1、深度学习简介
1.1 什么是深度学习?
机器学习是实现人工智能的一种途径
深度学习是机器学习的一个子集,也就是说深度学习是实现机器学习的一种方法。
1.2 深度学习与机器学习对比
传统机器学习算术依赖人工设计特征,并进行特征提取
深度学习方法不需要人工,而是依赖算法自动提取特征。 深度学习模仿人类大脑的运行方式,从经验中学习获取知识。深度学习被看做黑盒子,可解释性差。
1.3 深度学习优缺点
优点:
① 精度高,性能优于其它机器学习方法,在某些领域领先人类
② 可以拟合任意的非线性函数(例如:用户提问与回答之间)
③ 有大量的框架和库可供调用
缺点:
① 黑箱,人类不清楚模型如何工作
② 训练时间长,需要大量的算力
③ 网络结构复杂,需要调整超参数
④ 小数据表现不佳,容易过拟合
2、Pytorch框架
2.1 概念:
一个 Python 深度学习框架,它将数据封装成张量(Tensor)来进行处理
PyTorch 中的张量就是元素为同一种数据类型的多维矩阵。在 PyTorch 中,张量以 "类" 的形式封装起来,对张量的一些运算、处理的方法被封装在类中
2.2 张量(tensor)是什么?
本质是一个多维数组, 数组的另一个名字**,可以在CPU和GPU进行计算。**在深度学习、人工智能及数值计算领域(如使用 PyTorch、TensorFlow 等框架时)
张量主要用于存储和处理数据,并不一定附带几何或物理上的变换约束
具体表现为:
- 0维张量:标量(Scalar),即一个单独的数值。
- 1维张量:向量(Vector),一组有序的数。
- 2维张量:矩阵(Matrix),由行和列组成的二维表格。
- 3维及以上张量:高维数组
张量与ndarry对比:
ndarry不能在GPU上进行运算,只能在CPU上进行运算
两者本质上都是数组
2.3 张量的操作
2.3.1 张量的创建
2.3.1.1 【掌握】张量的创建方法
【掌握】torch.tensor 根据指定数据创建张量
【了解】torch.Tensor 根据形状创建张量, 其也可用来创建指定数据的张量
【了解】torch.IntTensor、torch.FloatTensor、torch.DoubleTensor 创建指定类型的张量
python
import numpy as np
import torch
# torch.tensor() 根据指定数据创建张量
print("torch.tensor():------>")
# 向量
data = np.random.randn(2, 3)
data = torch.tensor(data)
print(data)
# 矩阵
data = [[10., 20., 30.], [40., 50., 60.]]
torch.tensor(data)
print(data)
# torch.Tensor() 根据指定形状创建张量,也可以用来创建指定数据的张量
print("torch.Tensor():------>")
data = torch.Tensor(2, 3)
print(data)
data = torch.Tensor([10, 20])
print(data)
# torch.IntTensor()、torch.FloatTensor()、torch. 创建指定类型的张量
print("IntTensor(),FloatTensor(),DoubleTensor():------>")
data = torch.IntTensor(2, 3)
print(data)
# 注意: 如果传递的元素类型不正确, 则会进行类型转换
data = torch.IntTensor([2.5, 3.3])
print(data)
data = torch.FloatTensor([2.1, 3.2])
print(data)2.3.1.2 【了解】线性和随机张量的创建方法
torch.arange 和 torch.linspace 创建线性张量
torch.random.init_seed 和 torch.random.manual_seed 随机种子设置
torch.randn 创建随机张量
python
import torch
# 1. 在指定区间按照步长生成元素 [start, end, step)
data1 = torch.arange(1, 10, 2)
print(data1)
# 1. 在指定区间按照步长生成元素 [start, end, step)
data = torch.linspace(1, 10, 9)
print(data)
# 1. 创建随机张量
data = torch.randn(2,3)
print(data)
# 查看随机数种子
print('随机数种子:', torch.random.initial_seed())
# 2. 随机数种子设置
torch.random.manual_seed(100)
data = torch.randn(2, 3)
print(data)
print('随机数种子:', torch.random.initial_seed())2.3.1.3【了解】0-1张量的创建方法
torch.ones 和 torch.ones_like 创建全1张量
torch.zeros 和 torch.zeros_like 创建全0张量
torch.full 和 torch.full_like 创建全为指定值张量
python
import torch
data1 = torch.arange(1, 10, 2)
print(data1)
# # 1. 创建指定形状全0张量
data = torch.zeros(2, 3)
print(data)
# 2. 根据张量形状创建全0张量
data = torch.zeros_like(data1)
print(data)
# 1. 创建指定形状全1张量
data2 = torch.ones(3, 4)
print(data2)
# 2. 根据张量形状创建全1张量
data = torch.ones_like(data)
print(data)
# 1. 创建指定形状指定值的张量
data = torch.full([2, 3], 10)
print(data)
# 2. 根据张量形状创建指定值的张量
data = torch.full_like(data, 20)
print(data)2.3.1.4【了解】张量元素类型的转换方法
data.type(torch.DoubleTensor)
data.double()
python
import torch
data1 = torch.randn([2, 3])
print(data1)
# int16
# data = data1.type(torch.ShortTensor)
data = data1.short()
print(data)
# int32
# data = data1.type(torch.IntTensor)
data = data1.int()
print(data)
# int64
data = data1.type(torch.LongTensor)
# data = data1.long()
print(data)
# float 64
# data = data1.type(torch.DoubleTensor)
data = data.double()
print(data)2.3.2 【掌握】张量的类型转换
为什么要进行转换?
转换后的张量,可以使用pandas、metplotlab、nump的方法,进行数据处理
转换后的Numpy数组,可以使用torch中的方法,数据可以在GPU上处理
2.3.2.1 【掌握】张量转换为Numpy数组的方法
使用Tensor.numpy()函数可以将张量转换为ndarray数组,但是共享内存,可以使用copy()函数避免共享
python
import torch
torch.random.manual_seed(22)
data_tensor = torch.randint(0, 9, (2, 3))
print(data_tensor)
# data_ndarray = data_tensor.numpy()
# 使用copy()之后,更改ndarray数据不会影响原tensor数据
data_ndarray = data_tensor.numpy().copy()
print(type(data_ndarray))
print(data_ndarray)
data_ndarray[1, 1] = 3
print("data_ndarray:\n",data_ndarray)
print("data_tensor:\n",data_tensor)
# 输出
'''
tensor([[2, 7, 1],
[3, 7, 2]])
<class 'numpy.ndarray'>
[[2 7 1]
[3 7 2]]
data_ndarray:
[[2 7 1]
[3 3 2]]
data_tensor:
tensor([[2, 7, 1],
[3, 7, 2]])
'''2.3.2.2 【掌握】Numpy数组转换为张量的方法
① 使用 from_numpy 可以将 ndarray 数组转换为 Tensor,默认共享内存,使用 copy 函数避免共享。
torch.from_numpy(data_numpy)
torch.from_numpy(data_numpy.copy())
② 使用 torch.tensor 可以将 ndarray 数组转换为 Tensor,默认不共享内存。
python
import torch
import numpy as np
# 2、ndarray转tensor
data = np.arange(9)
# print(data)
data_ndarray = data.reshape(3, 3)
print(data_ndarray)
# 方法一
# data_tensor = torch.from_numpy(data_ndarray)
data_tensor = torch.from_numpy(data_ndarray.copy())
print(data_tensor)
# 方法二
data_tensor = torch.tensor(data_ndarray)
print(data_tensor)
'''
输出:
[[0 1 2]
[3 4 5]
[6 7 8]]
tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
'''2.3.2.3【掌握】标量张量和数字转换方法
对于只有一个元素的张量,使用item()函数将该值从张量中提取出来
python
import torch
data = torch.tensor([3])
print(data)
print(data.item())
# 输出
'''
tensor([3])
3
'''2.3.3 【掌握】张量的数值计算
张量基本运算
加减乘除取负号: add、sub、mul、div、neg
add_、sub_、mul_、div_、neg_(其中带下划线的版本会修改原数据)
python
import torch
torch.random.manual_seed(22)
data = torch.randint(1, 10, (3, 3))
# 基本运算
# 加
new_data = data.add(10)
data.add_(10)
print(data)
print(new_data)
# 减
new_data = data.sub(10)
data.sub_(10)
print(data)
print(new_data)
# 乘
new_data = data.mul(10)
data.mul_(10)
print(data)
print(new_data)
# 除
data1 = data.float()
new_data = data1.div(10)
data1.div_(10)
print(data1)
print(new_data)
# 取负
new_data = data.neg()
data.neg_()
print(data)
print(new_data)
'''
输出:
tensor([[3, 8, 2],
[4, 8, 3],
[3, 2, 3]])
tensor([[3, 8, 2],
[4, 8, 3],
[3, 2, 3]])
tensor([[30, 80, 20],
[40, 80, 30],
[30, 20, 30]])
tensor([[30, 80, 20],
[40, 80, 30],
[30, 20, 30]])
tensor([[3., 8., 2.],
[4., 8., 3.],
[3., 2., 3.]])
tensor([[3., 8., 2.],
[4., 8., 3.],
[3., 2., 3.]])
tensor([[-30, -80, -20],
[-40, -80, -30],
[-30, -20, -30]])
tensor([[-30, -80, -20],
[-40, -80, -30],
[-30, -20, -30]])
'''张量点乘运算
点乘指(Hadamard)的是两个同维矩阵对应位置的元素相乘,使用mul 和运算符 * 实现
方法一:mul(a,b)
方法二:a*b
广播机制:
python
# 点乘
torch.random.manual_seed(50)
a = torch.tensor([[1, 2, 3], [4, 5, 6]])
b = torch.tensor([[3, 4, 5], [5, 7, 9]])
c = torch.randint(1, 9, [3, 3, 2])
d = torch.randint(1, 9, [3])
e = torch.randint(1, 9, [3, 2])
print(c)
print(a*b)
print(a*d)
print(c*e)
# 方法二:
print(torch.mul(a, b))张量矩阵乘法运算
矩阵乘法运算要求第一个矩阵 shape: (n, m),第二个矩阵 shape: (m, p), 两个矩阵点积运算 shape 为: (n, p)。要求第一个矩阵行数与第二个矩阵列数相同
运算方法:
方法一:运算符 @ 用于进行两个矩阵的乘积运算
方法二:torch.matmul 对进行乘积运算的两矩阵形状没有限定.对数输入的 shape 不同的张量, 对应的最后几个维度必须符合矩阵运算规则
python
# 矩阵乘法
A = torch.randint(1, 9, [3, 2])
B = torch.randint(1, 9, [2, 3])
print(A@B)
C = torch.randint(1, 9, [2, 3, 2])
D = torch.randint(1, 9, [2, 3])
print(torch.matmul(C, D))
# 输出
'''
tensor([[19, 9, 13],
[40, 30, 20],
[77, 42, 49]])
tensor([[[ 63, 24, 44],
[ 98, 38, 70],
[112, 40, 72]],
[[ 91, 34, 62],
[ 84, 33, 61],
[ 70, 34, 66]]])
'''2.3.4 张量运算函数
均值(mean()) 、平方根(sqrt())、 求和(sum()) 、指数计算(pow(data,n次方)) 、对数(log())计算等等
注意:mean()只能处理Float 或者 Double 类型
python
import torch
data = torch.tensor([[4, 5, 6], [6, 7, 8]])
print(data)
# mean()只能处理Float 或者 Double 类型
data1 = data.float()
# 求平均值
print(data1.mean())
# 按列求平均值
print(data1.mean(dim=0))
# 按行求平均值
print(data1.mean(dim=1))
torch.random.manual_seed(50)
# 计算总和
data2 = torch.randint(1, 4, [2, 3, 4])
print(data2)
print(data2.sum())
# 求矩阵间的和 add
print(data2.sum(dim=0))
# 按列求和
print(data2.sum(dim=1))
# 按行求和
print(data2.sum(dim=2))
# 计算平方
print(torch.pow(data, 2))
# 计算平方根
print(data.sqrt())
# 5. 指数计算, e^n 次方,n为data中的每个元素
print(data.exp())
# 6. 对数计算
print(data.log())
print(data.log2())
print(data.log10())2.3.5 张量索引操作
【掌握】简单行列索引的使用
python
import torch
torch.random.manual_seed(22)
data = torch.randint(1, 9, [4, 5])
print(data)
# 取第2行数据
print(data[1])
# 取第2列数据
print(data[:, 1])
# 取第2,3,4行,第2,3,4列
print(data[1:, 1:5])
# 取从第1行开始步长为2,从第2列开始步长为2
print(data[::2, 1::2])【掌握】列表索引的使用
python
# 列表切片
# 取第索引为2,3的行,索引为3,4的行
print(data[[[2], [3]], [3, 4]])
# 取索引为 [2,3] [3,4] 的数据
print(data[[2, 3], [3, 4]])【了解】布尔索引的使用
python
# 布尔类型
# 第三列小于3的行
print(data[data[:, 2] < 3])
# 取第2行大于5的1:3 行
print(data[1:3, data[1] > 5])
# 第二行大于3的列
print(data[:, data[1] > 3])
# 取第三列大于3的,第2、3、4列
print(data[data[:, 2] > 3, 1:4])【了解】多维索引的使用
python
torch.random.manual_seed(22)
data = torch.randint(1, 9, [3, 4, 5])
print(data)
# 取第3个数组,1:3 行,2:4 列
print(data[2, 1:3, 2:4])
# 取第3个数组,1: 行,:4 列
print(data[2, 1:, :4])
# 取所有数组,1:3 行,2:4 列
print(data[:, 1:3, 2:4])
# 取所有数组,第2行,1: 列 步长为2
print(data[:, 1, 1::2])
# 取最后一个数组的,最后一行的,第四列数据
print(data[-1, -1, 3])2.3.6 张量形状操作
| API | 作用 |
|---|---|
| shape | 获取张量的形状 |
| size() | 获取张量的形状 |
| reshape() | 元素个数不变的情况下,改变张量形状 |
| squeze() | 函数删除形状为 1 的维度(降维 |
| unsqueeze() | 添加形状为1的维度(升维) |
| transpose() | 交换张量形状的指定维度 例如: 一个张量的形状为 (2, 3, 4) 可以通过 transpose 函数把 3 和 4 进行交换, 将张量的形状变为 (2, 4, 3) |
| permute() | 可以一次交换更多的维度 |
| view() | 【了解】相当于reshape,只能用于存储在整块内存中的张量 |
| contiguous() | 将张量转换到整块内存中 data.is_contiguous() 判断张量内存是否连续 |
python
import torch
data = torch.randint(1, 9, [3, 4, 5])
print(data)
# 1、查看张量形状
print(data.shape)
# 查看一维数据的类型
print(data.shape[0])
# 查看张量形状
print(data.size())
# 查看最后一维数据的类型
print(data.size(-1))
# 2、重塑形状
print(data.reshape(2, 5, 6))
print(data.reshape(3, 10, -1))
# 转换为2维
print(data.reshape(4, 15))
data = torch.randint(1, 9, [1, 4, 5])
print(data)
# 3、更改维度
# 在第三维添加一个维度为1的
print(data.unsqueeze(dim=2).shape)
# 在第最后一维添加一个维度为1的
print(data.unsqueeze(dim=-1).shape)
data = data.unsqueeze(dim=-1)
# print(data)
# 删除形状为 1 的维度
print(data.squeeze().shape)
# 4、交换维度
print(data.shape)
# transpose只能交换一对
print(data.transpose(1, 2).shape)
# permute可以一次交换更多的维度
print(data.permute(1, 2, 0).shape)
# 5、view和contiguous
# view方法处理时,内存地址必须连续
if data.is_contiguous():
print(data.view(2, 5, 6).shape)
else:
print(data.contiguous().view(2, 5, 6).shape)reshape与tranpose、premute的区别?
reshape是将向量先展平为一维向量,然后再依次按照顺序,生成多维向量
transpose相当于矩阵的转置操作
python
import torch
data1 = torch.randint(1, 9, [2, 3])
print(data1)
print(data1.transpose(1, 0))
print(data1.reshape(3, 2))
'''
输出:
tensor([[6, 1, 2],
[1, 6, 4]])
tensor([[6, 1],
[1, 6],
[2, 4]])
tensor([[6, 1],
[2, 1],
[6, 4]])
'''2.3.7 张量拼接操作
torch.cat()函数可以将两个张量根据指定的维度拼接起来,不改变维度数
python
import torch
data1 = torch.randint(0, 10, [1, 2, 3])
data2 = torch.randint(0, 10, [1, 2, 3])
print('data1:\n',data1)
print("data2:\n",data2)
# 1. 按0维度拼接
new_data = torch.cat([data1, data2], dim=0)
print("new_data:\n",new_data)
print(new_data.shape)
# 按照1维度进行拼接
new_data2 = torch.cat([data1, data2], dim=1)
print("new_data2:\n",new_data2)
print(new_data2.shape)
'''
data1:
tensor([[[9, 5, 5],
[7, 6, 4]]])
data2:
tensor([[[8, 5, 4],
[1, 2, 8]]])
new_data:
tensor([[[9, 5, 5],
[7, 6, 4]],
[[8, 5, 4],
[1, 2, 8]]])
torch.Size([2, 2, 3])
new_data2:
tensor([[[9, 5, 5],
[7, 6, 4],
[8, 5, 4],
[1, 2, 8]]])
torch.Size([1, 4, 3])
'''2.4 自动微分模块
为什么要自动微分?
神经网络的训练本质上是一个不断更新参数的过程,而更新参数必须依赖**"损失函数对参数的梯度"**。手动计算这些导数不仅极其耗时,还非常容易出错。PyTorch 的 Autograd 模块能够高效、准确地自动完成这一工作。
作用:
PyTorch 用来**自动计算梯度(导数)**的引擎,无需手动编写复杂的求导公式
如何工作的?
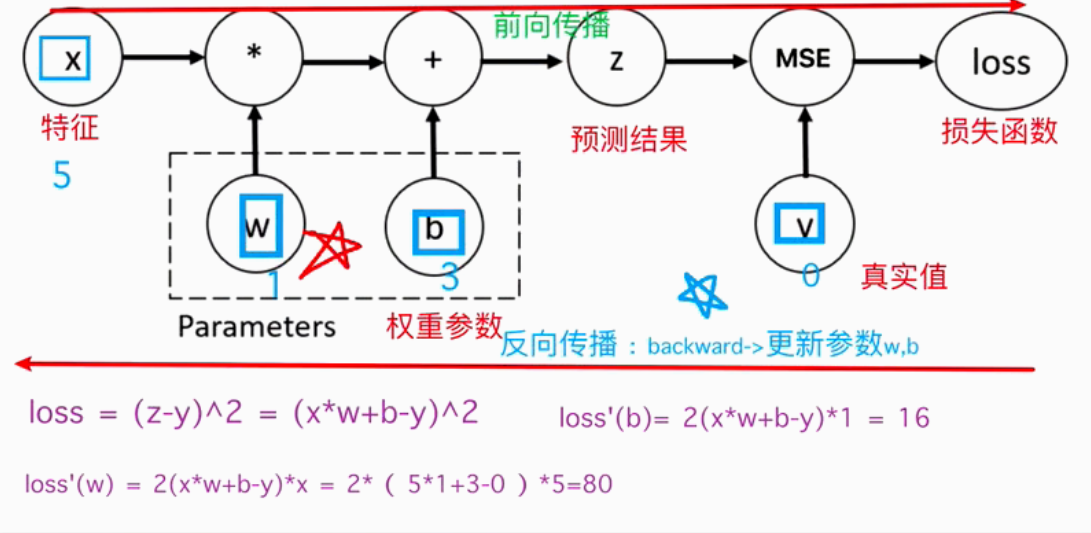
PyTorch 采用的是反向模式自动微分,其核心原理是构建并追踪一个"动态计算图"
① 正向传播(构建图):由特征值、初始化w、b,求损失函数的过程
② 反向传播(求导):损失函数使用对应的梯度,更新参数 w 和 b过程。
loss(损失值)调用.backward() 方法,会进行求导、并计算出梯度。计算完成后,梯度会自动累积并保存在对应张量的 .grad 属性中
梯度手动计算过程:
x = 5,w0 = 1,b =3,y=0
loss = (w*x + b - y) ^2
loss`(w) = 2(w*x + b - y) * x = 2(1*5+3 -0)*5 = 80
loss`(b) = 2(w*x + b - y) *1 = 2(1*5+3 -0) = 16
如何使用自动微分?
- 开启跟踪 :只有设置了
requires_grad=True的张量才会被加入计算图并参与求导。 - 触发求导 :在得到最终结果后,调用
.backward()即可触发反向传播。 - 获取梯度 :计算完成后,梯度会自动累积并保存在对应张量的
.grad属性中。 - 节省内存 :默认情况下,非叶子节点(中间运算产生的张量)不会保存梯度以节省内存;如果需要在推理阶段完全停止跟踪梯度,可以使用
torch.no_grad()上下文管理器或detach()方法。
代码实现自动微分:
python
import torch
# 特征值
x = torch.tensor(5.,dtype=torch.float32)
# 初始化w,b
w = torch.tensor(1., requires_grad=True, dtype=torch.float32)
b = torch.tensor(5., requires_grad=True, dtype=torch.float32)
# 预测值
z = w * x + b
# 真实值
y = torch.tensor(0., requires_grad=True, dtype=torch.float32)
# 损失函数
mse = torch.nn.MSELoss()
loss = mse(y, z)
# 反向传播
loss.backward()
# 梯度
print(w.grad)
print(b.grad)当x、w、b、y为矩阵时
python
import torch
# 特征值
x = torch.ones([4, 3], dtype=torch.float32)
# 初始化w,b
w = torch.randn([3, 2], requires_grad=True, dtype=torch.float32)
b = torch.ones(2, requires_grad=True, dtype=torch.float32)
# 预测值
z = x @ w + b
# 真实值
y = torch.zeros([4, 2], requires_grad=True, dtype=torch.float32)
# 损失函数
mse = torch.nn.MSELoss()
loss = mse(y, z)
# 反向传播
loss.backward()
# 梯度
print(w.grad)
print(b.grad)2.5 案例-线性回归案例
实现步骤:
准备训练集数据
构建要使用的模型
设置损失函数和优化器
模型训练
模型训练步骤:
① 构建损失函数 :mse = nn.MSELoss()
② 优化器:optimizer = optim.SGD(params=model.parameters(), lr=1e-2)
③ 遍历:
④ 模型预测:model(x_tensor.float32)
⑤ 计算损失:mse(y_pred, y_tensor.reshape(-1, 1).type(torch.float32))
⑥ 梯度清零: optimizer.zero_grad()
⑦ 自动微分,更新参数:loss.backward()、optimizer.step()
代码实现:
python
from sklearn.datasets import make_regression
import torch
import matplotlib.pyplot as plt
import matplotlib
from torch.utils.data import TensorDataset, DataLoader
matplotlib.use("TkAgg")
x, y, coef = make_regression(
n_samples=100,
n_features=1,
noise=10,
coef=True,
bias=1.5,
random_state=50
)
# 构造数据集对象
dataset = TensorDataset(torch.tensor(x), torch.tensor(y))
dataloader = DataLoader(dataset=dataset, batch_size=16, shuffle=True) # batch_size=:批量训练样本数据,shuffle=:样本数据是否进行乱序
# for x_tensor, y_tensor in dataloader:
# print(x_tensor.shape)
# print(y_tensor.shape)
# break
# 模型构建
model = torch.nn.Linear(in_features=1, out_features=1)
# 模型训练
# ① 构建损失函数
mse = torch.nn.MSELoss()
# ② 优化器
optimizer = torch.optim.SGD(params=model.parameters(), lr=0.01)
# ③ 遍历
loss_list = []
epochs = 20
iter_num = 0
loss_sum = 0
for epoch in range(epochs):
for x_tensor, y_tensor in dataloader:
# ④ 模型预测
y_pred = model(x_tensor.type(torch.float32))
# ⑤ 计算损失
loss = mse(y_pred, y_tensor.reshape(-1, 1).type(torch.float32))
iter_num += 1
loss_sum += loss.item()
# ⑥ 梯度清零
optimizer.zero_grad()
# ⑦ 自动微分,更新参数
loss.backward() # 计算梯度
optimizer.step() # 更新梯度
loss_list.append(loss_sum/(iter_num+0.001))
# plt.plot(range(len(loss_list)),loss_list)
# plt.show()
# 绘图比对预测值与真实值差异
plt.scatter(x, y)
y_true = x * coef + 1.5
# detach 将一个开启了自动微分(梯度追踪)的模型权重张量,安全地转换为 NumPy 数组
y_pred = x * model.weight.detach().numpy() + model.bias.detach().numpy()
plt.plot(x, y_true, c="blue")
plt.plot(x, y_pred, c="black")
plt.show()问题与思考:
1、loss_sum 为什么要处理 (iter_num+0.1)
① 因为前边代码中 loss_sum += loss.item(),loss_sum在一直进行累加,所以在后边 loss_list.append loss_sum时,要除以迭代次数
② 为什么不是 loss_list.append(loss.item()),而是 loss_list.append (loss_sum/(iter_num+ 0.001))?
直接使用 loss.item() 每一次的损失值绘图的话,图形的变化会比较大。使用 loss_sum / (iter_num + 0.001)图形会比较平滑,可以有效的显示与之前损失值的变化趋势
③ 为什么需要使用loss_sum/(iter_num+0.001),而不是 loss_sum/(iter_num)?
计算平均值的标准做法是直接除以迭代次数(即 loss_sum / iter_num)。代码中写成 iter_num + 0.1,主要是出于一种工程上的"防御性编程"考虑------为了防止在极少数情况下 iter_num 为 0 时触发"除以零"的错误。不过,既然你的代码在累加前已经执行了 iter_num += 1,那么 iter_num 至少为 1,此时加上 0.1 其实并不是必须的,它只是让分母稍微大了一点点,对最终的平均值结果影响微乎其微。
2、optimizer.step() 作用?优化器是什么?
optimizer = torch.optim.SGD(params=model.parameters(), lr=0.01)
loss = mse(y_pred, y_tensor.reshape(-1, 1).type(torch.float32)) # ⑤ 计算损失
loss.backward() # 计算梯度
optimizer.step() # 更新梯度
optimizer = torch.optim.SGD(params=model.parameters(), lr=0.01) 创建一个**随机梯度下降(SGD)优化器对象,**optimizer.step() 利用 loss.backward() 计算出的梯度来更新模型的参数,从而让模型的损失函数逐渐减小
使用步骤:
① 记录待优化的参数与超参数
初始化时,优化器会"记住"你需要更新的模型权重和偏置(即 model.parameters()),以及控制参数更新步长的学习率(lr=0.001)。
②执行参数更新(核心功能)
这是 SGD 优化器最本质的工作。它并不负责计算梯度(梯度由反向传播 loss.backward() 计算),而是负责根据已有的梯度去修改参数。当你调用 optimizer.step() 方法时,它会按照公式 新参数 = 旧参数 - 学习率 × 梯度 自动完成所有参数的更新1。
③ 提供工程辅助方法
由于 PyTorch 的自动微分机制默认会累加梯度,为了防止梯度重复计算导致错误,优化器还提供了 optimizer.zero_grad() 方法。这相当于一个"清零按钮",用于在每次迭代前清除上一步残留的梯度信息2。
3、model.bias.detach().numpy() 中detach作用?
model.bias 通常默认开启了自动微分(即 requires_grad=True),以便在反向传播时计算梯度。PyTorch 规定:不能直接对带有梯度追踪的张量调用 .numpy() 方法 ,否则会抛出如下错误:
Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.
使用 detach() 可以将该张量从当前的计算图中分离出来,从而解除这个转换限制。