文章目录
- 一、消息中间件(MQ)介绍
-
- [1.1 什么是消息中间件](#1.1 什么是消息中间件)
- [1.2 为什么需要消息队列](#1.2 为什么需要消息队列)
- [1.3 主流产品对比](#1.3 主流产品对比)
- [二、RabbitMQ 快速上手](#二、RabbitMQ 快速上手)
-
- [2.1 RabbitMQ 产品介绍](#2.1 RabbitMQ 产品介绍)
- [2.2 RabbitMq安装](#2.2 RabbitMq安装)
- [2.3 RabbitMq基础使用](#2.3 RabbitMq基础使用)
- [2.4 队列模式](#2.4 队列模式)
- [2.5 RabbitMq核心概念总结](#2.5 RabbitMq核心概念总结)
- [三、Kafka 快速上手](#三、Kafka 快速上手)
-
- [3.1 Kafka产品介绍](#3.1 Kafka产品介绍)
- [3.2 kafka 单机搭建](#3.2 kafka 单机搭建)
- [3.3 Kafaka基础功能测试](#3.3 Kafaka基础功能测试)
- [3.4 Kafka 智能监控与管理平台](#3.4 Kafka 智能监控与管理平台)
- [四、RocketMQ 快速上手](#四、RocketMQ 快速上手)
-
- [4.1 产品介绍](#4.1 产品介绍)
- [4.2 rocket 安装](#4.2 rocket 安装)
- [4.3 RocketMQ的基础使用](#4.3 RocketMQ的基础使用)
一、消息中间件(MQ)介绍
1.1 什么是消息中间件
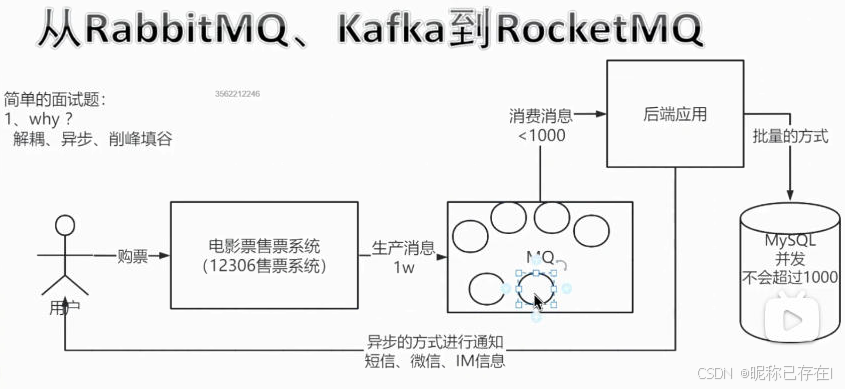
你是一家餐厅的老板。过去,点菜员(生产者)每接到一个订单,就要亲自冲到后厨,等着厨师(消费者)做完菜,然后才能去接待下一桌客人。如果客人很多,点菜员就会堵在后厨,新来的客人没人招呼,整个餐厅乱成一锅粥。
现在,你引入了一个新角色:传菜员(消息队列)。点菜员只需把订单写在传菜单上,放到传菜口的篮子里(队列),就可以立刻去接待下一桌客人。厨师按照自己的节奏从篮子里取单做菜。点菜员和厨师不再直接耦合,餐厅效率瞬间提升
在这个场景里,那个放传菜单的篮子,就是消息队列。它解决了直接沟通导致的堵塞和效率低下问题。
-
Message(消息): 指的是在应用程序之间传递的数据。它可以是一个简单的字符串,也可以是一个复杂的业务对象。
-
Queue(队列): 一种具有先进先出(FIFO)特性的数据结构。它保证了数据的顺序性
以队列的形式存储消息,并在不同的应用程序之间传递,这就形成了消息队列(Message Queue,简称MQ)。核心思想:从同步到异步
1.2 为什么需要消息队列
【图1:无MQ的同步调用架构】
+---------+ 同步调用 +---------+
| | -----------> | 系统B |
| 系统A | -----------> +---------+
| (发起方)| 同步调用 | 系统C |
| | -----------> +---------+
+---------+ 同步调用 | 系统D |
+---------+
问题:系统C宕机 → 整个调用失败
响应时间 = B + C + D 的总和在没有MQ的同步调用架构中,系统A直接调用系统B、C、D,
会面临三个问题:
响应慢: 系统A必须等所有系统处理完才能返回结果。
耦合高: 只要加一个新系统E,系统A就得改代码。
易崩溃: 如果系统C宕机,系统A就直接调用失败
【图2:引入MQ的异步解耦架构】
+---------+ 发送消息 +---------+
| 系统A | -----------> | MQ |
| (生产者)| | (消息队列)|
+---------+ +---------+
|
+-------------+-------------+
| | |
↓ ↓ ↓
+-------+ +-------+ +-------+
| 系统B | | 系统C | | 系统D | + 新增系统E
+-------+ +-------+ +-------+
优势:系统A无需等待
新增系统E无需修改A
系统C临时宕机不影响整体引入MQ后,完美解决:
异步处理 ------ 提升系统响应速度
应用解耦 ------ 降低系统间依赖性,生产者和消费者间的解耦
流量削峰 ------ 保护核心系统不被冲垮
1.3 主流产品对比
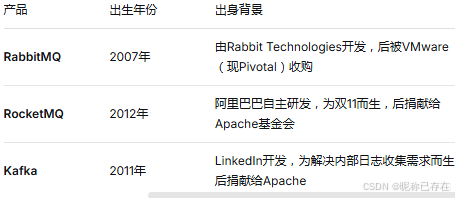
RabbitMQ 是"信使"-精通各种通信协议,路由灵活,但体力有限
RocketMQ是"特种兵"-功能全面,能打硬仗,尤其擅长金融交易类场景
Kafka 是"搬运工"-体力惊人,擅长处理海量数据流,但功能相对单


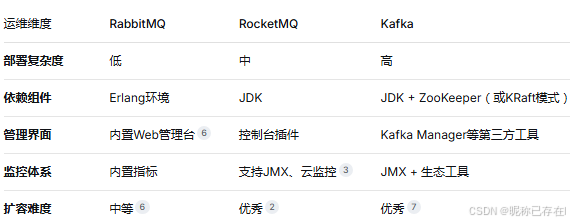
RabbitMQ 的运维最为友好:
Kafka 的运维复杂度最高
RocketMQ 介于两者之间,5.0版本通过Proxy组件实现了更好的云原生适配
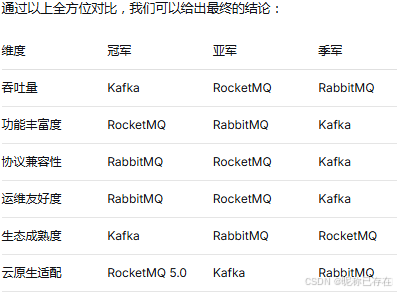
RabbitMQ 是"瑞士军刀"------功能全面、使用简单,适合大多数通用场景。
RocketMQ 是"手术刀"------在金融交易、电商订单等需要强一致性的场景中无可替代。
Kafka 是"屠龙刀"------专为海量数据而生,在大数据领域独孤求败

二、RabbitMQ 快速上手
2.1 RabbitMQ 产品介绍
RabbitMQ的名字有个有趣的含义------兔子跑得快,繁殖能力强,象征着消息中间件需要具备高并发、易扩展的特性。
RabbitMQ是一个开源的消息中间件,它基于Erlang语言开发,实现了AMQP(高级消息队列协议)标准。它的核心作用是:接收生产者发送的消息,按照规则路由到对应的队列,再交给消费者处理。
官网地址:https://www.rabbitmq.com/
2.2 RabbitMq安装
使用CentOs手动进行安装。这样更能接触产品的细节。后面可以docker安装。因装的还是centos 7,特找之前的版本。Erlang版本 21.x ~ 24.x。RabbitMQ版本 3.8.x ~ 3.10.x
Erlang语言包的安装
https://github.com/rabbitmq/erlang-rpm/releases
RabbitMq安装
https://github.com/rabbitmq/rabbitmq-server/releases
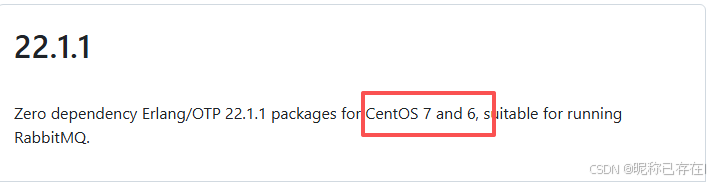
且需兼容 尝试了下,选择了都是el7的
erlang-23.3.4.11-1.el7.x86_64.rpm
rabbitmq-server-3.8.25-1.el7.noarc
附:centos 其它版本安装下载
包含ISO文件(如CentOS-8.x-x86_64-dvd1.iso)
阿里云开源镜像站:https://mirrors.aliyun.com/centos/
官网:https://www.centos.org/download/
清华大学镜像站:https://mirrors.tuna.tsinghua.edu.cn/
CentOS 8历史版本
由于CentOS 8已归档,需通过vault目录下载旧版本:
阿里云开源镜像站:https://mirrors.aliyun.com/centos-vault/8.5.2111/
https://vault.centos.org/centos/8-stream/isos/x86_64/
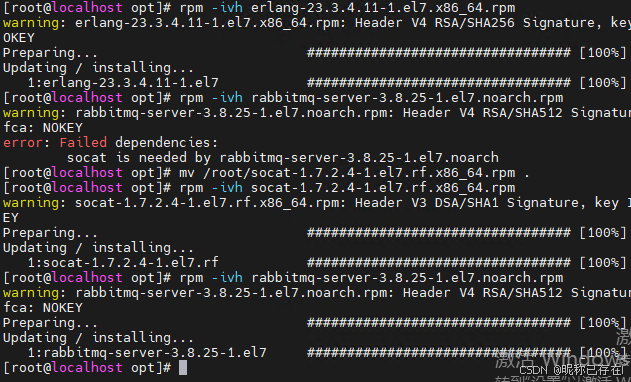
https://rpmfind.net/ 根据error 下载补丁
启动
python
service rabbitmq-server start
service rabbitmq-server status
systemctl stop firewalled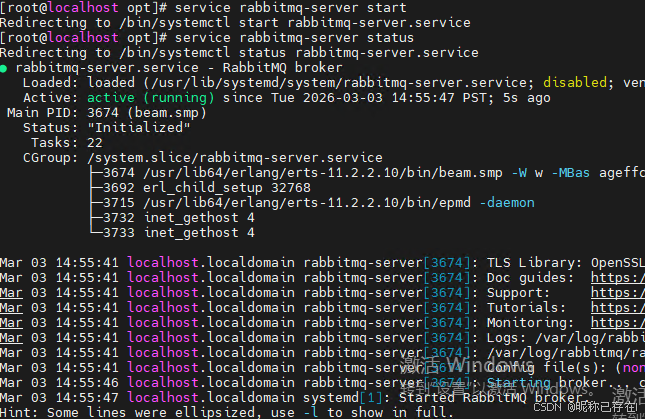
python
# 插件清单
rabbitmq-plugins list
# 启动管理界面 其它命令可在控制台处理了 默认密码guest/guest
rabbitmq-plugins enable rabbitmq_management
#创建用户:
sudo rabbitmqctl add_user admin 你的密码
#赋予管理员权限: 用户有资格访问Web管理界面
sudo rabbitmqctl set_user_tags admin administrator
#设置基础权限:用户对默认的虚拟主机拥有完整的配置、写入和读取权限
sudo rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"http:// *:15672

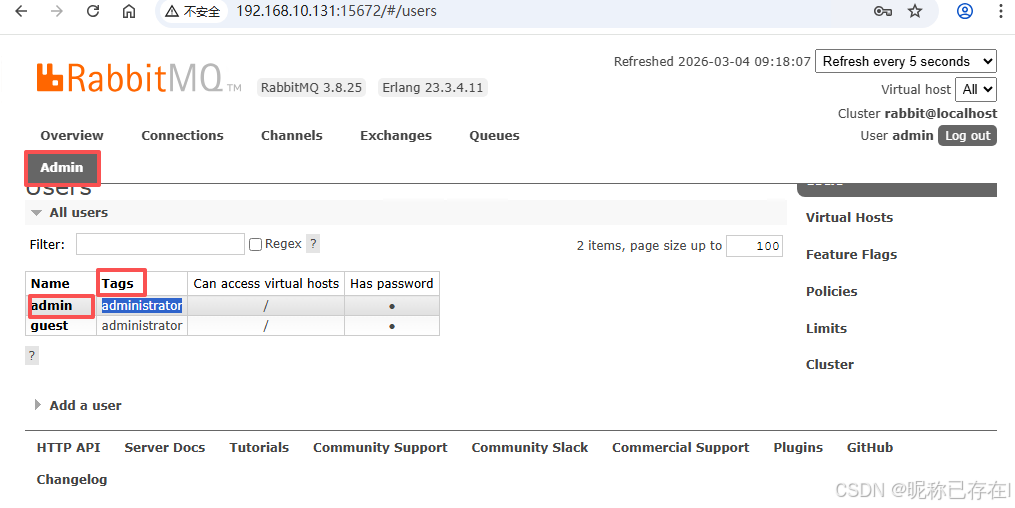
2.3 RabbitMq基础使用

生产者(寄件人)
↓ 写下地址标签(Routing Key = "order.create")
↓ 把包裹交给
Exchange(收发室) ← 你问的位置就在这里!
↓ 查看分拣规则表(Binding)
↓ 根据规则决定
Queue A(财务室101) Queue B(技术部202) Queue C(会议室)
↓ ↓ 消费者(财务人员取走) 消费者(程序员取走)
┌─────────────────────────────────────┐
│ Vhost:开发环境办公楼 │
│ (与其他办公楼完全隔离,互不相通) │
│ │
│ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │Queue │ │Queue │ │Queue │ │ ← 第二层:Queue(房间)
│ │ A │ │ B │ │ C │ │
│ └──┬───┘ └──┬───┘ └──┬───┘ │
│ │ │ │ │
│ ┌──▼───────────────────────┐ │
│ │ Exchange(收发室) │ │ ← 第三层:Exchange(分拣中心)
│ └──┬───────────────────────┘ │
│ │ │
│ ┌──▼───────────────────────┐ │
│ │ Channel 1(传送带1) │ │
│ │ Channel 2(传送带2) │ │ ← 第四层:Channel(虚拟通道)
│ │ Channel 3(传送带3) │ │
│ └──┬───────────────────────┘ │
│ │ │
│ ┌──▼───────────────────────┐ │
│ │ Connection(主干道) │ │ ← 第五层:Connection(物理连接)
│ │ (TCP连接) │ │
│ └──────────────────────────┘ │
│ │
└──────────────────────────────────────┘
Vhost(隔离环境)
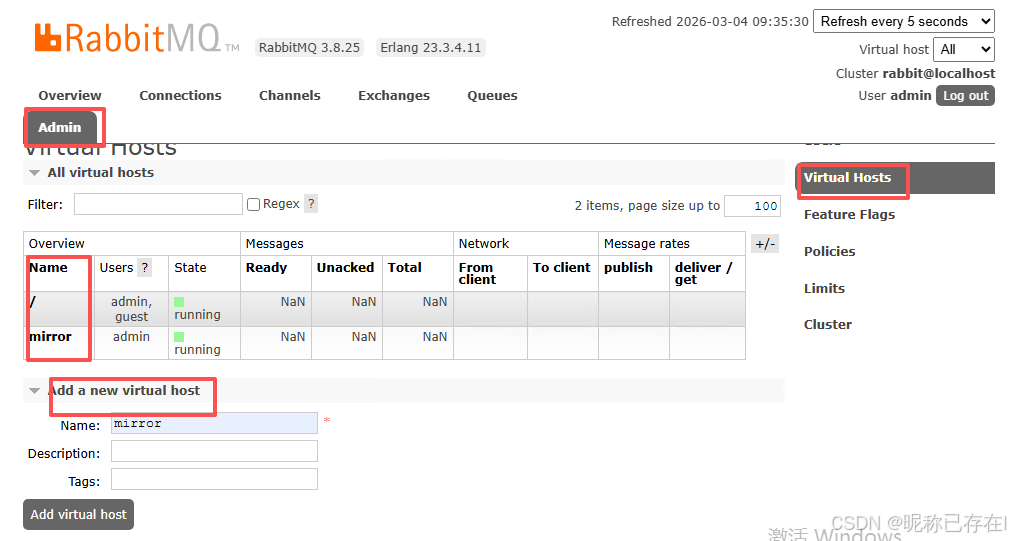
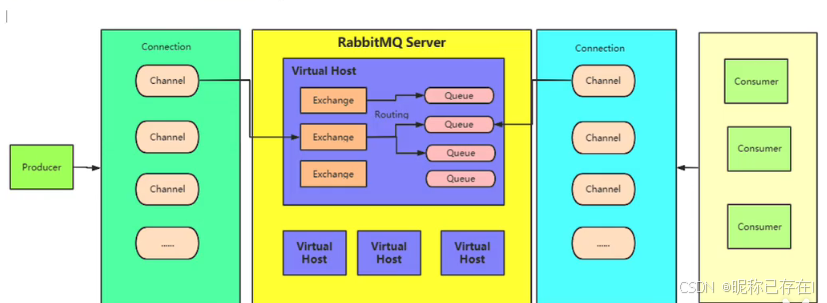
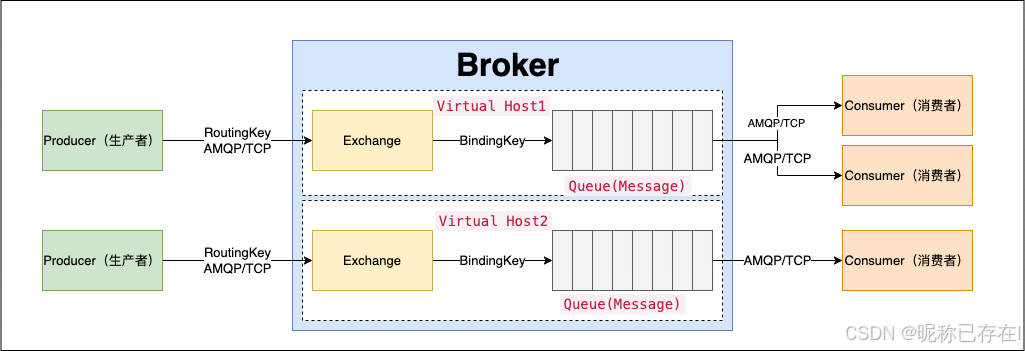
可以把 Vhost(虚拟主机) 理解成 RabbitMQ 服务器内部的一个独立的小型服务器,或者是一个完全隔离的运行环境
逻辑隔离 :
每个 Vhost 都有自己的队列(Queue)、交换机(Exchange)和绑定(Binding),彼此之间互不干扰。就像一台物理服务器上通过虚拟机技术跑着多个独立的系统一样。
默认 Vhost :RabbitMQ 安装后,会自动创建一个默认的 Vhost,名字就叫 /(斜杠)。我们之前所有的操作,比如给 admin用户授权,都是在这个默认的 / 上进行的。
权限边界 :
用户必须被授予访问某个特定 Vhost 的权限,才能对其进行操作。这正是我们之前通过 set_permissions命令所做的事情
Queues (队列)
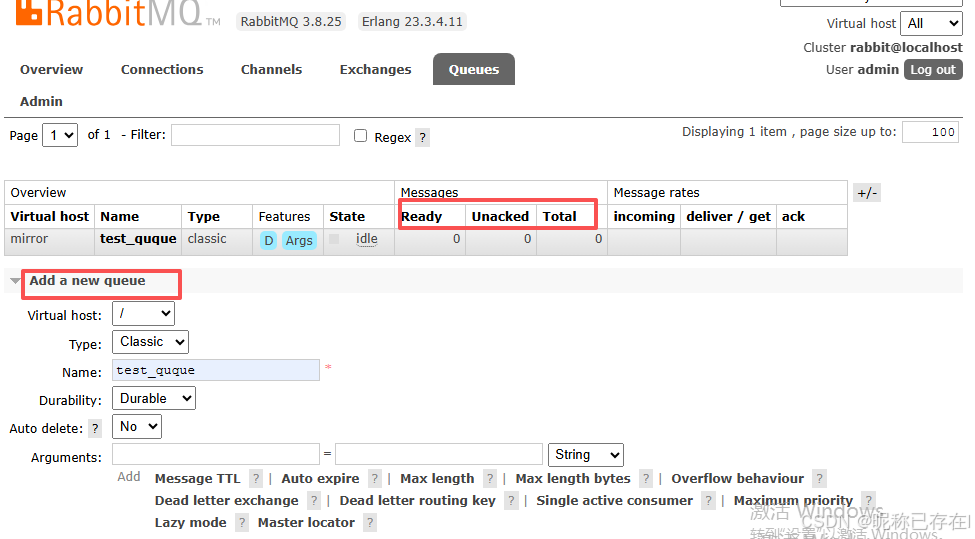
可以查看每个队列的消息数量(Ready:待消费;Unacked:已发送但未确认;Total:总数)
可以在点击新增的test_quque中
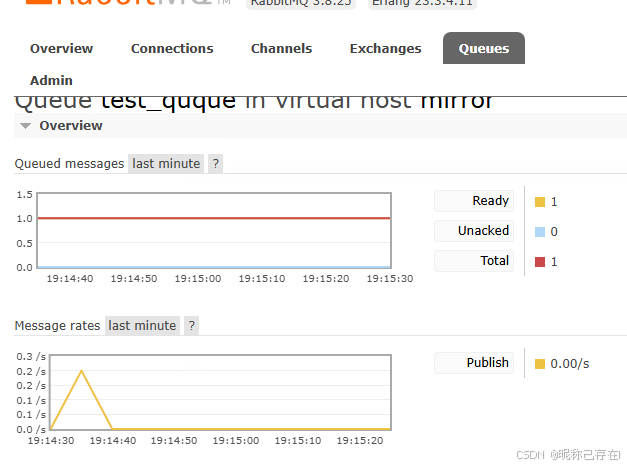
Publish message发送信息, Overview中查看
Exchange(交换机)
🚦 核心角色:解耦生产者与队列
当你登录 RabbitMQ 管理界面时,会看到一个名为 (AMQP default) 的特殊交换机
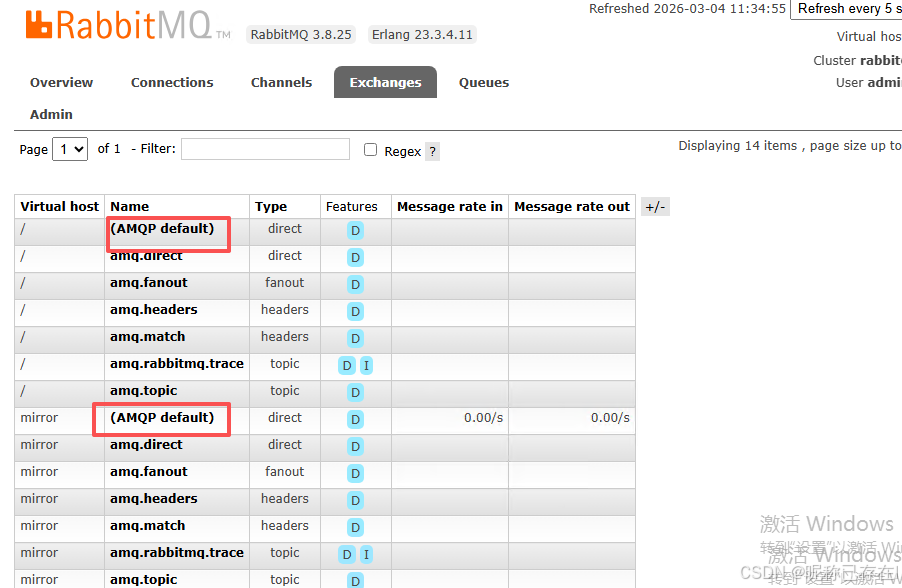

🔗 关键关系:Bindings(绑定)
特殊之处:每一个新建的队列,都会自动用"队列名"作为 Binding Key 绑定到这个默认交换机上。
amq.direct bind 新增的quque,可以通过交换机发送消息
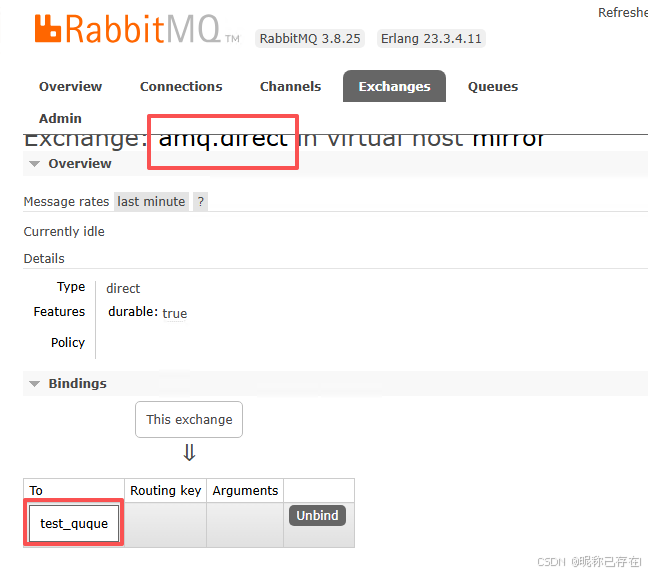
通过exchange发送消息 在quque中查看
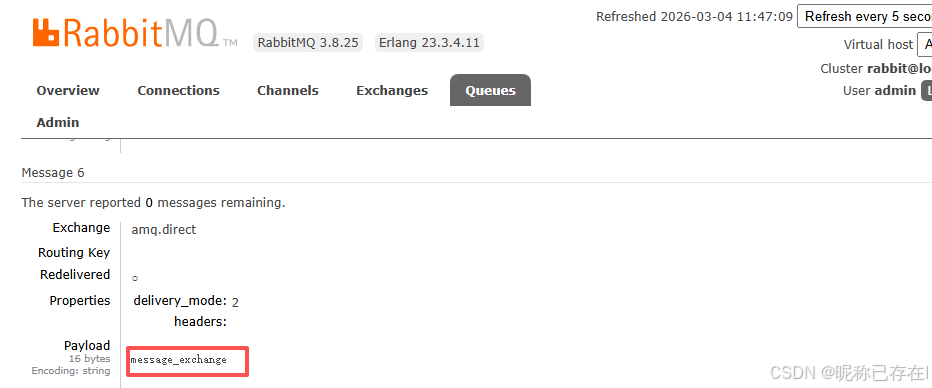
Connection 和 Channel
在 RabbitMQ 的管理界面中,Connections 标签页主要用于监控和管理客户端连接,你无法在这里"创建"一个连接(连接是由客户端代码发起的),但可以查看所有活跃连接的实时状态并进行干预。
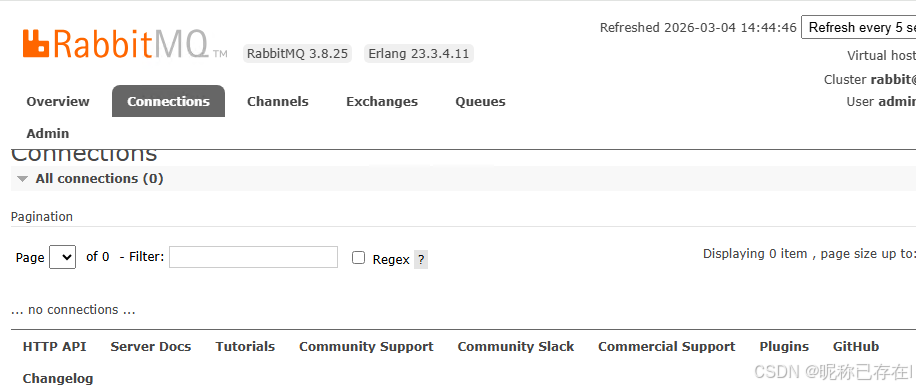
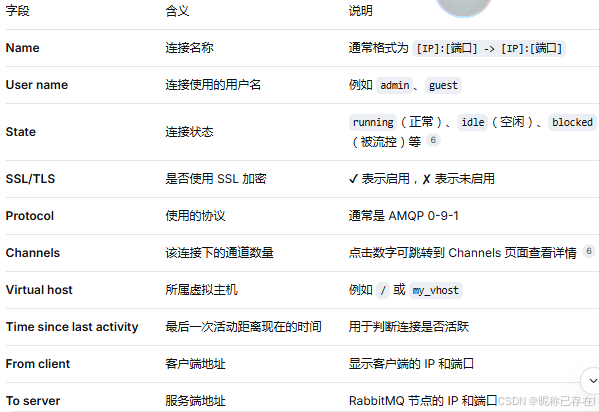
同一个客户端的生产者和消费者,在 Connections 列表中显示的 IP 地址是相同的,无法直接区分 。
解决方案:在客户端代码中设置 connection_name 参数,给连接起一个有意义的名字。
Python 示例(使用 pika)
python
import pika
import time
def rabbitmq_test():
print("=" * 50)
print("RabbitMQ 连接测试")
print("=" * 50)
try:
# 1. 连接
print("\n[1/5] 连接 RabbitMQ...")
credentials = pika.PlainCredentials('admin', 'admin')
parameters = pika.ConnectionParameters(
host='192.168.10.131',
port=5672,
virtual_host='mirror',
credentials=credentials,
heartbeat=60,
client_properties = {
'connection_name': 'my_producer_connection' # 👈 自定义连接名称
}
)
connection = pika.BlockingConnection(parameters)
print("✅ 连接成功")
# 2. 创建通道
print("\n[2/5] 创建通道...")
channel = connection.channel()
print("✅ 通道创建成功")
# 3. 声明队列
print("\n[3/5] 声明队列 'test_queue'...")
channel.queue_declare(queue='test_queue', durable=True)
print("✅ 队列声明成功")
# 4. 发送消息
print("\n[4/5] 发送消息...")
message = f"测试消息 - {time.strftime('%Y-%m-%d %H:%M:%S')}"
channel.basic_publish(
exchange='',
routing_key='test_queue',
body=message,
properties=pika.BasicProperties(delivery_mode=2) # 持久化消息
)
print(f"✅ 消息发送成功: {message}")
# 5. 查看队列状态
print("\n[5/5] 查看队列状态...")
queue_info = channel.queue_declare(queue='test_queue', durable=True, passive=True)
print(f"✅ 队列 '{queue_info.method.queue}' 中有 {queue_info.method.message_count} 条消息")
# 保持连接一会儿,方便在管理界面查看
print("\n⏳ 连接保持30秒,你可以去管理界面查看...")
print(" -> 查看 Queues 标签页")
time.sleep(30)
except Exception as e:
print(f"❌ 错误: {e}")
finally:
# 关闭连接
if 'connection' in locals() and connection.is_open:
connection.close()
print("\n✅ 连接已关闭")
print("\n" + "=" * 50)
print("测试完成")
print("=" * 50)
if __name__ == "__main__":
rabbitmq_test()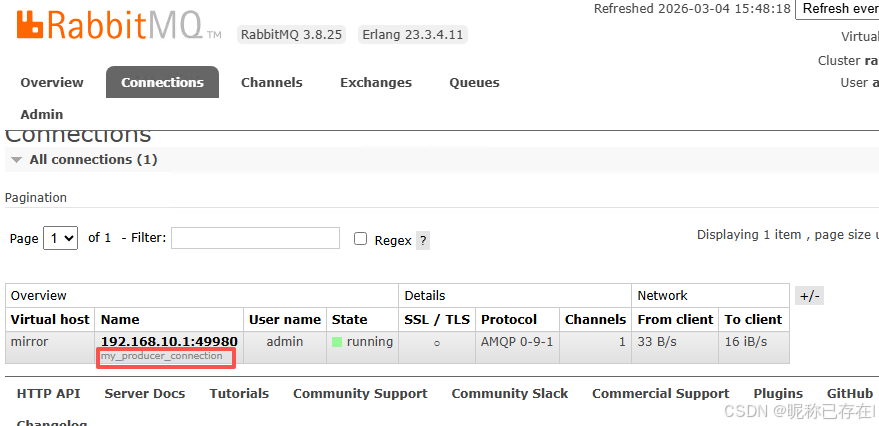
Java客户端连接
python
# 首先在项目中添加RabbitMQ Java客户端依赖
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.17.1</version>
</dependency>
# 其它生产者 消费者代码可自行搜索生成2.4 队列模式
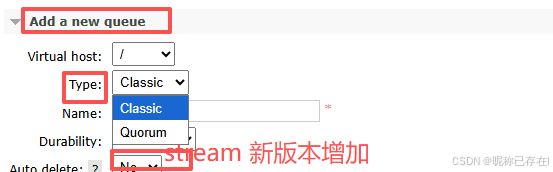

Classic Queue(经典队列)
存储机制:从 RabbitMQ 3.12 开始,默认行为类似于过去的"懒队列",即尽可能将消息写入磁盘,只在内存中保留少量消息用于快速投递给消费者
适用性:适用于开发环境,或对数据安全性要求不高、允许短暂中断的业务。
Quorum Queue(仲裁队列)
核心机制:基于 Raft 共识算法实现数据复制。消息必须写入到集群中多数节点(Quorum)后,才会向生产者确认成功 。这彻底避免了脑裂问题,保证了数据的强一致性
Stream(流)
Stream 是 RabbitMQ 中一种全新的、基于日志的持久化数据结构
颠覆性消费模式 :Stream 最大的特点是非破坏性消费。消息被追加到日志末尾后,不会因为被消费而删除。消费者可以从日志中的任意位置(如从开头、从某个时间点、从特定偏移量)开始读取,并且可以多次读取同一条消息.
适用场景:非常适合日志聚合、事件溯源、指标监控、需要"重放"数据或给多个独立消费者共享同一份数据副本的场景
2.5 RabbitMq核心概念总结
核心操作步骤
1 创建虚拟主机(Virtual Host)
虚拟主机类似于数据库中的"database",用于隔离不同业务的数据。
点击顶部 Admin 标签
在右侧点击 Virtual Hosts 选项卡
在 "Add a new virtual host" 中输入名称,例如 my_vhost
点击 Add virtual host
2 创建队列(Queue)
点击顶部 Queues 标签
在底部 "Add a new queue" 区域:
Virtual host:选择刚才创建的 my_vhost(或默认的 /)
Name:输入队列名称,例如 test_queue
Durable:是否持久化(如果选是,重启后队列依然存在)
Auto delete:是否自动删除(最后一个消费者断开后删除)
Arguments:可选参数(如队列长度限制、TTL等)
点击 Add queue
创建成功后,您会在队列列表中看到它。
3 创建交换机(Exchange)
点击顶部 Exchanges 标签
在底部 "Add a new exchange" 区域:
Virtual host:选择 my_vhost
Name:输入交换机名称,例如 test_exchange
Type:选择交换机类型
direct:精确匹配路由键
fanout:广播给所有绑定的队列
topic:通配符匹配(如 order.*)
headers:根据消息头匹配(较少用)
Durability:是否持久化
Auto delete:是否自动删除
点击 Add exchange
4 绑定队列到交换机
将队列和交换机关联起来,消息才能从交换机路由到队列。
在 Queues 标签页,点击您刚刚创建的队列名(例如 test_queue)
向下滚动到 Bindings 区域
在 "Add binding to this queue" 中:
From exchange:选择 test_exchange(默认是 (Default exchange),表示使用默认交换机)
Routing key:输入路由键,例如 test.key
点击 Bind
5 发送消息(测试用)
在 Queues 标签页,点击队列名进入详情
向下滚动到 Publish message 区域
填写:
Routing key:如果绑定到了交换机,输入对应的路由键(如 test.key);如果使用默认交换机,留空或填队列名
Headers:可选
Payload:消息内容,例如 Hello from management UI!
Properties:可以设置消息属性(如持久化、过期时间等)
点击 Publish message
消息发送成功后,您会在队列详情页的 Message rates 区域看到统计变化。
6 查看/消费消息
在队列详情页,向下滚动到 Get messages 区域
设置:
Ack mode:
Ack automatically:自动确认(消息取出即删除)
Ack manually:手动确认(可重新入队)
Messages:要获取的消息数量
Encoding:编码(通常选 text/plain)
点击 Get message(s)
界面下方会显示消息内容,您可以选择确认(Ack)或拒绝(Reject )
三、Kafka 快速上手
3.1 Kafka产品介绍
Kafka最初由LinkedIn开发,于2011年开源,后成为Apache顶级项目。它的诞生源于一个非常具体的需求:处理公司内部海量的日志和活动流数据.
Kafka是一个分布式事件流平台(Event Streaming Platform),专为高吞吐、持久化、可水平扩展的实时数据场景而生
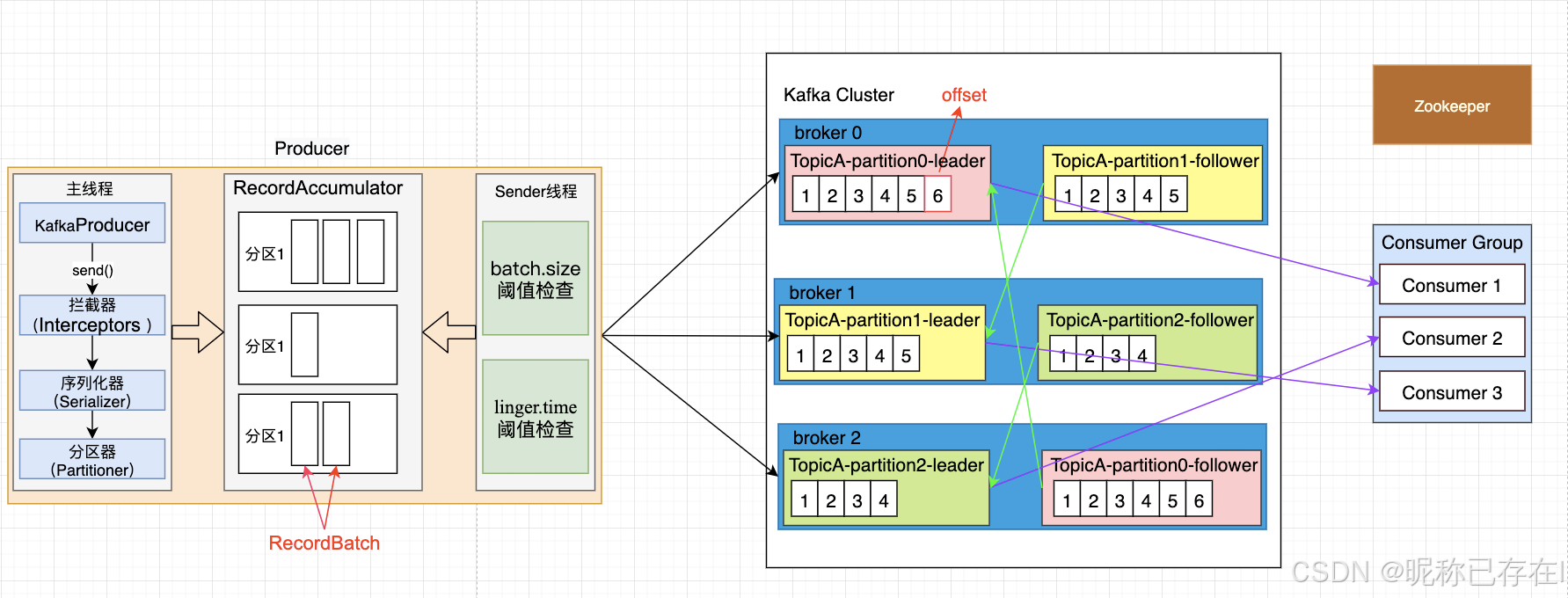
Kafka集群架构主要包括生产者、消费者、broker和注册中心(早期为Zookeeper,新版本为KRaft)等组件。生产者负责生成并发送消息到Kafka集群;消费者负责接收并处理消息;broker是Kafka的服务节点,负责存储和管理消息,每个broker都可以处理多个topic的消息;注册中心则负责统一管理Kafka集群元数据、选举可用控制器等功能

3.2 kafka 单机搭建
kafka 下载:https://kafka.apache.org/community/downloads/
本次单机使用内置zookeeper。
精力有限,集群及zookeeper下载配置,大家可参考其它文章研究
zookeeper下载:https://zookeeper.apache.org/releases.html
python
# 使用的是java 8.
# 3.9以上需要java11,java向后兼容,则java11 可以使用3.8
tar -zxvf kafka_2.13-3.8.1.tgz
cd kafka_2.13-3.8.1
vim config/server.properties
# 配置
---------------------------------------------------------------
# broker.id 在集群中唯一,单机用 0 就可以
broker.id=0
# 监听地址,让 Kafka 监听所有网卡上的 9092 端口=所有都可以访问
listeners=PLAINTEXT://0.0.0.0:9092
# 告诉客户端用服务器的 IP 连接,如果不设置,客户端只能连接 "localhost"
advertised.listeners=PLAINTEXT://<你的服务器IP>:9092
# 日志存储路径,建议修改到一个空间较大的位置
log.dirs=/app/kafka/kafka-logs
# ZooKeeper 连接地址,单机就用本地
zookeeper.connect=localhost:2181
#解释:
#listeners=0.0.0.0:9092 就像你开了一家店,门开向四面八方(所有方向都能进)
#advertised.listeners=192.168.10.131:9092 就像你在名片上印的地址,告诉顾客具体怎么找到你
----------------------------------------------------------------启动服务 (先 ZooKeeper,后 Kafka)
Kafka 依赖 ZooKeeper 来管理元数据,所以必须先启动它
python
# 启动 ZooKeeper:-daemon 参数让它在后台运行
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
# 启动 Kafka:
bin/kafka-server-start.sh -daemon config/server.properties
# 验证启动
#jps = Java Process Status 专门用来查看当前用户启动的所有 Java 进程
jps
# QuorumPeerMain (这个是 ZooKeeper)
3.3 Kafaka基础功能测试
Kafka的基础工作机制是消息发送者可以将消息发送到kafka上指定的topic,而消息消费者,可以从指定的topic上消费消息。
python
# 创建主题
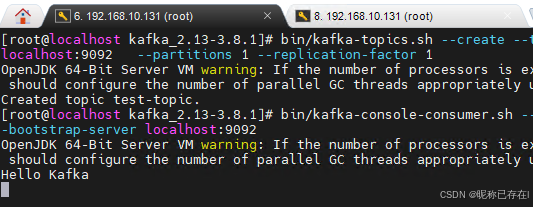
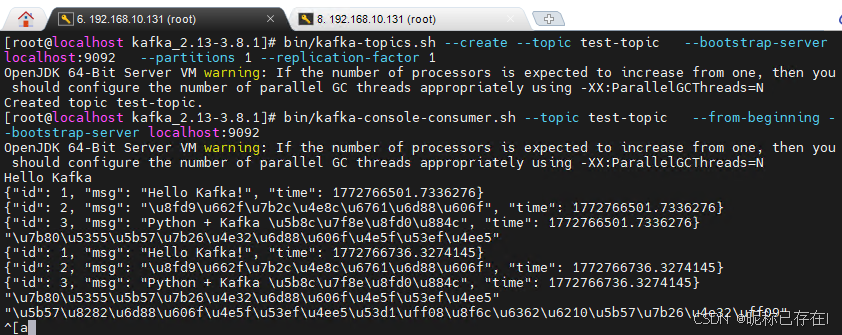
bin/kafka-topics.sh --create --topic test-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
# 启动一个消费者(监听消息)
bin/kafka-console-consumer.sh --topic test-topic --from-beginning --bootstrap-server localhost:9092
# 另开一个窗口,启动生产者(发送消息)
bin/kafka-console-producer.sh --topic test-topic --bootstrap-server localhost:9092
Python 示例
安装 Python Kafka 客户端
python
# 使用 pip 安装 kafka-python
pip install kafka-python
python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Kafka 单机环境 Python 测试脚本
包含:连接测试、生产者、消费者、主题管理
"""
import time
import json
from kafka import KafkaProducer, KafkaConsumer, KafkaAdminClient
from kafka.admin import NewTopic
from kafka.errors import NoBrokersAvailable, TopicAlreadyExistsError
# ========== 配置参数(根据你的环境修改)==========
KAFKA_SERVER = '192.168.10.131:9092' # 改成你的 Kafka 服务器 IP
TOPIC_NAME = 'test-topic'
# ============================================
def test_connection():
"""测试是否能连接到 Kafka"""
print(f"\n1. 测试连接 {KAFKA_SERVER}...")
try:
# 创建一个临时的生产者来测试连接
producer = KafkaProducer(
bootstrap_servers=KAFKA_SERVER,
max_block_ms=5000 # 最多等待5秒
)
# 尝试获取集群元数据
cluster = producer.bootstrap_connected()
if cluster:
print("✅ 连接成功!Kafka 服务正在运行")
else:
print("❌ 连接失败")
producer.close()
return cluster
except NoBrokersAvailable:
print("❌ 无法连接到 Kafka,请检查:")
print(" - Kafka 服务是否已启动")
print(" - 防火墙是否放行 9092 端口")
print(" - advertised.listeners 配置是否正确")
return False
except Exception as e:
print(f"❌ 连接出错: {e}")
return False
def create_topic():
"""创建测试主题"""
print(f"\n2. 创建测试主题 '{TOPIC_NAME}'...")
try:
admin_client = KafkaAdminClient(bootstrap_servers=KAFKA_SERVER)
# 定义新主题
topic_list = [
NewTopic(
name=TOPIC_NAME,
num_partitions=1, # 分区数
replication_factor=1 # 副本数(单机只能是1)
)
]
admin_client.create_topics(new_topics=topic_list, validate_only=False)
print(f"✅ 主题 '{TOPIC_NAME}' 创建成功")
admin_client.close()
return True
except TopicAlreadyExistsError:
print(f"ℹ️ 主题 '{TOPIC_NAME}' 已存在,继续使用")
return True
except Exception as e:
print(f"❌ 创建主题失败: {e}")
return False
def list_topics():
"""列出所有主题"""
print("\n3. 查看所有主题:")
try:
consumer = KafkaConsumer(bootstrap_servers=KAFKA_SERVER)
topics = consumer.topics()
for topic in sorted(topics):
print(f" - {topic}")
consumer.close()
except Exception as e:
print(f"❌ 获取主题列表失败: {e}")
def send_messages():
"""发送测试消息"""
print(f"\n4. 发送消息到 '{TOPIC_NAME}':")
producer = KafkaProducer(
bootstrap_servers=KAFKA_SERVER,
value_serializer=lambda v: json.dumps(v).encode('utf-8') # 自动序列化 JSON
)
# 发送几条测试消息
messages = [
{"id": 1, "msg": "Hello Kafka!", "time": time.time()},
{"id": 2, "msg": "这是第二条消息", "time": time.time()},
{"id": 3, "msg": "Python + Kafka 完美运行", "time": time.time()},
"简单字符串消息也可以", # 混合类型
#b"bytes message" # 二进制消息
"字节消息也可以发(转换成字符串)" # 改成字符串
]
for i, msg in enumerate(messages):
try:
# 发送消息
future = producer.send(TOPIC_NAME, value=msg)
# 等待发送完成
record_metadata = future.get(timeout=10)
print(f" ✅ 消息 {i + 1} 发送成功: {str(msg)[:30]}...")
print(f" 分区: {record_metadata.partition}, 偏移量: {record_metadata.offset}")
except Exception as e:
print(f" ❌ 消息 {i + 1} 发送失败: {e}")
producer.flush()
producer.close()
print(f"✅ 共发送 {len(messages)} 条消息")
def consume_messages():
"""消费消息"""
print(f"\n5. 消费 '{TOPIC_NAME}' 中的消息:")
consumer = KafkaConsumer(
TOPIC_NAME,
bootstrap_servers=KAFKA_SERVER,
auto_offset_reset='earliest', # 从最早的消息开始消费
enable_auto_commit=True, # 自动提交偏移量
group_id='python-test-group', # 消费者组ID
max_poll_records=10, # 每次最多拉取10条
consumer_timeout_ms=5000 # 5秒后如果没有新消息就退出
)
message_count = 0
try:
for message in consumer:
message_count += 1
print(f"\n 📨 收到第 {message_count} 条消息:")
print(f" 分区: {message.partition}")
print(f" 偏移量: {message.offset}")
print(f" 键: {message.key}")
# 尝试解析 JSON,如果失败就当普通字符串处理
try:
value = json.loads(message.value.decode('utf-8'))
print(f" 值 (JSON): {value}")
except:
value = message.value.decode('utf-8')
print(f" 值 (字符串): {value}")
# 模拟处理时间
time.sleep(0.5)
except Exception as e:
print(f"消费过程中出错: {e}")
finally:
consumer.close()
if message_count == 0:
print(" ℹ️ 没有收到任何消息")
else:
print(f"\n✅ 共消费 {message_count} 条消息")
def simple_test():
"""最简测试:只发一条消息,立刻消费"""
print("\n=== 快速测试模式 ===")
# 发送一条消息
producer = KafkaProducer(bootstrap_servers=KAFKA_SERVER)
future = producer.send(TOPIC_NAME, b"Quick test message")
result = future.get(timeout=5)
print(f"✅ 消息已发送,分区: {result.partition}, 偏移量: {result.offset}")
producer.close()
# 立即消费这条消息
consumer = KafkaConsumer(
TOPIC_NAME,
bootstrap_servers=KAFKA_SERVER,
auto_offset_reset='earliest',
max_poll_records=1,
consumer_timeout_ms=3000
)
for msg in consumer:
print(f"✅ 收到消息: {msg.value.decode('utf-8')}")
break
consumer.close()
if __name__ == "__main__":
print("=" * 50)
print("Kafka Python 测试脚本")
print("=" * 50)
print(f"Kafka 服务器: {KAFKA_SERVER}")
# 1. 先测试连接
if not test_connection():
print("\n❌ 无法连接到 Kafka,请先检查服务状态")
exit(1)
# 2. 创建主题
create_topic()
# 3. 列出主题
list_topics()
# 4. 发送消息
send_messages()
# 5. 消费消息
consume_messages()
# 6. 可选:快速测试
# simple_test()
print("\n" + "=" * 50)
print("测试完成!")
print("=" * 50)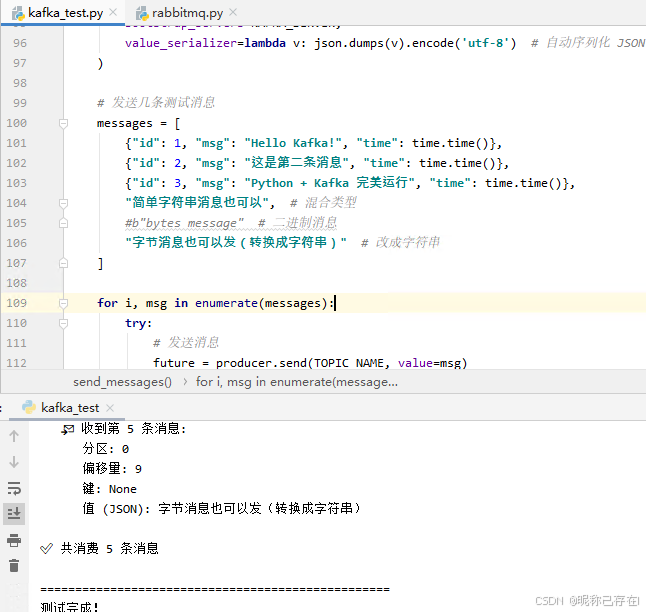
3.4 Kafka 智能监控与管理平台
下载地址:https://github.com/smartloli/EFAK
EFAK-AI (Eagle For Apache Kafka - AI) 是一款开源的 Kafka 智能监控与管理平台,融合了人工智能技术,为 Kafka 运维提供智能化、可视化、自动化的全方位解决方案
EFAK-AI 提供两种部署方式:Docker 容器化部署(推荐)和 tar.gz 安装包部署。具体参考github说明文档
四、RocketMQ 快速上手
4.1 产品介绍
RocketMQ 是一个纯Java开发、分布式、队列模型的开源消息中间件,前身是MetaQ,由阿里巴巴参考Kafka的特点研发而成,后捐献给Apache基金会成为顶级开源项目.
RocketMQ在设计上进行了多项创新,经过十多年的广泛场景打磨,已成为金融级可靠业务消息的行业标准
官网:https://rocketmq.apache.org/zh/
从物理部署上看,RocketMQ 服务端主要由两个核心组件构成,并且在 5.0 版本有了重大演进

RocketMQ 5.0 最重要的变化就是引入了 存算分离架构,通过新增的 Proxy 层来实现,职责单一,分工明确:Proxy 专注于计算和协议适配,Broker 专注于存储。这使得 Broker 的存储引擎可以做得更深、更稳定。
Broker 启动后,会向所有 NameServer 节点注册自身信息(如 IP、端口、存储的 Topic 队列等)。Producer 和 Consumer 在收发消息前,会先从 NameServer 获取最新的 Topic 路由信息
4.2 rocket 安装
python
unzip rocketmq-all-5.3.2-bin-release.zip
mv rocketmq-all-5.3.2-bin-release /usr/app/
# 创建软链接,方便以后升级
ln -s rocketmq-all-5.3.3-bin-release rocketmq
cd /usr/app/rocketmq-all-5.3.2-bin-release/
修改 JVM 内存参数(重要!)
RocketMQ 默认的启动内存要求较高(NameServer 默认 4G,Broker 默认 8G)。你的虚拟机可能没这么大内存,必须调小,否则启动会失败
python
vim bin/runserver.sh
-----------------------------------------------------------
JAVA_OPT="${JAVA_OPT} -server -Xms512m -Xmx512m -Xmn256m"
-----------------------------------------------------------
python
# 2. 调整 Broker 内存配置
vim bin/runbroker.sh
----------------------------------------------------------
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g"
----------------------------------------------------------RocketMQ 需要先启动 NameServer(注册中心),再启动 Broker(消息服务器)
python
# 启动 NameServer(-n 指定IP,这里先用 localhost)
nohup bin/mqnamesrv -n localhost:9876 > /usr/app/rocketmq/namesrv.log 2>&1 &
# 查看启动日志,确认成功
tail -f /usr/app/rocketmq/namesrv.log
# 看到 "The Name Server boot success..." 即表示成功[citation:1][citation:10]启动 Broker(含 Proxy 模式)
RocketMQ 5.x 引入了 Proxy 组件,我们采用最简单的 Local 模式(Broker 和 Proxy 同进程部署)
python
vim ~/.bash_profile
-----------------------------------
export NAMESRV_ADDR='localhost:9876'
------------------------------------
# 编辑 Broker 配置文件
# 简单配置一下 Broker,让它知道 NameServer 的地址
vim conf/broker.conf
----------------------------------------------------------
# 集群名称,单机可随意
brokerClusterName = DefaultCluster
# Broker 名称
brokerName = broker-a
# Broker ID,0 表示 Master
brokerId = 0
# NameServer 地址(关键!)
namesrvAddr = localhost:9876
# 允许自动创建 Topic(开发环境方便)
autoCreateTopicEnable=true
# Broker 对外暴露的 IP,如果是远程访问,这里需要改成你的内网 IP,例如 192.168.10.131
# brokerIP1 = 192.168.10.131
------------------------------------------------------------
# 启动 Broker,--enable-proxy 表示启用 5.x 的新特性[citation:2][citation:10]
nohup bin/mqbroker -c conf/broker.conf --enable-proxy > /usr/app/rocketmq/broker.log 2>&1 &
# 查看启动日志
tail -f /usr/app/rocketmq/broker.log
# 看到 "The broker[broker-a, 你的IP:10911] boot success..." 即表示成功[citation:1]

4.3 RocketMQ的基础使用
RocketMQ的基础使用主要包括主题管理、命令行工具以及Java,python客户端开发几个方面
执行任何 RocketMQ 相关命令都可能遇到内存问题,建议统一修改所有脚本的内存参数:
python
# 修改 runserver.sh(用于 NameServer)
vim /usr/app/rocketmq-all-5.3.2-bin-release/bin/runserver.sh
# 将 -Xms4g -Xmx4g 改为 -Xms256m -Xmx256m
# 修改 runbroker.sh(用于 Broker)
vim /usr/app/rocketmq-all-5.3.2-bin-release/bin/runbroker.sh
# 将 -Xms8g -Xmx8g 改为 -Xms512m -Xmx512m
# 修改 tools.sh(用于各种工具)
vim /usr/app/rocketmq-all-5.3.2-bin-release/bin/tools.sh
# 将 -Xms1g -Xmx1g 改为 -Xms128m -Xmx128m
python
# 使用自带的生产者工具发送消息
bin/tools.sh org.apache.rocketmq.example.quickstart.Producer
# 运行 Consumer 消费消息
bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer
# 查看 Broker 日志中是否有相关记录
tail -f ~/logs/rocketmqlogs/broker.log | grep TopicTest
# 查看所有主题
bin/mqadmin topicList -n localhost:9876

python
每个 SendResult 都表示一条消息发送成功:
SendResult [
sendStatus=SEND_OK, // 发送成功状态
msgId=C0A87A01...ECF0000, // 全局唯一消息ID
offsetMsgId=C0A80A83...3AFF2, // 物理存储消息ID
messageQueue=MessageQueue [ // 消息队列信息
topic=TopicTest, // 主题名称
brokerName=broker-a, // Broker名称
queueId=1 // 队列ID
],
queueOffset=251, // 队列中的偏移量
recallHandle=null
]开发测试
python
# Java客户端开发 在Maven项目中添加依赖
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client-java</artifactId>
<version>5.0.7</version>
</dependency>
# Spring Boot集成(更简单的开发方式)
# application.yml配置:
rocketmq:
name-server: 192.168.10.131:9876
producer:
group: spring-producer-group
#具体生产者 消费者消息参考其它python 示例
python
# Apache RocketMQ 官方开发文档中也标明,支持的平台只有 Linux 和 macOS,Windows 不被官方支持。
pip install rocketmq-client-python
# RocketMQ windows python 不支持.