目录
[一 inode和 datablock映射](#一 inode和 datablock映射)
[二 目录与文件名](#二 目录与文件名)
[三 路径解析](#三 路径解析)
[四 路径缓存](#四 路径缓存)
[五 挂载分区](#五 挂载分区)
[1 定义](#1 定义)
[2 一个实验](#2 一个实验)
[3 一个结论](#3 一个结论)
[六 软硬连接](#六 软硬连接)
[1 硬链接](#1 硬链接)
[2 软连接](#2 软连接)
一 inode和 datablock映射
inode:存储文件属性(大小、权限、创建时间、修改时间、链接数...),不存文件名、不存文件内容;
block:存储文件实际内容 (文本、图片、视频数据),是磁盘最小读写单元;
i_block15:inode 里的指针数组,专门用来指向存储文件内容的 block
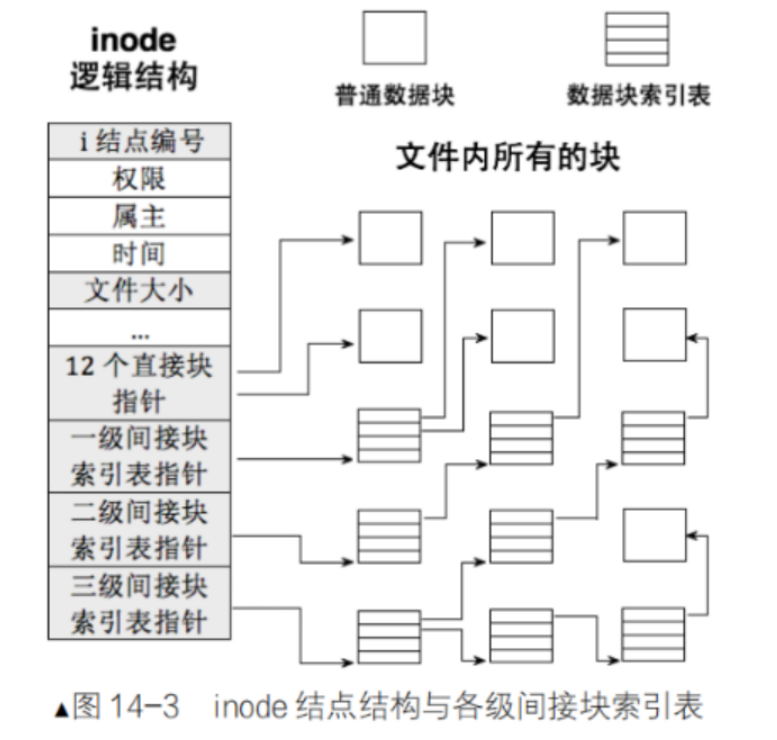
在上图中,我们看到Linux系统中对应的15个下标的元素,最终前12个是直接索引,后面分别是一级,二级,三级索引,对应文件内容保存的大小逐级扩增。所以Linux的文件可以定义很大
但是一个组才多大?可以并没有规定文件只能在一个组里面存储
块可以跨组创建
结论:
- 磁盘分区后的格式化操作 ,本质是对分区进行结构化分组,并在每个分组中写入超级块(SB)、组描述符表(GDT)、块位图、Inode 位图等核心管理数据,这些用于管理磁盘存储的所有元数据,统称为文件系统。
- 只要获取到文件的 Inode 编号,就能精准定位到该 Inode 所属的磁盘分组,进而在对应分组中找到具体的 Inode 节点。
- 一旦找到 Inode,文件的全部属性(权限、大小、时间等)和文件内容(通过 i_block 映射的数据块)就可以完整获取,文件的所有信息就此确定。
二 目录与文件名
目录有自己唯一的inode编号
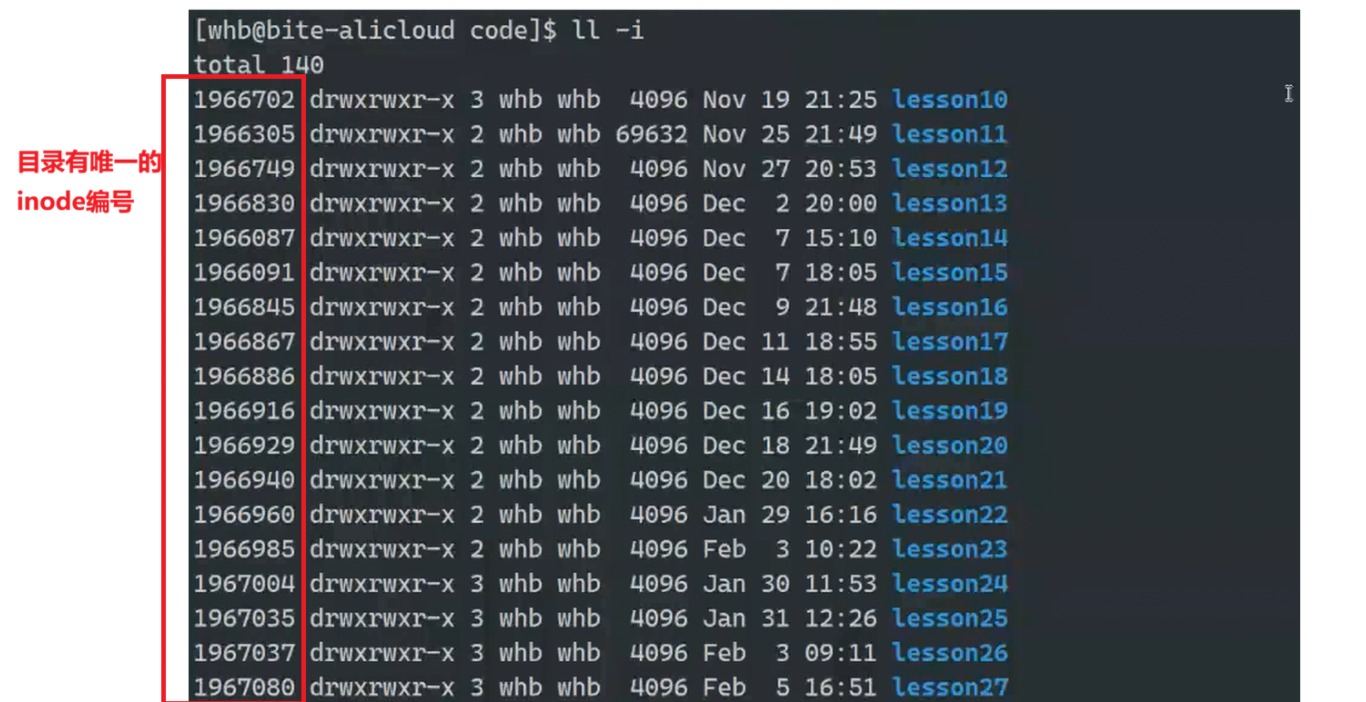
所以目录是文件
我们可以通过inode number找到对应的分区,之后找到指定文件
但是我们查找文件一般不用inode number,而是文件名
站在磁盘角度,在存储方式上,目录和普通文件的存储方式是一摸一样的!
在目录的内容里,存在inode number和文件名的映射关系,怎么证明?
我们来看一段验证代码:
cs
// readdir.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <directory>\n", argv[0]);
exit(EXIT_FAILURE);
}
DIR *dir = opendir(argv[1]); // 系统调⽤,⾃⾏查阅
if (!dir) {
perror("opendir");
exit(EXIT_FAILURE);
}
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) { // 系统调⽤,⾃⾏查阅
// Skip the "." and ".." directory entries
if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..")
== 0) {
continue;
}
printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned
long)entry->d_ino);
}
closedir(dir);
return 0;
}
cs
whb@bite:~/code/test/test$ ./readdir /
Filename: mnt, Inode: 1048577
Filename: tmp, Inode: 1179650
Filename: sys, Inode: 917506
Filename: libx32, Inode: 17
Filename: srv, Inode: 786434
Filename: lib64, Inode: 16
Filename: sbin, Inode: 18
Filename: dev, Inode: 131073
Filename: swapfile, Inode: 12
Filename: run, Inode: 1048578
Filename: log.txt, Inode: 20
Filename: proc, Inode: 1179649
Filename: lost+found, Inode: 11
Filename: etc, Inode: 262145
Filename: lib, Inode: 14
Filename: opt, Inode: 917505
Filename: usr, Inode: 1179651
Filename: lib32, Inode: 15
Filename: boot, Inode: 655361
Filename: var, Inode: 655365
Filename: product-service-1.0-SNAPSHOT.jar, Inode: 19
Filename: bin, Inode: 13
Filename: media, Inode: 393217
Filename: home, Inode: 786433
Filename: root, Inode: 655362
whb@bite:~/code/test/test$ ls -li /
total 1014436
13 lrwxrwxrwx 1 root root 7 Sep 14 2020 bin -> usr/bin
655361 drwxr-xr-x 3 root root 4096 May 6 14:34 boot
2 drwxr-xr-x 17 root root 3880 Jul 17 10:39 dev
262145 drwxr-xr-x 98 root root 4096 Oct 27 14:56 etc
786433 drwxr-xr-x 6 root root 4096 Sep 4 14:56 home
14 lrwxrwxrwx 1 root root 7 Sep 14 2020 lib -> usr/lib
15 lrwxrwxrwx 1 root root 9 Sep 14 2020 lib32 -> usr/lib32
16 lrwxrwxrwx 1 root root 9 Sep 14 2020 lib64 -> usr/lib64
17 lrwxrwxrwx 1 root root 10 Sep 14 2020 libx32 ->
usr/libx32
20 -rw-r--r-- 1 root root 461 Jul 16 15:51 log.txt
11 drwx------ 2 root root 16384 Sep 14 2020 lost+found
393217 drwxr-xr-x 4 root root 4096 Sep 14 2020 media
1048577 drwxr-xr-x 3 root root 4096 Oct 17 17:47 mnt
917505 drwxr-xr-x 3 root root 4096 May 6 14:37 opt
1 dr-xr-xr-x 169 root root 0 Jul 17 10:26 proc
19 -rw-r--r-- 1 root root 45457485 Feb 3 2024 product-service1.0-SNAPSHOT.jar
655362 drwx------ 13 xjh xjh 4096 Oct 27 09:36 root
2 drwxr-xr-x 25 root root 780 Oct 28 20:36 run
18 lrwxrwxrwx 1 root root 8 Sep 14 2020 sbin -> usr/sbin
786434 drwxr-xr-x 2 root root 4096 Apr 23 2020 srv
12 -rw------- 1 root root 993249280 Sep 14 2020 swapfile
1 dr-xr-xr-x 13 root root 0 Jul 17 18:26 sys
1179650 drwxrwxrwt 20 root root 4096 Oct 28 20:39 tmp
1179651 drwxr-xr-x 14 root root 4096 Nov 10 2023 usr
655365 drwxr-xr-x 12 root root 4096 Jun 16 16:40 var打开目录用的系统调用:opendir 它的返回类型是DIR*,是系统封装的一种类型,可以当作结构体
换句话说,访问文件,都必须先访问文件所在的目录,dir也是一个文件,也有自己的文件名和inode
所以,同一个目录下,不能存在同名路径!!
三 路径解析
路径解析,就是操作系统把你输入的 "路径字符串",一步步翻译成 "文件的 inode 号" 的全过程
操作系统会从根目录 / 开始,一层一层拆、一层一层找,每一步都只干一件事:
根据目录名 → 找到下一层的 inode → 直到找到目标文件。
任何一个Linux文件,都直接或间接包含路径,有些看不到只是隐藏起来了
在Linux内核角度,只认绝对路径,附加的考虑相对路径--->所有文件必须有路径,包含普通文件和目录,符合路径解析的需求。shell ,pwd,进程....由不同的角色提供路径
在Linux系统中,任何一个文件,都必须从根目录开始,进行路径解析,会把每个目录的内容都读出来
四 路径缓存
频繁的进行路径解析,非常的消耗资源和时间,效率会很低---->解决办法:路径缓存
例如:首次使用find查找路径,会比较慢,但是后面就快了,因为路径被缓存起来了
问题:在Linux中,操作系统要不要对缓存的目录进行管理?
要!先描述,再组织
在内核中,描述被打开的目录:struct dentry
在组织时,核心的数据结构是以多叉树的结构,把目录结构组织在内存中
cs
struct dentry {
struct inode *d_inode; // 指向对应的 inode 节点
struct dentry *d_parent; // 指向父目录的 dentry(回指路径)
struct qstr d_name; // 目录/文件名
struct list_head d_subdirs; // 子目录/文件的链表(多叉树结构)
};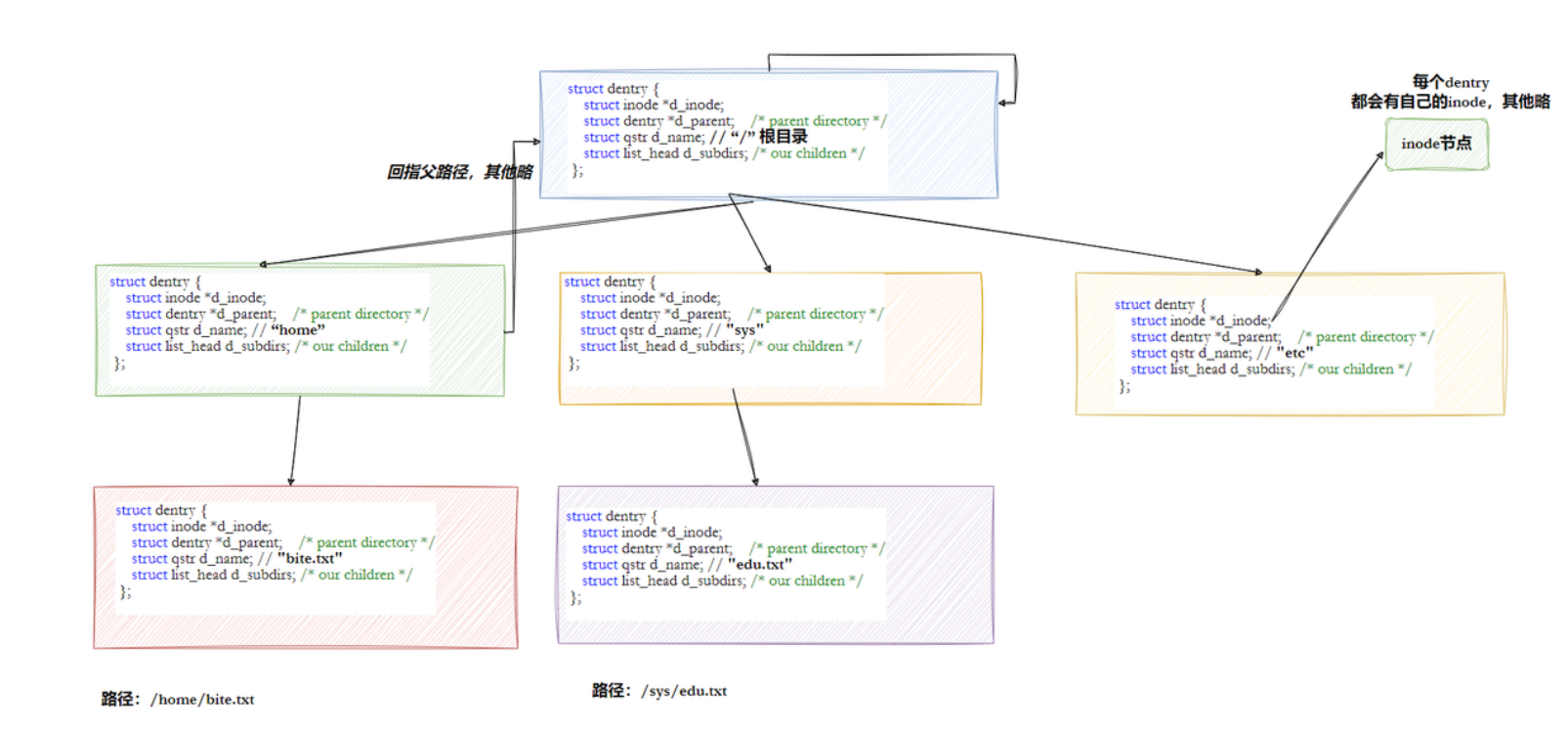
每个 dentry 都关联一个 inode,包含文件 / 目录的属性与数据块指针。
目录的 dentry 会通过 d_subdirs 管理所有子节点,形成多叉树结构。
普通文件的 dentry 是树的叶子节点,没有子节点
在以前学习的似乎,我们说过Linux的结构是一个树型结构,但是磁盘中没有存在严格的树型结构,所以我们口中的树状结构是内核中的树型结构
每个dentry都会有自己inode,每一个目录都会有一个dentry(前提是访问了它)
普通的文件也有dentry,相当于叶子节点
我们把整个的多叉树结构叫做dcache!!学名是路径缓存
五 挂载分区
1 定义
我们已经能够根据 inode 号在指定分区内定位文件,也能根据目录文件的内容,找到目标 inode。在单个分区内,我们几乎可以对文件系统进行任意操作。
但随之而来的问题是:
inode 无法跨分区使用,而 Linux 系统又可以挂载多个分区,那我该如何确定当前操作的文件 / 路径究竟位于哪一个分区呢?
我们要解决这个问题,要了解一些运维:一个磁盘被用户使用,要经过哪些步骤?
(1)分区
(2)格式化:本质是想分区写入文件系统,也就是管理信息
(3)格式化完成的分区,是没有办法被直接使用的,在Linux中,分区需要挂载
挂载是把指定的分区,和Linux系统中指定的目录关联起来,因为和目录关联起来,就可以通过目录,进入指定分区了
2 一个实验
dd命令:构建一个大文件
常见接口:
if=xxx 输入文件/设备(input file)
of=xxx 输出文件/设备(output file)
bs=xx 一次读写的块大小(block size)
count=xx 拷贝多少个块
cs
$ dd if=/dev/zero of=./disk.img bs=1M count=5 #制作⼀个⼤的磁盘块,就当做⼀个分
区
$ mkfs.ext4 disk.img # 格式化写⼊⽂件系统
$ mkdir /mnt/mydisk # 建⽴空⽬录
$ df -h # 查看可以使⽤的分区
Filesystem Size Used Avail Use% Mounted on
udev 956M 0 956M 0% /dev
tmpfs 198M 724K 197M 1% /run
/dev/vda1 50G 20G 28G 42% /
tmpfs 986M 0 986M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 986M 0 986M 0% /sys/fs/cgroup
tmpfs 198M 0 198M 0% /run/user/0
tmpfs 198M 0 198M 0% /run/user/1002
$ sudo mount -t ext4 ./disk.img /mnt/mydisk/ # 将分区挂载到指定的⽬录
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 956M 0 956M 0% /dev
tmpfs 198M 724K 197M 1% /run
/dev/vda1 50G 20G 28G 42% /
tmpfs 986M 0 986M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 986M 0 986M 0% /sys/fs/cgroup
tmpfs 198M 0 198M 0% /run/user/0
tmpfs 198M 0 198M 0% /run/user/1002
/dev/loop0 4.9M 24K 4.5M 1% /mnt/mydisk
$ sudo umount /mnt/mydisk # 卸载分区
whb@bite:/mnt$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 956M 0 956M 0% /dev
tmpfs 198M 724K 197M 1% /run
/dev/vda1 50G 20G 28G 42% /
tmpfs 986M 0 986M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 986M 0 986M 0% /sys/fs/cgroup
tmpfs 198M 0 198M 0% /run/user/0
tmpfs 198M 0 198M 0% /run/user/10023 一个结论
分区在写入文件系统后,并不能直接使用,必须与指定目录进行关联、完成挂载后才可正常使用。
因此,可以根据访问目标文件的路径前缀,准确判断该文件位于哪一个分区
六 软硬连接
1 硬链接
硬链接是 Linux 文件系统中直接指向同一个 inode 节点的文件别名,本质上是对同一个文件的多个 "入口",所以硬链接不是一个独立的文件
可以理解硬链接是一组新的文件名和目标文件inode的映射关系
同一个 inode,多个文件名:多个硬链接共享同一个 inode,它们在磁盘上是同一份数据,只是路径名不同。
inode 链接计数:创建硬链接时,目标文件的 i_nlink(链接数)会 +1;删除一个硬链接时,链接数 -1,只有当链接数降为 0 时,文件数据才会被真正释放。
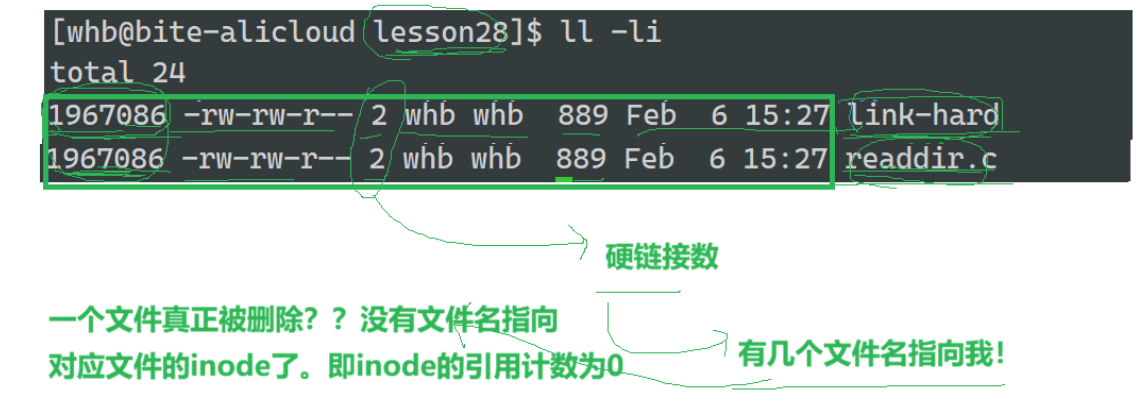
默认创建文件时,这个数字是1---->只有一个文件和我相关
不可跨分区:因为 inode 号是分区内唯一的,所以硬链接不能在不同分区之间创建
ln不带-s,默认建立硬链接
硬链接的作用:
1 安全备份
同一个文件多个名字,删了一个路径,文件还在。
适合重要配置、脚本,防止误删。
2 节省空间
不复制数据,只多一个目录项。
多个地方要用同一个大文件,用硬链接不占双倍空间。
3 保持文件稳定
只要还有一个硬链接存在,inode 和数据块就不会被释放。
适合日志、数据库这类不能随便消失的文件。
4 多路径访问同一个文件
比如同一个程序在 /bin 和 /usr/bin 都能调用,用硬链接实现。
Linux规定,不允许用户对目录建立硬链接 ,但是Linux自己制作文件系统结构时,自己有两个特殊的文件**.** 和**..** 这两个文件其实是对某一个目录进行的硬链接,所以Linux系统可以自己对目录建立硬链接
为什么?
因为不准用户给目录硬链接是因为系统分不清你是一个独立的目录,还是一个硬链接指向的目录,防止破坏文件遍历和一致性,防止目录树结构混乱和重复引用。而软连接有自己独立的inode,所以路径能分清
. :隐藏文件,是当前目录的硬链接 ,inode 号与当前目录完全一致。
.. :特殊命名文件,是父目录的硬链接,inode 号与父目录完全一致。
一个约定 :在进行路径遍历操作的时候,因为知道**.** 表示当前路径,**..**表示上级路径,所以就会自动判断而跳过
2 软连接
软链接(符号链接、symlink),可以理解成指向另一个文件的 "快捷方式"。
软连接是一个独立的文件,有自己独立的inode号,可以利用软连接快速找到目标文件
核心特点:
有自己独立的 inode
里面只存目标文件的路径字符串
不指向原文件数据,只指向路径
原文件删了,软链接就变成失效链接(断链)
可以跨分区、跨设备
可以链接目录
为什么要有软连接?潜台词是为什么要有快捷方式?
加速查找
cs
ln -s 原文件 软链接名可以利用rm或unlink删除软连接
软链接 = 文件系统里的快捷方式,只记路径,不共享 inode,可以跨分区。
| 特性 | 硬链接 | 软链接(符号链接) |
|---|---|---|
| 本质 | 指向同一个 inode | 指向另一个文件的路径字符串 |
| 跨分区 | ❌ 不可跨分区 | ✅ 可跨分区 / 跨设备 |
| 链接目录 | ❌ 禁止 | ✅ 允许 |
| 原文件删除后 | ✅ 其他链接仍可访问 | ❌ 变成 "死链接" 无法访问 |
| 占用空间 | 仅目录项,几乎无空间 | 存储路径字符串,占少量空间 |