目录
[2.1 切分数据集](#2.1 切分数据集)
[3.1 训练:](#3.1 训练:)
[3.2 模型](#3.2 模型)
节点级注意力:GATConv(调用dgl库,本次不做重点讲解,之后单独出一篇讲解)
[语义级注意力: SemanticAttention](#语义级注意力: SemanticAttention)
图神经网络概览:图神经网络分享系列-概览
理论部分:图神经网络分享系列-HAN(Heterogeneous Graph Attention Network)(一)
本章内容主要进行torch版本实战
一、参数-args
python
{'seed': 1,
'log_dir': 'results/ACM_2026-03-29_17-23-25',
'hetero': False,
'lr': 0.005,
'num_heads': [8],
'hidden_units': 8,
'dropout': 0.6,
'weight_decay': 0.001,
'num_epochs': 200,
'patience': 100,
'dataset': 'ACM',
'device': 'cpu'}二、数据集
python
#数据:ACM3025.pkl
with open(data_path, "rb") as f:
data = pickle.load(f)
print("label:")
print(data["label"].shape)
print(data["label"])
print("feature:")
print(data["feature"].shape)
print(data["feature"])
labels, features = (
torch.from_numpy(data["label"].todense()).long(),
torch.from_numpy(data["feature"].todense()).float(),
)
数据都是稀疏矩阵,以label为例,第0个节点,在第0类上是1,也就是说第0个节点属于第0类
feature同理,第0个节点,在第0个特征上是1,一共有1870个特征。
**之所以要做todense():**将稀疏矩阵转换为密集矩阵(dense matrix),将其转换为完整的 numpy 矩阵,便于后续转换为 PyTorch 张量;那之所以存储稀疏矩阵,是因为节省存储空间。
python
data["label"]
(0, 0) 1.0
(3024, 2) 1.0
data["feature"]
(0, 0) 1.0
(0, 1) 1.0一共有3025个节点,3类label,每个节点的特征1870维
python
label shape: (3025, 3)
feature shape:(3025, 1870)一共有两种元路径 (Meta -paths):
-
PAP: Paper-Author-Paper (通过作者相连的论文)
-
PLP: Paper-Label-Paper (通过标签(主题)相连的论文)
python
PAP和plp shape: [3025,3025] 均为邻接矩阵,如上面所说,存储都是稀疏矩阵形式,
data["PAP"]:
(0, 0) 1.0
(0, 8) 1.0
data["PLP"]:
(0, 0) 1.0
(0, 75) 1.0
author_g = dgl.from_scipy(data["PAP"])
subject_g = dgl.from_scipy(data["PLP"])
author_g: Graph(num_nodes=3025, num_edges=29281,
ndata_schemes={}
edata_schemes={})
subject_g:Graph(num_nodes=3025, num_edges=2210761,
ndata_schemes={}
edata_schemes={})
gs = [author_g, subject_g]2.1 切分数据集
直接读取即可,因为本身存储的时候已经划分了。
存储了各自的节点,加起来是3025个节点。
python
train_idx = torch.from_numpy(data["train_idx"]).long().squeeze(0)
val_idx = torch.from_numpy(data["val_idx"]).long().squeeze(0)
test_idx = torch.from_numpy(data["test_idx"]).long().squeeze(0)
train_idx shape torch.Size([600])
val_idx shape torch.Size([300])
test_idx shapetorch.Size([2125])
test_idx: tensor([ 300, 301, 302, ..., 3022, 3023, 3024])mask矩阵获取:
以train_mask为例,只有train节点为1,其余0.
python
num_nodes = author_g.num_nodes()
print(num_nodes) # 3025
train_mask = get_binary_mask(num_nodes, train_idx)
# train_mask shape: torch.Size([3025])
# train_mask : tensor([1, 1, 1, ..., 0, 0, 0], dtype=torch.uint8)
val_mask = get_binary_mask(num_nodes, val_idx)
test_mask = get_binary_mask(num_nodes, test_idx)
def get_binary_mask(total_size, indices):
"""
生成二进制掩码张量
Args:
total_size: 掩码的总长度
indices: 需要设置为1的索引位置
Returns:
二进制掩码张量,类型为torch.ByteTensor
"""
mask = torch.zeros(total_size)
mask[indices] = 1
return mask.byte()
三、训练+模型
3.1 训练:
- 200轮epoch,100轮早停机制
- ce损失函数
- adam优化器
python
from model import HAN
model = HAN(
num_meta_paths=len(g),
in_size=features.shape[1],
hidden_size=args["hidden_units"],
out_size=num_classes,
num_heads=args["num_heads"],
dropout=args["dropout"],
).to(args["device"])
g = [graph.to(args["device"]) for graph in g]
stopper = EarlyStopping(patience=args["patience"])
loss_fcn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
model.parameters(), lr=args["lr"], weight_decay=args["weight_decay"]
)
for epoch in range(args["num_epochs"]):
model.train()
logits = model(g, features)
loss = loss_fcn(logits[train_mask], labels[train_mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc, train_micro_f1, train_macro_f1 = score(
logits[train_mask], labels[train_mask]
)
val_loss, val_acc, val_micro_f1, val_macro_f1 = evaluate(
model, g, features, labels, val_mask, loss_fcn
)
early_stop = stopper.step(val_loss.data.item(), val_acc, model)
print(
"Epoch {:d} | Train Loss {:.4f} | Train Micro f1 {:.4f} | Train Macro f1 {:.4f} | "
"Val Loss {:.4f} | Val Micro f1 {:.4f} | Val Macro f1 {:.4f}".format(
epoch + 1,
loss.item(),
train_micro_f1,
train_macro_f1,
val_loss.item(),
val_micro_f1,
val_macro_f1,
)
)
if early_stop:
break
stopper.load_checkpoint(model)
test_loss, test_acc, test_micro_f1, test_macro_f1 = evaluate(
model, g, features, labels, test_mask, loss_fcn
)
print(
"Test loss {:.4f} | Test Micro f1 {:.4f} | Test Macro f1 {:.4f}".format(
test_loss.item(), test_micro_f1, test_macro_f1
)
)3.2 模型
HAN
- num_meta_paths:元路径数量,2个pap和plp
- in_size:1870,特征维度
- hidden_size: 8
- out_size: 3,label类别数
- num_heads: 8 ,
- dropout:0.6
python
class HAN(nn.Module):
def __init__(
self, num_meta_paths, in_size, hidden_size, out_size, num_heads, dropout
):
super(HAN, self).__init__()
self.layers = nn.ModuleList()
self.layers.append(
HANLayer(
num_meta_paths, in_size, hidden_size, num_heads[0], dropout
)
)
for l in range(1, len(num_heads)):
self.layers.append(
HANLayer(
num_meta_paths,
hidden_size * num_heads[l - 1],
hidden_size,
num_heads[l],
dropout,
)
)
self.predict = nn.Linear(hidden_size * num_heads[-1], out_size)
def forward(self, g, h):
for gnn in self.layers:
h = gnn(g, h)
return self.predict(h)HANLayer
- 节点级注意力:GATConv
- 2个元路径,对应2个gat,这个大家可以回想一下,之前gat的讲解,一个元路径可以理解为一个图,一个图里面之前对应了一个gat。
- 语义级注意力: SemanticAttention
python
class HANLayer(nn.Module):
"""
HAN layer.
Arguments
---------
num_meta_paths : number of homogeneous graphs generated from the metapaths.
in_size : input feature dimension
out_size : output feature dimension
layer_num_heads : number of attention heads
dropout : Dropout probability
Inputs
------
g : list[DGLGraph]
List of graphs
h : tensor
Input features
Outputs
-------
tensor
The output feature
"""
def __init__(
self, num_meta_paths, in_size, out_size, layer_num_heads, dropout
):
super(HANLayer, self).__init__()
# One GAT layer for each meta path based adjacency matrix
self.gat_layers = nn.ModuleList()
for i in range(num_meta_paths):
self.gat_layers.append(
GATConv(
in_size,
out_size,
layer_num_heads,
dropout,
dropout,
activation=F.elu,
)
)
self.semantic_attention = SemanticAttention(
in_size=out_size * layer_num_heads
)
self.num_meta_paths = num_meta_paths
def forward(self, gs, h):
semantic_embeddings = []
for i, g in enumerate(gs):
semantic_embeddings.append(self.gat_layers[i](g, h).flatten(1))
semantic_embeddings = torch.stack(
semantic_embeddings, dim=1
) # (N, M, D * K)
return self.semantic_attention(semantic_embeddings) # (N, D * K)节点级注意力:GATConv(调用dgl库,本次不做重点讲解,之后单独出一篇讲解)
- 原理可以先参考:图神经网络分享系列-GAT(GRAPH ATTENTION NETWORKS) (四)-实战篇
- 最终目标:获取节点对应的向量
语义级注意力: SemanticAttention
- 输入z shape: (N, M, D * K)
- N: 节点个数
- M:元路径个数
- D:每个头的维度
- K:头数
- 输出 (N,D*K)
- 细节:
- 第一步:计算元路径重要性分数
- 这里的project就是论文中w的公式,也就是元路径重要性分数
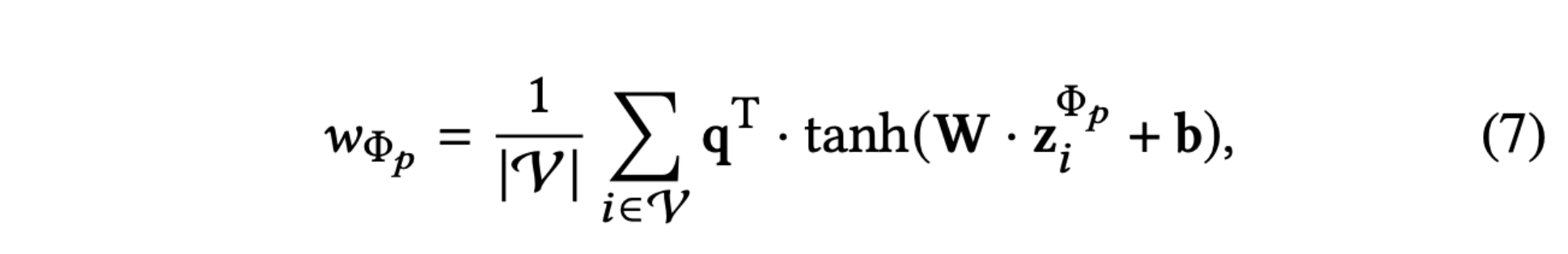
- project:linear->tanh->linear
- z(N, M, D * K) ->(N,M,1)
- mean(0):(N,M,1)->(M,1)
- project:linear->tanh->linear
- 第二步:归一化得到注意力权重
softmax(dim=0): 对M个元路径的分数进行归一化- 得到
beta: 各元路径的重要性权重,和为1 →(M, 1)
- 第三步:扩展权重维度
- 将
(M, 1)扩展为(N, M, 1) - 让每个节点都能使用相同的元路径权重进行加权
- 将
- 第四步:加权求和
-
beta * z: 注意力权重 × 元路径嵌入 →(N, M, D*K) .sum(1): 对元路径维度(M)求和 →(N, D*K)
-
- 第一步:计算元路径重要性分数
python
class SemanticAttention(nn.Module):
def __init__(self, in_size, hidden_size=128):
super(SemanticAttention, self).__init__()
self.project = nn.Sequential(
nn.Linear(in_size, hidden_size),
nn.Tanh(),
nn.Linear(hidden_size, 1, bias=False),
)
def forward(self, z):
w = self.project(z).mean(0) # (M, 1)
beta = torch.softmax(w, dim=0) # (M, 1)
beta = beta.expand((z.shape[0],) + beta.shape) # (N, M, 1)
return (beta * z).sum(1) # (N, D * K)结果:

|---------|----------------|----------------|
| | micro f1 score | macro f1 score |
| dgl-han | 0.8748 | 0.8744 |
至此HAN代码就完成讲解,本次没有细节讲解dgl框架下的gat卷积,之前提到过,后续专门出一篇讲解dgl框架的。
其实我们会发现,han还是比较好理解的,从实现上就是gat+语义注意力~