系统架构与设计能力
- 掌握主流架构模式:
单体架构、微服务架构(Spring Boot / FastAPI + gRPC)、事件驱动架构(Kafka + RabbitMQ)、CQRS、六边形架构、分层架构(Controller-Service-Repository)等。 - 熟悉分布式系统原理:
CAP定理、一致性、负载均衡、服务发现、熔断降级、分布式事务。具备高并发、高可用、高性能设计经验:能针对业务场景做出合理权衡。 - 云原生与部署架构:
熟悉Docker容器化、Kubernetes编排、服务网格(如Istio)以及云服务平台(AWS/Aliyun/腾讯云)的常用服务。能够设计可弹性伸缩、易于部署和运维的系统架构。 - 安全性设计:
将安全作为架构的核心要素,包括但不限于身份认证与授权(OAuth2.0, JWT)、数据加密、API安全、常见Web漏洞防护等。
主流架构模式
分布式系统与软件体系结构风格是两个密切相关但本质不同的概念。以下是它们的区别与关系的清晰梳理:
核心区别
- 分布式系统是一种系统部署与运行的形态,强调的是多个独立节点通过网络协同工作,以实现高可用性、可扩展性和容错性等目标。它关注的是"系统如何分布运行"。
- 软件体系结构风格是一种设计抽象模式,描述的是系统组件的组织方式、交互规则和结构范式(如分层、事件驱动、微服务等)。它关注的是"系统内部如何组织"。
传统经典架构模式
1、分层架构(Layered Architecture)
将系统划分为多个层次(如表示层、业务逻辑层、数据访问层),各层单向依赖。适用于结构清晰、变更较少的系统,如传统企业管理系统 。
在软件架构中,"分层架构(Controller-Service-Repository)"通常指 Spring Boot 等现代 Java Web 框架中推荐的三层或四层结构,而"传统分层架构"多指早期企业应用中较粗粒度的 表现层(UI)-业务逻辑层(BLL)-数据访问层(DAL) 模式。两者核心思想一致(关注点分离、低耦合),但在具体实现、职责划分和适用场景上存在差异。
-
现代三层(Controller-Service-Repository):
- Controller:仅处理 HTTP 请求/响应、参数校验、调用 Service,不包含业务逻辑。
- Service:专注核心业务逻辑、事务管理、流程编排,可调用多个 Repository 或第三方服务。
- Repository:仅负责数据持久化操作(CRUD),隔离数据库细节,支持更换持久化技术(如从 MySQL 换成 MongoDB)。
- 数据载体分离(DTO vs Entity):明确区分 Entity(数据库实体) 和 DTO(数据传输对象),避免敏感信息泄露,提升接口稳定性 。
- 依赖 Spring 的 @Controller、@Service、@Repository 等注解,实现自动依赖注入与事务管理 。
- 每层可独立单元测试(如 Mock Repository 测试 Service),无需启动 Web 容器或数据库 。
- 可演进为 领域驱动设计(DDD)四层架构(Interface-Application-Domain-Infrastructure),将业务逻辑下沉至领域层,更贴近业务本质。
-
传统分层架构:
- 三层划分较模糊,业务逻辑常混杂在 Controller 或 DAO 层,导致代码复用性差、测试困难。
- 数据载体分离(DTO vs Entity):常直接暴露 Entity 给前端,存在安全与耦合风险。
- 多使用原始 JDBC 或早期 ORM(如 Hibernate 配置复杂),缺乏统一管理机制。
- 测试常需依赖完整上下文,效率低。
- 以数据库为中心,"贫血模型" 常见,业务逻辑分散。
现代分层架构(Controller-Service-Repository)是传统分层架构的精细化、工程化演进,更适合中大型 Spring Boot 项目,强调高内聚、低耦合、可测试、易维护。而传统分层在小型项目或早期系统中常见,但容易导致"面条式代码" 。
2、客户端-服务器架构(Client-Server)
客户端-服务器架构(Client-Server,简称 C/S 架构)是一种分布式计算模型,将系统划分为两个核心角色:
- 客户端(Client):主动发起请求,负责用户交互、界面展示和部分业务逻辑处理;
- 服务器(Server):被动等待请求,负责处理业务逻辑、数据存储、安全控制并返回结果。
由客户端发起请求、服务器提供服务,适用于集中式资源管理场景,如数据库应用、文件共享 。
核心特征
- 请求-响应模式:客户端发送请求,服务器处理后返回响应 。
- 角色分离:客户端专注前端交互,服务器专注后端服务与数据管理 。
- 集中管理:数据和核心规则通常集中在服务器端,便于统一维护与安全控制 。
- 可扩展性:支持多个客户端同时连接同一服务器,适用于局域网或广域网环境 。
典型结构类型
-
两层架构(传统 C/S)
- 客户端承担界面 + 部分业务逻辑
- 服务器负责数据库操作
- 缺点:维护成本高、跨平台兼容性差
-
三层架构(现代演进)
- 表示层(客户端):用户界面
- 业务逻辑层(中间件/应用服务器):处理核心规则
- 数据访问层(数据库服务器):数据持久化
- 优势:松耦合、易维护、支持异构系统
优缺点对比
-
优点
- 响应速度快(客户端可分担计算)
- 安全性高(权限集中控制)
- 交互丰富(适合定制化界面)
- 适合局域网高性能应用(如游戏、专业软件)
-
缺点
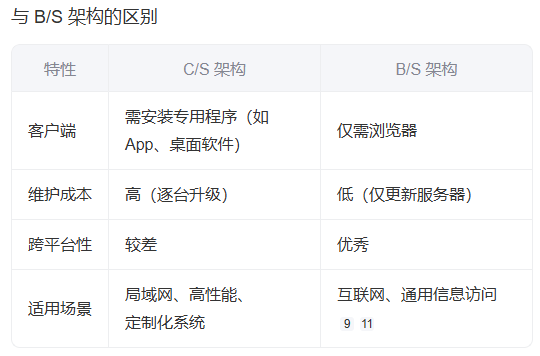
- 适用面窄,通常用于局域网中。
- 客户端需安装专用软件,部署与升级成本高
- 跨平台兼容性差(需为不同 OS 开发不同版本)
- 维护复杂(每台客户端需单独管理)
当前主流互联网应用多采用 B/S 架构,但 C/S 仍在金融、游戏、工业软件等领域广泛应用
相对于C/S,B/S具有如下优势:
1、分布性:可以随时进行查询、浏览等业务
2、业务扩展方便:增加网页即可增加服务器功能
3、维护简单方便:改变网页,即可实现所有用户同步更新
4、开发简单,共享性强,成本低,数据可以持久存储在云端而不必担心数据的丢失。
3、主从架构(Master-Slave)
主从架构(Master-Slave Architecture)是一种典型的分布式系统设计模式,其核心特征是通过角色划分实现资源协调:由一个主节点(Master)负责决策、调度和写操作,多个从节点(Slave)负责执行具体任务或提供读服务。
主节点协调多个从节点执行任务,常用于数据库复制、分布式计算等场景 。
核心特点
-
主节点职责:
- 承担写操作(如数据库的 INSERT/UPDATE/DELETE)
- 管理集群元信息、状态、任务分配
- 作为系统"决策中枢"
-
从节点职责:
- 执行主节点分配的任务(如计算、存储、查询)
- 通常只处理读请求(如 SELECT)
- 通过复制主节点数据保持同步
典型优势:
- 高可用性:从节点可接管主节点故障后的服务
- 负载均衡:读写分离减轻主节点压力
- 横向扩展:增加从节点可提升读吞吐量
潜在缺陷:
- 单点故障风险:主节点宕机可能导致服务中断(除非有自动故障转移机制)
- 数据一致性挑战:异步复制可能造成主从数据延迟
典型应用场景
- 数据库系统:MySQL、Redis、MongoDB(早期)使用主从复制实现读写分离与高可用
- 分布式计算框架:Hadoop MapReduce(Master + Workers)、Flink(JobManager + TaskManager)
- 存储系统:HDFS(NameNode + DataNode)、Elasticsearch(Master Node + Data Node)
- 持续集成工具:Jenkins(Master 调度任务,Slave 执行构建)
- 操作系统:早期多处理机系统如 DEC System 10、Cyber-170
- 工业控制:PLC 主从通信、数控系统中的 PC-DSP 控制
4、管道-过滤器架构(Pipe-Filter)
管道-过滤器架构(Pipe-Filter Architecture)是一种面向数据流的软件体系结构风格,其核心思想是将复杂的数据处理任务分解为一系列独立、可复用的处理单元(称为"过滤器"),并通过"管道"连接这些过滤器,形成一条有序的数据处理链路。
数据通过一系列独立处理组件(过滤器)流动,适用于编译器、生物信息学工作流等数据处理场景 。
核心组成
- 过滤器(Filter)
- 每个过滤器是一个独立的处理单元,负责执行特定的数据处理任务(如清洗、转换、校验、聚合等)。
- 过滤器之间无直接依赖,仅通过标准化接口与管道交互。
- 常见类型包括:
- 输入过滤器(如数据采集)
- 处理过滤器(如格式转换、逻辑校验)
- 输出过滤器(如结果写入)
- 管道(Pipe)
- 作为过滤器之间的数据传输通道,负责将前一个过滤器的输出传递给下一个过滤器的输入。
- 通常具备缓冲能力,支持异步或同步传输,甚至可实现并发处理。
主要特点
- 模块化与高内聚:每个过滤器职责单一,便于开发、测试和维护。
- 松耦合:过滤器之间不共享状态,仅通过数据流通信,便于替换或升级。
- 可重用性:相同过滤器可在不同系统或流程中复用。
- 支持并行与流水线处理:多个过滤器可同时运行,提升整体处理效率。
- 易于扩展:新增功能只需添加新过滤器,无需修改现有逻辑。
典型应用场景
- Unix/Linux 命令行管道(如 grep "ERROR" log.txt | sort | uniq -c)
- 编译器(词法分析 → 语法分析 → 语义分析 → 代码生成)
- ETL 工具(抽取 → 转换 → 加载)
- Web 框架中间件(如 Gin、Koa 的请求处理链)
- 图像/音视频处理流水线
- 日志分析系统(采集 → 清洗 → 解析 → 存储)
5、事件总线架构(Event-Bus)
事件总线架构(Event-Bus) 是一种基于 发布-订阅(Publish-Subscribe)模式 的软件架构风格,用于实现系统组件之间的 松耦合通信。其核心思想是:组件不直接相互调用,而是通过一个中央"事件总线"发布和订阅事件,从而完成异步协作。
组件通过发布/订阅事件通信,适用于异步解耦场景,如Android系统通知机制 。
核心特点
- 解耦:发布者与订阅者无需知道彼此的存在,仅通过事件类型或主题进行交互。
- 异步通信:事件通常异步处理,提升系统响应性和吞吐量。
- 可扩展:新增订阅者无需修改发布者代码,支持灵活扩展。
- 多对多通信:一个事件可被多个订阅者接收,也可由多个发布者产生。
典型应用场景
- 微服务架构:服务间通过事件(如"订单创建""用户注册")协同,避免直接HTTP调用。
- 前端组件通信:如 Vue 中的 EventBus,用于非父子组件间传递数据。
- Android 组件通信:替代 Intent、Handler,实现 Activity、Fragment、Service 间高效通信。
- 事件驱动架构(EDA):支撑实时数据处理、自动化运维、AI 触发等场景。
主要实现形式
- 轻量级框架:适用于单体应用或移动端,EventBus(Android/Java)
- 中间件事件总线: 用于分布式系统、微服务,阿里云 EventBridge
- 消息队列实现:基于 Kafka、RabbitMQ 等构建高可靠事件总线
- 语言原生实现:如 Go 使用 Channel 实现简易事件总线
6、MVC架构(Model-View-Controller)
MVC架构(Model-View-Controller)是一种经典的软件架构模式,用于将应用程序的数据逻辑、用户界面和用户交互控制分离,以提升代码的可维护性、可复用性和可测试性。
分离数据(Model)、界面(View)和控制逻辑(Controller),是Web开发(如Django、Rails)的核心范式 。
核心组成部分与职责
- Model(模型)
- 负责管理应用程序的数据和业务逻辑。
- 封装数据状态、访问数据库、执行业务规则。
- 不依赖视图或控制器,可被多个视图复用。
- View(视图)
- 负责展示数据给用户,即用户界面(如 HTML、JSP、前端页面等)。
- 仅关注数据呈现,不包含业务逻辑。
- 可从模型获取数据并响应其变化(在某些实现中)。
- Controller(控制器)
- 作为中间协调者,接收用户输入(如点击、表单提交)。
- 根据请求调用相应的模型方法更新数据,并选择合适的视图进行展示。
- 不直接处理业务逻辑或数据展示,只负责流程控制。
MVC 的优势
- 关注点分离:数据、界面、控制逻辑各司其职,便于团队协作。
- 高复用性:同一模型可被多个视图使用(如网页版与移动端共用后端模型)。
- 易测试:各组件可独立进行单元测试。
- 易维护与扩展:修改某一部分通常不影响其他部分。
常见应用场景与框架
- Web 开发:
- Java:Spring MVC、Struts
- .NET:ASP.NET MVC
- Python:Django(采用 MTV 模式,类似 MVC)
- Ruby:Ruby on Rails
- 桌面应用:Smalltalk-80、Cocoa(macOS/iOS)等早期 GUI 框架 。
与其他架构的对比
- 与 MVVM 对比:
- MVC 中 Controller 手动协调 Model 与 View;
- MVVM 通过双向数据绑定自动同步 View 与 ViewModel,更适合复杂前端交互 。
- 与分层架构区别:
- MVC 是架构模式,强调组件间协作关系;
- 分层(如三层架构)是代码组织方式,侧重纵向划分(表现层、业务层、数据层)。
7、黑板架构(Blackboard)
黑板架构(Blackboard Architecture)是一种用于解决复杂、非结构化问题的软件体系结构风格,特别适用于需要多知识源协作、推理驱动且无确定解决策略的场景。它模仿人类专家团队围绕黑板协同工作的过程,通过共享数据逐步构建解决方案。
多个知识源协作解决无确定解法的问题,用于语音识别、蛋白质结构分析等复杂推理场景 。
核心组成
- 黑板(Blackboard):全局共享的数据存储结构,用于存放问题的初始状态、中间结果、假设及最终解。所有知识源均可读写该数据。
- 知识源(Knowledge Sources):独立的专家模块,每个专注于特定子问题或领域知识,通过模式匹配监听黑板变化,并在适当时机贡献自己的推理结果。
- 控制组件(Controller):协调知识源的执行顺序与时机,根据黑板当前状态决定下一个激活哪个知识源,直至问题解决或达到终止条件。
特点与优势
- 模块化:知识源相互独立,便于维护和扩展。
- 灵活性:支持动态添加或移除专家模块。
- 适应性:能处理不完整、不确定或模糊的信息。
- 协作性:多个异构知识源通过黑板协同推理,适合复杂问题求解。
典型应用场景
- 语音识别(如早期Hearsay-II系统)
- 模式识别
- 专家系统
- 医学诊断辅助(如BFBEST工具)
- 多模态推理与大模型时代的智能体协作(如LangGraph实现的Blackboard Agent)
实现方式
- 使用数据库作为共享黑板(常见做法)
- 基于发布-订阅模式,利用消息队列(如Kafka、RabbitMQ)实现知识源间通信
- 在现代框架中,可通过状态管理库(如LangGraph)构建黑板驱动的智能体系统
黑板架构最早于1970年代由DARPA资助的Hearsay-II语音识别项目提出,并于1990年经全国科学技术名词审定委员会正式收录为自动化科学技术术语。
现代主流架构模式
随着云计算、微服务、AI等技术发展,以下模式成为当前主流:
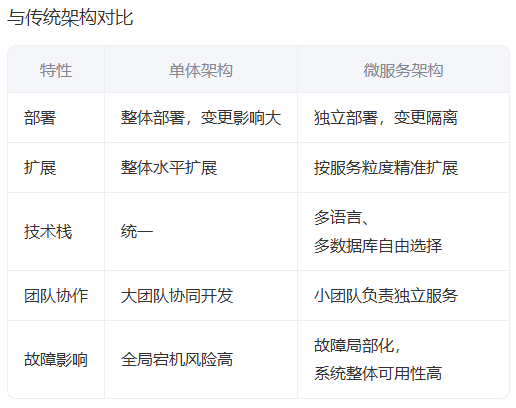
1、微服务架构(Microservices)
微服务架构(Microservices Architecture)是一种将单一应用程序拆分为多个小型、独立、松耦合服务的软件架构风格。每个服务围绕特定业务能力构建,可独立开发、部署、扩展,并使用轻量级通信协议(如 HTTP/REST、gRPC 或消息队列)进行交互。
将应用拆分为多个独立部署、松耦合的服务,每个服务可独立开发、扩展和维护。适用于高并发、高可用的大型系统(如电商平台、金融系统)。
核心特征
- 服务拆分:按业务领域(如用户管理、支付、订单)划分为独立服务,每个服务聚焦单一职责。
- 独立部署与扩展:各服务可单独发布、更新和伸缩,无需重新部署整个应用。
- 技术异构性:不同服务可采用不同编程语言、数据库或技术栈(如 Java、Go、MySQL、MongoDB)。
- 去中心化治理:服务拥有独立代码库和数据存储,避免共享数据库;团队可自主选择技术方案。
- 轻量级通信:服务间通过标准 API(如 REST、gRPC)通信,强调"智能端点、哑管道"(Smart Endpoints, Dumb Pipes)。
- 容错与弹性:通过熔断、限流、重试等机制实现故障隔离,提升系统韧性。
- 自动化运维:与 DevOps、CI/CD、容器(如 Docker)和编排工具(如 Kubernetes)深度集成。
2、事件驱动架构(Event-Driven Architecture, EDA)
事件驱动架构(Event-Driven Architecture, EDA)是一种以事件为核心进行系统组件间通信和协作的软件设计模式。其核心思想是:系统中的组件通过产生、发布、订阅和消费事件来触发行为,而非通过直接调用或同步请求响应。
组件通过异步事件通信,实现高扩展性与弹性,适用于秒杀、实时监控、日志处理等场景 。
核心特点
- 松耦合:事件生产者与消费者无需知道彼此的存在,仅通过事件通道交互。
- 异步通信:事件处理不阻塞生产者,提升系统响应速度与吞吐量。
- 高可扩展性:可动态添加新的事件消费者,支持水平扩展。
- 实时响应:事件发生后立即触发处理,适用于对延迟敏感的场景。
- 分布式处理:支持跨服务、跨地域的事件分发与处理。
核心组件
- 事件(Event):表示系统中发生的重要状态变化或动作(如"订单创建""支付成功")。
- 事件生产者(Producer):生成并发布事件的组件(如微服务、传感器、UI 控件)。
- 事件通道(Channel):传输事件的中间件(如 Kafka、RabbitMQ、阿里云 EventBridge)。
- 事件消费者(Consumer):订阅并处理特定事件的组件。
- 事件处理器(Handler):执行具体业务逻辑的代码单元。
典型应用场景
- 微服务架构:服务间通过事件解耦,如订单服务发布事件,库存、物流、积分服务分别订阅处理。
- 实时数据处理:如金融交易监控、物联网设备状态上报、点击流分析。
- 自动化运维:云监控告警自动触发修复脚本或通知。
- 电商系统:用户下单后触发支付、库存扣减、优惠券核销、物流调度等多流程并行。
- SaaS 集成:如 Salesforce 客户信息变更自动同步至内部 CRM。
常见实现技术
- 消息队列/事件总线:Kafka、RabbitMQ、Apache Pulsar、阿里云 EventBridge、腾讯云事件总线。
- 设计模式:发布-订阅(Pub/Sub)、观察者模式。
- 框架支持:Node.js(EventEmitter)、.NET(IAsyncEnumerable)、Java(Spring Event)、Python(Twisted)。
3、云原生架构(Cloud-Native)
云原生架构(Cloud-Native Architecture) 是一种专为充分利用云计算环境特性而设计的应用架构方法,强调从应用设计之初就"生于云、长于云",而非简单地将传统应用迁移到云上。
基于容器(如Docker)、Kubernetes、服务网格等技术构建,强调弹性、可观测性与自动化运维,是当前数字化转型的核心方向。
根据 云原生计算基金会(CNCF) 的权威定义,云原生技术使组织能够在公有云、私有云或混合云等动态环境中,构建和运行可扩展、高弹性的应用。其核心特征包括:
- 容器化:应用及其依赖被打包成标准化容器(如使用 Docker),确保环境一致性。
- 微服务架构:应用拆分为一组松耦合、独立部署的小型服务,每个服务聚焦单一业务能力。
- 服务网格(Service Mesh):通过 sidecar 代理(如 Istio + Envoy)实现去中心化的服务治理(如熔断、限流、监控)。
- 不可变基础设施:服务器或运行环境一旦部署即不再修改,故障时直接替换而非修复。
- 声明式 API:通过 YAML/JSON 等配置文件声明期望状态,系统自动维持该状态(如 Kubernetes)。
- DevOps 与 CI/CD:自动化开发、测试、部署流程,支持高频、可靠发布。
云原生 ≠ 上云,传统应用部署在云服务器上不等于云原生;只有当应用按云原生原则设计和构建,才能真正释放云的弹性、敏捷与韧性优势 。
核心目标
- 加速软件交付周期
- 提升系统可观测性、可维护性与容错性
- 实现资源高效利用与成本优化
- 支持跨云平台(公有/私有/混合)的可移植性
典型技术栈
- 容器编排:Kubernetes
- 微服务框架:Spring Cloud、Dubbo
- 服务网格:Istio、Linkerd
- CI/CD 工具:Jenkins、GitLab CI、ArgoCD
- 监控与日志:Prometheus + Grafana、ELK Stack、Datadog
- Serverless:AWS Lambda、阿里云函数计算(Serverless(无服务器) 是一种云计算执行模型,其核心思想是开发者无需管理底层服务器基础设施,而是通过云平台动态分配计算资源,并按实际使用量付费。这里的"无服务器"并非指没有服务器,而是服务器的运维、配置、扩容等细节被云厂商完全抽象和接管,开发者只需专注于业务逻辑代码的编写。)
Serverless = FaaS + BaaS
FaaS(Function as a Service,函数即服务)
开发者将业务逻辑拆分为独立函数(如 Node.js、Python 函数),上传至云平台,由事件触发执行。典型产品包括:
- AWS Lambda
- 阿里云函数计算(Function Compute)
- 腾讯云云函数(SCF)
BaaS(Backend as a Service,后端即服务)
提供预构建的后端能力,如数据库、身份认证、文件存储等,通过 API 调用。典型示例:
- Firebase(Google)
- AWS Amplify
- 阿里云 OSS + Cognito 替代方案
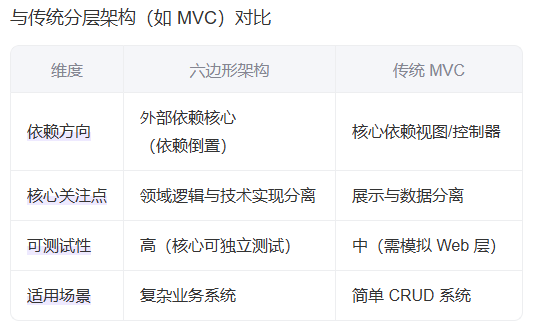
4、六边形架构(Hexagonal / Ports & Adapters)
六边形架构(Hexagonal Architecture),也称为端口与适配器架构(Ports and Adapters Architecture),是一种面向对象的软件架构设计模式,旨在提升系统的可测试性、可维护性和可扩展性。
该架构由 Alistair Cockburn 于 2005 年提出,其核心思想是将应用程序的核心业务逻辑与外部依赖(如数据库、UI、第三方服务等)完全解耦,使核心逻辑不依赖任何具体技术实现。
将业务逻辑置于中心,通过端口与适配器隔离外部依赖(如数据库、UI),提升可测试性与技术无关性 。
核心组成
- 应用程序核心(Domain / Application Core)
- 包含业务逻辑和领域模型
- 不依赖任何外部组件(如数据库、Web 框架等)
- 是整个架构的中心,负责处理所有核心业务规则
- 端口(Ports)
- 定义了应用程序与外部系统交互的接口
- 分为两类:
- 输入端口(Inbound Port / Driving Port):供外部调用核心功能(如 REST API、CLI、消息队列消费者)
- 输出端口(Outbound Port / Driven Port):供核心调用外部资源(如数据库访问、发送通知、调用第三方 API)
- 适配器(Adapters)
- 实现端口接口,桥接核心与外部系统
- 分为两类:
- 输入适配器(Driving Adapter):如 Spring Controller、gRPC 服务,将外部请求转换为对输入端口的调用
- 输出适配器(Driven Adapter):如 JPA Repository、RabbitMQ 生产者,将核心的输出请求适配为具体技术实现
架构特点
- 高内聚、低耦合:核心业务逻辑独立,修改外部技术不影响核心
- 强可测试性:核心可完全 Mock 外部依赖,进行单元测试
- 灵活扩展:新增接口(如 GraphQL、消息队列)只需添加新适配器,无需改动核心
- 依赖倒置:外部依赖核心(通过实现端口),而非核心依赖外部
典型应用场景
- 复杂业务系统:如金融交易、电商订单处理
- 多接口暴露需求:同时支持 Web、CLI、消息队列等
- 长期维护项目:需应对技术栈变更(如换数据库、迁云)
- 微服务架构:每个服务可独立采用六边形结构,提升自治性
⚠️ 不推荐用于:简单 CRUD 应用(如管理后台,CRUD 应用是指基于 Create(创建)、Read(读取)、Update(更新)和 Delete(删除) 四种基本数据库操作构建的软件应用程序。这类应用的核心目的是对数据进行增删改查,广泛用于管理各类业务信息,如客户资料、产品库存、员工记录等。)或短生命周期项目,可能造成过度设计。
5、CQRS模式(Command Query Responsibility Segregation)
CQRS(Command Query Responsibility Segregation,命令查询职责分离) 是一种软件架构模式,其核心思想是将对数据的读操作(查询) 和 写操作(命令) 分离到不同的模型中,分别处理,以提升系统的性能、可扩展性、安全性和可维护性。
读写操作分离,分别优化不同路径,适用于高并发读写场景(如电商商品浏览 vs 下单)。
核心概念-
- 命令(Command):代表对系统状态的修改请求(如创建、更新、删除),应具有业务意图,而非底层数据操作。
- 查询(Query):仅用于读取数据,不得修改系统状态,通常返回优化后的数据传输对象(DTO)。
- 写模型(Write Model):负责处理命令,包含业务逻辑、验证规则,优化事务一致性。
- 读模型(Read Model):负责处理查询,针对查询性能优化,可使用物化视图、缓存等技术。
主要特点
- 职责分离:读写逻辑解耦,各自独立演化。
- 独立优化:
- 写模型可面向事务与一致性;
- 读模型可面向查询效率与展示需求。
- 支持异步与最终一致性:在读写模型分离时,常通过事件驱动(如 Kafka、Axon)实现异步同步,读数据可能有短暂延迟。
- 可扩展性强:读写端可独立水平扩展,适应高并发场景。
典型应用场景
- 高读写负载不均衡的系统(如电商商品详情页读远多于库存更新)
- 复杂业务领域,需结合领域驱动设计(DDD) 与事件溯源(Event Sourcing)。
- 微服务架构中,需明确边界与自治性。
- 需要审计追踪、历史回溯或实时监控的系统(如设备状态管理、订单处理)。
实现方式(按复杂度)
- 单数据库,分离模型:共用同一数据源,但逻辑上区分读写模型。
- 多数据库,物理分离:
- 写端用关系型数据库(如 MySQL);
- 读端用文档数据库(如 MongoDB)或缓存(如 Redis);
- 通过领域事件保持同步 。
6、边缘计算架构(Edge Computing)
将计算推向数据源(如IoT设备、本地服务器),降低延迟,适用于自动驾驶、工业物联网等实时性要求高的场景 。
7、多智能体系统架构(Multi-Agent Systems, MAS)
多智能体系统架构(Multi-Agent Systems, MAS)是一种由多个具备自主决策能力的智能体(Agent)组成的分布式计算系统,通过交互与协作共同完成单一智能体难以处理的复杂任务 。
在AI与大模型背景下兴起,包括并行、顺序、循环、路由、聚合、网络、层级等七种智能体协作模式,适用于复杂决策与自动化流程。
核心特征
- 自主性:每个智能体可独立感知环境、制定目标并执行行动 。
- 分布性:任务和决策分散在多个智能体中,无全局中央控制(或仅部分集中)。
- 协调性:智能体通过通信、协商或竞争实现协同 。
- 容错性与可扩展性:单个智能体故障不影响整体系统,支持动态增减智能体 。
典型架构模式
- 集中式架构
- 存在中央协调器(如主智能体),统一调度全局任务。
- 优点:控制简单,适合小规模系统。
- 缺点:单点故障风险高 。
- 适用场景:无人机编队、小型机器人集群 。
- 分布式架构
- 无中央节点,智能体通过局部交互达成共识。
- 优点:鲁棒性强,扩展性好。
- 缺点:协调成本高,易陷入局部最优 。
- 适用场景:自动驾驶车队、智能电网调度 。
- 混合式架构
- 结合集中与分布:部分任务由中央协调,其余由智能体自主决策
- 优点:平衡效率与鲁棒性 。
- 适用场景:智慧城市交通管理、工业产线协作 。
协作模式(按交互方式)
- 层级架构:管理智能体(Manager Agent)分解任务并分配给专业智能体(Worker Agent),如项目经理协调开发、测试、运维团队 。
- 对等架构:多个智能体平等协商,通过讨论达成共识,适用于辩论、头脑风暴等场景 。
- 市场架构:智能体作为服务提供者竞争任务,用户智能体根据能力和报价选择,模拟自由市场机制 。
通信机制
- 直接通信:通过消息队列、RPC 等点对点交换信息 。
- 黑板系统:共享全局数据结构,智能体读写信息 。
- 发布-订阅模式:如 MQTT 协议,智能体订阅感兴趣的主题 。
关键技术与算法
- 任务分配:合同网协议、市场机制、基于 Q 学习的分配 。
- 冲突消解:协商、博弈论(如纳什均衡)、动态事件触发预测控制
- 强化学习:多智能体强化学习(MARL),包括 VDN、QMIX、MADDPG 等算法 。
- 大语言模型(LLM)融合:提升自然语言理解、推理与通信能力,但引入幻觉风险