SGLang vs vLLM
vLLM 的高并发原理:
PagedAttention(解决 KV Cache 碎片)
Continuous Batching(解决 GPU 空闲)
推测解码(加速 Decode 阶段)
=> vLLM 解决的是 如何让模型跑得快 的问题。
Thinking:SGLang的作用是什么?
如何让业务逻辑跑得快
SGLang 深度优化:Radix 缓存与复杂任务的极致吞吐
SGLang vs vLLM
vLLM 的高并发原理:
PagedAttention(解决 KV Cache 碎片)
Continuous Batching(解决 GPU 空闲)
推测解码(加速 Decode 阶段)
=> vLLM 解决的是 如何让模型跑得快 的问题。
Thinking:SGLang的作用是什么?
如何让业务逻辑跑得快
PD 分离架构 -- Prefill/Decode 解耦
PD 分离(Prefill/Decode 解耦) 是当前大语言模型(LLM)推理服务的主流高性能架构,核心是将推理中两个计算特性完全不同的阶段拆分到独立的硬件 / 进程中执行,解决资源错配、相互干扰、延迟抖动等问题。
为什么需要 PD 分离?
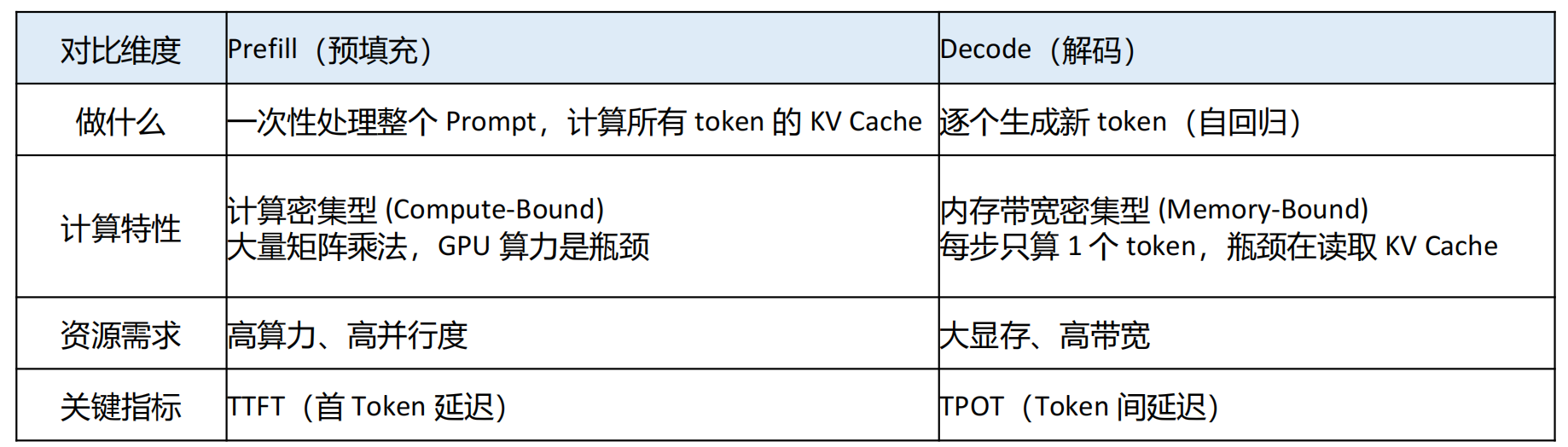
Continuous Batching 将 Prefill(预填充)和 Decode(解码)混合在同一个 GPU 上执行。
虽然提升了吞吐,但两个阶段的计算特性完全不同,混在一起会产生严重的资源争抢。
PD 分离架构:核心设计
1. 三层标准架构
-
Router / 调度层:请求路由、负载均衡、SLO 保障、P/D 节点状态管理。
-
Prefill 集群:高算力 GPU,批量处理 Prompt、生成 KV Cache。
-
Decode 集群:高带宽 GPU,消费 KV Cache、流式生成 Token。
适用场景
-
长上下文服务(>4k Token,如 Kimi/DeepSeek)
-
高并发实时对话(客服、助手、直播)
-
流式生成(Copilot、代码补全、写作)
-
超长文本生成(报告、小说、多轮对话)
Thinking:混合执行的问题是什么?
当 Prefill 和 Decode 在同一个 GPU 上交替执行时:
• 执行计算密集的 Prefill 时,会阻塞延迟敏感的 Decode → TPOT 飙升(用户感觉卡顿)
• 执行访存密集的 Decode 时,GPU 计算单元大量空闲 → 浪费了 Prefill 需要的算力
=> 让短跑运动员和马拉松运动员在同一条跑道上交替训练,谁都练不好。
sumarry
除了 vLLM,业界还有其他 PD 分离实现:
• Mooncake(Kimi 的推理架构):以 KV Cache 为中心的分离式架构
• NVIDIA Dynamo:提供声明式的 PD 分离部署(VllmPrefillWorker + VllmDecodeWorker)
• SGLang、llm-d(Kubernetes 原生推理栈)
PD 分离 = 计算与访存异构解耦 + 硬件专业化 + 流水线并行,
是当前 LLM 服务高吞吐、低延迟、高性价比的必选架构。
Thinking:为什么 Prefill 适合小 Batch,Decode 适合大 Batch?
• Prefill 本身就是计算密集型(处理整个 Prompt 的矩阵乘法),GPU 算力已经打满了。增大 Batch 只会增
加排队延迟,不提升吞吐。
• Decode 本身是内存带宽密集型(每步只算 1 个 token),GPU 算力大量空闲。增大 Batch 让 GPU 同时处
理更多请求,空闲的算力被利用起来,从 Memory-Bound 转向 Compute-Bound,吞吐大幅提升。
Thinking:PagedAttention, Continuous Batching,推测解码,PD分离分别解决什么问题?
• PagedAttention 解决显存浪费
• Continuous Batching 解决 GPU 空闲
• 推测解码:解决生成太慢
• PD 分离 解决资源争抢。
• PagedAttention
优化层面:内存层
解决的问题:KV Cache 碎片和浪费
=> 把 KV Cache 切成小块,按需分配,像虚拟内存一样管理
• Continuous Batching
优化层面:调度层
解决的问题:GPU 空闲等待(短请求完成后干等长请求)
=> 每生成一个 token 就调度一次,完成即腾位,新请求立即填入
• 推测解码 (EAGLE/MEDUSA)
优化层面:算法层
解决的问题:Decode 阶段 GPU 算力空闲(Memory-Bound)
=> 小模型猜多个 token,大模型一次并行验证,减少生成步数
• PD 分离
优化层面:架构层
解决的问题:Prefill 和 Decode 互相干扰
=> 两阶段物理隔离到不同 GPU,各自用最适合的硬件和 Batch 策略
Thinking:PagedAttention, Continuous Batching,推测解码,PD分离 如何叠加使用?

使用逻辑:
• PagedAttention 是基础设施,贯穿 Prefill 和 Decode 两端,所有场景都需要
• Continuous Batching 在 Prefill 和 Decode 集群内部各自运行,提升各自的 GPU 利用率
• 推测解码 只在 Decode 集群中使用(Decode 阶段是 Memory-Bound,最需要加速)
• PD 分离 是最外层的部署策略,决定了上面三者在哪里运行

SGLang深度优化
SGLang 通过 fork/join/select/gen 等原语,将分支 - 求解 - 合并的提示模式高效落地,既简化了多任务并行生成的代码,又通过 runtime 优化(KV 复用、约束解码等)大幅提升了 LLM 推理的效率与稳定性。

LangChain VS SGLang
LangChain 是应用层工作流编排框架,SGLang 是推理层 runtime 与编程抽象 ,两者是互补而非替代的关系。
| 维度 | LangChain | SGLang |
|---|---|---|
| 核心定位 | 应用层工作流编排(Agent、RAG、多步骤任务) | 推理层 runtime + 轻量级编程抽象 |
| 解决问题 | 如何把 LLM 与工具 / 知识库 / 多模态组件串联成复杂业务流程 | 如何让 LLM 推理更快、更省资源、更可控 |
| 抽象层级 | 高抽象:面向开发者业务逻辑(如 RetrievalQA、AgentExecutor) |
低抽象:面向生成原语与调度(如 fork/gen/select) |
| 典型场景 | 客服机器人、知识库问答、代码助手、多轮对话 Agent | 高并发推理、批量生成、结构化输出、多维度评估 |
SGLang系统中的RadixAttention技术


Summary(RadixAttention技术)

CASE:JSON约束输出

CASE:流式输出

CASE:性能测试

CASE:vLLM 与 SGLang 性能对比 - 相同任务下的性能差异


Q&A
Q:PagedAttention和RadixAttention都是解决KV Cache问题的,前者按需分配,后者重复使用?
PagedAttention:核心是分页式显存管理,解决 KV Cache 内存碎片化、按需分配的问题 RadixAttention:核心是前缀 KV Cache 共享复用,解决重复计算、冗余存储的问题两者都是为了优化 LLM 推理中 KV Cache 的内存效率与推理性能,但侧重点完全不同。
| 特性 | PagedAttention (vLLM) | RadixAttention (SGLang) |
|---|---|---|
| 核心目标 | 解决 KV Cache 内存碎片化,提升显存利用率 | 解决重复前缀的 KV Cache 冗余,提升吞吐与延迟 |
| 实现方式 | 将 KV Cache 划分为固定大小的 "页",按需分配 / 释放,类似虚拟内存 | 用基数树(Radix Tree)组织 KV Cache,共享相同前缀的 KV 数据 |
| 典型场景 | 多并发、变长序列场景(如聊天、流式生成) | 多轮对话、多分支生成、并行评估(如 SGLang 的 fork 原语) |
| 优化点 | 内存利用率↑(避免碎片),支持更大并发 | 计算量↓(共享前缀无需重算),显存占用↓(去重存储) |
| 代表框架 | vLLM | SGLang |
Q:用SGLang加载运行模型后 再给一个SGLang 按照加载的不同大模型注入各种不同的SGLang程序吗?
SGLang = 模型运行时(Runtime) + 可编程执行引擎
1.先用 SGLang 加载一个大模型(LLaMA、Qwen、GLM 等)
2.再向这个已经加载好模型的 SGLang 实例 ,动态注入、运行各种 SGLang 程序
3.不同模型 → 不同 SGLang 实例 → 各自跑不同的 SGLang 程序完全互不干扰
Q:RadixAttention 和 PagedAttention是可以同时启用的吗 或者是冲突的吗?
PagedAttention :底层显存管理器(分页、防碎片、按需分配物理块)
RadixAttention :上层缓存复用器(前缀共享、去重、减少重复计算)
用户请求 → RadixAttention(查前缀树 → 拿到复用的 Block IDs)→BlockTable(填复用块 + 分配新块)→PagedAttention(物理显存块、计算 Attention)
两者是 LLM 推理中 KV Cache 优化的黄金组合:前者提供高效、无碎片的物理显存分页管理,后者实现跨请求前缀的逻辑缓存共享复用,二者分层协同、默认同启,可同时最大化显存利用率与推理吞吐量。
Q:autodl上一个4090的机器 开一个 SGLang就把显存快占满了 怎么同时开SGLang和vLLM ?
用 4-bit 量化模型 + 各自限制 40% 显存 + 短上下文,就能让 SGLang 和 vLLM 同时跑起来,只是要牺牲一点性能和上下文长度。
Q:PD分离 P和D一定要跑同一个模型吗
模型不一样,KV Cache对不上。PD分离 = 同一个模型的推理过程拆成PD两个阶段,分到不同机器 / 卡上跑。
Q:vLLM 能通过调优达到 SGLang 的性能吗?
-
可以无限接近:通过上面提到的内存、批处理、量化等参数调优,vLLM 的性能可以得到巨大提升,在简单的、单轮的、不需要复杂结构化输出的文本生成任务中,其表现会非常接近 SGLang。
-
很难完全持平 :在高并发、多轮对话、RAG、强依赖结构化输出等复杂场景下,SGLang 凭借其
RadixAttention等架构优势,性能上限更高,vLLM 难以仅靠调参来抹平这种"结构性"差距。
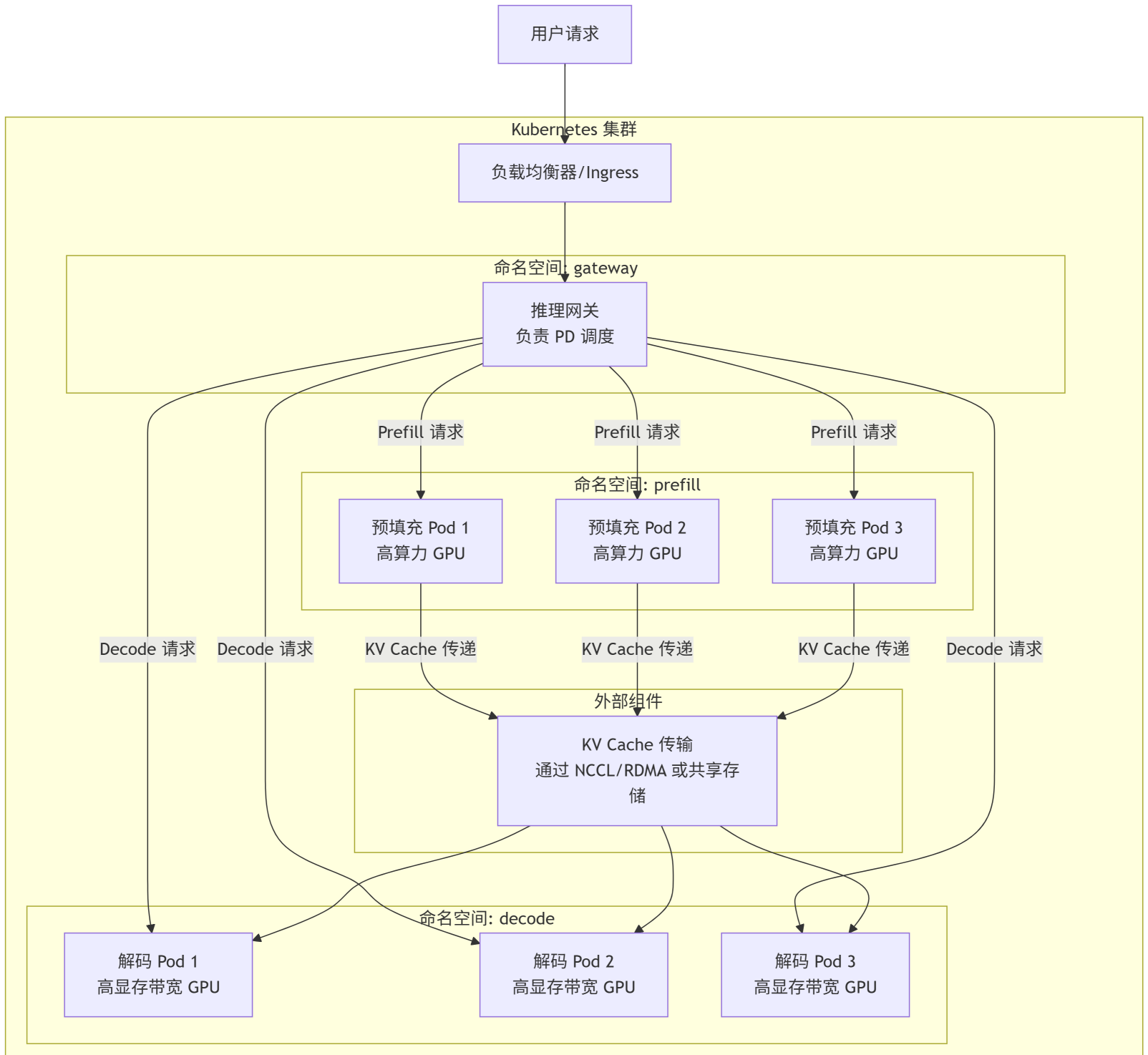
Q:如果生产产线本地部署,PD分离需要配合K8S做部署吗?
对于生产环境的本地部署,尤其是追求极致性能和稳定性的场景,将 PD 分离与 Kubernetes (K8s) 结合是最佳实践。
K8s 作用
隔离与异构管理 、独立弹性伸缩 (Auto-scaling) 、服务发现与负载均衡 、声明式运维与故障自愈
-
KV Cache 传输:这是 PD 分离的难点。你需要一个高性能的机制来将预填充阶段产出的巨大 KV Cache 数据传递给解码节点。常见方案:
-
RDMA (Remote Direct Memory Access):最高效,直接 GPU 间通信,需要 InfiniBand 或 RoCE 网络。
-
NCCL (NVIDIA Collective Communications Library):NVIDIA 的集合通信库,也支持多机传输。
-
共享内存/存储 (Redis/内存盘):相对慢一些,但实现简单,适合小规模。
-
-
K8s 配置要点:
-
使用
PodDisruptionBudget防止自愿中断(如节点升级)时同时杀死太多 Pod。 -
为每个 Pod 配置
requests和limits,尤其是nvidia.com/gpu资源。 -
使用
readinessProbe和livenessProbe确保只有真正就绪的 Pod 才接收流量。
-