📖标题:AdaMem: Adaptive User-Centric Memory for Long-Horizon Dialogue Agents
🌐来源:arXiv, 2603.16496v1
🌟摘要
大型语言模型(LLM)智能体越来越依赖外部记忆来支持长距离交互、个性化辅助和多步推理,但现有的记忆系统仍然面临三个核心挑战:过于依赖语义相似性,这可能会错过以用户为中心理解的关键证据;本文提出了一个面向长时间对话Agent的自适应的以用户为中心的记忆框架AdaMem,它将对话历史组织成工作记忆、情景记忆、人物记忆和图形记忆,使系统能够保存最近的上下文、结构化的长期体验、稳定的用户特征在推理时,AdaMem首先解析目标参与者,然后构建一个问题条件检索路径,仅在需要时才将语义检索与关系感知图扩展相结合,最后通过一个角色产生答案-证据合成和响应生成的专用管道。我们在LoCoMo和PERSONAMEM基准上评估AdaMem,水平推理和用户建模。实验结果表明,AdaMem在两个基准测试中都达到了最先进的性能。代码将在验收后发布。
🛎️文章简介
🔸研究问题:现有大模型代理的记忆系统如何克服过度依赖语义相似、缺乏时空连贯性及粒度静态化这三大挑战,以支持长程对话中的精准推理?
🔸主要贡献:论文提出了 AdaMem 框架,通过构建四类互补记忆结构及多智能体协作检索机制,在长程推理基准上实现了最先进性能。
📝重点思路
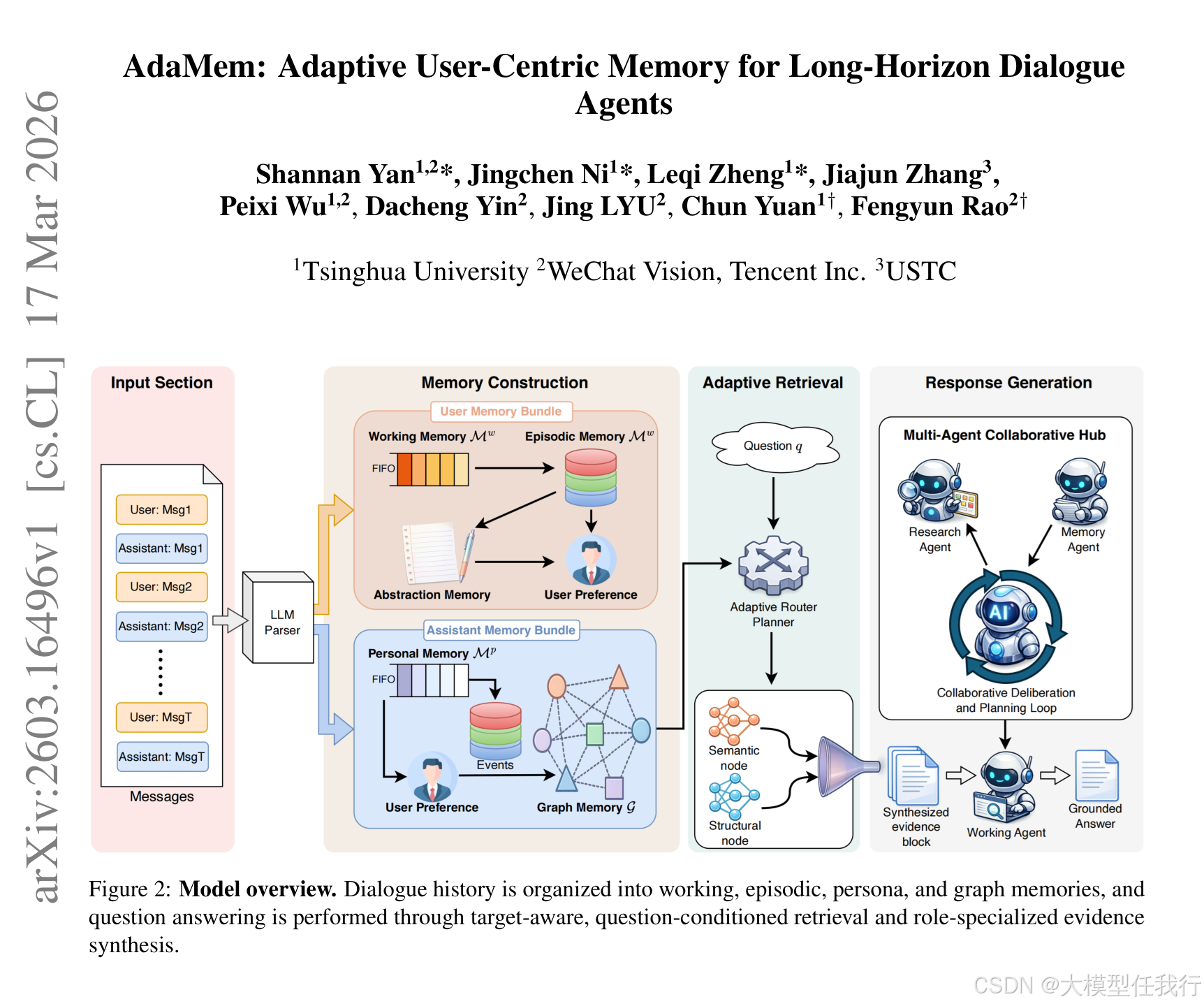
🔸构建包含工作记忆、情景记忆、人设记忆和图记忆的四层异构存储体系,分别用于维持近期上下文、结构化长期经历、稳定用户特征及关系感知连接。
🔸设计基于参与者的记忆组织方式,将对话历史按用户和助手分离存储,确保在多方对话中能精准定位目标对象并提取专属信息。
🔸实施问题条件的检索规划策略,先解析目标参与者,再根据问题类型动态决定是否启用关系感知的图扩展检索,避免不必要的计算开销。
🔸采用多智能体协作流水线,由记忆代理负责标准化写入与更新,研究代理执行迭代式证据搜集与反思,工作代理专注于综合证据生成最终回答。
🔎分析总结
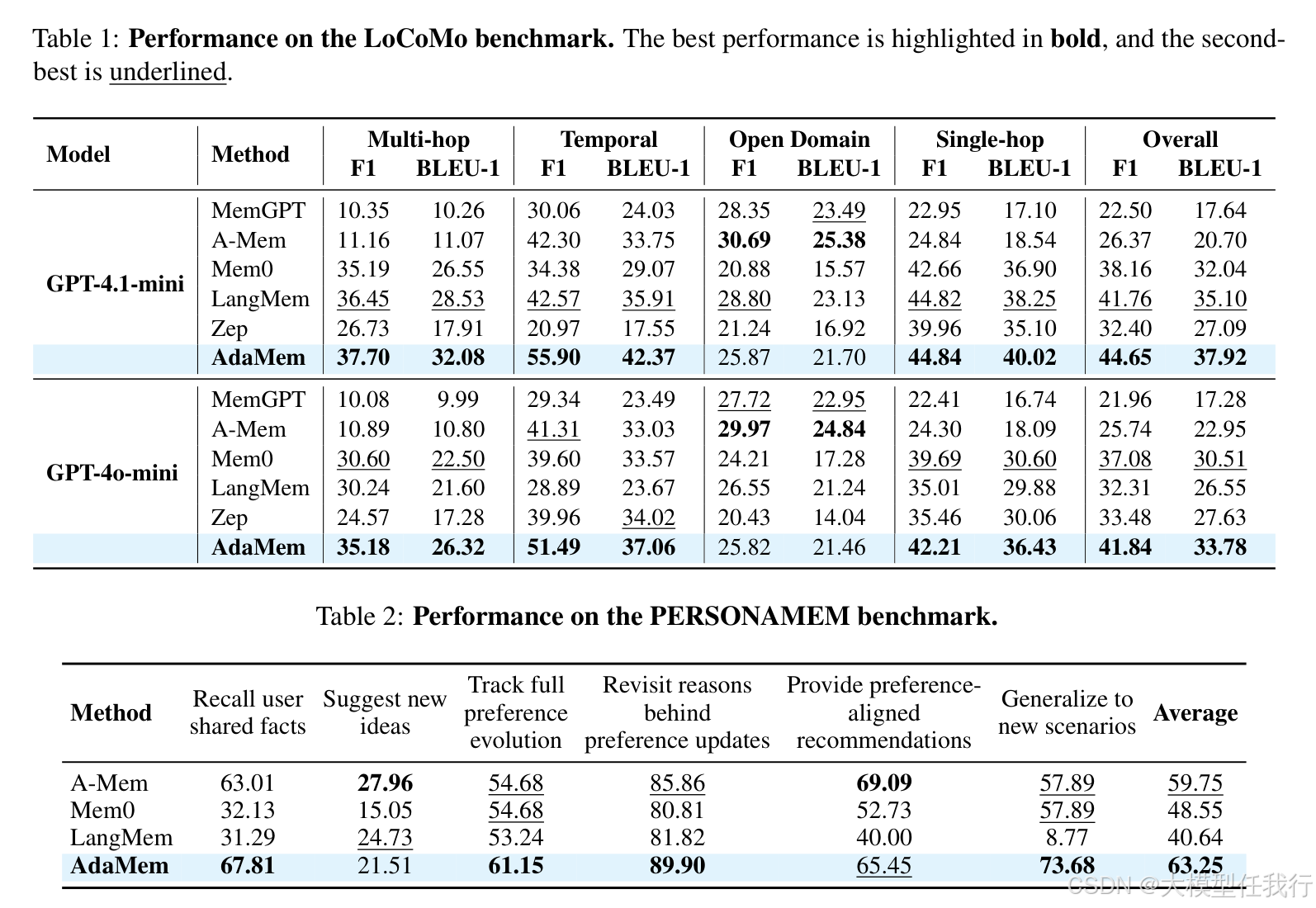
🔸实验表明 AdaMem 在 LoCoMo 和 PERSONAMEM 基准上均达到最先进水平,特别是在时序推理任务上相比基线方法有显著提升。
🔸消融实验证实图记忆组件贡献最大,移除后性能下降明显,证明关系感知对于恢复跨轮次依赖和因果链条至关重要。
🔸多智能体分工机制有效减少了记忆维护与推理生成的相互干扰,使得证据合成更加精准,且框架在不同规模模型上均表现出良好的泛化性。
🔸超参数分析显示适度的检索数量和有限的迭代次数即可达到最佳效果,过多的证据积累反而引入噪声导致性能微降。
💡个人观点
论文打破了传统单一语义检索的局限,将结构化图记忆与动态检索规划相结合。
🧩附录