llama.cpp 原生网页聊天教程:一条命令开启,无需第三方UI
前言
很多本地大模型玩家,都不知道新版llama.cpp自带原生网页聊天服务,不用部署Python、不用装额外WebUI,纯原生启动,占用低、速度快,还能局域网共享,手机、平板、其他电脑都能无缝访问。本篇就用最简命令+完整避坑步骤,手把手教你开启。

一、前置准备
-
准备好编译好的llama.cpp(GitHub上可直接下载),拿到llama-server.exe(不是旧版main.exe)
-
准备GGUF格式的量化模型,支持7B/13B/20B等各类主流模型
-
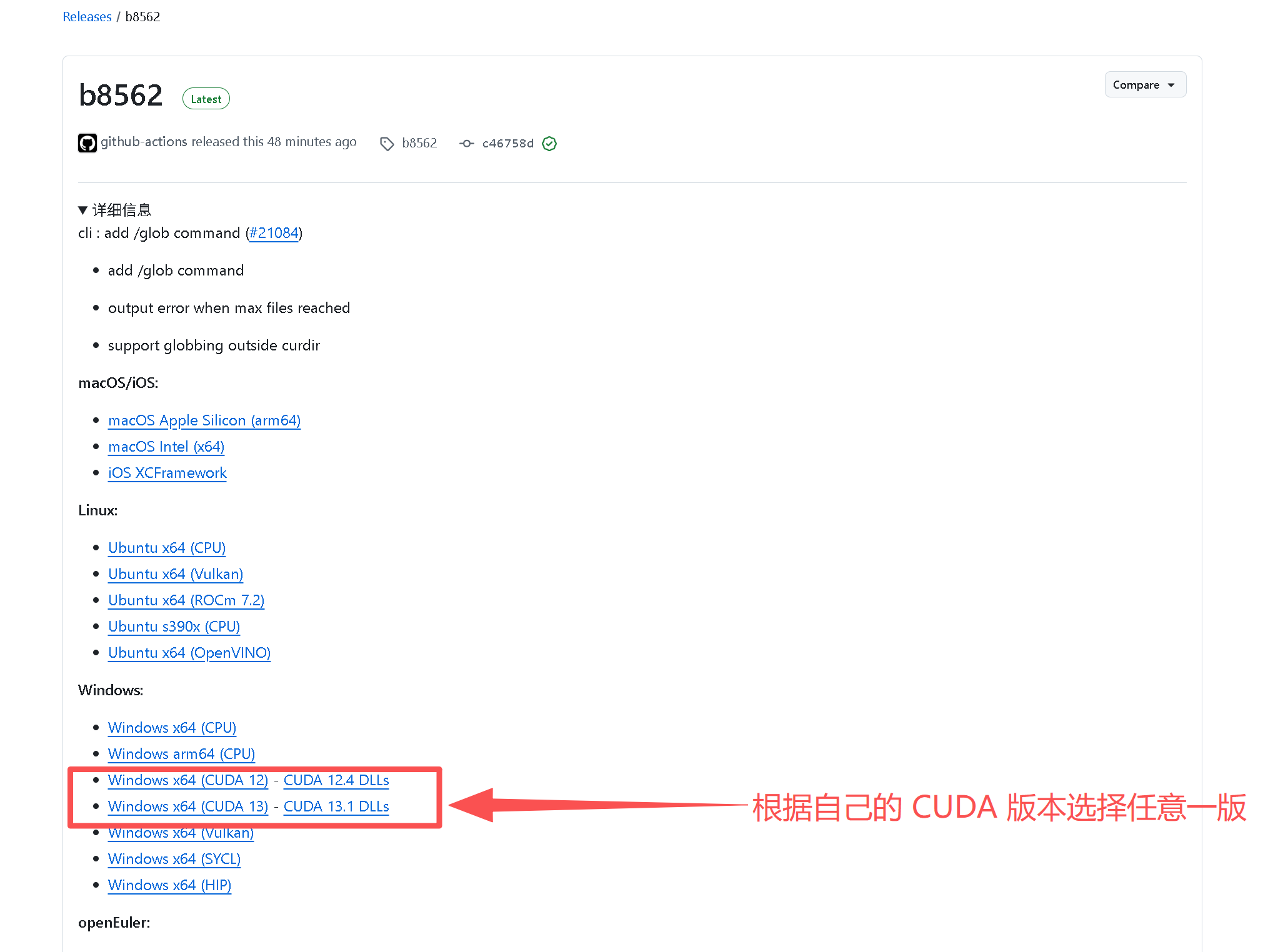
Windows系统,显卡建议带CUDA加速,推理更流畅
-
手机和电脑务必连接同一个局域网/同一个WiFi,不要用手机流量(户外模式需配合其他方法,见文末)
如果要自己编译:
llama-cpp-python 编译 CUDA + Flash Attention 双加速 实战完整指南--Windows
技术复盘:llama-cpp-python CUDA 编译实战 (Windows)
二、极简启动命令(直接复制可用)
这是适配你的20B模型+RTX3090的稳定极简命令,参数少、无坑,直接在终端运行即可:
极简命令示例:
llama-server.exe -m "你的模型.gguf" --host 0.0.0.0我们目前测试实用的命令示例:
llama-server.exe -m "E:\Downloads\OpenAI-20B-NEO-HRRPlus-Uncensored-IQ4_NL.gguf" --host 0.0.0.0 --port 8081 --gpu-layers all --ctx-size 2048命令参数说明(新手不用改)
-
-m:指定本地模型的完整路径,替换成你自己的模型位置即可
-
--host 0.0.0.0:关键参数,开放局域网访问,不加的话只有电脑本机能打开
-
--port 8081:固定网页端口,方便记忆
-
--gpu-layers all:全层加载到显卡,大显存显卡直接拉满速度
-
--ctx-size 2048:对话上下文窗口,按需调整即可
三、启动成功标志
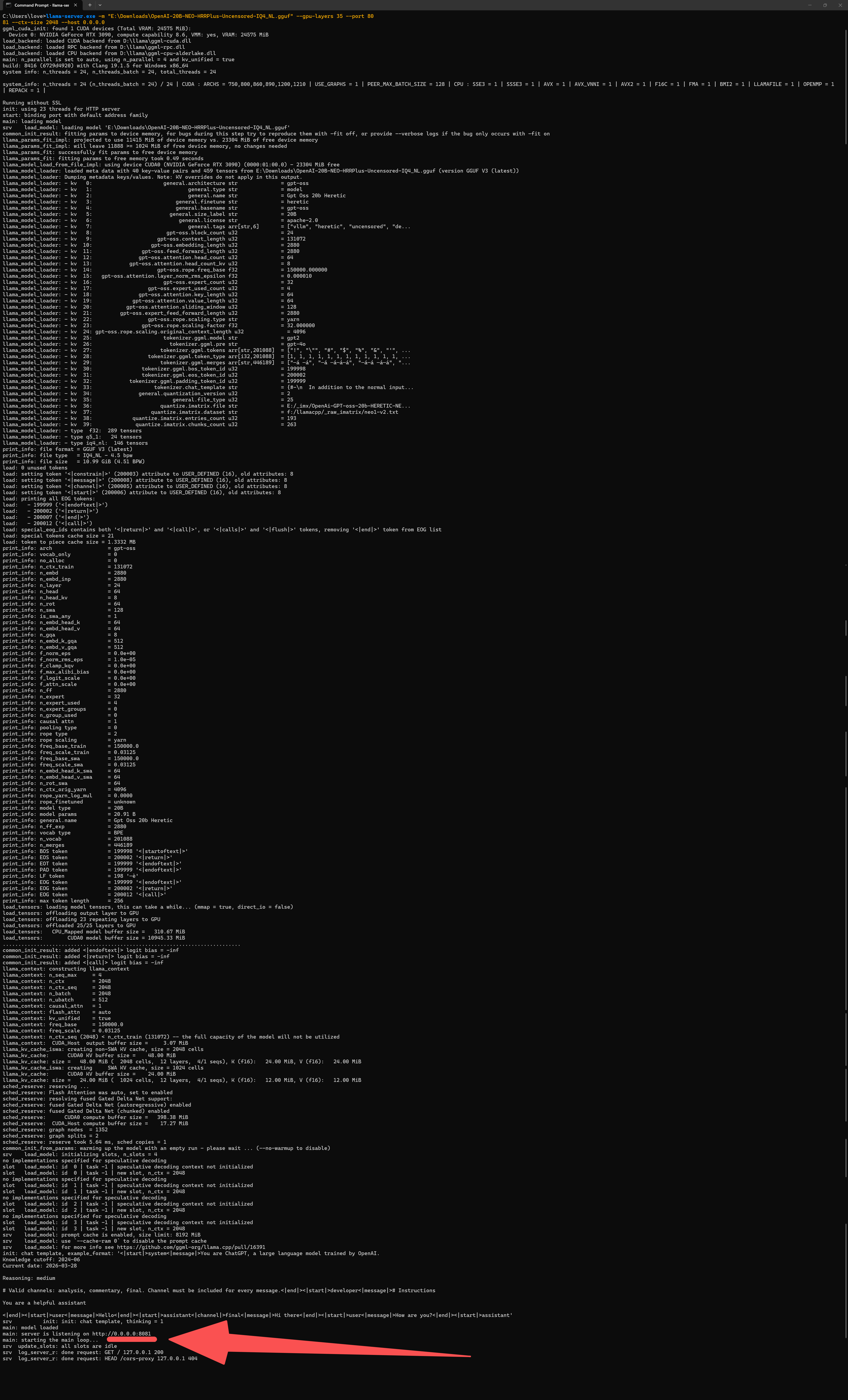
运行命令后,等待模型加载完成,看到最后一行出现这句话,就说明服务启动成功:
main: server is listening on http://0.0.0.0:8081日志里出现的favicon.ico 404报错,只是浏览器请求图标失败,完全不影响聊天,直接忽略即可。
四、访问网页聊天界面
1. 电脑本机访问
浏览器直接输入地址,秒开聊天界面:
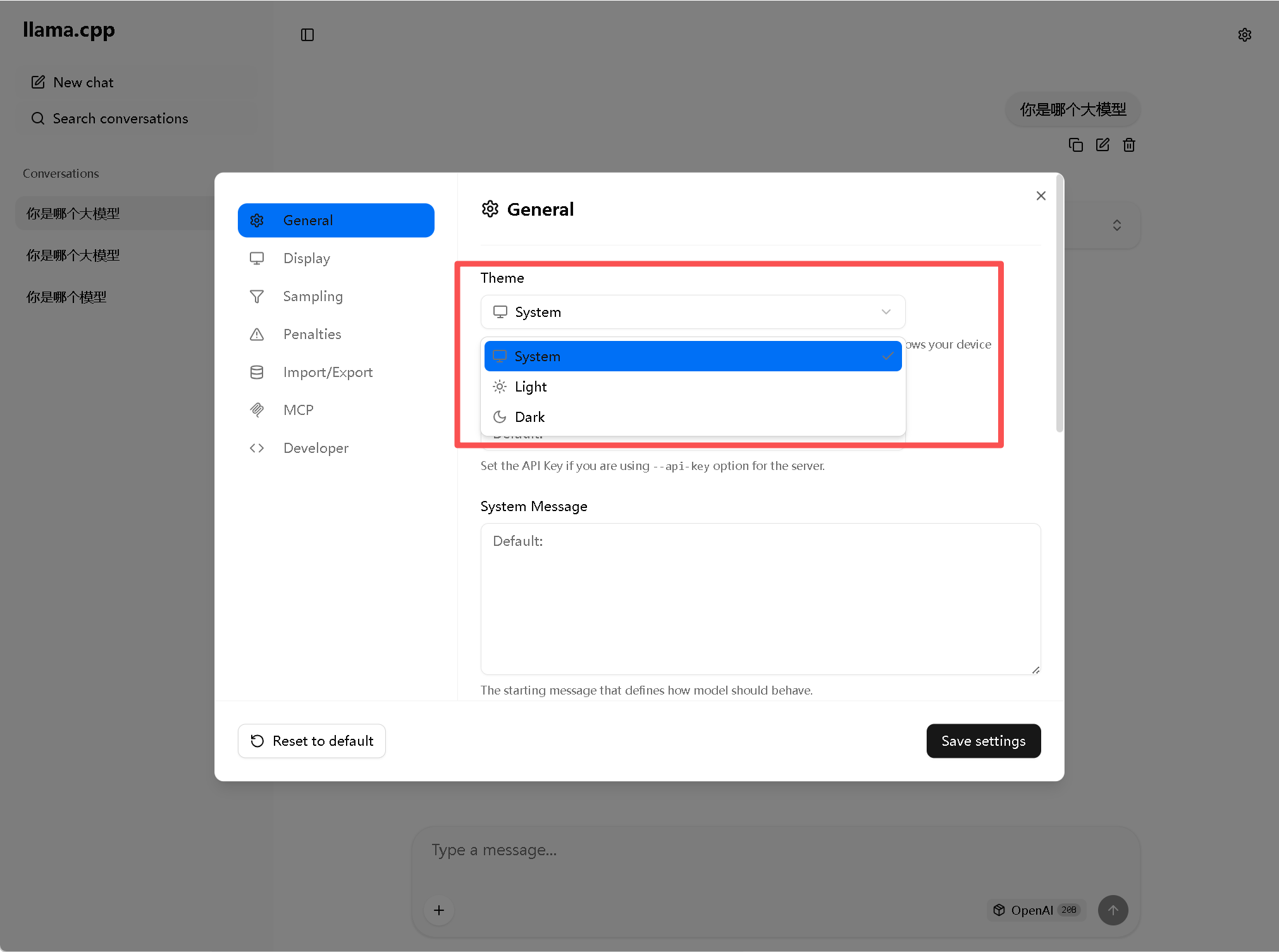
http://localhost:8081注意首次启动时可调节一下浏览器的外观为浅色模式避免看不清聊天内容
之后可以在 llama.cpp 的 UI 设置里,单独设置 UI 的外观模式
2. 手机/局域网其他设备访问(精准地址)
根据自己的IP配置,手机连接同一路由器WiFi后,访问以下任一地址即可:
http://192.168.1.10:8081
http://192.168.1.11:8081比如地址发送到微信中,可在微信里直接打开:
五、必做:放行防火墙(手机打不开的核心解决办法)
电脑能打开、手机打不开,99%是Windows防火墙拦截了端口,按以下步骤一键放行:
-
右键开始菜单,打开管理员权限的PowerShell
-
复制粘贴以下命令,回车运行
New-NetFirewallRule -DisplayName "llamacpp-8081放行" -Direction Inbound -LocalPort 8081 -Protocol TCP -Action Allow
放行之后,手机再访问上面的地址,就能正常打开聊天界面了。
六、关键注意事项(避坑必看)
1. 网络要求:手机和电脑必须连同一个WiFi/局域网,严禁用手机4G/5G流量,否则无法访问。
2. 代理/VPN与组网:日常局域网访问请关闭 Mihomo、梯子等代理;如需跨网使用,建议用 Tailscale 组网,不要用普通代理,避免拦截连接导致打不开页面。
3. 命令不能少参数:必须带--host 0.0.0.0,少了这个参数,仅电脑本机可访问,外部设备一律打不开。
4. 访问地址别写错:一定要用http://,不要写成https://,llama.cpp原生服务不支持SSL,写错会无法访问。
5. 显存适配:小显存显卡可以把--gpu-layers all改成--gpu-layers 20、30等数值,降低显卡负载,避免报错。
七、跨局域网/外网访问(不在同一WiFi也能用)
llama.cpp 本身不带公网穿透/跨网原生能力 ,仅支持同一局域网内访问;想在户外、不同网段使用,推荐用 Tailscale 组网实现,安全稳定、上手简单。
方案1:Tailscale 组网(推荐)
-
电脑和手机都安装并登录同一个 Tailscale 账号
-
保持 llama-server 正常运行(命令不变,仍带 --host 0.0.0.0)
-
查看电脑的 Tailscale IP(形如
100.xxx.xxx.xxx)ipconfig -
手机用流量/其他WiFi,访问:
http://100.xxx.xxx.xxx:8081即可
我们的电脑已安装配置 Tailscale,直接登录配对后就能跨网使用,无需额外端口映射、不用暴露公网,隐私更安全。
方案2:其他公网方式(不推荐新手)
不建议直接端口映射公网,容易暴露端口存在风险;也可选用 ngrok 等内网穿透工具,但配置繁琐、稳定性和速度不如组网方案。
八、网页功能说明
原生网页UI自带完整聊天功能,支持多轮对话、上下文记忆,还能调节温度、生成长度、重复惩罚等参数,不用额外配置,开箱即用,同时还兼容OpenAI标准接口,可对接其他客户端。