GRPO 深度解析 (TRL 源码视角)
TRL 是一个面向后训练(post-training)的前沿库,支持 SFT、GRPO、DPO 等技术,构建于 🤗 Transformers 生态之上,可跨多种硬件规模扩展。
一、核心思想
GRPO(Group Relative Policy Optimization) 是一种专为大语言模型设计的强化学习算法。
它最大的创新在于:去掉了传统 PPO 中庞大的 Critic 模型。
取而代之的方式是:
- 对同一个 Prompt,一次性生成 G 条回复
- 用 Reward 函数对这 G 条回复分别打分
- 以这组分数的组内均值作为基线,计算每条回复的相对优势(Advantage)
- 用 Advantage 指导参数更新:高于均值的 → 增大生成概率(鼓励),低于均值的 → 减小概率(惩罚)
对比 PPO:PPO 需要一个额外的 Critic 网络来估计当前状态的价值函数 V(s),而 GRPO 直接用组内统计量替代,大幅降低了显存和计算开销。
二、整体框架
核心骨架围绕三个方面展开:模型体系 、奖励机制(Reward) 、生成引擎(vLLM 等)。
2.1 Reference Model(参考模型)
Reference Model 用于计算 KL 散度,防止策略模型训练偏离太远(由超参 beta 控制)。
python
self.beta = args.beta
if self.beta == 0.0:
# beta=0 时不需要 KL 约束,Reference Model 置空
self.ref_model = None
elif is_peft_model(model):
# 使用 PEFT(如 LoRA)时,关闭 adapter 即可还原为初始模型,无需单独维护
self.ref_model = None
else:
# 全量微调或 DeepSpeed/FSDP 场景:从头创建一份 Reference Model
self.ref_model = create_model_from_path(...)
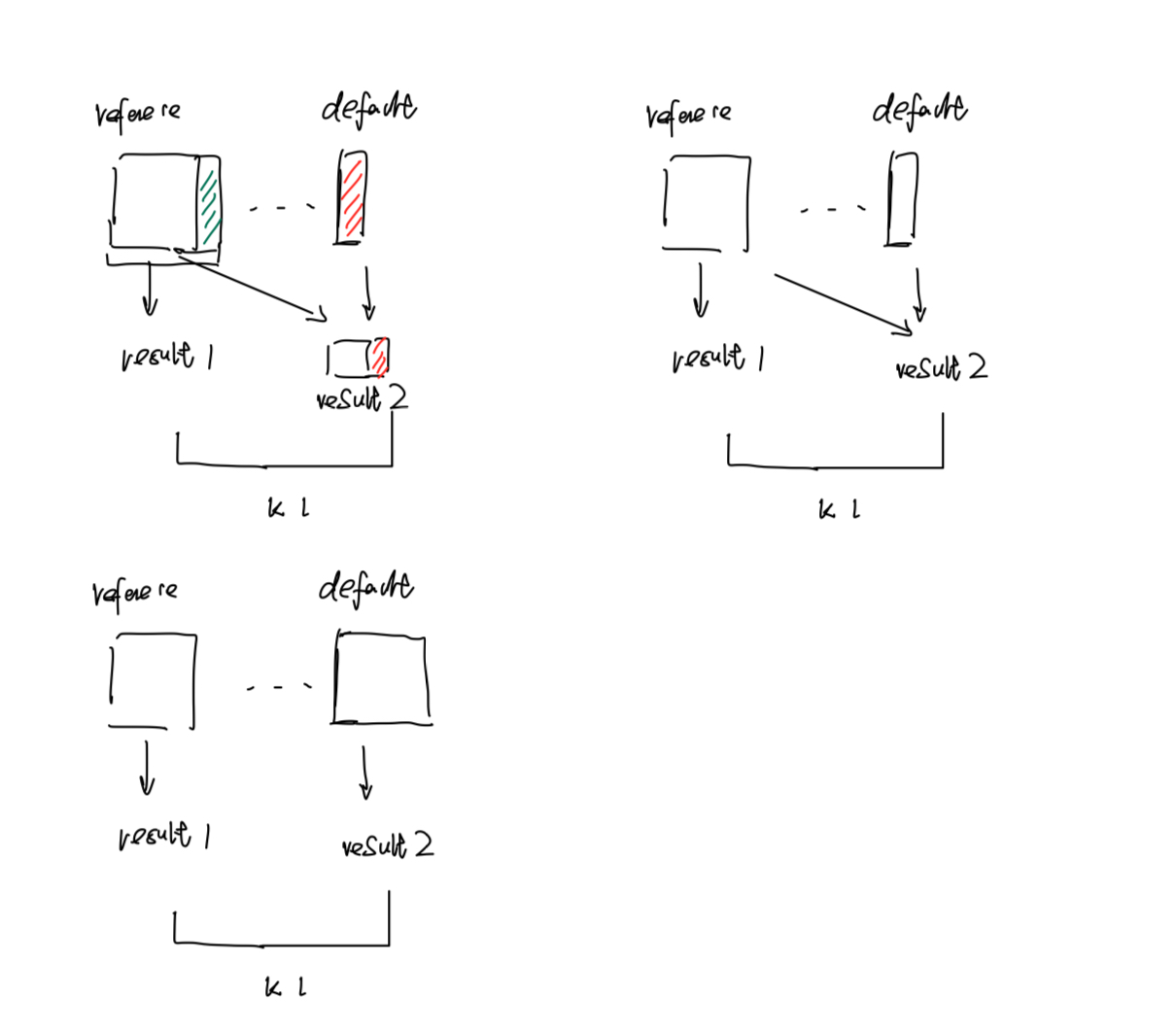
一种需要new model instance , 一种不需要
2.2 Reward Model(奖励模型)
Reward Model 有两种形式:
- 预训练神经网络 (
AutoModelForSequenceClassification) - 基于规则的函数 (如
if-else长度判断、正则匹配输出格式、调用外部代码编译器)
python
# 统一包装成列表,支持多个 Reward 函数组合
if not isinstance(reward_funcs, list):
reward_funcs = [reward_funcs]
for i, reward_func in enumerate(reward_funcs):
if isinstance(reward_func, str):
# 传入模型路径字符串 → 加载预训练的序列分类模型
reward_funcs[i] = AutoModelForSequenceClassification.from_pretrained(...)当传入多个 Reward 函数(如 [length_reward, format_reward, accuracy_reward])时,GRPOTrainer 会将多位"裁判"的分数合并。
三、生成与打分:_generate_and_score_completions
这是训练循环的核心函数,负责:
- 为当前 Batch 的 Prompts 生成多条补全(completions)
- 对补全进行 Padding 和张量化
- 计算每条补全的 per-token log 概率(用于后续 loss 计算)
- 调用 Reward 函数打分,计算 Advantage
3.1 生成与 Padding
python
# 生成回答(支持 vLLM 和 HF generate 两种引擎)
(
prompt_ids_list,
completion_ids_list,
...
) = self._generate(prompts)
# 将变长序列 Padding 成等长张量
# Prompt 左 Padding,Completion 右 Padding
prompt_ids = pad(prompt_ids, padding_side="left", ...).to(device)
completion_ids = pad(completion_ids, padding_side="right", ...).to(device)3.2 Advantage 计算(多目标 Reward 合并)
当存在多个 Reward 函数时,TRL 提供两种合并策略:
策略一:sum_then_normalize(先加权求和,再组内归一化)
python
# 1. 对各 reward 函数的输出加权求和
rewards = (rewards_per_func * self.reward_weights).nansum(dim=1)
# 2. 组内均值作为基线(GRPO 核心:对比 PPO 的优势函数)
mean_grouped_rewards = rewards.view(-1, num_generations).mean(dim=1)
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(num_generations, dim=0)
# 3. 计算优势值,并用组内标准差归一化
advantages = rewards - mean_grouped_rewards
advantages = advantages / (std_rewards + 1e-4)策略二:normalize_then_sum(先各自归一化,再加权求和)
python
# 先对每个 reward 函数的输出单独做组内归一化
grouped = rewards_per_func.view(-1, num_generations, len(self.reward_funcs))
reward_k = (grouped - mean_k) / (std_k + 1e-4)
# 再加权求和,得到最终 advantages
rewards = (reward_k * self.reward_weights).nansum(dim=1)
advantages = (rewards - rewards.mean()) / (std_rewards + 1e-4)四、损失函数计算:_compute_loss
4.1 概率比(重要性权重)
python
# log_ratio = log(π_θ / π_old)
log_ratio = per_token_logps - old_per_token_logps
# coef_1 = π_θ / π_old(新旧策略的概率比)
coef_1 = torch.exp(log_ratio)4.2 KL 散度惩罚项
python
if self.beta != 0.0:
# 用近似公式计算 token 级别的 KL(ref || model)
per_token_kl = (
torch.exp(ref_per_token_logps - per_token_logps)
- (ref_per_token_logps - per_token_logps)
- 1
)4.3 各 Loss 类型
TRL 支持多种 loss 变体,核心是 GRPO:
python
if self.loss_type in ["grpo", "bnpo", "dr_grpo", "dapo", "luspo"]:
# coef_2:对概率比进行 Clipping,防止单步更新过大(类比 PPO 的 clip trick)
coef_2 = torch.clamp(coef_1, 1 - self.epsilon_low, 1 + self.epsilon_high)
per_token_loss1 = coef_1 * advantages
per_token_loss2 = coef_2 * advantages
# 取两者中较保守的一个,防止策略飞车
per_token_loss = -torch.min(per_token_loss1, per_token_loss2)Clipping 的作用 :把新旧策略的概率比强制截断在
[1-ε, 1+ε]之间,防止一次梯度步走得太远,是 PPO-style 算法的核心稳定性机制。
4.4 最终 Loss 聚合
python
# GRPO:对每条序列内取 token 平均,再对 batch 取均值
if self.loss_type == "grpo":
loss = ((per_token_loss * mask).sum(-1) / mask.sum(-1).clamp(min=1.0)).mean()
# 加上 KL 惩罚
if self.beta != 0.0:
per_token_loss = per_token_loss + self.beta * per_token_kl五、分组采样实现:_get_train_sampler
GRPO 的关键工程细节:同一个 Prompt 必须在同一个 GPU 上被复制 G 次,才能在组内计算 Advantage。
| GPU 0 | GPU 1 |
global_step step <──> num_generations=2
<─────> per_device_train_batch_size=3
grad_accum=2 ▲ ▲ 0 0 0 0 1 1 2 2 ← 生成 prompts 0-11;存缓存;取第1切片算 loss
▼ | 0 1 3 3 4 4 5 5 ← 从缓存取第2切片
|
| 1 2 6 6 7 7 8 8 ← 从缓存取第3切片
steps_per_gen=4 ▼ 1 3 9 9 10 10 11 11 ← 从缓存取第4切片
2 4 12 12 13 13 14 14 ← 再次生成(第二轮)
python
return RepeatSampler(
data_source=dataset,
mini_repeat_count=self.num_generations, # 每个 prompt 复制 G 次
batch_size=self.args.generation_batch_size // self.num_generations,
repeat_count=self.num_iterations * self.args.steps_per_generation,
shuffle=self.shuffle_dataset,
seed=self.args.seed,
)六、双引擎架构:生成与训练解耦
6.1 为什么要解耦?
文本生成(自回归 Inference)和梯度更新(Forward/Backward)在计算特性上有本质差异:
| 阶段 | 瓶颈 | 优化手段 |
|---|---|---|
| 推理(生成) | 显存带宽(KV Cache 频繁读写) | vLLM PagedAttention、FlashAttention |
| 训练(梯度) | 显存容量(激活值 + 梯度 + 优化器状态) | 混合精度、梯度累积、ZeRO |
两种优化策略互不兼容,混在一起只会两头受损。RL 训练的标准做法:攒一个超级大 Batch 做生成 → 切片 → 多次梯度更新。
代码逻辑:
python
generate_every = self.args.steps_per_generation * self.num_iterations
if self._step % generate_every == 0 or self._buffered_inputs is None:
# 1. 一次性生成大 Batch 并打分
generation_batch = self._generate_and_score_completions(generation_batch)
# 2. 切分成小份,存入缓存
generation_batches = split_tensor_dict(generation_batch, self.args.steps_per_generation)
self._buffered_inputs = generation_batches
# 3. 每次训练只取缓存里的一小份算 loss 和梯度
inputs = self._buffered_inputs[self._step % self.args.steps_per_generation]6.2 权重同步问题
双引擎架构带来一个工程挑战:vLLM 的推理权重和 PyTorch 的训练权重需要保持同步。
python
# 每次生成前,检查 step 是否变化,若变化则同步权重
if self.state.global_step != self._last_loaded_step:
self.vllm_generation.sync_weights()
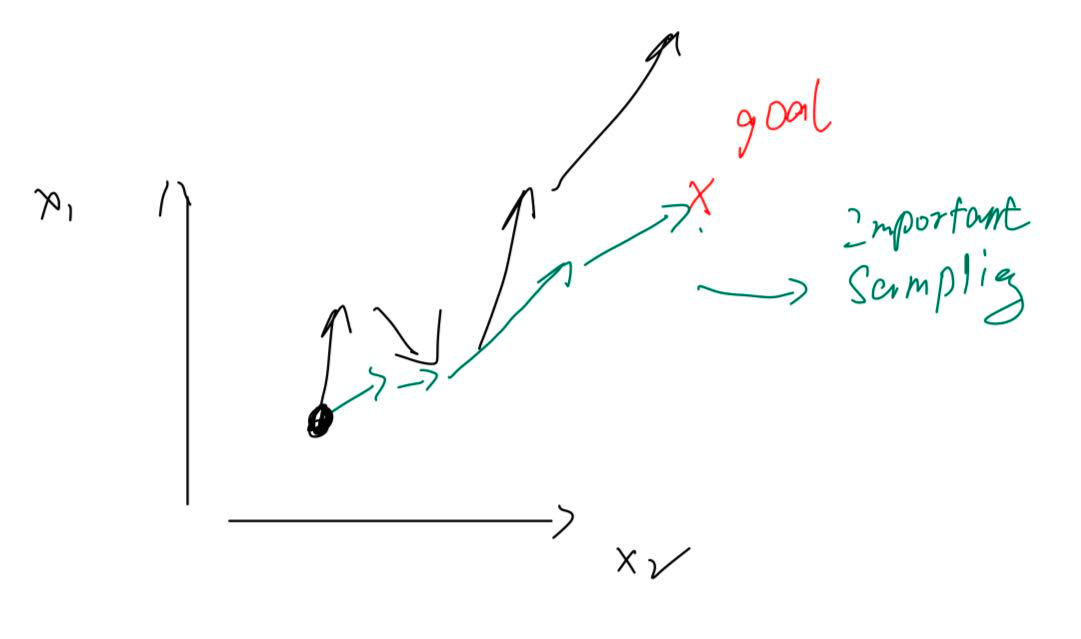
self._last_loaded_step = self.state.global_step七、重要性采样修正(Importance Sampling)
7.1 问题来源
设想:vLLM 用"旧权重"生成了 1000 条回答,切成 10 份,PyTorch 做 10 次梯度更新。第 2~10 次更新时,训练数据仍是旧权重生成的,但模型已经被更新过了 → 数据分布偏移(off-policy)。
7.2 数学修正
E x ∼ π sample π θ ( x ) π sample ( x ) × Loss ( x ) \mathbb{E}{x \sim \pi{\text{sample}}} \left \\frac{\\pi_{\\theta}(x)}{\\pi_{\\text{sample}}(x)} \\times \\text{Loss}(x) \\right Ex∼πsampleπsample(x)πθ(x)×Loss(x)
在对数空间下,概率除法变减法,避免浮点下溢:
python
# 计算重要性采样比值
per_token_logps_diff = (old_per_token_logps - sampling_per_token_logps) * mask
vllm_importance_sampling_ratio = torch.exp(per_token_logps_diff)
# 用 clamp 截断过大的比值,防止数值爆炸
vllm_importance_sampling_ratio = torch.clamp(
vllm_importance_sampling_ratio, max=self.vllm_importance_sampling_cap
)
# 作用到最终 loss 上
per_token_loss = per_token_loss * inputs["importance_sampling_ratio"]直觉理解:这是一种坐标系修正。就像在运动学中,从地面参考系切换到运动参考系时需要做速度变换一样,这里是把"从旧策略角度看到的数据"修正为"从当前策略角度看到的期望"。
八、从零手写极简训练循环(伪代码)
思考题:脱离 TRL 的工程封装,从
prompts到loss.backward()+optimizer.step(),完整流水线是什么?
python
def train_step(prompts, model, ref_model, reward_fn, optimizer):
G = num_generations # 每个 prompt 生成的回复数
# ── Step 1: 生成 ──────────────────────────────────
# 对每个 prompt,采样 G 条回复
completions = model.generate(prompts, num_return_sequences=G)
# completions.shape: (B*G, seq_len)
# ── Step 2: 打分 ──────────────────────────────────
rewards = reward_fn(prompts, completions) # shape: (B*G,)
# ── Step 3: 计算 Advantage(GRPO 核心)────────────
rewards_grouped = rewards.view(B, G)
mean_rewards = rewards_grouped.mean(dim=1, keepdim=True) # 组内均值作为基线
std_rewards = rewards_grouped.std(dim=1, keepdim=True)
advantages = ((rewards_grouped - mean_rewards) / (std_rewards + 1e-4)).view(B*G)
# ── Step 4: 计算 per-token log prob ───────────────
per_token_logps = model.get_logps(prompts, completions)
ref_per_token_logps = ref_model.get_logps(prompts, completions) # 如果 beta > 0
# ── Step 5: 计算 Loss ─────────────────────────────
# Clipped surrogate loss(类 PPO)
old_logps = per_token_logps.detach()
ratio = torch.exp(per_token_logps - old_logps) # coef_1
ratio_clipped = torch.clamp(ratio, 1 - eps, 1 + eps) # coef_2
policy_loss = -torch.min(ratio * advantages, ratio_clipped * advantages)
# KL 惩罚(防止偏离参考模型太远)
kl = torch.exp(ref_per_token_logps - per_token_logps) - (ref_per_token_logps - per_token_logps) - 1
per_token_loss = policy_loss + beta * kl
# 对 token 和 batch 维度取均值
loss = (per_token_loss * completion_mask).sum(-1) / completion_mask.sum(-1).clamp(1)
loss = loss.mean()
# ── Step 6: 反向传播 ──────────────────────────────
loss.backward()
optimizer.step()
optimizer.zero_grad()
return loss.item()