config.activation_function] # GELU3.5 Encoder 输出
经过所有 Encoder Layers 后,应用最终的 LayerNorm:
python
hidden_states = self.layer_norm(hidden_states)
return BaseModelOutput(last_hidden_state=hidden_states)四、Decoder 架构
4.1 输入处理
Decoder 接收文本 token 序列作为输入:
python
# 配置参数
vocab_size: int = 51865 # 词汇表大小
max_target_positions: int = 448 # 最大输出序列长度
decoder_start_token_id: int = 50257 # Decoder起始token4.2 Token 嵌入与位置编码
Decoder 使用 可学习的 Token 嵌入 + 可学习的位置编码:
python
# Token Embeddings
self.embed_tokens = nn.Embedding(config.vocab_size, config.d_model, padding_idx)
# Positional Embeddings (learned)
self.embed_positions = WhisperPositionalEmbedding(
self.max_target_positions, config.d_model
)位置编码实现:
python
class WhisperPositionalEmbedding(nn.Embedding):
def forward(self, input_ids, past_key_values_length=0, position_ids=None):
if position_ids is None:
return self.weight[past_key_values_length : past_key_values_length + input_ids.shape[1]]
else:
return self.weight[position_ids]4.3 Decoder Layer 结构
每个 Decoder Layer 包含 三个 子模块:
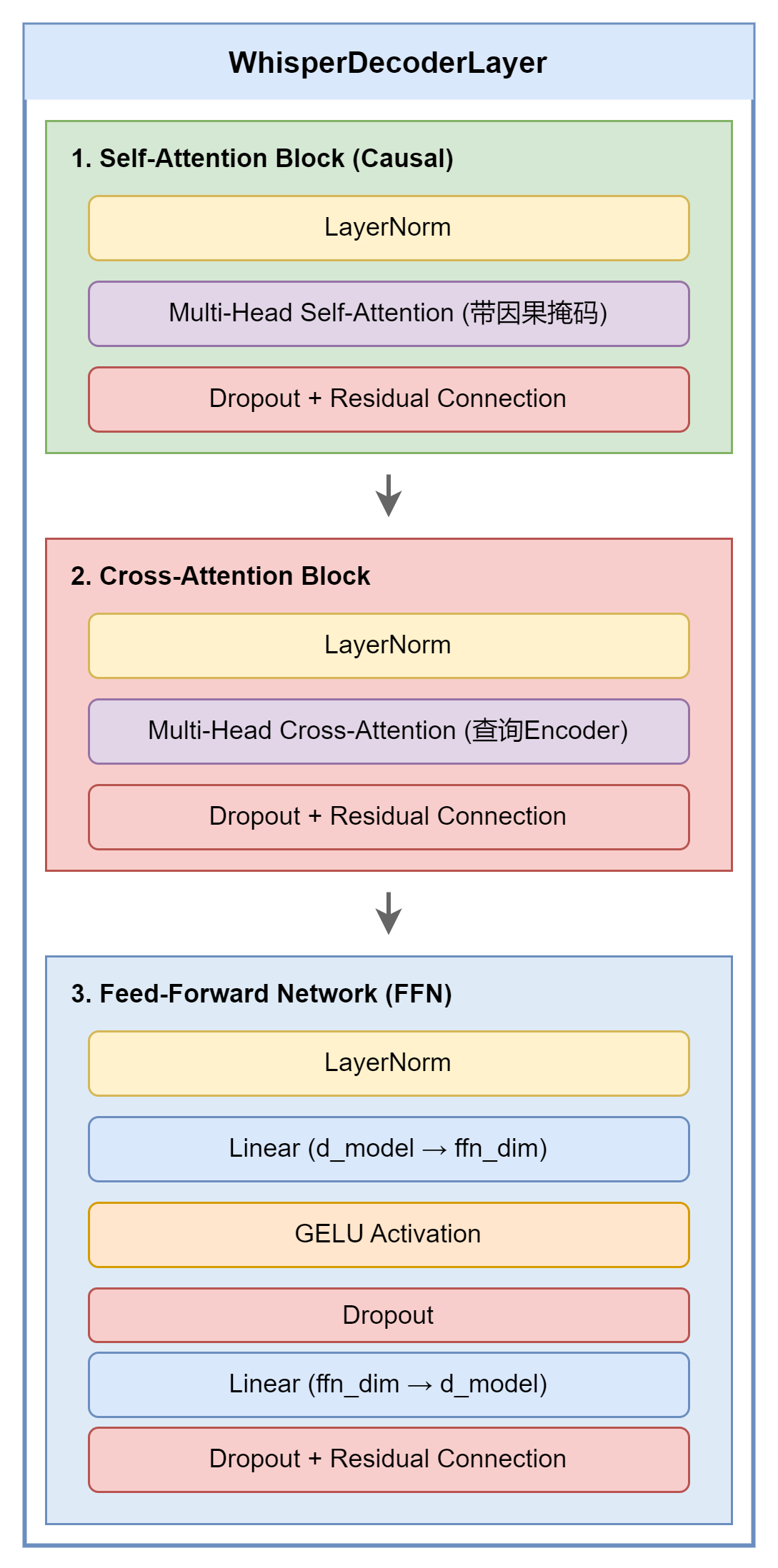
代码实现:
python
class WhisperDecoderLayer(GradientCheckpointingLayer):
def __init__(self, config: WhisperConfig, layer_idx: int | None = None):
# Self-Attention (因果)
self.self_attn = WhisperAttention(
embed_dim=self.embed_dim,
num_heads=config.decoder_attention_heads,
is_decoder=True,
is_causal=True,
layer_idx=layer_idx,
)
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
# Cross-Attention
self.encoder_attn = WhisperAttention(
self.embed_dim,
config.decoder_attention_heads,
is_decoder=True,
layer_idx=layer_idx,
)
self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
# FFN
self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)4.4 因果掩码(Causal Mask)
Decoder 的 Self-Attention 使用因果掩码,确保当前位置只能关注之前的位置:
python
causal_mask = create_causal_mask(
config=self.config,
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
past_key_values=past_key_values,
position_ids=position_ids,
)五、Attention 机制
5.1 多头注意力实现
Whisper 使用标准的缩放点积注意力(Scaled Dot-Product Attention):
python
class WhisperAttention(nn.Module):
def __init__(self, embed_dim, num_heads, dropout=0.0, is_decoder=False, bias=True):
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.scaling = self.head_dim ** -0.5 # 缩放因子
# 投影层
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=False)
self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)5.2 Attention 计算流程
python
def eager_attention_forward(module, query, key, value, attention_mask, scaling, dropout):
# 1. 计算注意力分数
attn_weights = torch.matmul(query, key.transpose(2, 3)) * scaling
# 2. 应用掩码
if attention_mask is not None:
attn_weights = attn_weights + attention_mask
# 3. Softmax归一化
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
# 4. Dropout
attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
# 5. 加权求和
attn_output = torch.matmul(attn_weights, value)
return attn_output, attn_weights5.3 Cross-Attention 机制
在 Decoder 的 Cross-Attention 中:
- Query: 来自 Decoder 当前层
- Key/Value: 来自 Encoder 输出
python
# Cross-Attention调用
hidden_states, _ = self.encoder_attn(
hidden_states, # Query: Decoder的隐藏状态
key_value_states=encoder_hidden_states, # Key/Value: Encoder输出
attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
)六、模型变体
6.1 主要模型类
| 类名 | 功能 | 用途 |
|---|---|---|
WhisperModel |
基础 Encoder-Decoder | 返回隐藏状态,不生成文本 |
WhisperForConditionalGeneration |
带语言模型头 | 自动语音识别(ASR) |
WhisperForCausalLM |
Decoder-only变体 | 辅助模型,用于推测解码 |
WhisperForAudioClassification |
带分类头 | 音频分类任务 |
6.2 WhisperForConditionalGeneration
这是最常用的模型,用于语音识别:
python
class WhisperForConditionalGeneration(WhisperGenerationMixin, WhisperPreTrainedModel):
def __init__(self, config: WhisperConfig):
self.model = WhisperModel(config)
self.proj_out = nn.Linear(config.d_model, config.vocab_size, bias=False)
# 权重绑定:输出层权重与输入嵌入共享
_tied_weights_keys = {"proj_out.weight": "model.decoder.embed_tokens.weight"}输出投影层将隐藏状态映射到词汇表维度:
python
lm_logits = self.proj_out(outputs.last_hidden_state)6.3 WhisperForAudioClassification
用于音频分类(如语言识别、关键词检测):
python
class WhisperForAudioClassification(WhisperPreTrainedModel):
def __init__(self, config):
self.encoder = WhisperEncoder(config) # 只使用Encoder
self.projector = nn.Linear(config.hidden_size, config.classifier_proj_size)
self.classifier = nn.Linear(config.classifier_proj_size, config.num_labels)分类流程:
- Encoder 编码音频 →
hidden_states - Projector 降维 →
projected - Mean Pooling →
pooled_output - Classifier 分类 →
logits
七、模型规模配置
Whisper 提供多种规模版本:
| 模型 | d_model | Encoder Layers | Decoder Layers | Attention Heads | FFN Dim | 参数量 |
|---|---|---|---|---|---|---|
| tiny | 384 | 4 | 4 | 6 | 1536 | 39M |
| base | 512 | 6 | 6 | 8 | 2048 | 74M |
| small | 768 | 12 | 12 | 12 | 3072 | 244M |
| medium | 1024 | 24 | 24 | 16 | 4096 | 769M |
| large | 1280 | 32 | 32 | 20 | 5120 | 1550M |
八、特殊技术
8.1 SpecAugment
训练时可应用 SpecAugment 数据增强:
python
# 配置参数
apply_spec_augment: bool = False
mask_time_prob: float = 0.05 # 时间轴掩码概率
mask_time_length: int = 10 # 时间掩码长度
mask_feature_prob: float = 0.0 # 特征轴掩码概率
mask_feature_length: int = 10 # 特征掩码长度8.2 LayerDrop
支持 LayerDrop 技术,训练时随机跳过某些层:
python
encoder_layerdrop: float = 0.0
decoder_layerdrop: float = 0.08.3 推测解码(Speculative Decoding)
Whisper 支持 Decoder-only 模型作为辅助模型进行推测解码:
python
# 使用 Distil-Whisper 作为辅助模型
assistant_model = WhisperForCausalLM.from_pretrained("distil-whisper/distil-large-v2")
predicted_ids = model.generate(input_features, assistant_model=assistant_model)8.4 Encoder 冻结
可冻结 Encoder 参数,仅训练 Decoder:
python
model.freeze_encoder() # 禁用Encoder梯度计算九、数据流总结
完整的 Whisper 数据流:
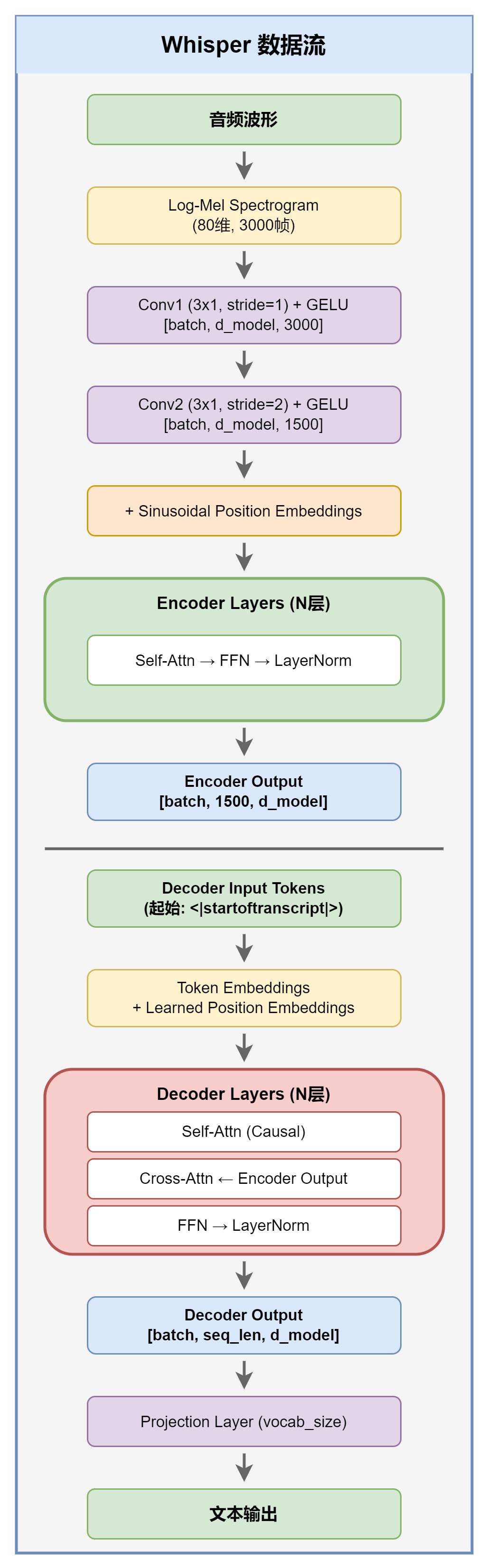
十、关键代码位置
| 功能 | 位置 |
|---|---|
| 模型配置 | configuration_whisper.py |
| Encoder | modeling_whisper.py 中的 WhisperEncoder 类 |
| Decoder | modeling_whisper.py 中的 WhisperDecoder 类 |
| Encoder Layer | modeling_whisper.py 中的 WhisperEncoderLayer 类 |
| Decoder Layer | modeling_whisper.py 中的 WhisperDecoderLayer 类 |
| Attention | modeling_whisper.py 中的 WhisperAttention 类 |
| ASR 模型 | modeling_whisper.py 中的 WhisperForConditionalGeneration 类 |
| 音频分类 | modeling_whisper.py 中的 WhisperForAudioClassification 类 |
参考资料
- OpenAI Whisper 论文: Robust Speech Recognition via Large-Scale Weak Supervision
- HuggingFace Transformers 文档: Whisper Model
- Whisper 源码: transformers/models/whisper