TensorFlow
工作流程:数据预处理,构建模型和训练模型,进行预测。
框架将数据输入称为张量的多维数组,并以两种不同方式执行。
- 构建一个计算图形来定义用于训练模型的数据流
- 使用Eager Execution,遵循命令编程原则并立即评估操作
架构:
- 前端:提供编程模型,负责构造计算图,提供python,C++,java,go等
- 后端:提供运行时环境,负责执行计算图,采用c++实现
编程模式:
- 符号式编程:将计算过程抽象为计算图
- 命令式编程
基本概念:
- 使用图表示计算流程:
- 在会话中执行图:图的构建和图的执行
- 图的构建
- 创建源OP(source op)
- 图的执行
- 需要创建Session对象,如果不提供参数,Session构造器将运行默认图。
- 图的构建
- 使用张量表示数据:TensorFlow提供了创建张量函数的方法,以及导数的自动计算。
- 使用变量维护状态:存储和更新参数。tf.Variable(0,name="counter")
- 使用feed和fetch为任意的操作赋值或从中获取数据
- Feed机制实现从外部导入数据。一般Feed总是与占位符placeholder一起使用。
- 要获取操作的输出,需要执行会话的run()函数,并且提供需要提取的OP
变量示例
# 创建一个变量,初始化为标量值 0。
state = tf.Variable(0, name="counter")
# 创建一个操作,将 state 的值加 1。
one = tf.constant(1) # 创建一个常量 1
new_value = tf.add(state, one) # 计算 state + 1
update = tf.assign(state, new_value) # 将新值赋给 state(即 state = state + 1)
# 变量必须在启动图后通过运行一个 'init' 操作来初始化。
# 我们首先需要将 'init' 操作添加到图中。
init_op = tf.initialize_all_variables() # 初始化所有变量(注意:这是 TF1.x 的旧写法,推荐使用 tf.global_variables_initializer())
# 启动图并运行操作。
with tf.Session() as sess:
# 运行 'init' 操作以初始化变量
sess.run(init_op)
# 打印 state 的初始值
print(sess.run(state)) # 输出: 0
# 运行更新操作并打印 state 的值(循环 3 次)
for _ in range(3):
sess.run(update) # 执行 state = state + 1
print(sess.run(state)) # 依次输出: 1, 2, 3图的构建示例
bash
# 导入TensorFlow库,简写为tf,这是使用TensorFlow的第一步
import tensorflow as tf
# ====================== 定义常量节点 ======================
# 创建一个常量操作(Constant op),输出一个 1行2列 的矩阵
# 这个操作会被作为节点添加到**默认计算图(Graph)**中
# 构造函数的返回值 matrix1 代表这个常量操作的输出结果
matrix1 = tf.constant([[3., 3.]])
# 创建另一个常量操作,输出一个 2行1列 的矩阵
matrix2 = tf.constant([[2.],[2.]])
# ====================== 定义矩阵乘法操作 ======================
# 创建一个矩阵乘法操作(Matmul op)
# 将上面定义的 matrix1 和 matrix2 作为这个乘法操作的输入
# 返回值 product 代表矩阵相乘的**计算结果**
product = tf.matmul(matrix1, matrix2)图的执行示例
bash
# 导入TensorFlow库
import tensorflow as tf
# ====================== 1. 构建计算图 ======================
# 创建1x2常量矩阵(节点)
matrix1 = tf.constant([[3., 3.]])
# 创建2x1常量矩阵(节点)
matrix2 = tf.constant([[2.],[2.]])
# 创建矩阵乘法操作(节点),输入为上面两个常量
product = tf.matmul(matrix1, matrix2)
# ====================== 2. 启动会话执行计算 ======================
# 启动默认的计算图(Graph)
# 创建一个TensorFlow会话(Session),会话负责执行图中的操作
sess = tf.Session()
# 调用会话的 run() 方法,执行矩阵乘法操作
# 传入 product,表示我们需要获取这个操作的输出结果
# 执行时,会话会自动运行该操作所需的**所有依赖节点**(两个常量 + 矩阵乘法)
# 这些节点通常会并行执行,提高效率
# run() 方法执行后,会把计算结果返回为 numpy 数组格式
result = sess.run(product)
# 打印计算结果
print(result)
# 输出结果:[[ 12.]]
# 计算完成后,关闭会话,释放资源
sess.close()实战1 手写MNIST字符识别
tensorflow实现
bash
# 导入TensorFlow深度学习框架
import tensorflow as tf
# 导入matplotlib绘图库,用于图像展示和结果绘图
from matplotlib import pyplot as plt
"""
功能:MNIST手写数字识别,使用卷积神经网络CNN
对应原PyTorch代码,结构、逻辑、输出完全一致
1. 输出训练过程中的loss和acc
2. 使用Sequential搭建模型
3. 训练+测试+绘图可视化
"""
# ====================== 超参数定义 ======================
# 每批次训练的样本数量
batch_size = 64
# 优化器学习率,控制参数更新步长
learning_rate = 0.01
# 动量参数,加速SGD收敛
momentum = 0.5
# 训练总轮数(整个数据集迭代10次)
EPOCH = 10
# ====================== 加载MNIST数据集 ======================
# 加载官方MNIST数据集,自动分为训练集和测试集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 将图像像素值从0-255归一化到0-1之间,提升训练稳定性
x_train = x_train / 255.0
x_test = x_test / 255.0
# 增加通道维度,从 (batch,28,28) → (batch,28,28,1),适配卷积层输入
x_train = tf.expand_dims(x_train, axis=-1)
x_test = tf.expand_dims(x_test, axis=-1)
# 将标签转换为独热编码,适配交叉熵损失函数
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
# 构建训练集管道:打乱数据 + 按批次读取
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(60000).batch(batch_size)
# 构建测试集管道:只分批,不打乱
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_dataset = test_dataset.batch(batch_size)
# ====================== 可视化12张训练集样本 ======================
# 创建画布
plt.figure()
# 循环绘制12张图
for i in range(12):
# 3行4列的子图
plt.subplot(3, 4, i+1)
# 自动调整子图间距
plt.tight_layout()
# 显示灰度图像,去掉通道维度
plt.imshow(tf.squeeze(x_train[i]), cmap='gray')
# 显示图像对应的真实标签
plt.title(f"Label: {tf.argmax(y_train[i])}")
# 隐藏x轴刻度
plt.xticks([])
# 隐藏y轴刻度
plt.yticks([])
# 显示图像窗口
plt.show()
# ====================== 搭建CNN模型(和PyTorch结构完全一致) ======================
# 使用Sequential顺序模型搭建网络
model = tf.keras.Sequential([
# 第一层卷积:输入通道1,输出通道10,卷积核5×5,激活函数ReLU
tf.keras.layers.Conv2D(10, kernel_size=5, activation='relu', input_shape=(28,28,1)),
# 第一层池化:2×2最大池化
tf.keras.layers.MaxPool2D(pool_size=2),
# 第二层卷积:输入通道10,输出通道20,卷积核5×5,激活函数ReLU
tf.keras.layers.Conv2D(20, kernel_size=5, activation='relu'),
# 第二层池化:2×2最大池化
tf.keras.layers.MaxPool2D(pool_size=2),
# 展平层:将特征图展平为一维向量
tf.keras.layers.Flatten(),
# 全连接层1:320 → 50
tf.keras.layers.Dense(50, activation='relu'),
# 全连接层2(输出层):50 → 10,softmax输出概率
tf.keras.layers.Dense(10, activation='softmax')
])
# 打印模型结构信息
model.summary()
# ====================== 损失函数与优化器 ======================
# 定义优化器:带动量的SGD随机梯度下降
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum)
# 定义损失函数:多分类交叉熵损失
loss_fn = tf.keras.losses.CategoricalCrossentropy()
# 定义训练指标:损失均值
train_loss = tf.keras.metrics.Mean()
# 定义训练指标:分类准确率
train_acc = tf.keras.metrics.CategoricalAccuracy()
# ====================== 单轮训练函数 ======================
def train_epoch(epoch):
# 记录当前训练步数
step = 0
# 遍历每一批训练数据
for x_batch, y_batch in train_dataset:
# 梯度带:记录前向传播过程,用于自动求导
with tf.GradientTape() as tape:
# 前向传播,计算模型预测值
y_pred = model(x_batch, training=True)
# 计算当前批次损失
loss = loss_fn(y_batch, y_pred)
# 计算损失对模型参数的梯度
grads = tape.gradient(loss, model.trainable_variables)
# 用优化器更新参数
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 累计当前损失
train_loss(loss)
# 累计当前准确率
train_acc(y_batch, y_pred)
# 步数+1
step += 1
# 每300个batch打印一次loss和acc(和原PyTorch一致)
if step % 300 == 0:
print(f"[{epoch+1}, {step:5d}] loss: {train_loss.result():.3f}, acc: {train_acc.result()*100:.2f} %")
# 一轮结束后重置指标
train_loss.reset_states()
train_acc.reset_states()
# 定义测试集准确率指标
test_acc = tf.keras.metrics.CategoricalAccuracy()
# ====================== 测试函数 ======================
def test_epoch():
# 遍历测试集
for x_batch, y_batch in test_dataset:
# 模型预测,不启用训练模式
y_pred = model(x_batch, training=False)
# 累计准确率
test_acc(y_batch, y_pred)
# 获得最终准确率
acc = test_acc.result()
# 重置测试指标
test_acc.reset_states()
# 打印测试结果
print(f"[{epoch+1}/{EPOCH}] Test Accuracy: {acc*100:.1f} %")
# 返回当前测试准确率
return acc.numpy()
# ====================== 主程序:开始训练和测试 ======================
if __name__ == '__main__':
# 用于保存每轮测试准确率,方便绘图
acc_list = []
# 按轮次循环训练
for epoch in range(EPOCH):
# 训练一轮
train_epoch(epoch)
# 测试一轮
acc = test_epoch()
# 保存本轮准确率
acc_list.append(acc)
# 绘制测试集准确率变化曲线
plt.plot(acc_list)
# x轴标签:训练轮数
plt.xlabel("Epoch")
# y轴标签:测试集准确率
plt.ylabel("Test Accuracy")
# 显示图像
plt.show()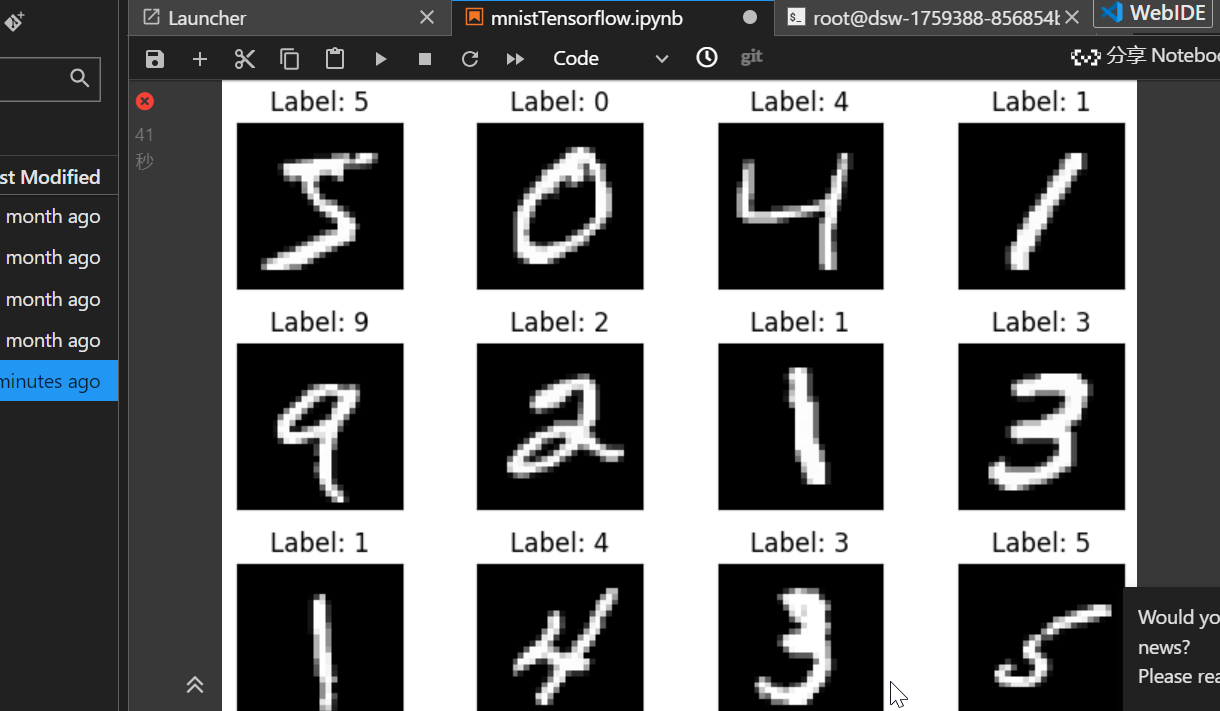
pytorch实现
bash
# 导入PyTorch深度学习框架核心库
import torch
# 导入数值计算库,用于数据处理
import numpy as np
# 导入matplotlib绘图库,用于可视化数据和结果
from matplotlib import pyplot as plt
# 导入数据加载器工具类,用于批量加载数据
from torch.utils.data import DataLoader
# 导入图像预处理工具
from torchvision import transforms
# 导入内置数据集(这里使用MNIST手写数字数据集)
from torchvision import datasets
# 导入PyTorch激活函数、损失函数等工具
import torch.nn.functional as F
"""
代码功能说明:
基于卷积神经网络(CNN)实现MNIST手写数字识别
与之前版本区别:
1. 训练过程中输出每轮的准确率(acc)
2. 使用torch.nn.Sequential简化模型搭建
"""
# ====================== 1. 定义超参数 ======================
# 批次大小:每次训练输入64张图片
batch_size = 64
# 学习率:控制参数更新的步长
learning_rate = 0.01
# 动量:加速梯度下降收敛
momentum = 0.5
# 训练总轮数:整个数据集训练10遍
EPOCH = 10
# ====================== 2. 数据预处理与加载 ======================
# 定义图像预处理流程:转为张量 + 归一化
transform = transforms.Compose([
transforms.ToTensor(), # 将PIL图像转为PyTorch张量(0~1)
transforms.Normalize((0.1307,), (0.3081,)) # 归一化:均值0.1307,标准差0.3081(MNIST数据集固定值)
])
# 加载训练集:本地路径、训练集、应用预处理、无数据自动下载
train_dataset = datasets.MNIST(root='./data/mnist', train=True, transform=transform, download=True)
# 加载测试集
test_dataset = datasets.MNIST(root='./data/mnist', train=False, transform=transform, download=True)
# 训练数据加载器:打乱顺序、批量读取
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 测试数据加载器:不打乱顺序
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# ====================== 3. 可视化部分训练样本 ======================
fig = plt.figure() # 创建画布
# 循环显示12张训练集图片
for i in range(12):
plt.subplot(3, 4, i+1) # 3行4列子图
plt.tight_layout() # 自动调整子图间距
plt.imshow(train_dataset.train_data[i], cmap='gray', interpolation='none') # 灰度显示图片
plt.title("Labels: {}".format(train_dataset.train_labels[i])) # 显示对应标签
plt.xticks([]) # 隐藏x轴刻度
plt.yticks([]) # 隐藏y轴刻度
plt.show() # 显示图片窗口
# ====================== 4. 搭建卷积神经网络模型 ======================
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 第一个卷积块:卷积+激活+池化
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 10, kernel_size=5), # 输入通道1,输出通道10,卷积核5x5
torch.nn.ReLU(), # ReLU激活函数
torch.nn.MaxPool2d(kernel_size=2), # 最大池化,核2x2
)
# 第二个卷积块
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(10, 20, kernel_size=5), # 输入10通道,输出20通道
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
)
# 全连接层:分类输出
self.fc = torch.nn.Sequential(
torch.nn.Linear(320, 50), # 输入320维,输出50维
torch.nn.Linear(50, 10), # 输出10维(对应0~9十个数字)
)
# 前向传播(数据流动逻辑)
def forward(self, x):
batch_size = x.size(0) # 获取批次大小
x = self.conv1(x) # 经过第一个卷积块
x = self.conv2(x) # 经过第二个卷积块
x = x.view(batch_size, -1) # 展平为一维:(batch, 20,4,4) → (batch,320)
x = self.fc(x) # 经过全连接层输出结果
return x # 输出10分类结果
# 创建模型实例
model = Net()
# ====================== 5. 定义损失函数与优化器 ======================
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失(多分类任务专用)
# 随机梯度下降(SGD)优化器:传入模型参数、学习率、动量
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum)
# ====================== 6. 定义训练函数 ======================
def train(epoch):
running_loss = 0.0 # 累计损失值清零
running_total = 0 # 累计样本总数
running_correct = 0 # 累计预测正确数
# 遍历训练集,按批次读取数据
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data # 拆分输入图像和标签
optimizer.zero_grad() # 梯度清零(避免累积)
# 前向传播:计算预测结果
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, target)
# 反向传播:计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 统计当前批次的损失
running_loss += loss.item()
# 获取预测类别(取输出最大值的下标)
_, predicted = torch.max(outputs.data, dim=1)
# 累计总样本数
running_total += inputs.shape[0]
# 累计正确预测数
running_correct += (predicted == target).sum().item()
# 每300个批次打印一次:轮数、批次、平均损失、准确率
if batch_idx % 300 == 299:
print('[%d, %5d]: loss: %.3f , acc: %.2f %%'
% (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total))
# 清零,准备下一组300批次统计
running_loss = 0.0
running_total = 0
running_correct = 0
# ====================== 7. 定义测试函数 ======================
def test():
correct = 0 # 正确数
total = 0 # 总数
# 测试时不计算梯度,节省内存
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
# 获取预测结果
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算测试集准确率
acc = correct / total
print('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc))
return acc
# ====================== 8. 启动训练与测试 ======================
if __name__ == '__main__':
acc_list_test = [] # 保存每轮测试准确率
# 循环训练EPOCH轮
for epoch in range(EPOCH):
train(epoch) # 训练一轮
acc_test = test() # 测试一轮
acc_list_test.append(acc_test) # 保存准确率
# 绘制测试准确率变化曲线
plt.plot(acc_list_test)
plt.xlabel('Epoch') # x轴:训练轮数
plt.ylabel('Accuracy On TestSet') # y轴:测试集准确率
plt.show()