1.BN 简介
Batch Normalization (BN):深度学习中常用的归一化层,核心作用是对每个 batch 的特征做 (x - μ)/σ 归一化(μ 是均值,σ 是方差),并通过可学习的 γ、β 调整分布; 
训练时 BN 会滑动更新全局的 running_mean/running_var,pytorch 中更新规则如下:
Plain
running_mean=(1−momentum)⋅running_mean+momentum⋅batch_mean
running_var=(1−momentum)⋅running_var+momentum⋅batch_varPyTorch 中 BatchNorm 的 momentum 默认值是 0.1:
Plain
nn.BatchNorm2d(num_features, momentum=0.1)它控制 running_mean 和 running_var 的更新速度。
推理时则使用这些预存的统计值。 因此,推理阶段,BN 公式变为: 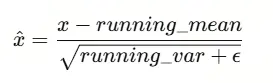
2.freezebn 简介
freezebn:训练时固定 BN 层的行为 ------ 通常是冻结 running_mean/running_var 的更新,同时固定 γ/β(也有仅冻结统计量的情况),让 BN 层以 "推理模式" 运行。
freezebn 并非所有浮点训练场景都需要,而是在迁移学习 / 微调(Fine-tuning) 、小批量训练 等场景中应用。
2.1 迁移学习 / 微调
在迁移学习/微调时 freezebn,主要目的是:避免预训练的 BN 统计量被破坏。迁移学习/微调是 使用 freezebn 最常见的场景。当你基于预训练模型微调时:
- 预训练模型的 BN 层已经学习到了通用数据集(如 ImageNet)上的 running_mean/running_var,这些统计量是模型泛化能力的重要基础;
- 微调时的数据集通常更小、分布与预训练集差异大(比如从通用图像微调至特定场景:人脸识别、工业缺陷检测),小批量数据的统计量(batch_mean/batch_var)会偏离预训练的全局统计量;
- 如果不冻结 BN,微调时新的小批量数据会持续更新 running_mean/running_var,导致预训练的有效统计量被覆盖,模型快速 "忘记" 通用特征,出现过拟合或精度暴跌;
- 冻结 BN 后,BN 层复用预训练的全局统计量,仅更新后续分类层 / 任务层的参数,既保留通用特征,又适配新任务。
2.2 小批量训练
浮点训练中如果 batch size 过小(比如 ≤8),freeezebn 可以解决 BN 层统计量不稳定的问题
- BN 层计算的 batch_mean/batch_var 会严重偏离真实的全局统计量(批次越小,随机性越强),导致归一化效果失效,模型训练震荡、不收敛;
- 冻结 BN 后,使用预训练的稳定统计量,能规避小批量带来的统计噪声,让训练过程更稳定。(迁移学习)
2.3 freezebn 示例
Plain
import torch
import torch.nn as nn
import torchvision.models as models
def freeze_bn(model):
"""
冻结模型中所有BN层:
1. 设置eval()让BN以推理模式运行(不更新统计量)
2. 冻结BN层的参数(γ/β不更新)
"""把关注点转到量化部署,常听到:浮点训练时使用 freezebn 的技巧,在 QAT 时建议尝试 withbn 的训练方式,当然,常规情况下,还是建议 QAT 采用 fusebn 的方式。下面我们来看看量化部署时,fusebn/withbn 的情况。
3.conv 与 bn 融合原理
地平线算法工具链在做量化训练 prepare 时,默认会将 Conv(卷积)+ BN(批归一化)融合,核心原因是 BN 层会动态改变张量的数值范围,而融合后可将其 "固化" 为卷积的静态参数,消除动态范围波动对量化的干扰,让量化的 "范围映射" 更精准,提升量化模型的精度。
单独的 conv 卷积和 BN 计算可拆解为:
-
卷积层输出:
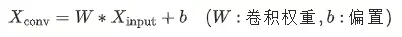
-
BN 层输出:
训练时
- 将 BN "固化" 为卷积参数:使用 BN 全局统计量(μ/σ^{2),将 BN 的计算 "合并" 到卷积层中
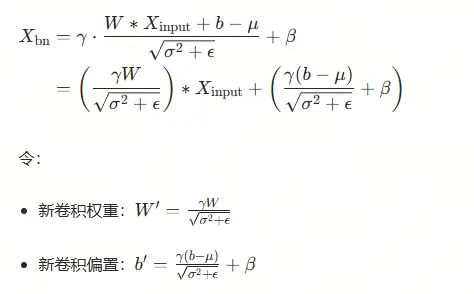
融合后,Conv+BN 等价于一个 "新的卷积层",无需单独的 BN 计算,提高推理效率。
4.fusebn/withbn 介绍
qat_mode 用于设置 QAT 阶段是否带 BN 进行量化训练。如果在浮点训练中使用了 freeze bn 的技巧,那么 qat 训练中需要将 qat mode 设置为 withbn。
qat_mode 可选的设置有如下三种:
Plain
class QATMode(object):
FuseBN = "fuse_bn"
WithBN = "with_bn"
WithBNReverseFold = "with_bn_reverse_fold" # 先不关注4.1 fuse_bn
QAT 阶段没有 BN,horizon_plugin_pytorch 默认的量化训练方式。
通过将 qat_mode 设置为 fuse_bn ,在浮点模型 op 融合的过程中,BN 的 weight 和 bias 均被吸收到 Conv 的 weight 和 bias 中,原来的 Conv + BN 的组合将只剩下 Conv,这一吸收过程理论上是没有误差的。
4.2 with_bn
QAT 阶段带 BN 进行训练。
通过设置 qat_mode 为 with_bn ,浮点模型转为 QAT 模型的时候 BN 不会吸收进 Conv,而是在 QAT 阶段以 Conv + BN + 输出量化节点 的形式作为一个被融合的量化 op 存在于量化模型中。最终在量化训练结束 convert 转为 quantized 模型的步骤中,BN 的 weight 和 bias 将自动吸收进 conv 的量化参数中,吸收之后得到的 quantized op 和原来的 QAT op 计算结果保持一致。
之所以说"理论上吸收前后无损"或"无变化",是由于在实际计算中吸收前后两次浮点计算的结果有较低的概率会在小数点较靠后的数位上不一致,微小的变化加上量化操作导致吸收 BN 后 Conv 的输出相比吸收前 Conv + BN 的输出在部分数值上可能会产生一个输出 scale 的绝对误差。
4.3 使用用法(重要)
在 prepare 前设置 qat_mode,calib 和 qat 的 prepare 前需要保持 qat_mode 一致,否则会出现 qat_model 无法加载 calib_model_ckpt 的问题。
Plain
from horizon_plugin_pytorch.qat_mode import QATMode, set_qat_mode
set_qat_mode(QATMode.WithBN)
calib_qat_net = prepare(float_model, (input_tensor),qconfig_setter=qconfig_setter)一般训练流程是浮点训练到理想精度然后量化训练,此时只需要使用 fuse_bn 即可。