本系列为从零编写完整 Bootloader 项目 ,涵盖下位机 Bootloader、PC 端上位机(Qt)、设备端 APP 全套实现。Bootloader 与上位机支持 UART、WIFI(基于 ESP32-S3 SPI 实现)、ETH 三种通讯方式(ETH 功能当前仍在调试优化)。为统一通讯规范、保证兼容性,我设计了自定义类 MODBUS 数据帧协议 ,所有多字节数据均采用大端序传输。
本章重点记录Protocol_FeedByte 逐字节数据解析函数 的实现细节,通过该函数的编写与调试,我彻底理清了协议大端传输、STM32 小端存储场景下,嵌入式通讯中最核心的字节序适配问题。
目录
[一、基础概念:MSB 与 LSB](#一、基础概念:MSB 与 LSB)
[1. 位级定义(针对单个字节的二进制位)](#1. 位级定义(针对单个字节的二进制位))
[2. 字节级定义(针对多字节整数)](#2. 字节级定义(针对多字节整数))
[1. 大端模式(Big-Endian,BE)](#1. 大端模式(Big-Endian,BE))
[2. 小端模式(Little-Endian,LE)](#2. 小端模式(Little-Endian,LE))
[三、直观对比图(以 32 位整数 0x12345678 为例)](#三、直观对比图(以 32 位整数 0x12345678 为例))
[16 位整数 0x1234 对比](#16 位整数 0x1234 对比)
[1. 大端模式的优势](#1. 大端模式的优势)
[2. 小端模式的优势](#2. 小端模式的优势)
[3. 历史原因](#3. 历史原因)
六、本项目中的Protocol_FeedByte的作用与实现方法
一、基础概念:MSB 与 LSB
MSB 和 LSB 是描述多字节数据 "最高 / 最低有效部分"的通用术语,存在位级和字节级两种语境,这是理解大小端的前提。
1. 位级定义(针对单个字节的二进制位)
- MSB(Most Significant Bit) :最高有效位
- 一个字节中权重最大的二进制位,即最左边的第 7 位
- 例如:字节
0b10100101的 MSB 是1,代表数值128
- LSB(Least Significant Bit) :最低有效位
- 一个字节中权重最小的二进制位,即最右边的第 0 位
- 例如:字节
0b10100101的 LSB 是1,代表数值1
2. 字节级定义(针对多字节整数)
- MSB(Most Significant Byte) :最高有效字节
- 多字节整数中权重最大的字节,包含数值的最高位部分
- 例如:32 位整数
0x12345678的 MSB 是0x12,代表数值0x12000000
- LSB(Least Significant Byte) :最低有效字节
- 多字节整数中权重最小的字节,包含数值的最低位部分
- 例如:32 位整数
0x12345678的 LSB 是0x78,代表数值0x00000078
还有一个很简单的方法判断高低位在哪,还是 用0x12345678举例,你可以把它看成单纯的一串数字12345678,并把它念出来,12345678就是一千二百三十四万五千六百七十八,很显然这其中的一就是最高位,因为其代表着千万位,八就是最低位,因为其代表着个位。有时候突然看到一个数据恍惚了不知道哪边是高低位了就可以用这种土方法去判断。
二、核心概念:大小端模式
大小端是多字节数据在内存中的存储顺序规则 ,只针对 2 字节及以上的整数(如uint16_t、uint32_t),单字节数据不存在大小端问题。
1. 大端模式(Big-Endian,BE)
定义 :MSB 存放在低地址,LSB 存放在高地址
- 存储顺序与人类阅读数字的顺序完全一致
- 也称为 "网络字节序",所有网络协议、绝大多数串口协议默认使用大端
2. 小端模式(Little-Endian,LE)
定义 :LSB 存放在低地址,MSB 存放在高地址
- 存储顺序与人类阅读顺序相反
- 绝大多数 CPU 架构(x86、ARM Cortex-M 系列、STM32)默认使用小端
三、直观对比图(以 32 位整数 0x12345678 为例)
内存地址与字节对应关系
| 内存地址 | 0x00000000(低地址) | 0x00000001 | 0x00000002 | 0x00000003(高地址) |
|---|---|---|---|---|
| 大端模式 | 0x12(MSB) | 0x34 | 0x56 | 0x78(LSB) |
| 小端模式 | 0x78(LSB) | 0x56 | 0x34 | 0x12(MSB) |
16 位整数 0x1234 对比
| 内存地址 | 0x00000000(低地址) | 0x00000001(高地址) |
|---|---|---|
| 大端模式 | 0x12(MSB) | 0x34(LSB) |
| 小端模式 | 0x34(LSB) | 0x12(MSB) |
四、为什么会有两种字节序?
1. 大端模式的优势
- 符合人类阅读习惯,调试时直接查看内存就能读出正确数值
- 适合协议传输,接收方按顺序读取即可拼接成正确数值
2. 小端模式的优势
- 符合 CPU 的运算逻辑:CPU 从低地址开始读取数据,先拿到 LSB 可以直接开始运算
- 强制类型转换更方便:例如将
uint32_t强制转换为uint8_t时,直接取低地址的 LSB 即可
3. 历史原因
- 大端模式最早由 IBM 大型机使用,后来成为网络协议的标准
- 小端模式由 Intel x86 架构普及,现在绝大多数消费级电子设备都使用小端
大端模式和小端是实际的字节顺序和存储的地址顺序对应关系的两种模式。
大端模式:高位字节存放在低地址中,低位字节存放在高地址中。最直观的字节序。
小端模式:高位字节存放在高地址中,低位字节存放在低地址中。最符合人的思维的字节序 ,x86、ARM都是这种形式(KEIL C51中,变量都是大端模式的;KEIL MDK中,变量是小端模式的)。
五、本项目中的情况
由于本项目中**协议为大端传输,STM32小端存储,**这里可以举一个例子:
上位机发 0x1234(大端:先发 0x12,后发 0x34)
我们希望 STM32 收到后,存储的变量里也是 0x1234
但 STM32 是 小端 CPU:
- 如果直接
memcpy收到的字节[0x12, 0x34] - STM32 会自动理解成 低地址 = 低字节,高地址 = 高字节
- 结果变量变成 0x3412(完全错误)
所以 必须手动移位重组,不能直接 memcpy。
在这里我还写了一个Protocol_test函数来验证这个问题,rx_byte2是从上位机接收到的2字节数据,如果我们直接使用memcpy将其拷贝到result_memcpy中,那么得到的其实是result_memcpy=0x3412,只有通过手动移位的方法将数据存入result_shift ,才会得到我们想要的result_shift=0x1234;
cpp
void Protocol_test(void)
{
/*上位机大端发送,stm32小端处理所以需要通过手动移位的方式进行存储,
如果直接使用memcpy会出现字节序错误*/
const uint8_t rx_byte[2] = {0x12, 0x34};
uint16_t result_memcpy = 0;
uint32_t result_shift = 0;
memcpy(&result_memcpy, rx_byte, 2);
result_shift = (result_shift << 8) | rx_byte[0];
result_shift = (result_shift << 8) | rx_byte[1];
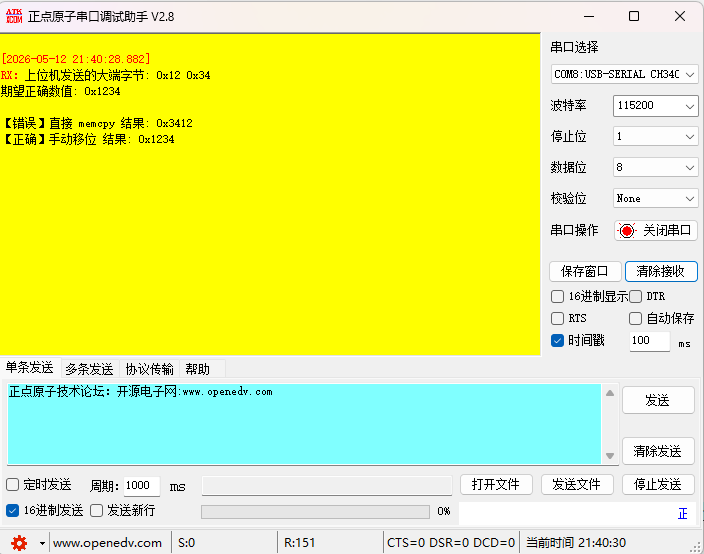
printf("上位机发送的大端字节: 0x%02X 0x%02X\n", rx_byte[0], rx_byte[1]);
printf("期望正确数值: 0x1234\n\n");
printf("【错误】直接 memcpy 结果: 0x%04X\n", result_memcpy);
printf("【正确】手动移位 结果: 0x%04X\n", result_shift);
return 0;
}
六、本项目中的Protocol_FeedByte的作用与实现方法
下面呈现的Protocol_FeedByte函数的作用就是它不依赖 CPU 自身的字节序特性 ,严格按照协议约定的大端传输顺序,通过手动移位 + 按位或的方式逐字节重组数据,将总线上的大端字节流,正确拼接为 STM32 可直接使用的整型数值。
最终实现:上位机发送的原始数据 = STM32 解析后的变量值,从根源上解决了大小端不匹配导致的协议解析错误。
cpp
void Protocol_FeedByte(ProtocolHandle_t *handle, uint8_t byte)
{
/*空指针 + 帧已处理判断*/
if (handle == NULL || handle->frame_ready)
{
return;
}
switch (handle->state)
{
// -------------------------- 帧头0xAA,0X55 --------------------------
case PROTO_STATE_IDLE:
if (byte == 0xAA)
{
handle->state = PROTO_STATE_HEADER_2;
}
else
handle->state = PROTO_STATE_IDLE;
break;
case PROTO_STATE_HEADER_2:
if (byte == 0x55)
{
handle->frame.header = 0XAA55;
handle->state = PROTO_STATE_CMD;
handle->byte_cnt = 0;
handle->temp_val = 0;
}
else if (byte == 0xAA)
handle->state = PROTO_STATE_HEADER_2;
else
handle->state = PROTO_STATE_IDLE;
break;
// -------------------------- 命令区(2字节大端)、长度区(2字节大端)解析 --------------------------
case PROTO_STATE_CMD:
case PROTO_STATE_LEN:
handle->temp_val = (handle->temp_val << 8) | byte;
handle->byte_cnt++;
if (handle->byte_cnt == 2)
{
if (handle->state == PROTO_STATE_CMD)
{
handle->frame.cmd = handle->temp_val;
handle->state = PROTO_STATE_LEN;
}
else
{
handle->frame.length = handle->temp_val;
if (handle->frame.length > sizeof(handle->frame.data))
{
handle->state = PROTO_STATE_IDLE;
}
else
{
handle->state = PROTO_STATE_DATA;
handle->data_idx = 0;
}
}
handle->state = (handle->frame.length == 0) ? PROTO_STATE_RESERVE : PROTO_STATE_DATA;
handle->byte_cnt = 0;
handle->temp_val = 0;
}
break;
// -------------------------- 数据区解析 ----------------------------------
case PROTO_STATE_DATA:
handle->frame.data[handle->data_idx++] = byte;
if (handle->data_idx >= handle->frame.length)
{
handle->state = PROTO_STATE_RESERVE;
handle->byte_cnt = 0;
handle->temp_val = 0;
}
break;
// -------------------------- 4字节大端保留位处理(大端) --------------------------
case PROTO_STATE_RESERVE:
handle->temp_val = (handle->temp_val << 8) | byte;
handle->byte_cnt++;
if (handle->byte_cnt == 4)
{
handle->frame.reserve = handle->temp_val;
handle->state = PROTO_STATE_CRC;
handle->byte_cnt = 0;
handle->temp_val = 0;
}
break;
// ==================== CRC16(小端)+ 校验 ====================
case PROTO_STATE_CRC:
if (handle->byte_cnt == 0)
handle->temp_val = byte;
else if (handle->byte_cnt == 1)
handle->temp_val = (byte << 8) | handle->temp_val;
handle->byte_cnt++;
if (handle->byte_cnt == 2)
{
handle->frame.crc16 = handle->temp_val;
handle->state = PROTO_STATE_IDLE;
handle->byte_cnt = 0;
handle->temp_val = 0;
if (Protocol_VerifyFrameCRC(&handle->frame))
handle->frame_ready = 1;
}
break;
default:
break;
}
}