线性表
类似a0,a1,a2,......an−1(i=0,1,2,......,n−1)a_0,a_1,a_2,......a_{n-1}(i=0,1,2,......,n-1)a0,a1,a2,......an−1(i=0,1,2,......,n−1)的列表称为有限列表,其中:
ai−1a_{i-1}ai−1是aia_iai的直接前趋,但a0a_0a0没有,ai+1a_{i+1}ai+1是aia_iai的直接后继,但an−1a_{n-1}an−1没有,长度为nnn,长度为0时称为空表。
两种存储方式
顺序表
逻辑、物理位置均相邻的,称为顺序表。
示例:python的list、tuple,其他语言的数组
链表
类别
1.单链表

示例代码分析:
- python版:
python
############################### 定义单链表的结点 ###############################
class Node(object): # 定义节点类
def __init__(self, elem): # 定义构造函数,传入相应参数,初始化链表
self.elem = elem # 给数据域赋值,即将elem赋值给self.elem
self.next = None # 初始设置下一节点为空
############################### 定义单链表相关函数 ###############################
class SingleLinkList(object): # 创建单链表
def __init__(self, node=None): # 使用一个默认参数,传入头结点接收;没有传入时,默认头结点为空
self.__head = node # 将传入的node值赋值给self.__head,即链表的头部
def is_empty(self): # 编写相关函数便于判断链表是否为空
return self.__head == None # 返回self.__head是否为None的布尔值,如果为True,则为空链表
def length(self): # 编写相关函数计算链表长度
cur = self.__head # 初始化cur游标,用来移动遍历节点,起始位置位于self.__head
count = 0 # 初始化用于记录变量的count的值
while cur != None: # 当cur获取的值不为None时,即后续还有结点,进入计数循环
count += 1 # 记录不为空的结点数,总记录+1
cur = cur.next # 移动游标,指向下一个结点的位置
return count # 循环完成,即cur为None,后续无结点时,返回count的值
def travel(self): # 定义函数遍历整个列表,输出元素内容
cur = self.__head # 初始化cur游标,用来移动遍历节点,起始位置位于self.__head
while cur != None: # 当cur获取的值不为None时,即后续还有结点,进入遍历循环
print(cur.elem, end=' ') # 打印结点的数据域的内容,结尾设置为空格便于输出大量内容
cur = cur.next # 移动游标,指向下一个结点的位置
print("\n") # 遍历完成,输出换行符,便于后续输出
def add(self, item): # 定义链表头部添加元的相关函数
node = Node(item) # 使用Node类初始化node结点,传入参数item
node.next = self.__head # 将该结点的尾部指针域指向原链表的头部,即将node.next赋值为self.__head
self.__head = node # 将新链表的头部指向该元素,即self.__head指向node结点
def append(self, item): # 定义向链表尾部添加元素
node = Node(item) # 由于特殊情况当链表为空时没有next,所以在前面要做个判断
if self.is_empty(): # 使用之前判断空链表的的函数进行判断是否为空链表
self.__head = node # 如果是,则将该结点设置为首结点
else: # 否则
cur = self.__head # 移动游标,遍历链表
while cur.next != None: # 遍历链表,直到结尾
cur = cur.next # 移动游标到下一个结点
cur.next = node # 将原链表尾部结点的指针域指向新的结点
def insert(self, pos, item): # 编写函数实现在指定位置添加元素
if pos <= 0: # 如果pos位置在0,当做头插法
self.add(item) # 使用之前编写的头插法函数
elif pos > self.length() - 1:# 如果pos位置比原链表长,那么都当做尾插法来做
self.append(item) # 使用之前编写的尾插法函数
else: # 如果都不是
per = self.__head # 将插入点移动到链表头部
count = 0 # 初始化计数变量,记录游标走过的数量
while count < pos - 1: # 如果计数结果小于插入点,则继续移动游标
count += 1 # 计数器自增
per = per.next # 移动游标到下一个位置,即当循环退出后,pre指向pos-1位置
node = Node(item) # 初始化结点
node.next = per.next # 将目标插入点的后面一个元素的位置保存到新节点的指针域,即新节点的下一个结点是插入点的下一个元素
per.next = node # 插入结点的数据域,让前一个结点指向新节点
def remove(self, item): # 编写函数实现删除节点的功能
cur = self.__head # 将游标移动到开头
pre = None # 定义删除点变量,初始化为None
while cur != None: # 遍历链表
if cur.elem == item: # 如果数据匹配,找到该结点
if cur == self.__head:# 如果游标在头节点
self.__head = cur.next# 更改头节点的指向,指向原链表头节点的下一个结点
else: # 否则,继续遍历
pre.next = cur.next#修改前一个结点的指针域指向,跳过要删除的结点,达到删除的效果
break # 完成操作后,跳出循环
else: # 如果没找到,继续遍历,直到找到
pre = cur # 移动待删除的结点的标记
cur = cur.next # 移动游标到下一个结点
def search(self, item): # 编写函数实现查找节点是否存的功能
cur = self.__head # 移动游标到链表的开头
while not cur: # 当游标没有在末尾时,继续遍历
if cur.elem == item: # 如果成功查找到结点
return True # 返回布尔值True,代表找到
else: # 否则
cur = cur.next # 移动游标到下一个元素,继续查找
return False # 如果遍历整个链表都没找到,返回布尔值False,代表未找到该元素
############################### 运行代码 ###############################
if __name__ == "__main__": # 程序入口,开始执行代码
ll = SingleLinkList() # 实例化类,初始化链表ll
print(ll.is_empty()) # 判断是否为空列表
print(ll.length()) # 获取链表长度
ll.append(3) # 向链表尾部添加结点,值为3
ll.add(999) # 向链表头部添加结点,值为999
ll.insert(-3, 110) # 向链表添加一个结点,位置是-3,即倒数第三个前面,值为110
ll.insert(99, 111) # 向链表添加一个结点,位置是99,但没有99个结点,则添加到链表末尾,值为111
print(ll.is_empty()) # 再次判断链表是否为空链表
print(ll.length()) # 再次获取链表长度
ll.travel() # 遍历并打印当前链表的所有结点的值
ll.remove(111) # 移除值为111的结点
ll.travel() # 再次遍历,查看删除是否成功- c语言版:
c
#include <stdio.h>
#include <stdlib.h>
/*========定义链表结点结构========*/
typedef struct node {
/*定义数据域,这里采用整型变量演示*/
int item;
/*定义指针域,链表一般指向下一个节点的位置*/
struct node * next;
} Node;
/*========初始化链表函数========*/
Node * initLinkList(int totalNode)
{
/*定义头指针,当前还没有结点,暂时为NULL*/
Node * head = NULL;
/*定义头节点,使用malloc开辟合适的空间*/
Node * headNode = (Node *)malloc(sizeof(Node));
/*为头节点的数据域填充数据*/
headNode->item = 0;
/*将头节点的指针域指向下一个结点,当前没有,暂时为NULL*/
headNode->next = NULL;
/*将头指针指向头结点*/
head = headNode;
/*定义一个临时变量作为游标,初始化指向头节点*/
Node * cur = headNode;
/*根据传入的结点数初始化链表的每个结点*/
for (int i = 1; i < totalNode; i++) {
/*根据结点所占的大小分配空间*/
Node * eachNode = (Node *)malloc(sizeof(Node));
/*为了简便,我们直接使用循环变量赋值,当然也可以用其他的*/
eachNode->item = i;
/*每个结点在当次循环中均是最后一个,所以next指向NULL*/
eachNode->next = NULL;
/*将当前结点的位置赋值给上一个结点的指针域*/
cur->next = eachNode;
/*修改游标,指向当前结点*/
cur = cur->next;
}
/*返回头节点的位置的指针*/
return head;
}
int insectItem(Node * head, int item, int position)
{
/*定义一个插入结点,初始化指向空*/
Node * insectNode = NULL;
/*定义游标,初始化指向传入链表的头节点*/
Node * cur = head;
/*遍历链表,找到插入的位置所在的结点*/
for (int i = 1; i < position; i++) {
/*移动游标,指向下一个结点*/
cur = cur -> next;
/*判断游标在给定位置范围内是否到头*/
if (NULL == cur) {
/*输出报错信息,跳出函数*/
printf_s("结点不存在!插入失败!\n");
return -1;
}
}
/*为插入的值建立结点,分配空间*/
insectNode = (Node *)malloc(sizeof(Node));
/*将传入的item的值赋值到新结点的数据域中*/
insectNode->item = item;
/*将插入的结点和后继结点连接上*/
insectNode->next = cur->next;
/*断开原链表前结点的连接,将前趋结点的下一个结点指向新节点*/
cur->next = insectNode;
return 1;
}
int deleteItem(Node * head, int item)
{
/*定义删除位置变量,游标变量指向链表头结点*/
Node * position,*cur = head;
/*定义变量记录是否查找到对应结点*/
int findOut = 0;
/*遍历链表查找结点,直到结尾*/
while (cur ->next) {
/*判断游标的下一个结点的数据域是否是要查找的内容*/
if (item == cur->next->item) {
/*修改变量,标记为查找到对应结点,并跳出循环*/
findOut = 1;
break;
}
/*否则,指向下一个结点,继续遍历*/
cur = cur ->next;
}
/*如果未找到目标结点*/
if (0 == findOut) {
/*输出报错信息并跳出函数*/
printf_s("结点不存在!删除失败!\n");
return -1;
} else {
/*找到对应结点,将删除位置指向该节点*/
position = cur->next;
/*将待删除结点的上一个结点的指针域指向待删除结点的下一个结点,断开待删除结点的两头连接*/
cur->next = cur->next->next;
/*用free函数清理待删除结点的空间,删除对应结点*/
free(position);
return 1;
}
}
int findItem(Node * head, int item)
{
/*定义游标,指向头节点的下一个结点*/
Node * cur = head->next;
/*遍历链表查找指定元素*/
for (int i = 1; cur != NULL; i++) {
/*如果游标所在结点的数据域和要查找的相同*/
if (cur->item == item) {
/*返回所在位置*/
return i;
}
/*移动游标到下一个结点*/
cur = cur->next;
}
return -1;
}
int editItem(Node * head, int item, int newItem)
{
/*定义游标,指向头节点的下一个结点*/
Node * cur = head->next;
/*遍历链表查找指定元素*/
while (cur) {
/*如果游标所在结点的数据域和要查找的相同*/
if (cur->item == item) {
/*将数据域的数据替换为新数据*/
cur ->item = newItem;
/*返回所在位置*/
return 1;
}
/*移动游标到下一个结点*/
cur = cur->next;
}
return -1;
}
void travel(Node * head)
{
/*定义游标,指向头节点的下一个结点*/
Node * cur = head->next;
/*遍历链表查找指定元素*/
while (cur) {
/*输出结点的数据域的数据*/
printf_s("%d ",cur->item);
/*移动游标到下一个结点*/
cur = cur->next;
}
/*遍历输出完成,换行继续下一个函数*/
printf_s("\n");
}
void freeLinkList(Node * head)
{
/*定义变量,遍历链表进行清理*/
Node * freeNode = NULL;
/*定义游标,指向头节点的下一个结点*/
Node * cur = head->next;
/*当游标未到达链表尾部时*/
while(cur ->next)
{
/*待清理的结点标记游标所在结点的下一个结点*/
freeNode = cur->next;
/*将游标的下一个结点指向原下一个结点的下一个结点*/
cur->next = cur->next->next;
/*调用free函数清理已标记的结点*/
free(freeNode);
}
/*当所有后继结点都清理完成后,清理头节点*/
free(head);
}
/*========程序入口========*/
int main()
{
Node * headLinkListNode = initLinkList(5);
printf_s("初始化链表为:\n");
travel(headLinkListNode);
printf("在第 3 的位置上添加元素 6:\n");
insectItem(headLinkListNode, 6, 3);
travel(headLinkListNode);
printf("删除元素4:\n");
deleteItem(headLinkListNode, 4);
travel(headLinkListNode);
printf("查找元素 2:\n");
printf("元素 2 的位置为:%d\n", findItem(headLinkListNode, 2));
printf("更改元素 1 的值为 6:\n");
editItem(headLinkListNode, 1, 6);
travel(headLinkListNode);
freeLinkList(headLinkListNode);
return 0;
}2.循环链表
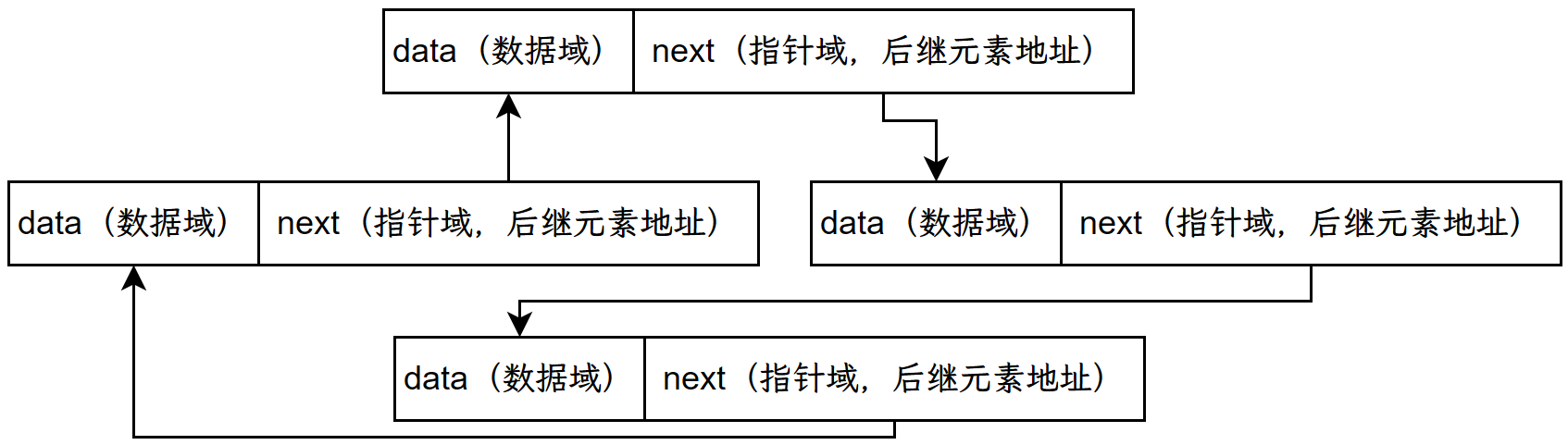
3.双向链表

相关操作
1. 前移策略
前移策略是一种基于局部性原理的自组织链表优化算法,其核心思想是"最近被访问的节点在将来很可能再次被访问",因此通过将刚访问过的节点直接移动到链表头部,使得频繁访问的热点数据始终位于链表前端,从而大幅减少后续查找这些数据的平均遍历长度,提升整体访问效率。
实现步骤
- 遍历链表查找目标节点;
- 若找到目标节点且该节点不是头节点,则将其从原位置摘除;
- 将该节点插入到链表头部,更新头指针指向该节点。
Python代码
python
class Node:
def __init__(self, data):
self.data = data
self.next = None
class MoveToFrontList:
def __init__(self):
self.head = None
def search_and_move(self, key):
if not self.head:
return False
if self.head.data == key:
return True
current = self.head
while current.next and current.next.data != key:
current = current.next
if not current.next:
return False
target = current.next
current.next = target.next
target.next = self.head
self.head = target
return TrueC代码
c
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
typedef struct {
Node* head;
} MoveToFrontList;
void init_list(MoveToFrontList* list) {
list->head = NULL;
}
int search_and_move(MoveToFrontList* list, int key) {
if (!list->head) return 0;
if (list->head->data == key) return 1;
Node* current = list->head;
while (current->next && current->next->data != key) {
current = current->next;
}
if (!current->next) return 0;
Node* target = current->next;
current->next = target->next;
target->next = list->head;
list->head = target;
return 1;
}2. 交换策略
交换策略是另一种自组织链表优化方法,相比前移策略更加温和,它不将访问节点直接移到头部,而是仅与前驱节点交换位置,这样既能逐步将热点数据向链表前端移动,又能避免因单次偶然访问导致链表结构剧烈变动,适合访问频率分布相对均匀的场景。
实现步骤
- 遍历链表查找目标节点,同时记录其前驱节点;
- 若找到目标节点且该节点不是头节点,则交换目标节点与前驱节点;
- 若目标节点是头节点,则无需操作。
Python代码
python
class Node:
def __init__(self, data):
self.data = data
self.next = None
class TransposeList:
def __init__(self):
self.head = None
def search_and_transpose(self, key):
if not self.head or self.head.data == key:
return True
prev = self.head
current = self.head.next
while current and current.data != key:
prev = current
current = current.next
if not current:
return False
# 交换数据域
prev.data, current.data = current.data, prev.data
return TrueC代码
c
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
typedef struct {
Node* head;
} TransposeList;
void init_list(TransposeList* list) {
list->head = NULL;
}
int search_and_transpose(TransposeList* list, int key) {
if (!list->head || list->head->data == key) return 1;
Node* prev = list->head;
Node* current = list->head->next;
while (current && current->data != key) {
prev = current;
current = current->next;
}
if (!current) return 0;
// 交换数据域
int temp = prev->data;
prev->data = current->data;
current->data = temp;
return 1;
}3. 环路检测与环路断开
基于弗洛伊德判圈算法,利用快慢指针的速度差检测环路:若链表存在环,快指针(每次走两步)最终会在环内追上慢指针(每次走一步);若链表无环,快指针会先到达链表末尾(NULL),通过判断两指针是否相遇即可确定是否存在环路。
实现步骤
- 初始化快慢指针均指向链表头节点;
- 循环移动指针:慢指针每次前进一步,快指针每次前进两步;
- 若快指针或其下一节点为NULL,说明无环;
- 若快慢指针相遇,说明存在环路。
Python代码
python
class Node:
def __init__(self, data):
self.data = data
self.next = None
def has_cycle(head):
if not head or not head.next:
return False
slow = head
fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
if slow == fast:
return True
return FalseC代码
c
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
int has_cycle(Node* head) {
if (!head || !head->next) return 0;
Node* slow = head;
Node* fast = head;
while (fast && fast->next) {
slow = slow->next;
fast = fast->next->next;
if (slow == fast) {
return 1;
}
}
return 0;
}4. 链表反转
通过迭代方式逐个反转节点的指针方向,将原链表中每个节点的next指针从指向后继节点改为指向前驱节点,最终使整个链表的遍历方向完全颠倒,核心是维护三个指针分别记录当前节点、前驱节点和临时保存的后继节点,避免链表断裂。
实现步骤
- 初始化前驱指针为NULL,当前指针为头节点;
- 循环处理每个节点:保存当前节点的下一节点,将当前节点的next指向前驱节点,前驱指针和当前指针依次后移;
- 当当前指针为NULL时,前驱指针即为新的头节点。
Python代码
python
class Node:
def __init__(self, data):
self.data = data
self.next = None
def reverse_list(head):
prev = None
current = head
while current:
next_temp = current.next
current.next = prev
prev = current
current = next_temp
return prevC代码
c
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
Node* reverse_list(Node* head) {
Node* prev = NULL;
Node* current = head;
while (current) {
Node* next_temp = current->next;
current->next = prev;
prev = current;
current = next_temp;
}
return prev;
}