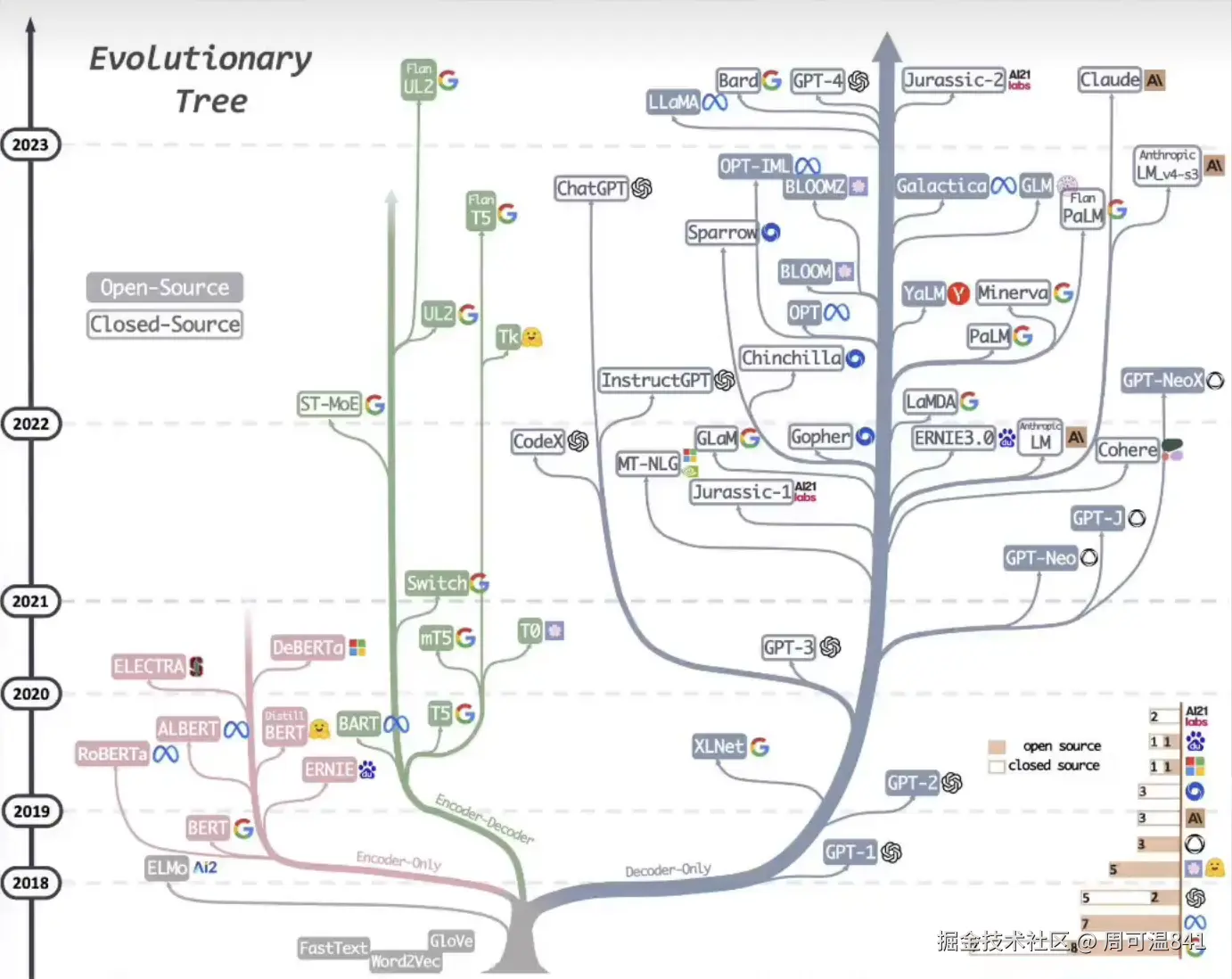
完整代码与训练流程:github.com/ahuang0324/...
参考资料:【从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN)】www.bilibili.com/video/BV1XH...
【【官方双语】GPT是什么?直观解释Transformer | 深度学习第5章】www.bilibili.com/video/BV13z...
Transformer 是一种以 注意力机制(Attention) 为核心的序列建模架构,它用"序列中任意位置之间的可学习加权聚合"来替代 RNN 的递归,从而实现更强的并行性与长程依赖建模能力。
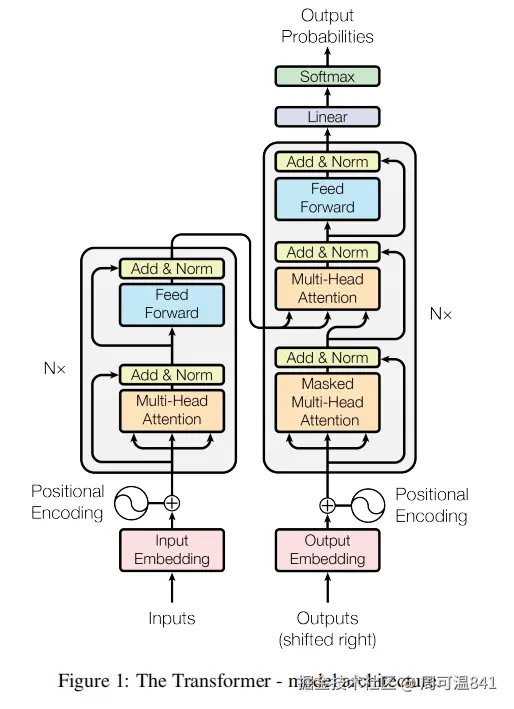
注意力机制
为了解决什么问题?
理解特定情境下,某个词的语义信息,和整个句子的语义信息。
在进入注意力模块之前,我们通过 Embedding 层把字变成了向量。但那时候的向量是 "静态的"、"孤立的" 。比如"打"这个字,不管是在"打篮球"、"打酱油"还是"打车"里,它的初始 Embedding 都是一模一样的。
经过 Attention 之后,这个输出的特征向量已经不再是单纯的"打"字了,而是 "包含了打篮球这个真实语境的复合语义向量"。这就叫上下文感知(Contextualized) 。
核心结构:
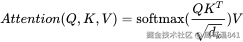
特定语义空间-V矩阵 和 注意力得分
我们从词向量(embedding)的起点出发,已经能够捕捉到词语本身的基础含义。然而,语言的魅力在于其多变性,同一个词语在不同的语境下可能呈现出截然不同的意思。例如,"bank"既可以指金融机构,也可以指河岸。仅仅依赖静态的词向量,我们无法区分这种细微但至关重要的语义差异。这就催生了一个核心问题:如何让模型理解并区分词语在不同语境下的含义,从而构建一个更丰富、更精确的语义空间?
所以我们考虑一个单词是适合需要加入上下文。传统的RNN 是顺序的考虑上下文:这就造成了两个问题,容易遗忘,且计算效率低。 通过人类阅读适合的注意力,我们能发现这不是一个顺序过程,而且我们在阅读时候,能自动忽略不重要的东西,抓住关键词语我们就能明白整个句子的意思。
(这里有个特别合适的比喻是,RNN类似于顺序的传话,Transformer类似于圆桌会议,每个人同时发表意见)
好了现在我们有了目标: 我们要将对不同场景的词语进行区分,拓展语义空间,找到每个词在不同语境下的向量 (找到一个新的向量空间,这个空间不但存储词的意思,而且区分同一个词语在不同语境下的意思)
即目标: 词向量 + 上下文 -> 新的带语境信息的词向量(语境化向量) 我们要求中间的过程(f函数)
然后再拆分目标,我们总不能把整个上下文都利用吧?开销太大,且不合理,我们需要找到重要的词,忽略不重要的词, 这种"抓住重点、忽略无关"的能力,正是我们所追求的"注意力"的体现。那如何判断哪个词是重要的,哪个词不重要呢?为此,我们进行量化,给每个词对f的贡献起个名,就是后来的 ****注意力得分。还有个词是关联程度计算 我觉得差不多个意思。
然后有了提取出来重要的关键词, 我们还需要转化成 语义向量 这个就是V矩阵。
注意力得分: Q K 矩阵
设计两个变换,一个是对当前词的变换Q ,一个是对其他词的变换K,然后通过dot来计算匹配程度。 原理就是,每个词可能有它固定在意的词语的类型(或者需要提取一个特征,就是当前词对哪种词语敏感,对哪信息敏感,也就相当于是发出一次查询Q,也就是我需要注意的词的特征) 那同时我们还要提起每个词的特征,也就是这个词是什么样的,也就是Key 来与Q匹配。
这个命名和操作的灵感,直接来源于计算机科学中一个非常经典的领域:信息检索(Information Retrieval)与数据库系统。
总结:每个单词准备三张名片
- Q (Query - 查询): 代表当前词语 "我想了解什么?" 它的本质是当前词语发出的一个"查询请求",它携带了当前词语对上下文的"兴趣点"或"关注方向"。
- K (Key - 键): 代表每个上下文词语 "我有什么特点?" 它是上下文词语自身的一种"特征表示",用于与 Q 进行匹配。
- V (Value - 值): 代表每个上下文词语 "我的具体信息是什么?" 它是上下文词语本身携带的"信息内容",在计算出权重后,将被加权求和。
注意:QKV的含义 仅仅是人类对于其含义的形象化理解。
假设句子:"猫喜欢吃鱼,它很聪明"
以"它"这个词为例:
- "它"提出Query:"我指代谁?" 从"ta" 到"我指代谁" 这个是学习出来的 Q
- 所有词出示Key:"我是名词/动词/代词..." 中间的过程也是学习出来的。
- 计算匹配度:Qᵢ·Kⱼ (点积相似度)
- 得到注意力权重:"猫", "喜欢", "吃", "鱼", "它", "很", "聪明"
0.7, 0.05, 0.05, 0.1, 0.02, 0.03, 0.05
- 加权求和:0.7×"猫"的信息 + 0.05×"喜欢"的信息 + ... (注意这里,是我们后来将位置编码的基础)
整个网络的精髓应该是 注意力(如何计算每个数的贡献,也就是注意力得分)
这三个卡片就是 W_Q W_K W_V 矩阵,这里也蕴含着我理解的一个整个神经网络的设计原则。我们设定好功能以及结构,通过梯度下降和反向传播,就能让这个部件具备我们想要的功能。
最后呈现的结构就是 一个矩阵变换,记录了转换规则。(从矩阵的几何意义上来说,矩阵就是空间变换的规则)
如Embedding,并不是记录一个个转换后的向量,而是w_in 记录了这个转换过程。
scaling
为什么一定要加上这个  的"缩放(Scale)"操作?
的"缩放(Scale)"操作?
- 统计学危机:维度越大,点积越"爆炸" 矩阵相乘本质是加权求和,方差会放大。
- Softmax 的坏脾气:极度敏感与"赢者通吃" 降低所有数据的大小。 在这个温和的区间里,Softmax 的梯度非常健康
多头注意力机制
这个可以用CNN 中的多通道来类比。 CNN设置不同的通道,每个通道独立一个卷积核,然后每个卷积核单独扫描全部数据,提取不同的特征。 (所以 注意力头-> 卷积核)
但是跟CNN 也还是有区别的:
- CNN 的逻辑:全盘接收,多角度扫描
-
- 在 CNN 中,假设输入图像的特征图是
[Batch, 512, Height, Width](有 512 个通道)。 如果你设定了 8 个卷积核(Filters),每一个卷积核在扫过画面时,它的深度必须也是 512。
- 在 CNN 中,假设输入图像的特征图是
- Transformer 的逻辑:物理隔离,强行分工 将一个大的向量空间 拆成等多个小的向量空间
在 Transformer 中,输入的词特征是 [Batch, SeqLen, 512]。
按照 CNN 的逻辑,8 个头应该每个头都去拿完整的 512 维去算  对吧?
对吧?
但 Transformer 偏不! 它是把 512 强行切成了 8 份,每份只有 64 维。
- 物理意义: 头 1 只允许 看特征的第 0
63 维;头 2 只允许看第 64127 维。大家井水不犯河水。
为什么 Transformer 要这么"抠门"地拆分 Q 和 K?
- 精妙的算力恒定魔法 (Constant Compute)
- 强迫子空间正交化 (Forced Specialization)
把一个 512 维的大向量空间,强行切分成 8 个 64 维的小向量空间(子空间)。这就好比把一个笼统的"综合评分"体系,拆分成了"外貌"、"性格"、"学历"、"财力"等多个独立的评价维度。每个头(Head)只在自己的那个小维度空间里去计算距离(相似度),最后再把大家的结果拼回来。
Head 1 (专家1) 只拿前 64 维算点积: 它的注意力分数 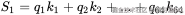
假设我们只有单头注意力(Single-Head Attention)。模型在计算一个词与其他词的关联时,只能聚焦于一种特定的关系。比如在"The animal didn't cross the street because it was too tired"这句话中,单头注意力可能把所有的权重都用来寻找"it"指代的是什么(animal)。
但这还不够。我们还需要理解"tired"是谁的状态,时态是什么,等等。
多头注意力就像是给模型分配了一个"专家委员会"。
- Head 1 专家专门负责分析语法结构(主谓宾关系)。
- Head 2 专家专门负责分析代词指代。
- Head 3 专家专门负责分析情感色彩。
每个"头"都有自己独立的权重矩阵(W_k,W_q,W_v),把输入映射到不同的子空间(Subspace)中进行学习。最后,模型把所有专家的意见汇总(Concat),从而获得对这句话极其丰富的多维度理解。
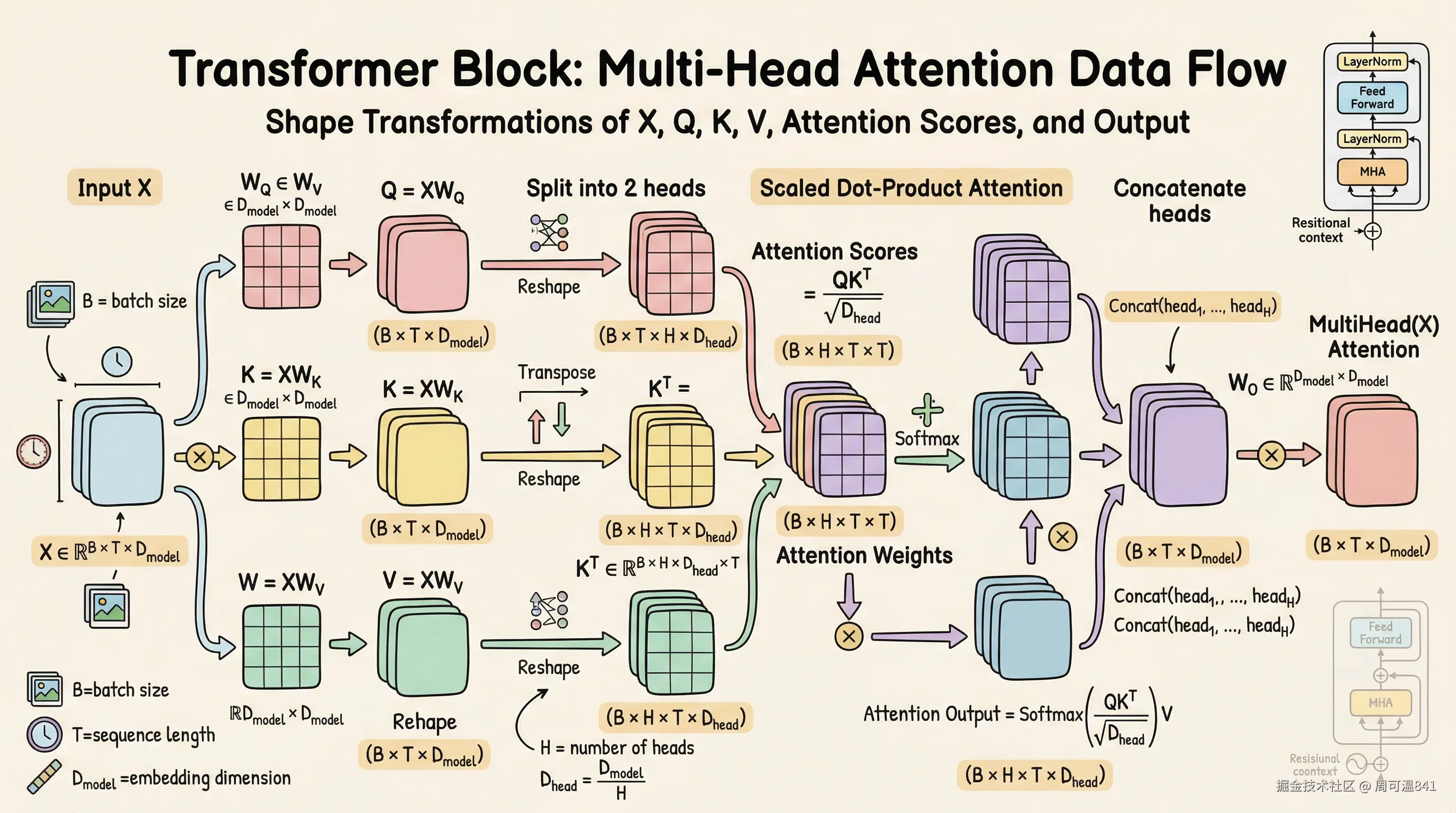
在真正的代码实现上,有一个小技巧。
不需要使用for循环去让每个注意力头跑一边,而是可以将每个注意力头的W_q 和W_k 拼成一个大矩阵:
生成一个QKV ,然后在进行拆分,做Attention计算。
总结一下代码里的完整数据流(以 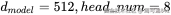 ,SeqLen是一个句子有多少个Token):
,SeqLen是一个句子有多少个Token):
- 输入
 :
: [Batch, SeqLen, 512] - 生成 : 用大矩阵映射,依然是
[Batch, SeqLen, 512] - 拆分维度 (view): 变成
[Batch, SeqLen, 8, 64]
-
- PyTorch 矩阵乘法的死规定 它永远只看张量的最后两个维度来做矩阵乘法。
- 交换维度 (transpose): 变成
[Batch, 8, SeqLen, 64](在这里做各头独立的 Attention 计算)
-
- QK dot -> Scaling -> 加入掩码 -> softmax
- 计算完 Attention: 形状还是
[Batch, 8, SeqLen, 64] - 换回维度 (transpose): 变成
[Batch, SeqLen, 8, 64] - 拼接维度 (view): 把最后的
8和64揉在一起,瞬间"变回"了[Batch, SeqLen, 512] - 输出投影 (
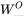 ): 经过
): 经过 nn.Linear(512, 512),最终安全输出[Batch, SeqLen, 512]
前馈神经网络(Feed-Forward Network, FFN)
Attention 的职责是"收集信息": 它决定了当前字应该看向哪里。
FFN 的职责是"理解和记忆": 它通常是一个把维度放大 4 倍再缩回来的两层线性网络结构(加上激活函数)。它拿着 Attention 收集来的信息进行深度的非线性思考,把模型在海量数据中背下来的"知识"注入进去。
输入  Attention (看上下文) FFN (思考与回忆) 最后的线性层 (语言建模层)(输出下一个字的概率)。
Attention (看上下文) FFN (思考与回忆) 最后的线性层 (语言建模层)(输出下一个字的概率)。
Embedding 和 位置编码
Embedding:它就是一个"查表"的超级大矩阵
在 PyTorch 中,我们会使用 nn.Embedding(vocab_size, d_model) 来实现这一层。
假设你的字典里有 3000 个汉字(vocab_size = 3000),你的模型维度是 d_model = 512。
那么 nn.Embedding 在底层其实就是随机初始化了一个形状为 [3000, 512] 的可学习权重矩阵。
当输入 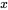 是一个包含了字 ID 的张量(比如"床"的 ID 是 12)时,Embedding 层根本不做任何复杂的矩阵运算 。它只是去那个
是一个包含了字 ID 的张量(比如"床"的 ID 是 12)时,Embedding 层根本不做任何复杂的矩阵运算 。它只是去那个 [3000, 512] 的矩阵里,把第 12 行的那 512 个浮点数直接 "抽" 出来,作为"床"的初始词向量。
所以,这 3000 行向量,就是模型在训练过程中要不断通过梯度下降来微调(Fine-tune)的参数。模型要自己学会在 512 维的坐标系里,把"猫"和"狗"的坐标拉近,把"猫"和"宇宙"的坐标推远。
- Word2Vec: 通常是"预训练"好的。你先用一个巨大的语料库跑一遍 Word2Vec 算法,得到一个固定的词典到向量的映射表,然后把它死死地固定住(Freeze) ,拿去给下游任务(比如情感分析)用。
- Transformer (Mini-GPT): 我们通常是从零开始(From Scratch)随机初始化这个矩阵,然后让它跟着后面的 Attention 层、预测层一起,为了"预测下一个字"这个终极目标进行端到端的联合训练。它完全是为当前任务量身定制的。
位置编码 (Positional Encoding) :
单纯的注意力计算来说 "狗咬人" 和"人咬狗" 最后对于"咬"这个字计算出来的语义信息是一致的。
原因就在于"加法交换律"
- 加权求和:0.7×"猫"的信息 + 0.05×"喜欢"的信息 + ... (注意这里,是我们后来将位置编码的基础)
最后的矩阵相乘 分解到每个向量 就是一个加权求和的过程。所以我们需要一个位置编码。
1. 最朴素也最实用的方案:可学习的绝对位置编码 (Learned Positional Embedding)
这是 GPT 系列(包括 GPT-1 到 GPT-3) 采用的方案。既然你打算手搓一个 Mini-GPT,我强烈建议你 首选这个方案。
核心逻辑:
既然词意可以通过一个巨大的矩阵(查表)学出来,那位置信息为什么不能也让模型自己学呢?
- 我们预设一个模型支持的最大序列长度,比如
max_seq_len = 1024。 - 我们直接初始化一个新的 Embedding 矩阵:
nn.Embedding(1024, d_model)。 - 第 0 个位置,就去查第 0 行的 512 维向量;第 1 个位置,就去查第 1 行的向量。
- 相加: 把查到的词向量和位置向量直接相加。
x = token_emb + pos_emb。
优点: 代码极其简单,符合深度学习"万物皆可学"的暴力美学。
缺点: 缺乏外推性(Extrapolation)。如果训练时句子最长只有 1024,推理时突然来了一个长度为 1025 的句子,模型就傻眼了,因为第 1025 个位置的编码它从来没学过。
2. 原版论文的浪漫:正余弦位置编码 (Sinusoidal Positional Encoding)
这是《Attention Is All You Need》原论文使用的经典方案。作者不想让模型死记硬背位置,而是想用一个确定性的数学公式,直接"算"出独一无二的位置向量。
数学公式:
对于位置 pos 的 512 维向量,它的每一个维度 i 的值,都是通过正弦或余弦函数算出来的:
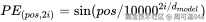
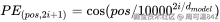
直觉理解:
想象一个由 512 个齿轮组成的机械钟表。
- 向量的第 0 维(低维):像钟表的秒针,频率极快,位置 0 和位置 1 的值变化非常剧烈。
- 向量的第 511 维(高维):像钟表的时针,频率极慢,可能走过几百个字,它的值才发生微小的改变。
这 512 个不同频率的波形组合在一起,就像是指纹一样,保证了绝对不可能有两个位置算出相同的向量。
为什么用三角函数?(精妙之处):
因为三角函数有一个神奇的数学性质: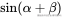 和
和  可以展开成
可以展开成 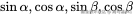 的线性组合。
的线性组合。
这意味着,位置  的编码,可以通过位置
的编码,可以通过位置  的编码进行线性变换 得到。这就让模型非常容易学到词与词之间的相对距离(Relative Distance) 。
的编码进行线性变换 得到。这就让模型非常容易学到词与词之间的相对距离(Relative Distance) 。
3. 现代大模型的霸主:旋转位置编码 (RoPE - Rotary Position Embedding)
在目前最前沿的开源大模型(如 Llama、Qwen、GLM)以及你的联邦微调研究中,经常会遇到各种参数高效的方法,而在底层架构上,它们几乎全部抛弃了前两种,采用了 RoPE。
前两种方案,都是在网络的最开头,把位置编码加到词向量里。
而 RoPE 的思维极其跳跃:它不在 Embedding 层加,而是在每次计算 Attention 之前,直接作用于 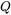 和
和  矩阵!
矩阵!
核心逻辑:
它把 和 的向量两两分组,看作复数平面上的向量。
如果一个词在第  个位置,RoPE 就会把它的 向量在复平面上旋转
个位置,RoPE 就会把它的 向量在复平面上旋转 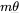 的角度。
的角度。
当 和 在计算内积(点积相似度)时,由于它们都发生了旋转,内积的结果只与它们的相对角度差(也就是相对位置差距  )有关,而与它们的绝对位置无关!
)有关,而与它们的绝对位置无关!
这种方案完美融合了绝对位置的计算效率和相对位置的泛化能力,是目前大模型能够支持超长上下文(Context Window)的核心技术之一。
Mini-GPT 训练过程
在 Decoder-only 的大语言模型(Mini-GPT)中,训练过程的核心被称为自回归(Autoregressive)的"下一个词预测(Next-Token Prediction)" 。
0. 和 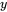 的形式:错位时空
的形式:错位时空
假设我们正在用唐诗训练你的模型,我们的词表(Vocabulary)里有很多中文字符,每个字符都有一个唯一的整数 ID。
假设我们的上下文窗口大小(block_size 或 seq_len)设置为 4。
我们当前要训练的一句诗是:"床前明月光"。
在构建训练数据时, 和 是从同一段文本中截取出来的,仅仅相差一个字符的位移。
- 输入 (Input):
[床, 前, 明, 月] 对应 ID [12, 45, 9, 33] - 标签 (Target):
[前, 明, 月, 光] 对应 ID [45, 9, 33, 88]
它们的形状都是: [Batch, SeqLen](这里是 [Batch, 4])。
在 RNN 时代,计算"明"的概率,必须 等"前"的概率算完,因为信息是串行传递的。但在 Transformer 中,这四个字的预测是在 GPU 中同一瞬间、完全并发算出来的。
它是怎么做到的?核心秘诀就藏在 "矩阵乘法" 和 "下三角掩码(Causal Mask)" 的精妙配合中。
我们用你的"床前明月"作为例子,放慢动作,看看 GPU 在那一瞬间到底干了什么:
1. 算力全开:不管三七二十一,先全算出来 (Matrix Multiplication)
假设我们已经得到了 4 个字的 (查询)和 (键)矩阵。
此时,GPU 不会去管什么"先后顺序",它直接执行一次极其暴力的矩阵乘法: 。
。
这一步算出来的是一个 [4, 4] 的注意力原始分数矩阵(Scores Matrix)。
在这个矩阵里,每一个字都看到了所有的字(包括未来) :
- 第 1 行 (Q="床") 算出了它对 床, 前, 明, 月 的注意力分数。
- 第 2 行 (Q="前") 算出了它对 床, 前, 明, 月 的注意力分数。
- 第 3 行 (Q="明") 算出了它对 床, 前, 明, 月 的注意力分数。
- 第 4 行 (Q="月") 算出了它对 床, 前, 明, 月 的注意力分数。
注意: 此时,物理层面的计算已经全部并行完成了!这是 GPU 最擅长的事情。只是现在的数据是不合法的,因为"床"看到了未来的"前明月"。
2. 物理阉割:下三角掩码 (The Causal Mask)
计算虽然完成了,但为了防止作弊,我们需要在把这些分数送进 Softmax 变成概率之前,进行一次"物理阉割"。
我们会凭空生成一个同样是 [4, 4] 的掩码矩阵(Mask)。这个矩阵的左下角(包含对角线)全是 0,右上角全是负无穷( 或
或 -1e9)。
我们将这个 Mask 直接加到刚才算出的 Scores 矩阵上:

相加之后,神奇的事情发生了:

3. 化腐朽为神奇:Softmax 激活
现在,我们对这个带负无穷的矩阵的每一行做 Softmax 归一化(把分数变成总和为 1 的概率)。
数学上, 等于
等于 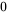 。
。
所以,经过 Softmax 后,注意力权重矩阵变成了这样:
- 第 1 行 ("床")的权重:
[1.0, 0, 0, 0](它被迫把 100% 的注意力放在"床"上,后面的未来全被抹零了)。 - 第 2 行 ("前")的权重:
[0.01, 0.99, 0, 0](它只能在"床"和"前"之间分配注意力)。 - 第 3 行 ("明")的权重:
[0.1, 0.2, 0.7, 0](它看到了前三个字)。 - 第 4 行 ("月")的权重:
[0.1, 0.2, 0.2, 0.5](它看到了全部四个字)。
4. 并行提取特征
最后,拿这个 [4, 4] 的权重矩阵去乘以 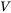 (值)矩阵。
(值)矩阵。
因为每一行的权重已经被 Mask 强行修改过了,所以:
- 输出的第一行,只融合了"床"的 。
- 输出的第二行,只融合了"床、前"的 。
- ...以此类推。
这 4 个融合了正确历史上下文的特征向量,会同时 继续向上层传递,最终同时通过最后的线性层,变成 4 个预测下一个字的概率分布。 然后与真实的y的4个token 进行交叉熵损失。