摘要 本周阅读了论文GCPO,针对当前实验出现的预测目标稀疏、全局建模困难的问题进行简单的梳理,从GCPO找到解决办法。 ## Abstract This week, I read the paper GCPO and briefly reviewed the issues of sparse prediction targets and difficulties in global modeling that have arisen in current experiments, aiming to find solutions from GCPO.
- 残差
img1与img2之间只有文本区域不同,residual=img2-img1得到的就是图片大致需要编辑的区域,将残差作为模型需要预测的目标,输入rec2(新文本),img1_latent(原图),模型从rec2和img1_latent中学习预测这个对应的残residual。
自回归模型是从零生成的,如果重新生成一个图片,就会引入伪影和漂移导致效果不好,只对残差进行预测,就可以只编辑部分区域。
1、稀疏
残差作为目标稀疏性太高,输入的原图经过处理后是32*128的,需要从大的图片编辑文本这个较小的区域,稀疏的目标不适合预测。2、伪影
低分辨率导致的边缘模糊,上采样层把特征上采样到图片尺寸,会导致字体的边缘模糊。

原图


生成图


效果图
- 全图生成
输入rec2(新文本),img1_latent(原图)到模型,然后学习图片的KV特征,拼接查询txt_query,img_query得到生成的图片img2和对img1的识别。将目标文本和图片在第一阶段融合,第二阶段可以从零生成目标图片。
1、损失目标不一致
识别损失(rec_loss)与生成损失(mse_loss)的目标不一致,rec_loss希望kv特征中保留足够识别rec1的信息。生成损失(img_mse_loss)希望可以从kv特征重建出img2,而img2的文字是rec2,与rec1不同。
2、没有显式空间建模
缺少图片mask来计算注意力损失,让注意力更多关注文本区域,没有空间对齐;
- Group Critical-token Policy Optimization for Autoregressive Image Generation
由于AR模型的自注意力机制,早期生成的token持续影响后续所有token,对图像整体结构起到决定性作用。实验显示,对前10%的图像token添加扰动会导致图像全局结构发生明显变化,而对中间token的扰动仅影响有限的局部细节。

研究发现,token熵的梯度图能够稳定地标识出图像中的结构区域。高熵梯度token通常对应于主体结构或视觉区域间的过渡区域,这些区域随着RL训练变得更加明显,显示出对RL训练的敏感性。熵梯度反映的是图像中结构边界和视觉区域连接处的变化强度,是识别图像结构关键 token 的稳定指标。

在GRPO的组内采样中,某些位置的token在不同图像间展现出显著差异性。低相似度token往往对应复杂结构区域,为策略优化提供更丰富信息。
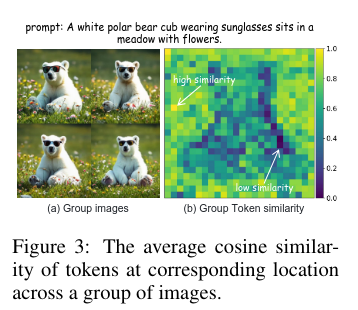
GCPO框架:
1、关键Token选择策略:综合上述三个角度,从全部Token中筛选出约30%的关键Token。
2、动态优势权重:基于策略模型与参考模型在关键Token上的置信度差异,为每个关键Token分配动态的优势权重,以分配不同程度的探索权重。
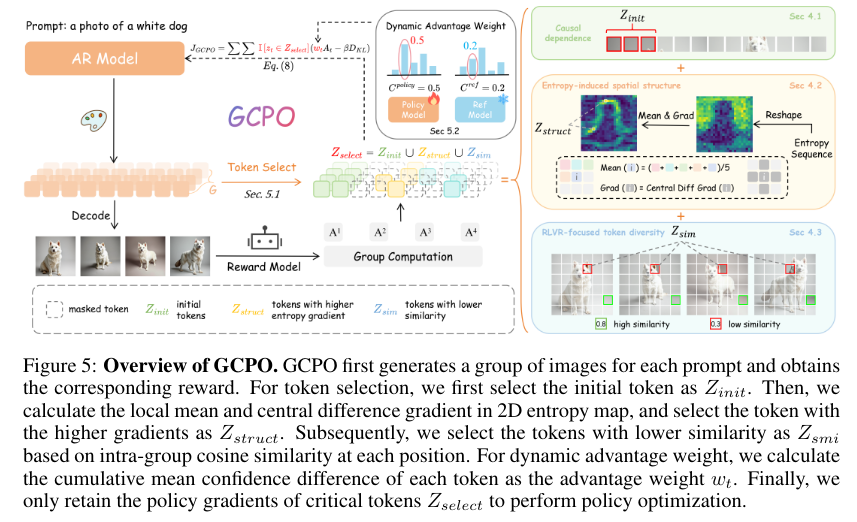
首先为每一个提示生成一组图片,选择前10%的关键token为zinitz_{init}zinit,然后从剩下的token根据熵梯度、相似性对剩下的token来进行采样,为每一类token分配一个权重,通过训练动态调整这个权重。
对这组图片也会获得奖励,效果好的,得到的奖励更高,同时组内计算奖励均值和标准差,这个图片相对其他图片好与坏由公式(Ri−R‾)σ\frac{(R_i-\overline{R})}{\sigma}σ(Ri−R)
对于我的问题
1.引导模型聚焦文本区域
关键 token,可以在损失计算中赋予它们更高的权重,迫使模型优先保证文本区域的准确重建。这直接针对任务核心------文本内容的正确性和视觉一致性。
- 提升序列生成的稳定性
在自回归中,优化这些关键token的预测精度,可以为后续生成提供更可靠的上下文,避免误差累积。
- 强化文本-图像对齐
关键 token 可以显式地与文本条件建立更强的关联,使模型在生成每个图像 patch 时都能充分参考对应的文本字符信息,提高文本布局和风格的准确性。
- 改善样本效率
模型可以更快地学习到文本编辑的本质规律,而不是浪费容量在背景等无关区域上。这在不增加数据集的情况下尤其重要。
总结
阅读GCPO论文后,觉得可以用于优化预测的目标和流程,解决稀疏和全局重建的劣势。