摘要
本文对机器学习的基础概念进行了系统性回顾。文章阐述了人工智能、机器学习与深度学习三者之间的层级关系,区分了基于规则与基于模型两种学习方式。进一步介绍了机器学习发展的三要素(数据、算法、算力)及常用术语(样本、特征、标签等)。文中总结了有监督、无监督、半监督与强化学习四类主要算法,并梳理了从数据获取到模型评估的完整建模流程。此外,还探讨了拟合问题的类型与泛化能力,并简要介绍了Scikit-learn开发环境。本文为理解机器学习提供了全面的知识框架。
Abstract
This article provides a systematic review of fundamental concepts in machine learning. It explains the hierarchical relationships among artificial intelligence, machine learning, and deep learning, distinguishing between rule-based and model-based learning approaches. The three essential elements of machine learning development---data, algorithms, and computing power---are introduced alongside common terminology such as samples, features, and labels. The article summarizes four main categories of algorithms: supervised, unsupervised, semi-supervised, and reinforcement learning, and outlines the complete modeling process from data acquisition to model evaluation. Additionally, it discusses types of fitting problems and generalization capability, and briefly introduces the Scikit-learn development environment. This article offers a comprehensive knowledge framework for understanding machine learning.
通过前面对于机器学习的学习,现在对于所学的进行简单的概述
一.相关概述
人工智能(AI)
AI简单地说就是用计算机来模拟人脑,像人一样能够理性思考和行动
机器学习(ML)
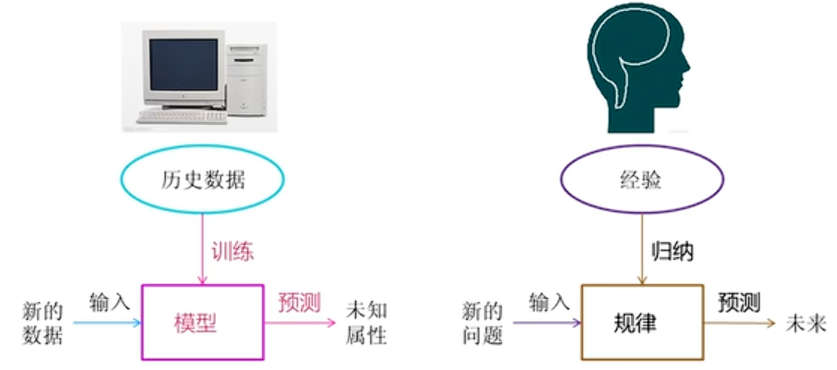
机器学习简单地说就是赋予计算机学习能力而不需要明确编程的研究领域(先训练再预测)
深度学习(DL)
深度学习也叫深度神经网络,是对大脑的仿生,通过设计一层一层的神经元模拟万事万物。
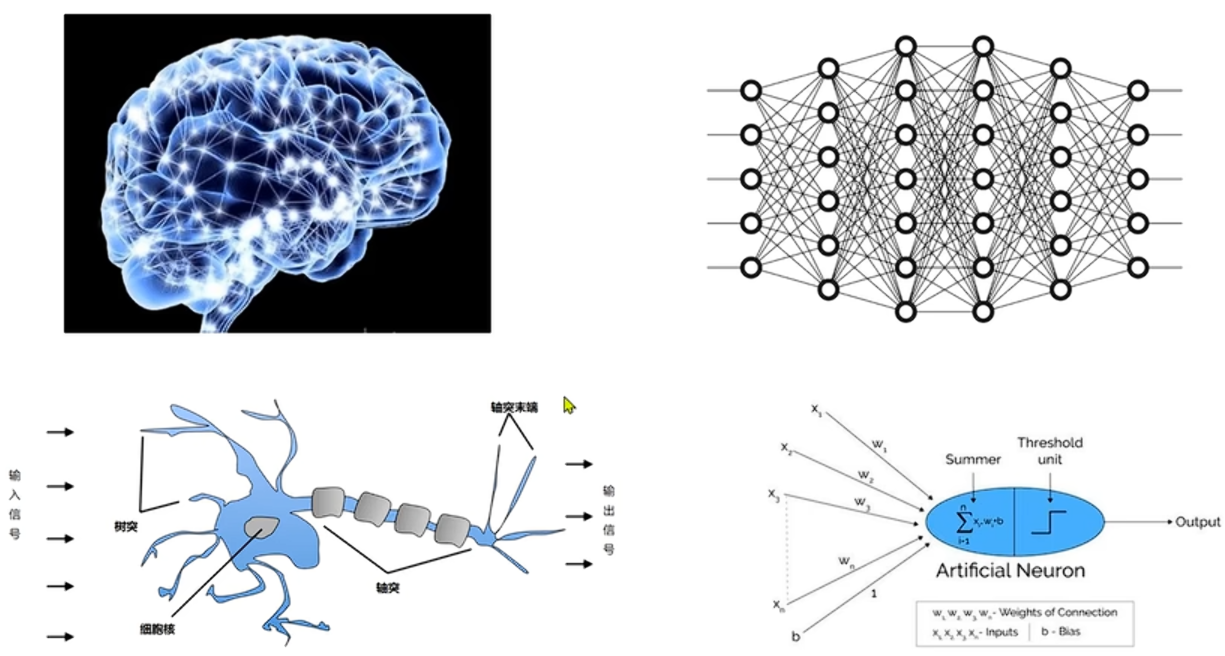
对于上面三者的关系可以概括成人工智能包括机器学习,机器学习包括深度学习。但是严格意义上深度学习属于机器学习的一个分支,其底层主要用到的是强化学习。
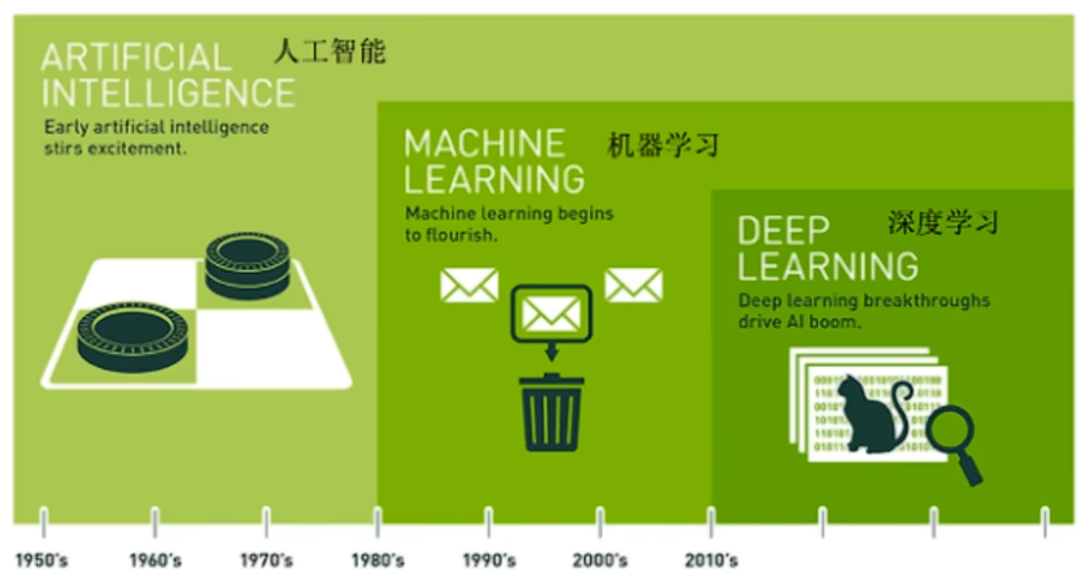
所以总的来说机器学习是实现人工智能的一种途径,深度学习是机器学习的一种方法。
学习方式
· 基于规则的学习:一种通过预定义的逻辑规则(如if-else)来进行决策或预测的方法。
如对于垃圾邮件的判别。
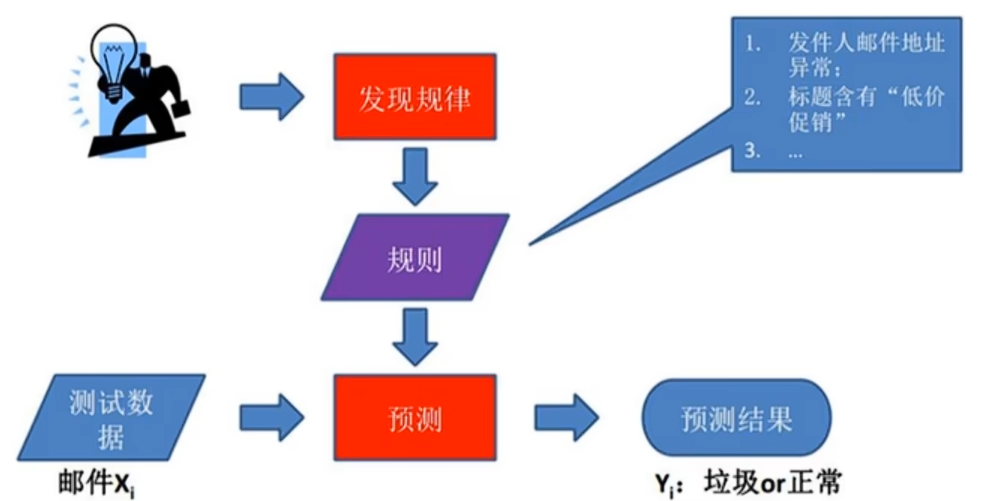
因为在很多问题上无法明确地写下规则,此时我们无法使用规则学习的方式来解决这一类问题,如图像语音识别和自然语言处理,所以就有了下面的学习。
· 基于模型的学习:从数据中自动学习规律。
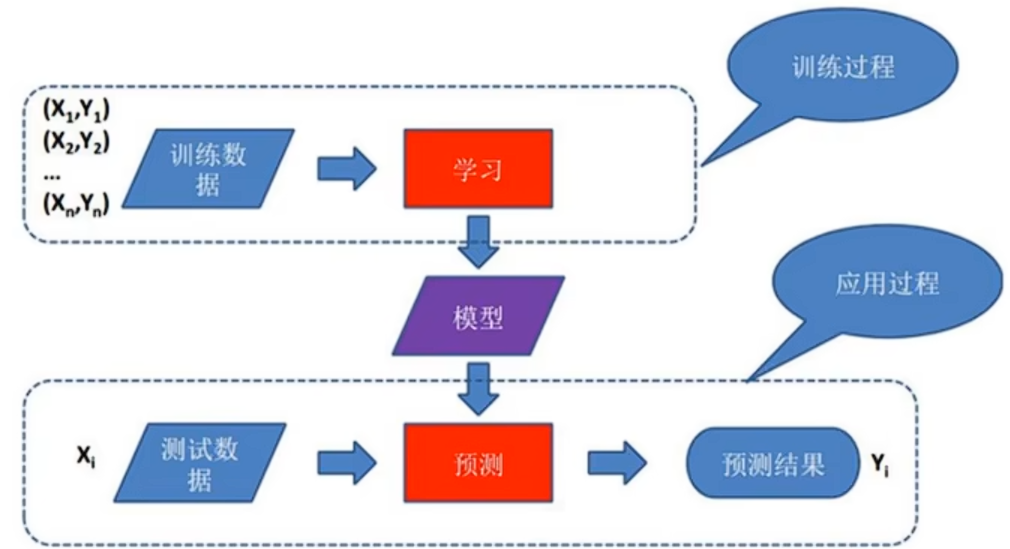
其实中训练数据我们可以看作是x_train,模型就是在找规律找公式,测试数据看作是x_test,在训练时预测结果就是y_train,测试时就是y_test。
对此基于模型的学习就可以用于房价的预测。
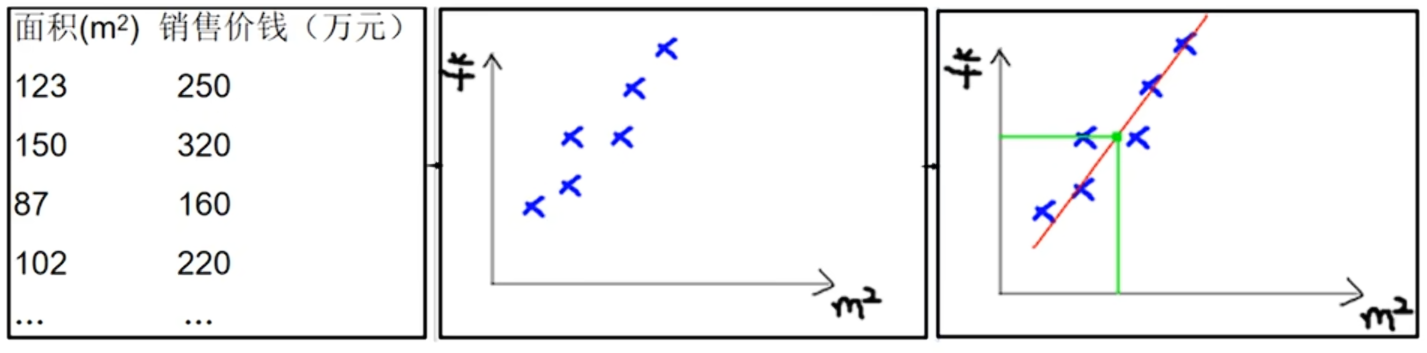
其中面积是x_train(也就是特征),销售价钱就是y_train,这些已知的就是训练集与测试集。所以就可以通过训练集得到一些坐标点如上面第二张图,接着根据这些坐标得到拟合回归线。
从而就可以利用线性关系来模拟面积和房价之间的关系得到一元线性回归,也就是y=ax+b,其中的权重(a),偏置(b)就是我们需要训练的模型参数。
二 . 机器学习发展三要素以及常用术语
三要素
AI发展的三要素是数据、算法、算力相互作用,也是AI发展的基石。AI的底层逻辑就是将数据输入到算法中,要运行算法,并且快速完成就要有足够的算力支撑,最后得到结果。
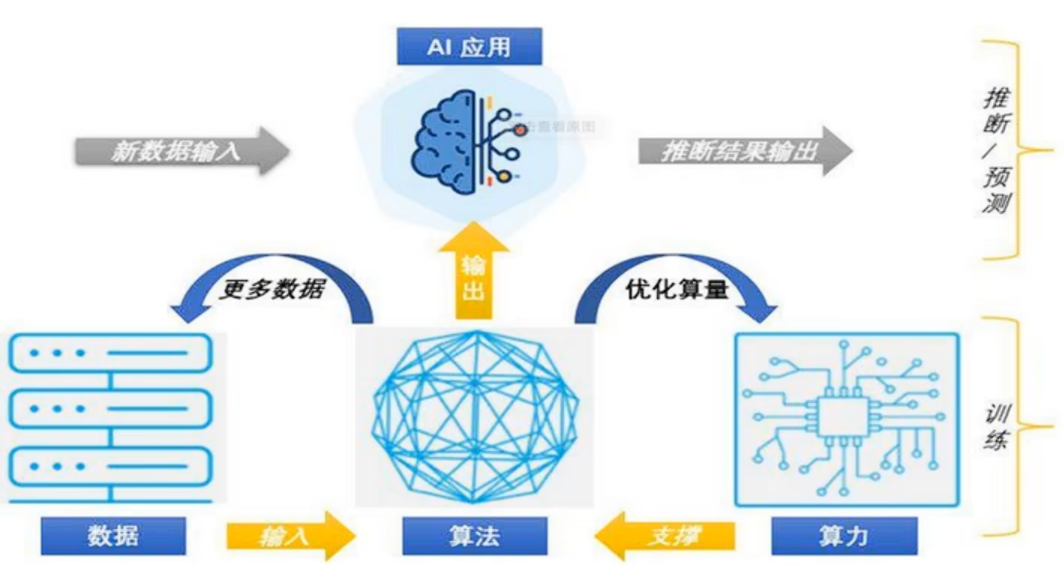
其中算力分为CPU(主要适合I\O密集型任务)、GPU(主要适合计算密集型任务)、TPU(专门针对大型网络训练而设计的一款处理器)。
常用术语
常用术语有样本、特征、标签、训练集和测试集。
样本:一行数据就是一个样本,当多个样本组成数据集;
特征(属性):一列数据一个特征;
标签(目标):模型要预测的那一列数据;
训练集:用来训练模型的数据集;
测试集:用来测试模型的数据集;
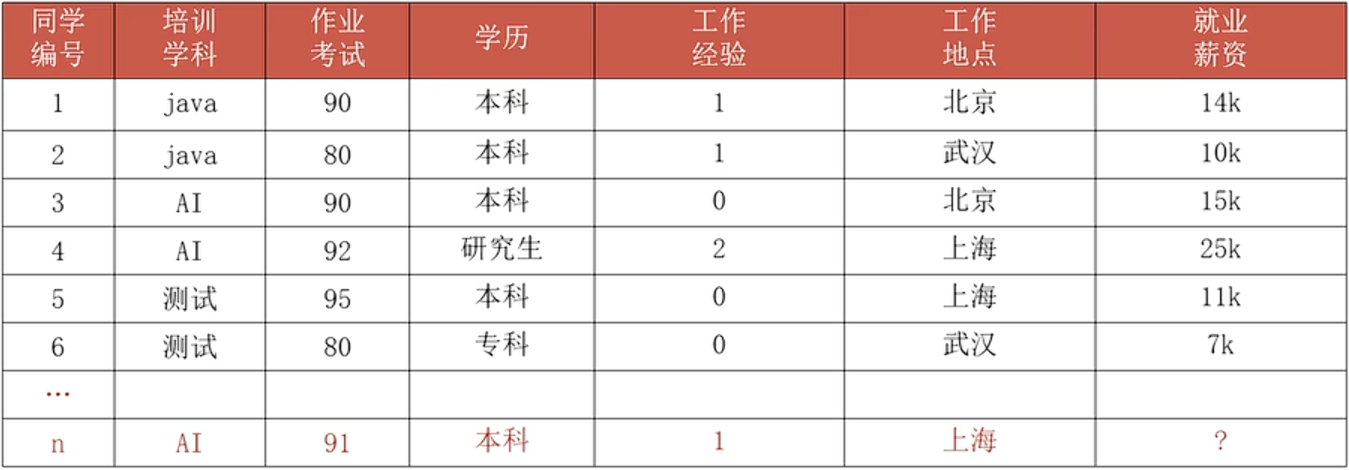
就如上面的表格,其中培训学科、作业考试、学历、工作经验、工作地点一起就是组成特征,就业薪资就是标签,每一行数据就是样本。
其中将前面部分的特征就称之为x_train,下面的部分就是用来测试的称之为x_test,训练集特征得到的标签就是y_train,最终希望得到的就是y_test。
对于在数据集上对于训练集与测试集的划分的比例一般是8 : 2或7 : 3。
三 . 机器学习算法分类
有监督学习
有监督学习:输入数据由输入特征值和目标值组成,即输入的训练数据有标签的。
有监督学习根据标签值可分为分类问题和回归问题,当标签值连续时就是回归问题,当不连续时就是分类问题。分类问题又可以分为二分类和多分类。
无监督学习
无监督学习:输入数据没有被标记,即样本数据无标签,是根据样本间的相似性,对样本集聚类,以发现事物内部的结构以及相互关系。
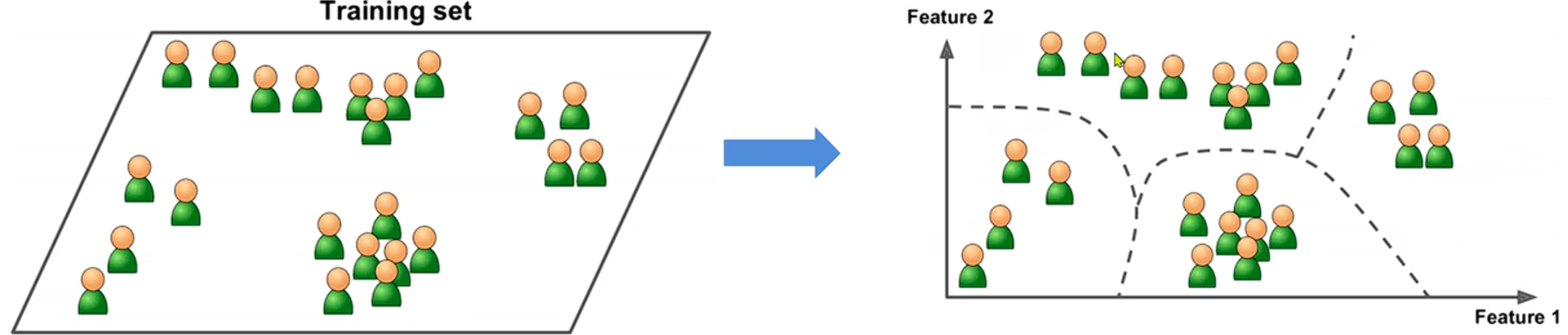
对此这里就包含了机器学习的三大类的问题:回归 、分类 和聚类。
半监督学习
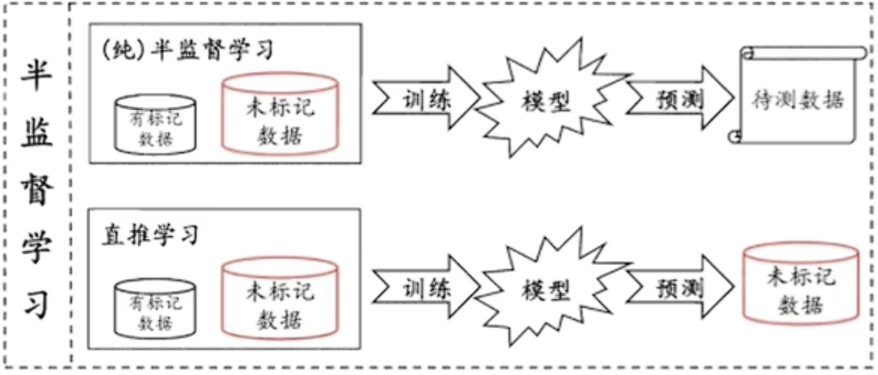
半监督学习:输入数据由输入特征值和部分目标值组成,即输入的训练数据部分有标签。模型参考有标签的数据进行训练,最后给没有标签的数据打标签。这个方法的好处就是降低专家标注的成本。
强化学习
强化学习就是及机器学习的一个重要分支,其就是寻找最优解,以便获取最优奖励。应用场景:里程碑AlphaGo围棋、各类对抗比赛、无人驾驶场景。
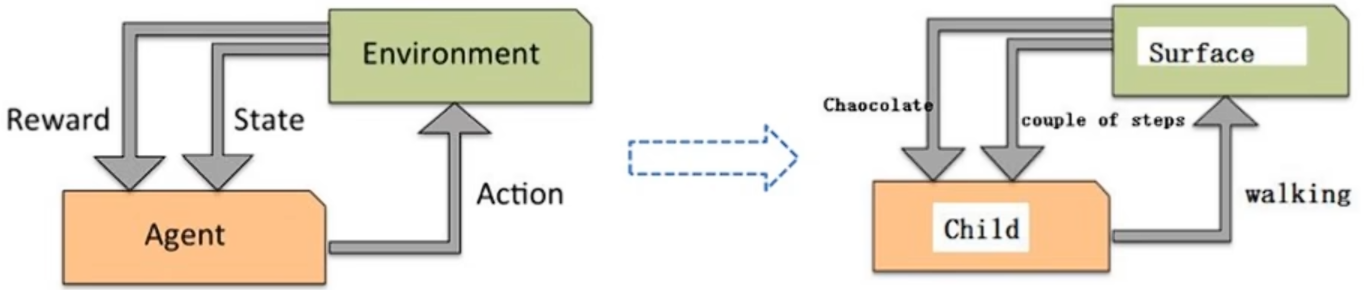
其基本原理是通过构建四个要素:agent、环境状态、行动、奖励,其中agent根据环境状态进行行动获得最多的累计奖励。
四. 建模流程
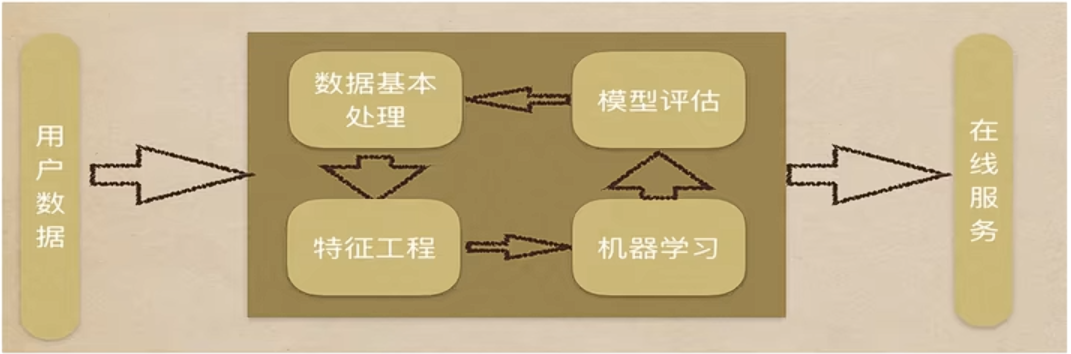
1.获取数据
建模的第一步是获取数据,数据来源包括数据库、文件系统、API接口或实时日志等。在这一阶段,需要明确业务目标,确定所需的数据范围与字段,并将原始数据加载到分析环境中。获取时不仅要关注数据的规模(样本量与特征数),还要初步检查数据的完整性、一致性与相关性,为后续处理打下基础。同时,需记录数据的来源与结构,确保后续步骤可追溯、可复现。
2.数据基本处理
获取到的原始数据通常存在缺失值、异常值或格式不一致等问题,因此需要进行数据清洗与预处理。这包括处理缺失值(如填充、插值或删除缺失严重的记录)、识别并处理异常值(基于统计方法或业务规则),以及对数据进行划分,将数据集按比例拆分为训练集、验证集和测试集,保证模型评估的客观性。对于分类问题,若类别分布不均衡,还需采用过采样或欠采样等方法平衡数据,避免模型偏向多数类。
3.特征工程
特征工程是将原始数据转化为更能体现问题本质的输入特征,是提升模型效果的关键环节。主要工作包括从已有字段中提取新特征(如从时间戳中解析出时段、星期几)、对类别型特征进行编码(如独热编码或标签编码)、将数值型特征进行缩放(标准化或归一化)以消除量纲影响,以及通过相关性分析、主成分分析或模型重要性筛选等方式进行特征选择与降维。良好的特征工程能显著降低模型对复杂结构的依赖,提升训练效率与泛化能力。
4.训练模型
在完成特征工程后,根据任务类型(分类、回归、聚类等)选择合适的算法,并使用训练集数据让模型学习其中的规律。训练过程中,模型通过迭代优化(如梯度下降)调整内部参数,最小化损失函数。同时,需要利用验证集或交叉验证对超参数(如学习率、树深度、正则化强度)进行调优,以找到泛化能力最强的配置。这一阶段的目标是使模型在训练数据上充分拟合,同时保持对未见数据的适应能力
5.模型评估
模型训练完成后,需要使用测试集(模型从未参与学习的数据)对最终模型的性能进行客观评估。评估时根据任务选择合适的指标,分类任务常用准确率、精确率、召回率、F1分数和AUC值,回归任务常用均方误差、平均绝对误差等。通过对比训练集与测试集的表现,可以诊断是否存在过拟合或欠拟合问题。此外,还需结合业务场景验证模型的预测结果是否符合预期、是否具备可解释性,最终判断模型是否满足上线或部署的要求。
五. 模型拟合问题
拟合问题分为拟合、欠拟合、过拟合。拟合就是模型在训练集和测试集上表现情况,其中欠拟合是因为数据集比较少,模型简单,所以在训练集以及测试集上表现得都不好;过拟合就是数据集比较多,模型比较复杂,导致学习到脏内容,所以在训练集上变现好,在测试集上表现差。
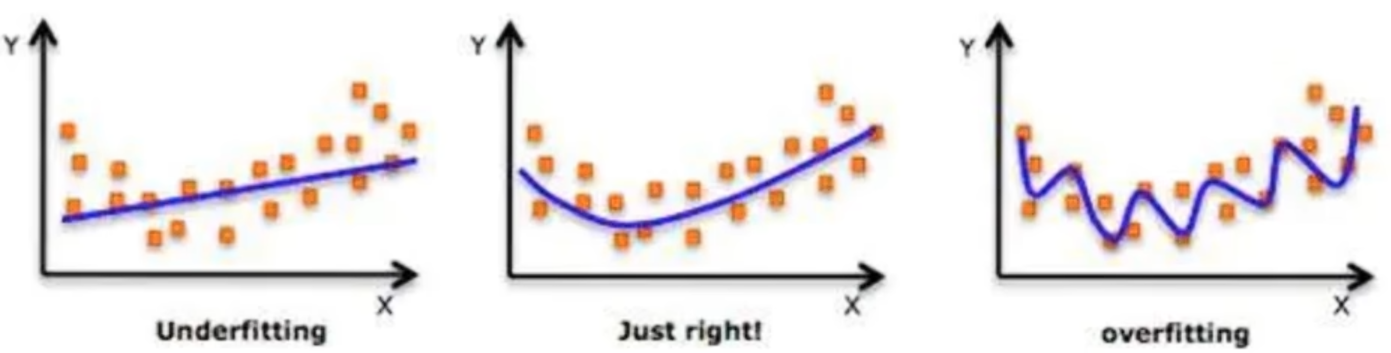
其中涉及的泛化是指模型在新数据集(非训练数据)上的表现好坏的能力。奥卡姆剃刀原则是指给定的两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取。
就如下面欠拟合与过拟合的例子:
六.机器学习开发环境
在python中有一个scikit-learn库,是一个简单高效的数据挖掘和数据分析工具。安装这个库就是在Anaconda黑窗口中输入pip install scikit-learn,回车进行安装。
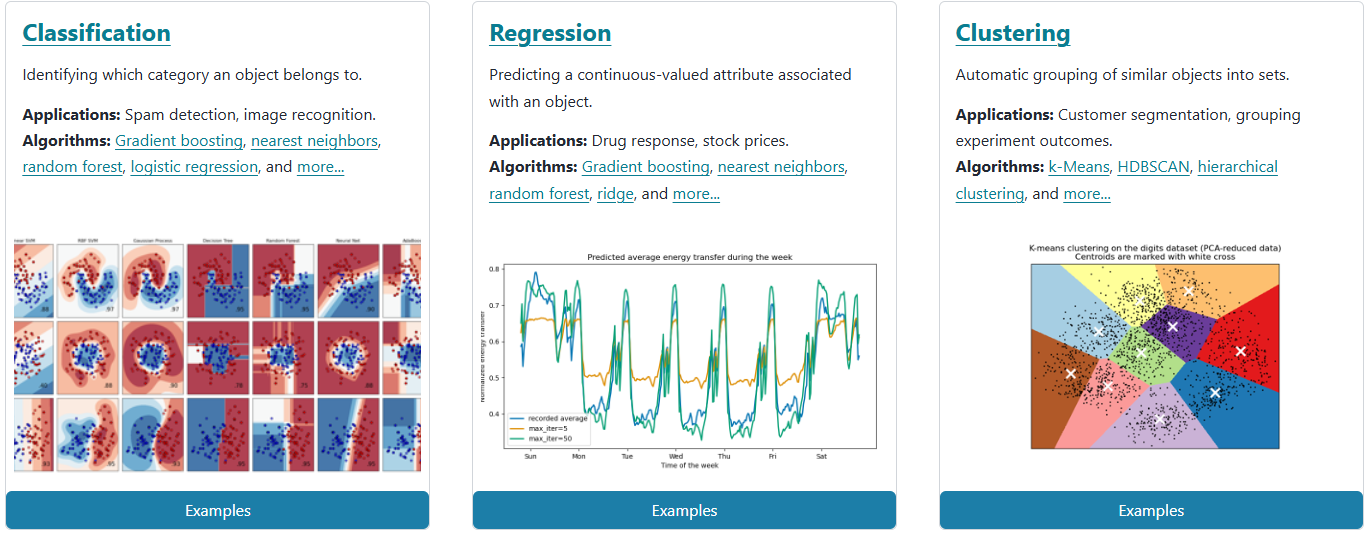
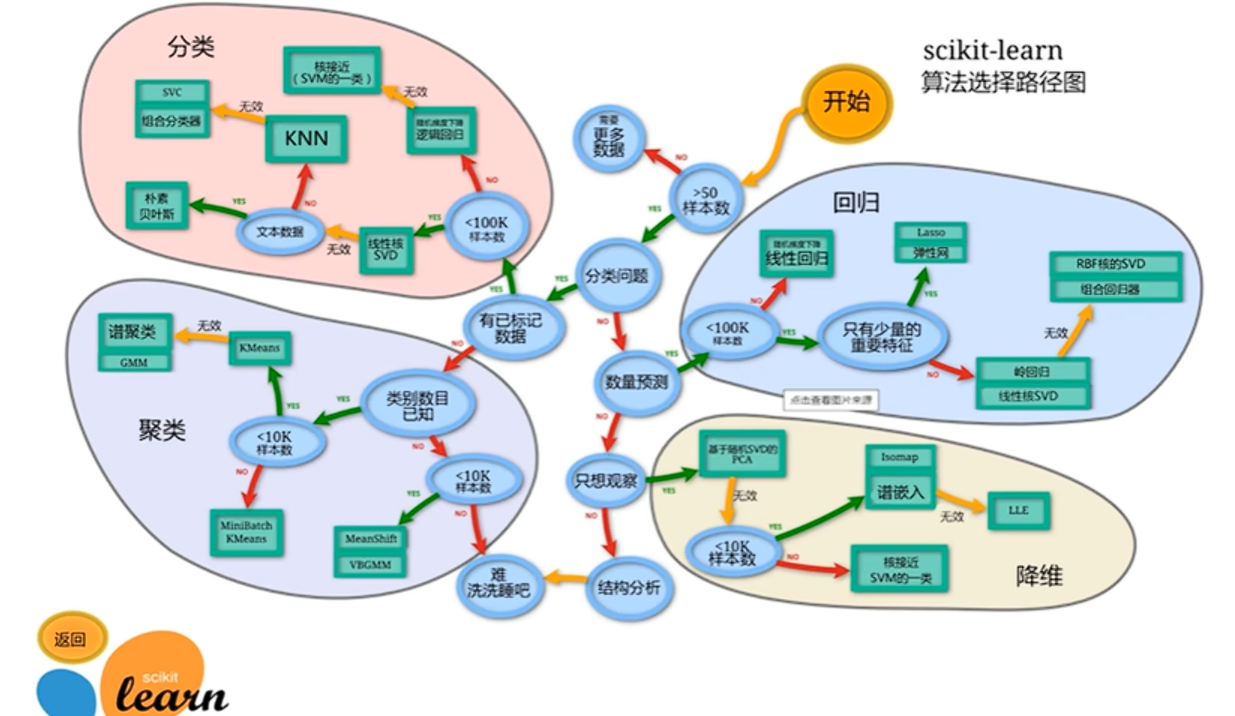
pip install scikit-learn同访问这个库的官网我们可以发现其是可以支持回归、分类以及聚类问题。
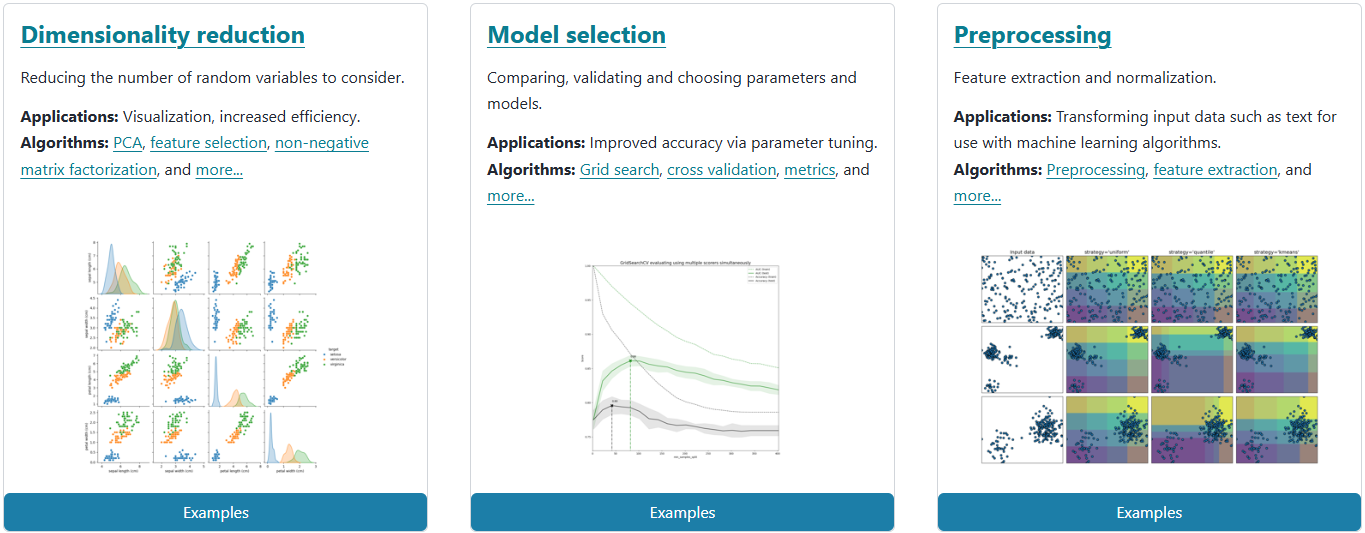
也可以经行降维、模型选择以及预处理。
最后再看看在这个库中对于算法的选择:
总结
本文作为机器学习学习路径的回顾,系统梳理了从基础概念到完整建模流程的核心知识点。文章明确了人工智能、机器学习与深度学习之间的层级关系,介绍了基于规则与基于模型两种学习方式的适用场景。通过对算法分类、建模步骤及拟合问题的详细阐述,帮助建立起完整的机器学习知识体系。同时,文中对Scikit-learn开发环境的介绍,为实践应用提供了工具基础。