前言
决策树算法是一种监督学习算法,英文是Decision tree。
决策树思想的来源非常朴素,试想每个人的大脑都有类似于if-else这样的逻辑判断,这其中的if表示的是条件,if之后的else就是一种选择或决策。程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
一、核心定位与基础概念
1. 核心定位
决策树是一种监督学习算法 ,既可以用于 分类任务,也可以用于回归任务。它的核心思想是通过对数据特征进行一系列"是/否"的判断,最终将样本划分到不同的类别(分类树)或预测一个连续值(回归树)。整个过程类似于我们日常生活中做决定时的流程图,因此具有很强的可解释性。
适用场景:分类(二分类 / 多分类,如风控、情感分析)、回归(预测连续值,如房价、销量),无需特征标准化,可解释性极强。
2. 基本结构(倒生长的树)
- 根节点:包含全部样本,是第一个判断条件。
- 内部节点:一个特征判断(如「年龄 ≤ 30?」「是否有房?」)
- 分支:特征判断的结果(如「是 / 否」「高 / 中 / 低」)
- 叶子节点:最终决策结果(分类标签:「见 / 不见」;回归值:「房价 80 万」)
- 根→叶的一条路径 = 一条决策规则
3. 核心目标
找到最优特征 + 最优分割点 ,让划分后的子集更纯。最终实现:
- 分类树:叶子节点的类别纯度尽可能高(某一类占比趋近 100%)
- 回归树:叶子节点内的数值方差尽可能小
4. 通俗演绎-"猜动物"游戏
想象一下,你心里想好一种动物,让朋友来猜。朋友的提问会像一棵树一样展开:
-
第一问:它是哺乳动物吗?
-
-
如果是 → 进入下一个问题:它会飞吗?
-
-
如果不会飞 → 再问:它有条长鼻子吗?
-
- 如果有 → 可能是大象
- 如果没有 → 可能是狗
-
-
如果不是哺乳动物 → 下一个问题:它有鳞片吗?
-
- 如果有 → 可能是鱼
- 如果没有 → 可能是鸟
-
这就是决策树的工作方式:
- 每个问题 = 树上的一个节点(特征判断)
- 每个答案 = 一条分支(特征值)
- 最终的猜测 = 一片叶子(预测结果)
二、决策树构建步骤
整体三步
- 特征选择
选择分类 / 回归能力最强的特征,让划分后的子集更 "纯"。
- 决策树生成
按最优特征对数据集递归划分,生成完整决策树。
- 剪枝
简化树结构,防止过拟合,提升模型泛化能力。
特征选择准则
为了找到"最优"划分特征,常用以下指标衡量划分前后的纯度提升:
- 信息增益(ID3算法):基于熵的减少量。熵越低,纯度越高。
- 信息增益比(C4.5算法):对信息增益进行归一化,避免偏向取值多的特征。
- 基尼系数(CART算法):衡量数据集的不纯度,值越小越纯。
递归构建过程
- 从根节点开始,用最优特征将数据集划分为若干子集。
- 对每个子集重复特征选择与划分操作。
- 直到满足停止条件 :
- 子集内样本属于同一类别(熵 = 0/ 基尼 = 0)
- 没有更多特征可用
- 样本数量太少如 < 5个,避免过拟合)
- 达到预设最大深度(如最多5层)
三、ID3决策树(基于信息增益)
1. 信息熵(衡量样本「乱不乱」)
- 度量随机变量的不确定性
- 分布越均匀,熵越大,数据越混乱(如类别占比 {0.5, 0.5},H=1)
- 分布越集中,熵 越小,数据越纯净(如类别占比 {1, 0},H=0)
- 完全纯:熵 = 0
数学公式:
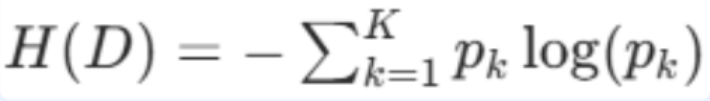
信息熵 = -(每个类别占比 × 该占比的对数)之和
注释:
H(D):数据集 D 的信息熵,取值 [0,+∞)
K:数据集 D 的类别总数
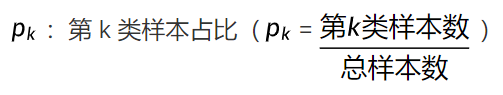
log:默认以 2 为底(bit:比特,信息量单位),也可用自然对数(nat:纳特,全称自然比特,以自然数e为底的对数),不影响相对大小
例子 :
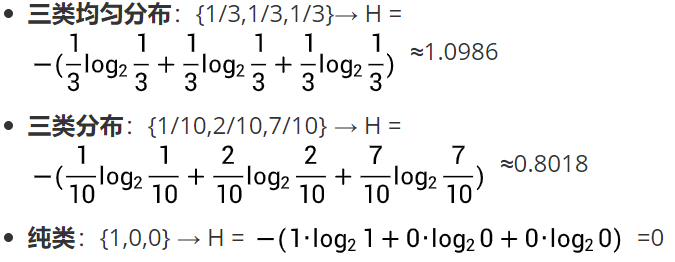
2. 条件熵(分岔后「还乱不乱」)
条件熵 H(D∣A) 表示在已知随机变量 A 的条件下,随机变量 D 的不确定性(熵)。
核心意义:
衡量「用特征 A 分岔后,样本整体的混乱程度」,条件熵越小,分岔效果越好。
数学公式:
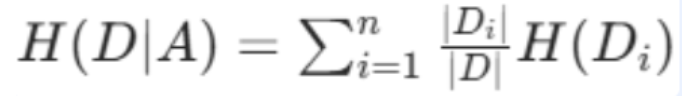
条件熵 = (每个分岔子集的样本占比 × 该子集的信息熵)之和
注释:
H(D|A):用特征 A 划分后,数据集 D 的熵
A:待划分特征,有 n 个取值,将 D 划分为 D1,D2,...,Dn
例子 :

与信息熵的关系
- 信息熵 H(Y):只考虑 Y 本身的不确定性。
- 条件熵 H(Y∣X):考虑在知道 X 之后 Y 剩余的不确定性。
- 两者差值就是 X 带给 Y 的信息量(信息增益)。
3. 信息增益(ID3 决策树:选最管用的特征)
定义
信息增益 = 熵的减少量
表示:用某个特征对数据集进行划分后,不确定性(混乱程度)减少了多少。
核心思想
- 划分前:数据集有一定混乱程度,记为 H(D)(经验熵)
- 划分后:按特征 A 分成若干子集,混乱程度降低,记为 H(D|A)(条件熵)
- 信息增益就是:划分后比划分前 "纯" 了多少
数学公式:
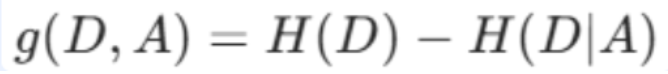
信息增益 = 分岔前的混乱度(原熵) - 分岔后的混乱度(条件熵)
注释:
-
g(D,A):特征 A 对数据集 D 的信息增益
-
H(D):划分前的熵
-
H(D∣A):划分后的条件熵
核心意义
- 代表「特征 A 能让样本不确定性减少多少」
- 增益越大 → 特征 A 分类能力越强,越优先选择
- 缺陷:偏向取值多的特征(如「ID、编号」这类无意义但取值多的特征),这类特征会把数据分得很细,但****没有泛化能力****,容易过拟合。
ID3构建流程
-
计算每个特征的信息增益
-
选择信息增益最大的特征作为当前节点
-
根据该特征划分数据集
-
对子集递归重复
四、C4.5决策树(基于信息增益率,修正ID3的偏向)
1. 信息增益率
为解决 信息增益(ID3) 偏向多值特征的问题,引入信息增益率 。在信息增益的基础上,除以特征自身的熵,惩罚取值过多的特征。
数学公式 :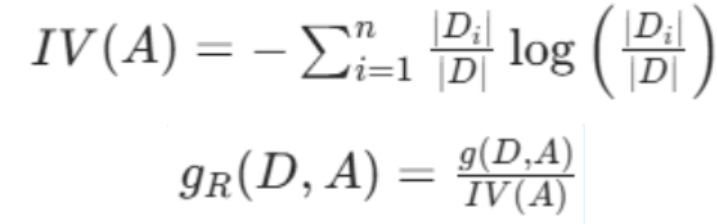
信息增益率 = 信息增益 ÷ 特征本身的「选项复杂度」(特征熵)
注释:
-
IV(A):特征 A 的固有值(特征熵),特征取值越多,IV(A) 越大
-
其余符号同信息增益
核心意义:
通过「特征熵」惩罚取值多的特征,缓解 ID3 树的偏向问题:
- 取值多的特征:IV(A) 大 → 增益率被压低
- 取值少的特征:IV(A) 小 → 增益率更能体现真实分类能力
特点
- 可处理连续值(通过二分法)
- 可处理缺失值
- 比 ID3 更稳定
五、CART决策树(分类与回归树)
CART 是二叉树,既可分类也可回归。
1. 分类树:基尼指数
作用
- 和信息熵 作用完全一样 :衡量集合的纯度
- 计算比熵更快,不用对数,只做乘加减
- 是 CART 决策树 的划分标准
数学公式 :
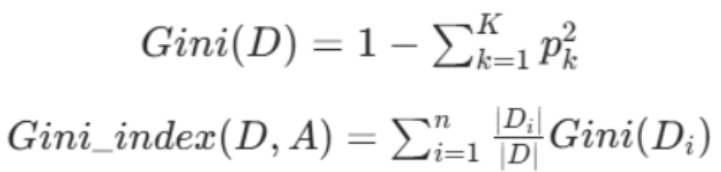
-
基尼值 = 1 -(每个类别占比的平方)之和
-
基尼指数 = (每个分岔子集的样本占比 × 该子集基尼值)之和
核心意义:
- 基尼值:衡量「随机抽两个样本,类别不一致的概率」,取值 [0,1)
- 基尼值越小 → 样本越纯净(如全是同一类,Gini=0)
- 基尼指数:分岔后整体不纯度,越小则特征 A 分类能力越强
- 相比熵:计算更快,无对数运算,适合工程实现
2. 回归树(预测连续值):平方损失
- 回归树用平方损失(均方误差)做划分准则
- 每个叶子节点输出该区域样本的均值
- 目标是让真实值与预测值的平方误差最小
数学公式:
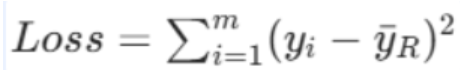
平方损失 = (每个样本真实值 - 该分支所有样本平均值)的平方之和
核心意义:
-
分支预测值 = 该分支所有样本的平均值
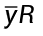
-
分岔时,选择「总平方损失最小」的特征和分割点,损失越小则分支预测越准
构建流程
-
对每个特征,生成候选分割点(如连续特征取相邻样本值的中点)
-
对每个候选点,将样本分为左右两枝,分别计算两枝的平方损失,求和得总损失
-
选总损失最小的「特征 + 分割点」,完成一次二叉分裂
-
对左右子树递归分裂,直到满足终止条件
-
叶子节点输出:该节点所有样本的平均值
六、三种决策树对比
| 决策树类型 | 特征选择标准 | 分支方式 | 支持特征类型 | 优点 | 缺点* |
|---|---|---|---|---|---|
| ID3(1975) | 信息增益 | 多分支(特征有 n 个取值则分 n 支) | 仅离散特征 | 计算简单,可解释性强 | 偏向取值多的特征;不支持连续 / 缺失值 |
| C4.5(1993) | 信息增益率 | 多分支 | 离散 + 连续(自动分阈值)+ 缺失值 | 修正 ID3 缺陷;适配更多数据类型 | 计算复杂度高;大数据集性能差 |
| CART(1984) | 基尼指数(分类)/ 平方损失(回归) | 二叉分支(无论特征取值多少,仅分 2 支) | 离散 + 连续 + 缺失值 | 计算速度快;同时支持分类 + 回归 | 多分类需多次拆分;对异常值敏感 |
七、决策树剪枝(防止过拟合)
1. 为什么要剪枝
树分裂过细 → 会过度拟合训练数据的噪声(如个别异常样本),对新数据预测不准 → 剪枝就是「剪掉无用细枝」,简化模型,降低复杂度,提高泛化能力。
2. 两种剪枝方式
(1)预剪枝(提前刹车)
-
逻辑:构建树时,每准备分裂一个节点,先在验证集上测试:
-
- 若分裂后验证集准确率提升 → 允许分裂
- 若分裂后准确率不变 / 下降 → 停止分裂,直接标记为叶子节点
-
优点:计算快,避免生成无用分支
-
缺点:可能「欠拟合」,错过后续更优的分裂
(2)后剪枝(先长后剪)
-
逻辑:先把树完整生长到最细(所有叶子都纯),再从下往上检查:
-
- 尝试将某个子树替换为叶子节点(取该子树样本的多数类 / 平均值)
- 若替换后验证集准确率提升 → 剪掉该子树
-
优点:通常比预剪枝效果好,不易欠拟合
-
缺点:需先生成完整树,计算量大、耗时久
八、决策树 API(sklearn)
1. 分类决策树(CART 树,默认基尼指数)
python
from sklearn.tree import DecisionTreeClassifier
# 实例化模型(核心参数控制过拟合)
model = DecisionTreeClassifier(
criterion='gini', # 可选 'gini'(基尼)或 'entropy'(信息增益)
max_depth=5, # 树最大深度(预剪枝:限制层数)
min_samples_split=10, # 至少 10 个样本才允许分裂
min_samples_leaf=5, # 每个叶子至少 5 个样本
random_state=42 # 固定随机种子,结果可复现
)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test) # 预测类别
y_pred_proba = model.predict_proba(X_test) # 预测各类别概率
# 查看特征重要性(哪个特征最管用)
print("特征重要性:", model.feature_importances_)2. 回归决策树(CART 回归树)
python
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(
criterion='squared_error', # 回归专用:平方损失
max_depth=3,
min_samples_leaf=3,
random_state=42
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test) # 输出连续预测值3. 模型评估
python
# 分类评估
from sklearn.metrics import accuracy_score, classification_report
print("准确率:", accuracy_score(y_test, y_pred))
print("分类报告:\n", classification_report(y_test, y_pred))
# 回归评估
from sklearn.metrics import mean_squared_error, r2_score
print("均方误差:", mean_squared_error(y_test, y_pred))
print("拟合度 R²(越接近1越好):", r2_score(y_test, y_pred))4、可视化
python
from sklearn.tree import plot_tree
plot_tree(estimator, feature_names, class_names, filled=True)九、案例:泰坦尼克号生存预测
python
'''
利用CART分类树模型 对泰坦尼克号幸存者数据进行分类(幸存估计)
# 1. 加载数据.
# 2. 数据的预处理.
# 2.1 提取特征和标签.
# 2.2 发现Age列有缺失, 我们用该列的 平均值做填充.
# 2.3 处理字符串类型的特征
# 2.4 数据集分割
# 3.1 模型定义
# 3.2 模型训练
# 3.3 模型预测
# 3.4 模型评估
'''
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier # 从 tree库中加载 决策树分类器
from sklearn.metrics import classification_report # 分类器性能评估报告
import matplotlib.pyplot as plt # 绘图工具
from sklearn.tree import plot_tree # 绘制决策树专用工具
# 1. 加载数据.
data = pd.read_csv(r'file/train.csv')
#data.info()
# 2. 数据的预处理.
# 2.1 提取特征和标签.
x = data[['Pclass', 'Sex', 'Age']] # x = data.iloc[:, [1, 2, 4]]
y = data['Survived']
#print(x.head(5))
#print(y.head(5))
# 2.2 发现Age列有缺失, 我们用该列的 平均值做填充.
x = x.copy() # 拷贝一次,避免对原数据集进行修改 而产生报警
#求年龄特征的平均值
avg = x['Age'].mean()
#print(avg)
x['Age']= x['Age'].fillna(avg)
#print(x['Age'])
# 2.3 处理字符串类型的特征
# 如果不指定columns,则默认处理所有字符串列
x = pd.get_dummies(x, columns=['Sex'])
# 消除重复的列 axis = 1 整列删除 inplace是否修改原数据集
x.drop(columns=['Sex_male'], axis=1, inplace=True)
x.info()
# 2.4 数据集分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22, stratify=y)
# 3.1 模型定义
model = DecisionTreeClassifier(criterion='gini', max_depth=10)
# 3.2 模型训练
model.fit(x_train, y_train)
# 3.3 模型预测
y_pred = model.predict(x_test)
print(y_pred)
# 3.4 模型评估
# 生成评估报告 输入 真实标签 和 预测标签
print(classification_report(y_test,y_pred))
# 绘制决策树
# 设置画布大小, 160*100dpi = 16000个像素
plt.figure(figsize=(160,80))
# 绘制决策树
# 参1 : 模型 参2 :是否填充节点颜色 参3 :特征名称 参4 :树最大深度 参5 :字体大小
plot_tree(model, filled=True, feature_names=x.columns, max_depth=10, fontsize=8 )
# 保存图片
plt.savefig('file/titanic.png')
plt.show()