1. 作者介绍
程锡贵,男,西安工程大学电子信息学院,2025级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:15327178796@163.com
2. Rectified Flow 与 Diffusion Transformer 理论介绍
2.1 实验任务与总体框架
本实验的目标是生成 MNIST 风格的手写数字图像。模型训练完成后,不需要输入某张待识别图片,而是从随机高斯噪声出发,经过多步速度场更新,逐步得到具有手写数字轮廓的灰度图像。
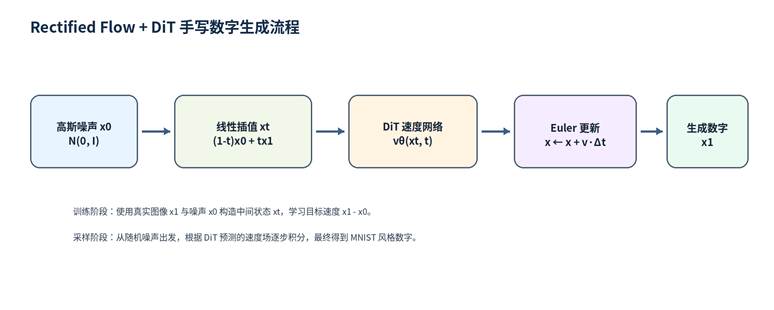
图 1 Rectified Flow + DiT 手写数字图像生成流程
2.2 Rectified Flow 基本原理
Rectified Flow 将图像生成视为一个连续分布运输问题:从标准高斯噪声分布采样初始状态 x₀,从真实 MNIST 数据分布采样目标图像 x₁,并在两者之间构造直线路径。
xₜ = (1 - t)x₀ + tx₁ , t ∈ 0, 1
当 t=0 时,xₜ 等于纯噪声 x₀;当 t=1 时,xₜ 等于真实图像 x₁。由于该路径是线性的,对时间 t 求导后可得到目标速度:
v*(xₜ, t) = dxₜ / dt = x₁ - x₀
训练阶段使用神经网络 vθ(xₜ, t) 拟合上述目标速度,采用均方误差作为损失函数:
L = E || vθ(xₜ, t) - (x₁ - x₀) ||²
2.3 Diffusion Transformer (DiT)
DiT 使用 Transformer 替代常见扩散模型中的 U-Net 作为核心网络。在本实验中,DiT 的作用是接收中间状态图像 xₜ 与连续时间 t,并预测与输入图像尺寸相同的速度图 vθ(xₜ, t)。
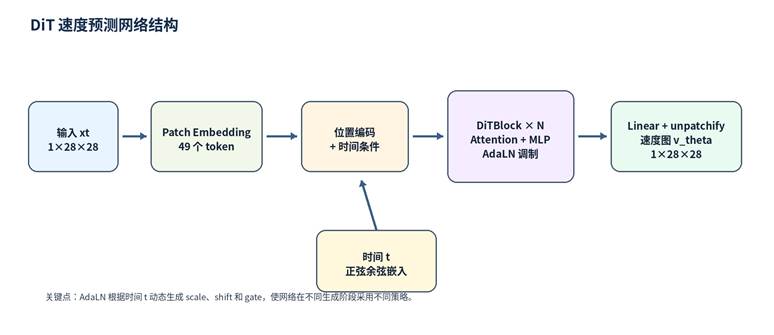
图 2 DiT 速度预测网络结构
2.4 DiT 中的关键模块
| 模块 | 作用 |
|---|---|
| Patch Embedding | 将 1×28×28 的图像切分为 4×4 patch,并映射为 token。默认参数下得到 7×7=49 个 token。 |
| DiTBlock | 由多头自注意力、MLP、残差连接与条件调制组成,用于建模不同 patch 之间的关系。 |
| AdaLN | Adaptive Layer Normalization。根据时间条件动态生成 scale、shift 与 gate,使网络适应不同生成阶段。 |
| unpatchify | 将 Transformer 输出的 patch 重新排列并拼接为 1×28×28 的速度预测图。 |
数据在 DiT 内部的主要形状变化为:
B, 1, 28, 28 → B, 256, 7, 7 → B, 49, 256 → B, 49, 16 → B, 1, 28, 28
2.5 Euler ODE 采样
训练完成后,模型从随机噪声开始生成图像。将时间区间 0, 1 划分为若干步,在每一步调用 DiT 预测速度,并使用 Euler 方法更新当前图像:
xₜ₊Δₜ = xₜ + vθ(xₜ, t) · Δt
默认 sample_steps=100,对应 Δt=0.01。采样步数增加时通常更新更细致,但推理时间也会增加。
3. Rectified Flow + DiT 手写数字生成实验
3.1 实验环境与软件包
本项目使用 Python 与 PyTorch 实现。建议优先使用带 NVIDIA GPU 的环境训练;若没有 GPU,程序会自动切换到 CPU,但训练速度较慢。
| 软件或包 | 用途 | 安装说明 |
|---|---|---|
| Python | 运行实验代码 | 建议使用 Python 3.10 或更高版本 |
| torch | 张量计算、模型搭建、反向传播和 GPU 加速 | pip install torch |
| torchvision | 下载 MNIST、图像预处理、保存生成图片 | pip install torchvision |
| tqdm | 显示训练进度条 | pip install tqdm |
安装项目依赖:
pip install -r requirements.txt
检查 CUDA 是否可用:
python -c "import torch; print(torch.cuda.is_available())"
3.2 MNIST 数据集介绍
MNIST 是经典的手写数字数据集,图像为 28×28 灰度图,数字类别为 0 至 9。程序使用 torchvision.datasets.MNIST 自动下载训练数据,并通过 Normalize((0.5,), (0.5,)) 将像素范围从 0, 1 转换到 -1, 1。
3.3 项目文件结构
rf_dit_mnist/
├── train.py # 训练入口
├── sample.py # 单独采样入口
├── utils.py # 时间嵌入和 AdaLN 调制函数
├── models/
│ ├── init.py
│ └── dit.py # Diffusion Transformer
├── flow/
│ ├── init.py
│ └── rectified_flow.py # Rectified Flow 训练和采样
├── requirements.txt
└── README.md
3.4 训练与测试步骤
| 步骤 | 操作说明 |
|---|---|
| 步骤 1 | 解压项目压缩包,并进入 rf_dit_mnist 目录。 |
| 步骤 2 | 安装依赖:pip install -r requirements.txt。 |
| 步骤 3 | 执行训练命令。程序会自动下载 MNIST,并定期保存生成图片和 latest.pt。 |
| 步骤 4 | 训练结束后使用 sample.py 加载 latest.pt,单独生成 final_sample.png。 |
推荐训练命令:
python train.py --epochs 30 --batch_size 128 --sample_steps 100
显存不足时可降低 batch size 和模型规模:
python train.py --epochs 30 --batch_size 64 --dim 128 --depth 4 --heads 4
训练完成后单独采样:
python sample.py --ckpt ./runs_rf_dit_mnist/latest.pt
3.5 训练过程说明
| 阶段 | 程序操作 | 对应代码位置 |
|---|---|---|
| 数据加载 | 读取 MNIST 图像并归一化到 -1, 1 | train.py |
| 构造路径 | 采样 x₀、x₁ 与 t,计算 xₜ=(1-t)x₀+tx₁ | flow/rectified_flow.py |
| 速度预测 | DiT 输入 xₜ 与 t,输出预测速度 | models/dit.py |
| 损失计算 | MSE(pred_v, x₁-x₀) | flow/rectified_flow.py |
| 反向传播 | 更新模型参数并裁剪梯度 | flow/rectified_flow.py |
| 生成样例 | 从噪声出发,利用 Euler 方法积分 | flow/rectified_flow.py |
3.6 完整实验代码
以下代码与项目文件结构一一对应。为了便于阅读,代码按照文件拆分展示,并加入了必要注释。
文件:requirements.txt
torch torchvision tqdm
文件:models/init.py
导出 DiT 模型,方便其他文件使用 from models import DiT
from .dit import DiT
文件:flow/init.py
导出 Rectified Flow 的训练和采样函数
from .rectified_flow import train_one_epoch, sample
文件:utils.py
python
import math
import torch
def timestep_embedding(t, dim, max_period=10000):
"""将连续时间 t 编码为正弦余弦向量。
参数:
t: [B],范围为 [0, 1] 的连续时间。
dim: 时间嵌入的维度。
返回:
[B, dim] 的时间特征。
"""
half = dim // 2
t = t * 1000.0
freqs = torch.exp(
-math.log(max_period)
* torch.arange(0, half, dtype=torch.float32, device=t.device)
/ half
)
args = t[:, None] * freqs[None]
emb = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
if dim % 2 == 1:
emb = torch.cat([emb, torch.zeros_like(emb[:, :1])], dim=-1)
return emb
def modulate(x, shift, scale):
"""AdaLN 调制:根据时间条件对标准化后的特征缩放和平移。"""
return x * (1 + scale[:, None, :]) + shift[:, None, :]文件:models/dit.py
python
import torch
import torch.nn as nn
from utils import timestep_embedding, modulate
class DiTBlock(nn.Module):
"""一个 DiTBlock:自注意力、MLP、残差连接和 AdaLN 条件调制。"""
def __init__(self, dim, heads, mlp_ratio=4.0):
super().__init__()
# 不使用 LayerNorm 自带仿射参数,由 AdaLN 动态生成 scale 和 shift。
self.norm1 = nn.LayerNorm(dim, elementwise_affine=False)
self.attn = nn.MultiheadAttention(
embed_dim=dim,
num_heads=heads,
batch_first=True
)
self.norm2 = nn.LayerNorm(dim, elementwise_affine=False)
hidden_dim = int(dim * mlp_ratio)
self.mlp = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, dim)
)
# 输出 Attention 和 MLP 各自所需的 shift、scale 和 gate。
self.adaLN = nn.Sequential(
nn.SiLU(),
nn.Linear(dim, dim * 6)
)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = \
self.adaLN(c).chunk(6, dim=1)
# 多头自注意力分支。
x_norm = modulate(self.norm1(x), shift_msa, scale_msa)
attn_out, _ = self.attn(x_norm, x_norm, x_norm, need_weights=False)
x = x + gate_msa[:, None, :] * attn_out
# MLP 分支。
x_norm = modulate(self.norm2(x), shift_mlp, scale_mlp)
mlp_out = self.mlp(x_norm)
x = x + gate_mlp[:, None, :] * mlp_out
return x
class DiT(nn.Module):
"""面向 28×28 MNIST 灰度图的轻量级 Diffusion Transformer。"""
def __init__(
self,
img_size=28,
patch_size=4,
in_channels=1,
dim=256,
depth=6,
heads=8,
mlp_ratio=4.0
):
super().__init__()
assert img_size % patch_size == 0
self.img_size = img_size
self.patch_size = patch_size
self.in_channels = in_channels
self.num_patches = (img_size // patch_size) ** 2
self.patch_dim = in_channels * patch_size * patch_size
# 使用卷积完成 Patch Embedding。
self.patch_embed = nn.Conv2d(
in_channels,
dim,
kernel_size=patch_size,
stride=patch_size
)
# 可学习位置编码:告诉 Transformer 每个 patch 位于图像的什么位置。
self.pos_embed = nn.Parameter(
torch.zeros(1, self.num_patches, dim)
)
# 把连续时间嵌入映射为条件向量 c。
self.time_mlp = nn.Sequential(
nn.Linear(dim, dim * 4),
nn.SiLU(),
nn.Linear(dim * 4, dim)
)
self.blocks = nn.ModuleList([
DiTBlock(dim, heads, mlp_ratio)
for _ in range(depth)
])
self.final_norm = nn.LayerNorm(dim, elementwise_affine=False)
self.final_adaLN = nn.Sequential(
nn.SiLU(),
nn.Linear(dim, dim * 2)
)
self.final_linear = nn.Linear(dim, self.patch_dim)
self.initialize_weights()
def initialize_weights(self):
"""初始化位置编码、线性层和卷积层。"""
nn.init.normal_(self.pos_embed, std=0.02)
for module in self.modules():
if isinstance(module, nn.Linear):
nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.zeros_(module.bias)
if isinstance(module, nn.Conv2d):
nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.zeros_(module.bias)
def unpatchify(self, x):
"""将 patch 形式的预测结果重新拼接成二维图像。"""
B = x.shape[0]
p = self.patch_size
h = w = self.img_size // p
c = self.in_channels
x = x.reshape(B, h, w, c, p, p)
x = torch.einsum("bhwcpq->bchpwq", x)
x = x.reshape(B, c, h * p, w * p)
return x
def forward(self, x, t):
"""输入中间图像 x_t 与时间 t,输出同尺寸的速度预测图。"""
# [B, 1, 28, 28] -> [B, dim, 7, 7] -> [B, 49, dim]
x = self.patch_embed(x)
x = x.flatten(2).transpose(1, 2)
x = x + self.pos_embed
t_emb = timestep_embedding(t, x.shape[-1])
c = self.time_mlp(t_emb)
for block in self.blocks:
x = block(x, c)
shift, scale = self.final_adaLN(c).chunk(2, dim=1)
x = modulate(self.final_norm(x), shift, scale)
# 每个 token 输出一个 patch,再拼回速度图。
x = self.final_linear(x)
x = self.unpatchify(x)
return x文件:flow/rectified_flow.py
python
import torch
import torch.nn.functional as F
from tqdm import tqdm
def train_one_epoch(model, loader, optimizer, device):
"""训练一个 epoch:学习从噪声到真实图像的速度场。"""
model.train()
total_loss = 0.0
for imgs, _ in tqdm(loader, desc="Training", leave=False):
imgs = imgs.to(device)
# x0:高斯噪声;x1:真实 MNIST 图像。
x0 = torch.randn_like(imgs)
x1 = imgs
B = imgs.shape[0]
# 为 batch 中每个样本随机采样连续时间 t。
t = torch.rand(B, device=device)
t_view = t.view(B, 1, 1, 1)
# Rectified Flow 直线路径:x_t = (1-t)x0 + tx1。
xt = (1 - t_view) * x0 + t_view * x1
# 对直线路径求导,可得目标速度 x1 - x0。
target_v = x1 - x0
pred_v = model(xt, t)
loss = F.mse_loss(pred_v, target_v)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total_loss += loss.item() * B
return total_loss / len(loader.dataset)
@torch.no_grad()
def sample(model, device, n_samples=64, steps=100):
"""从高斯噪声开始,使用 Euler 方法积分得到生成图像。"""
model.eval()
x = torch.randn(n_samples, 1, 28, 28, device=device)
dt = 1.0 / steps
for i in range(steps):
t = torch.full((n_samples,), i / steps, device=device)
v = model(x, t)
# Euler ODE 更新:x_(t+dt) = x_t + v(x_t, t) * dt。
x = x + v * dt
# 将图像从训练时的 [-1, 1] 转回保存图片所需的 [0, 1]。
x = x.clamp(-1, 1)
x = (x + 1) / 2
return x文件:train.py
python
import os
import argparse
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.utils import save_image
from models import DiT
from flow import train_one_epoch, sample
def parse_args():
"""读取训练参数。"""
parser = argparse.ArgumentParser()
parser.add_argument("--data_dir", type=str, default="./data")
parser.add_argument("--save_dir", type=str, default="./runs_rf_dit_mnist")
parser.add_argument("--epochs", type=int, default=30)
parser.add_argument("--batch_size", type=int, default=128)
parser.add_argument("--lr", type=float, default=1e-4)
parser.add_argument("--dim", type=int, default=256)
parser.add_argument("--depth", type=int, default=6)
parser.add_argument("--heads", type=int, default=8)
parser.add_argument("--patch_size", type=int, default=4)
parser.add_argument("--sample_steps", type=int, default=100)
parser.add_argument("--sample_every", type=int, default=1)
return parser.parse_args()
def main():
args = parse_args()
os.makedirs(args.save_dir, exist_ok=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device:", device)
# 将图像像素范围由 [0, 1] 映射到 [-1, 1]。
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 若本地没有 MNIST,则自动下载。
dataset = datasets.MNIST(
root=args.data_dir,
train=True,
transform=transform,
download=True
)
loader = DataLoader(
dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=4,
pin_memory=True,
drop_last=True
)
model = DiT(
img_size=28,
patch_size=args.patch_size,
in_channels=1,
dim=args.dim,
depth=args.depth,
heads=args.heads
).to(device)
optimizer = torch.optim.AdamW(
model.parameters(),
lr=args.lr,
betas=(0.9, 0.95),
weight_decay=1e-4
)
for epoch in range(1, args.epochs + 1):
loss = train_one_epoch(model, loader, optimizer, device)
print(f"Epoch [{epoch}/{args.epochs}] Loss: {loss:.6f}")
# 每隔指定 epoch 保存一次生成样例。
if epoch % args.sample_every == 0:
samples = sample(
model,
device,
n_samples=64,
steps=args.sample_steps
)
save_path = os.path.join(
args.save_dir,
f"sample_epoch_{epoch}.png"
)
save_image(samples, save_path, nrow=8)
print(f"Saved samples to {save_path}")
# 保存最新模型和训练参数,便于之后单独采样。
ckpt_path = os.path.join(args.save_dir, "latest.pt")
torch.save(
{
"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"epoch": epoch,
"args": vars(args)
},
ckpt_path
)
if __name__ == "__main__":
main()文件:sample.py
python
import os
import argparse
import torch
from torchvision.utils import save_image
from models import DiT
from flow import sample
def parse_args():
"""读取单独采样时所需的参数。"""
parser = argparse.ArgumentParser()
parser.add_argument("--ckpt", type=str,
default="./runs_rf_dit_mnist/latest.pt")
parser.add_argument("--save_path", type=str,
default="./runs_rf_dit_mnist/final_sample.png")
parser.add_argument("--n_samples", type=int, default=64)
parser.add_argument("--sample_steps", type=int, default=100)
return parser.parse_args()
def main():
args = parse_args()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device:", device)
# 读取训练阶段保存的权重和模型配置。
ckpt = torch.load(args.ckpt, map_location=device)
model_args = ckpt["args"]
model = DiT(
img_size=28,
patch_size=model_args["patch_size"],
in_channels=1,
dim=model_args["dim"],
depth=model_args["depth"],
heads=model_args["heads"]
).to(device)
model.load_state_dict(ckpt["model"])
samples = sample(
model,
device,
n_samples=args.n_samples,
steps=args.sample_steps
)
os.makedirs(os.path.dirname(args.save_path), exist_ok=True)
save_image(samples, args.save_path, nrow=8)
print(f"Saved samples to {args.save_path}")
if __name__ == "__main__":
main()3.7 测试结果
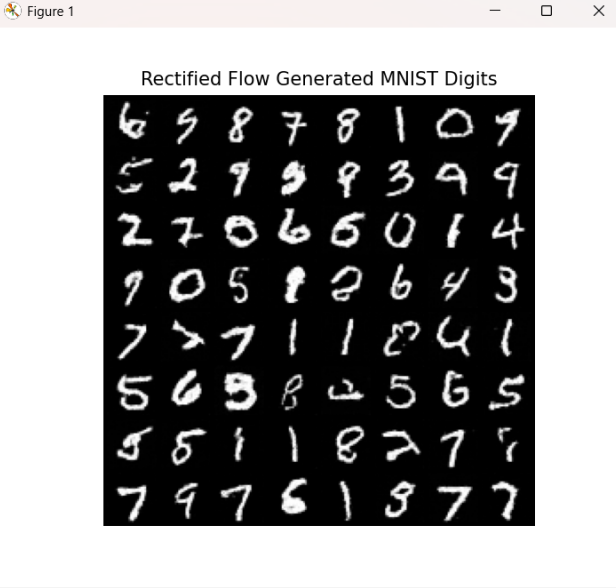
训练过程中,程序会在 runs_rf_dit_mnist 文件夹中保存 sample_epoch_1.png、sample_epoch_2.png 等图片。训练完成后,sample.py 默认将新生成的 64 张图片保存为 final_sample.png
3.8 可能遇到的问题与解决办法
| 问题 | 可能原因 | 解决办法 |
|---|---|---|
| MNIST 下载失败 | 网络连接异常或数据目录权限不足 | 检查网络;也可手动下载 MNIST,并放入 data/MNIST/raw。 |
| CUDA 不可用 | 未安装 GPU 版 PyTorch、显卡驱动异常或无 NVIDIA GPU | 运行 torch.cuda.is_available() 检查;必要时重新安装匹配环境的 PyTorch。 |
| 显存不足 Out of Memory | batch_size、dim 或 depth 过大 | 减小 batch_size;将 dim 改为 128、depth 改为 4。 |
| Windows 多进程报错 | DataLoader 的 num_workers=4 在部分环境中不稳定 | 把 train.py 中 num_workers 改为 0。 |
| 生成图片模糊 | 训练轮数不足、模型尚未收敛或采样步数过少 | 适当增加 epochs;检查 Loss;尝试提高 sample_steps。 |
| 模型权重找不到 | sample.py 指定的 ckpt 路径不正确 | 确认 runs_rf_dit_mnist/latest.pt 是否存在,并修正 --ckpt 参数。 |
| 生成图无法指定类别 | 当前代码是无条件生成 | 如需指定数字类别,需要增加 label embedding,改为条件 DiT。 |
4. 参考链接
1 Xingchao Liu, Chengyue Gong, Qiang Liu. Learning to Generate and Transfer Data with Rectified Flow. arXiv:2209.03003. https://arxiv.org/abs/2209.03003
2 William Peebles, Saining Xie. Scalable Diffusion Models with Transformers. arXiv:2212.09748. https://arxiv.org/abs/2212.09748
3 Torchvision Documentation: MNIST Dataset. https://docs.pytorch.org/vision/main/generated/torchvision.datasets.MNIST.html
4 PyTorch Documentation. https://pytorch.org/docs/stable/index.html
实验总结
本实验使用 Rectified Flow 建立从噪声到 MNIST 图像的连续直线路径,并使用 DiT 预测路径上的速度场。DiT 将图像转换为 patch token,通过多头注意力建模不同区域之间的关系,并利用 AdaLN 注入时间条件。采样阶段从随机噪声开始,使用 Euler 方法逐步积分,最终得到手写数字图像。该实验结构清晰、代码模块化程度较高,适合作为生成模型与 Transformer 图像建模的入门实践。