Peng Xia 1 ∗ ^{1*} 1∗ Jianwen Chen 1 ∗ ^{1*} 1∗ Hanyang Wang 1 ^{1} 1 2 ∗ ^{2*} 2∗ Jiaqi Liu 1 ^{1} 1 Kaide Zeng 1 ^{1} 1 Yu Wang 3 ^{3} 3 Siwei Han 1 ^{1} 1 Yiyang Zhou 1 ^{1} 1 Xujiang Zhao 4 ^{4} 4 Haifeng Chen 4 ^{4} 4 Zeyu Zheng 5 ^{5} 5 Cihang Xie 6 ^{6} 6 Huaxiu Yao 1 ^{1} 1
1 ^{1} 1 UNC-Chapel Hill 2 ^{2} 2 University of Chicago 3 ^{3} 3 University of California San Diego 4 ^{4} 4 NEC Labs America 5 ^{5} 5 University of California Berkeley 6 ^{6} 6 University of California Santa Cruz.
通讯作者:Peng Xia pxia@cs.unc.edu, Huaxiu Yao huaxiu@cs.unc.edu.
预印本。2026 年 2 月 10 日。
摘要
大语言模型(LLM)智能体在复杂任务中展示了惊人的结果,然而它们通常在孤立状态下操作,未能从过去的经验中学习。现有的基于记忆的方法主要存储原始轨迹,这些轨迹往往是冗余且充满噪声的。这阻碍了智能体提取对于泛化至关重要的高层、可重用的行为模式。在本文中,我们提出了 SKILLRL,这是一个通过自动技能发现和递归进化来弥合原始经验与策略改进之间差距的框架。我们的方法引入了一种基于经验的蒸馏机制来构建分层技能库 SKILLBANK,一种用于通用和任务特定启发式的自适应检索策略,以及一种递归进化机制,允许技能库在强化学习期间与智能体的策略共同进化。这些创新显著减少了 token footprint(token 占用量),同时增强了推理效用。在 ALFWorld、WebShop 和七个搜索增强任务上的实验结果表明,SKILLRL 实现了最先进的性能,优于强基线超过 15.3%,并在任务复杂度增加时保持鲁棒性。代码 available at this https://github.com/aiming-lab/SkillRL.
1. 引言
大语言模型(LLM)智能体 (Yao et al., 2022b; Shinn et al., 2023) 已经在各种复杂任务中展示了非凡的能力,例如网页导航 (Google, 2025; OpenAI, 2025c) 和深度研究 (OpenAI, 2025b; Google, 2024; Team et al., 2025),通过与复杂环境的自然语言交互。尽管取得了这些进展,每次任务执行仍然很大程度上是孤立的 (episodic)。当前的 LLM 智能体孤立操作,无法从过去的成功或失败中学习 (Zhang et al., 2025b),这显著阻碍了它们的进化。因此,一个根本性的挑战仍然存在:智能体如何有效地从经验中学习并将该知识转移到其他任务?
现有的针对 LLM 智能体的基于记忆的方法主要涉及在采样过程中将原始轨迹直接保存到外部数据库中,作为类似未来任务的参考 (Shinn et al., 2023; Zhao et al., 2024)。虽然直观,但这些原始轨迹通常很长且包含显著冗余和噪声 (Chhikara et al., 2025),使得模型难以提取关键信息。最近的工作尝试压缩轨迹并通过在线训练更新记忆库 (Zhang et al., 2025b; 2026),提高了记忆效率。然而,这些方法仅仅模仿过去的解决方案,未能提炼核心原则或调整智能体的内部策略以利用记忆进行 guided decision-making(引导决策)。如图 1(a) 的虚线流所示,此类方法通常在信息密度和噪声之间的权衡中挣扎,导致次优性能甚至如图 1(b) 所示的性能下降。
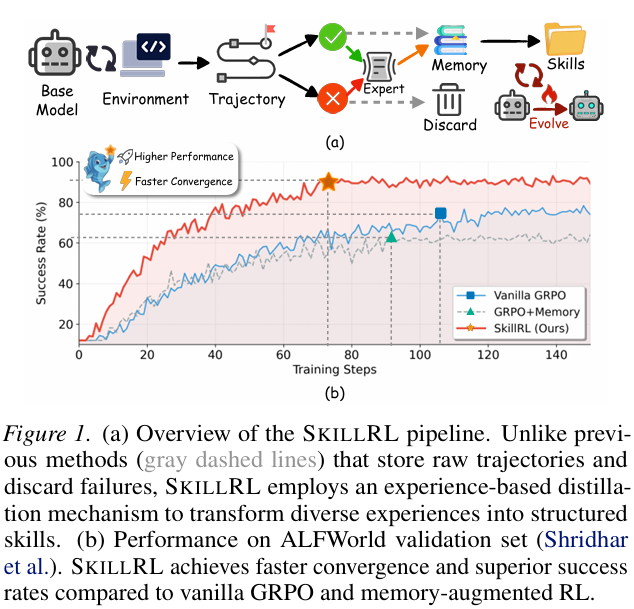
我们认为这些方法忽略了一个关键见解:有效的经验转移需要抽象。人类专家不会记住每种情况下的每个动作;相反,他们发展技能 (Anthropic, 2024),即捕捉如何完成特定子任务本质紧凑且可重用的策略。受此观察启发,我们提出了 SKILLRL,这是一个通过自动技能发现和递归技能进化来弥合原始经验与高效策略改进之间差距的框架。
SKILLRL 首先引入了一种基于经验的技能蒸馏机制,该机制收集来自环境 rollouts 的多样化轨迹并应用差异化处理:成功的 episode 被保留为演示,而失败的 episode 被合成为简洁的失败教训以减轻上下文噪声。其次,我们将这些经验转化为分层技能库 SKILLBANK,区分用于通用战略指导的通用技能和用于任务级启发式的任务特定技能。这种抽象允许智能体在决策过程中自适应地检索相关技能,显著减少 token footprint 同时增强推理效用。最后,SKILLRL 在强化学习 (RL) 期间结合了递归技能进化机制,其中技能库被视为动态组件而不是静态知识源。通过在每个验证 epoch 后分析失败模式以生成新技能或细化现有技能,我们的方法确保技能库和智能体的策略共同进化,随着任务复杂度增加保持鲁棒性。如图 1(b) 所示,SKILLRL 实现了 substantially faster convergence(显著更快的收敛)和更高的渐近性能。
主要贡献是 SKILLRL,这是一个使 LLM 智能体能够通过自动技能发现和递归进化弥合原始经验与策略改进之间差距的框架。通过将冗余轨迹蒸馏为分层 SKILLBANK,我们的方法抽象出通用和任务特定技能以高效指导决策。此外,我们引入了一种递归进化机制,确保技能库和智能体策略在强化学习期间共同进化。在 ALFWorld、WebShop 和七个搜索增强基准上的实证结果表明,SKILLRL 实现了最先进的性能,提高了 15.3%,在任务成功率和推理效用方面显著优于当前的基于记忆的智能体微调基线。
2. 预备知识
LLM 智能体。 我们考虑一个在交互式环境 E E E 中操作的智能体。在每个时间步 t t t,智能体观察状态 o t ∈ O o_t \in O ot∈O,选择动作 a t ∈ A a_t \in A at∈A,并接收奖励 r t r_t rt 和下一个观察 o t + 1 o_{t+1} ot+1。轨迹 τ = ( o 0 , a 0 , r 0 , . . . , o T , a T , r T ) \tau = (o_0, a_0, r_0, ..., o_T, a_T, r_T) τ=(o0,a0,r0,...,oT,aT,rT) 捕捉一次交互 episode。任务由自然语言描述 d d d 指定。参数为 θ \theta θ 的基于 LLM 的智能体实现策略 π θ ( a t ∣ o ≤ t , d , c ) \pi_\theta(a_t|o_{\le t}, d, c) πθ(at∣o≤t,d,c),其中 c c c 代表附加上下文(例如,技能、演示)。我们的目标是学习一个策略,以在上下文长度约束 ∥ c ∥ ≤ L max \|c\| \le L_{\max} ∥c∥≤Lmax 下最大化期望回报 max θ E τ ∼ π θ ∑ t = 0 T γ t r t \max_\theta \mathbb{E}{\tau \sim \pi\theta}\\sum_{t=0}\^T \\gamma\^t r_t maxθEτ∼πθ∑t=0Tγtrt。
组相对策略优化 (GRPO)。
GRPO (Shao et al., 2024) 是一种强化学习方法,通过使用组内相对奖励来优化策略,避免了训练 critic。对于每个查询 x x x,模型采样 G G G 个响应 { y ( 1 ) , . . . , y ( G ) } \{y^{(1)}, ..., y^{(G)}\} {y(1),...,y(G)},评分以获得奖励 { R 1 , . . . , R G } \{R_1, ..., R_G\} {R1,...,RG}。GRPO 计算归一化优势并使用 PPO 风格的 clipped 目标更新策略 (Schulman et al., 2017):
J G R P O ( θ ) = E x , { y i } 1 G ∑ i = 1 G min ( r i A i , clip ( r i , 1 − ϵ , 1 + ϵ ) A i ) − β D K L ( π θ ∥ π r e f ) , ( 1 ) J_{GRPO}(\theta) = \mathbb{E}_{x, \{y_i\}} \\frac{1}{G} \\sum_{i=1}\^G \\min(r_i A_i, \\text{clip}(r_i, 1 - \\epsilon, 1 + \\epsilon) A_i) - \\beta D_{KL}(\\pi_\\theta \\\| \\pi_{ref}) , \quad (1) JGRPO(θ)=Ex,{yi}G1i=1∑Gmin(riAi,clip(ri,1−ϵ,1+ϵ)Ai)−βDKL(πθ∥πref),(1)
其中 r i = π θ ( y i ∣ x ) π o l d ( y i ∣ x ) r_i = \frac{\pi_\theta(y_i|x)}{\pi_{old}(y_i|x)} ri=πold(yi∣x)πθ(yi∣x) 是重要性比率, A i = R i − mean ( { R j } j = 1 G ) std ( { R j } j = 1 G ) A_i = \frac{R_i - \text{mean}(\{R_j\}{j=1}^G)}{\text{std}(\{R_j\}{j=1}^G)} Ai=std({Rj}j=1G)Ri−mean({Rj}j=1G) 是归一化优势, ϵ , β \epsilon, \beta ϵ,β 是超参数, π o l d \pi_{old} πold 是当前更新前的策略。
3. SKILLRL
在本节中,如图 2 所示,我们提出了 SKILLRL,这是一个旨在通过自动技能发现和递归进化弥合原始交互经验与策略改进之间差距的框架。SKILLRL 由三个核心组件组成。首先,我们开发了一种基于经验的技能蒸馏机制,将冗余轨迹转化为简洁、可操作的知识。其次,我们将这些蒸馏后的经验组织成分层技能库 S S S,实现通用和任务特定专业知识的高效检索。最后,我们引入了一种递归技能进化机制,利用 RL 动态细化技能库并与智能体策略同步。我们详细说明这些组件如下:
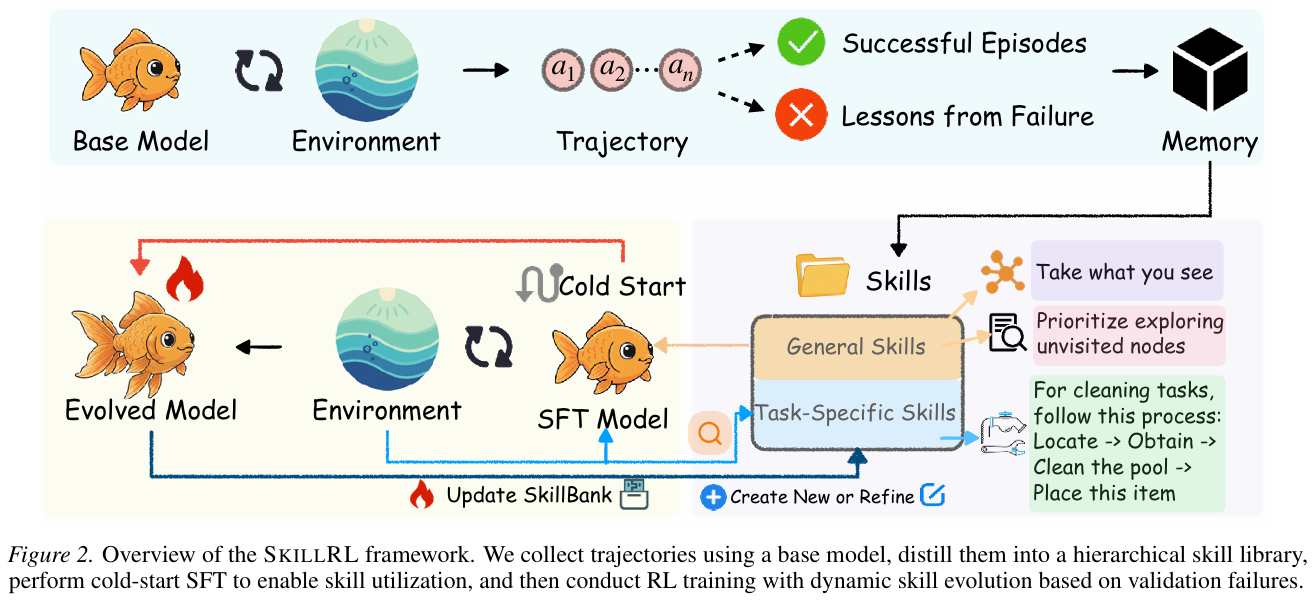
3.1. 基于经验的技能蒸馏
从环境交互中收集的原始轨迹 τ \tau τ 是冗长的,包含探索性动作、回溯和冗余步骤,掩盖了导致成功或失败的关键决策。为了将这些经验转化为可操作的知识,我们使用教师模型 M T M_T MT 将轨迹蒸馏为紧凑、可重用的技能。
具体而言,我们首先在目标环境 E E E 中部署基础 LLM 智能体 π b a s e \pi_{base} πbase 以收集多样化轨迹。与先前仅保留成功 episode 的方法不同,我们故意保留成功轨迹 T + = { τ i : r ( τ i ) = 1 } \mathcal{T}^+ = \{\tau_i: r(\tau_i) = 1\} T+={τi:r(τi)=1} 和失败轨迹 T − = { τ i : r ( τ i ) = 0 } \mathcal{T}^- = \{\tau_i: r(\tau_i) = 0\} T−={τi:r(τi)=0},其中 r ( τ ) r(\tau) r(τ) 表示二元任务成功指示器。失败轨迹揭示了失败模式和边界条件,即仅从成功中难以推断的信息。
我们根据轨迹结果应用差异化处理。对于成功轨迹 τ + ∈ T + \tau^+ \in \mathcal{T}^+ τ+∈T+,我们提取导致任务完成的战略模式:
s + = M T ( τ + , d ) . ( 2 ) s^+ = M_T(\tau^+, d). \quad (2) s+=MT(τ+,d).(2)
教师模型识别关键决策点、正确动作背后的推理以及可泛化到特定任务实例之外的模式。
对于失败轨迹 τ − ∈ T − \tau^- \in \mathcal{T}^- τ−∈T−,由于长度和噪声,直接包含在上下文中是不可行的。相反,我们合成简洁的失败教训:
s − = M T ( τ − , d ) . ( 3 ) s^- = M_T(\tau^-, d). \quad (3) s−=MT(τ−,d).(3)
分析识别:(1) 失败点,(2) 有缺陷的推理或动作,(3) 应该做什么,以及 (4) 防止类似失败的一般原则。这将冗长的失败 episode 转化为反事实。
3.2. 分层技能库 (SKILLBANK)
构建。 遵循 Agent Skills (Anthropic, 2024) 的设计原则,我们将蒸馏后的知识组织成分层技能库 SKILLBANK,以便在决策过程中高效检索相关专业知识。
技能组织。 我们将 SKILLBANK 结构化为两个级别:1) 通用技能 S g S_g Sg 捕捉适用于环境中所有任务类型的通用战略原则。这些通常包括探索策略(例如,系统搜索模式,优先访问未访问位置)、状态管理原则(例如,动作前验证前提条件)和目标跟踪启发式(例如,维护进度计数器,仅在验证完成后终止)。通用技能提供跨不同任务类别转移的基础指导。2) 任务特定技能 S k S_k Sk 编码任务类别 k k k 的专业知识。这些捕捉领域特定的动作序列、任务特定的前提条件和约束、任务类型独有的常见失败模式以及利用任务结构的优化过程。通过在收集过程中按任务类型组织轨迹,我们能够提取补充更广泛通用技能的细粒度、类别特定策略。
完整的技能库 SKILLBANK 是 S g ∪ ⋃ k = 1 K S k S_g \cup \bigcup_{k=1}^K S_k Sg∪⋃k=1KSk。每个技能 s ∈ SKILLBANK s \in \text{SKILLBANK} s∈SKILLBANK 的结构包含:简洁的名称(例如,系统探索)、描述策略的原则,以及指定适用性的何时应用条件。这种格式支持高效检索,同时提供清晰的应用指导。
技能检索。 在推理时,给定任务描述 d d d,智能体检索相关技能以增强其上下文。通用技能 S g S_g Sg 始终作为基础指导包含在内。任务特定技能通过语义相似度检索:
S r e t = TopK ( { s ∈ S k : sim ( e d , e s ) > δ } , K ) , ( 4 ) S_{ret} = \text{TopK}(\{s \in S_k : \text{sim}(e_d, e_s) > \delta\}, K), \quad (4) Sret=TopK({s∈Sk:sim(ed,es)>δ},K),(4)
其中 e d , e s e_d, e_s ed,es 分别是任务描述和技能的嵌入, δ \delta δ 是相似度阈值, K K K 控制检索技能的数量。策略随后以检索到的技能为条件:
a t ∼ π θ ( a t ∣ o ≤ t , d , S g , S r e t ) . ( 5 ) a_t \sim \pi_\theta(a_t | o_{\le t}, d, S_g, S_{ret}). \quad (5) at∼πθ(at∣o≤t,d,Sg,Sret).(5)
值得注意的是,与原始轨迹相比,技能蒸馏实现了 10--20 倍的 token 压缩,同时增强而不是降低原始经验的效用。这种压缩允许智能体在有限的上下文窗口内利用丰富的经验知识。
3.3. 递归技能进化
静态技能库无法预见智能体将遇到的所有场景。随着策略改进并探索新的状态区域,它面临现有技能提供不足指导的情况。我们在强化学习期间引入递归技能进化来解决这一限制,使技能库和智能体策略能够共同进化。
冷启动初始化。 在 RL 训练之前,我们解决一个关键挑战:基础智能体尚未学会如何有效利用技能。简单地向不变的模型提供技能收益有限 (Guo et al., 2025)。因此,我们执行冷启动监督微调 (SFT) 阶段 (Ouyang et al., 2022),其中教师模型 M T M_T MT 生成 N N N 个技能增强的推理轨迹 D S F T = { ( d i , S i , τ i ∗ ) } i = 1 N \mathcal{D}_{SFT} = \{(d_i, S_i, \tau^*i)\}{i=1}^N DSFT={(di,Si,τi∗)}i=1N,演示如何在决策过程中检索、解释和应用技能。基础模型随后在这些演示上进行微调:
θ s f t = arg min θ L C E ( D S F T ; θ ) , ( 6 ) \theta_{sft} = \arg \min_\theta \mathcal{L}{CE}(\mathcal{D}{SFT}; \theta), \quad (6) θsft=argθminLCE(DSFT;θ),(6)
其中 L C E \mathcal{L}{CE} LCE 表示交叉熵损失。 resulting 模型 π θ s f t \pi{\theta_{sft}} πθsft 既作为 RL 训练的起点,也作为 KL 正则化的参考策略 π r e f \pi_{ref} πref。
递归技能进化。 静态技能库无法预见智能体将遇到的所有场景。随着策略改进并探索新的状态区域,它面临现有技能提供不足指导的情况。我们引入递归技能进化来解决这一限制。该过程从包含 baseline 任务动作原则的初始技能库开始。
在每个验证 epoch 之后,我们监控每个任务类别 C C C 的成功率 Acc ( C ) \text{Acc}(C) Acc(C)。为了确保有针对性的增长,仅当 Acc ( C ) < δ \text{Acc}(C) < \delta Acc(C)<δ 的类别触发进化。然后我们使用感知多样性的分层采样策略收集失败轨迹 T v a l − = { τ j : r ( τ j ) = 0 } j = 1 M \mathcal{T}^-{val} = \{\tau_j: r(\tau_j) = 0\}{j=1}^M Tval−={τj:r(τj)=0}j=1M:轨迹按类别分组,按失败严重程度(负奖励)优先排序,并通过轮询采样选择以维持类别熵。然后我们将分析这些样本以识别差距:
S n e w = M T ( T v a l − , SKILLBANK ) . ( 7 ) S_{new} = M_T(\mathcal{T}^-_{val}, \text{SKILLBANK}). \quad (7) Snew=MT(Tval−,SKILLBANK).(7)
提示教师模型:(1) 识别当前技能未解决的失败模式,(2) 提出新技能以覆盖这些差距,以及 (3) 建议细化被证明无效的现有技能。库随后更新:
SKILLBANK ← SKILLBANK ∪ S n e w . \text{SKILLBANK} \leftarrow \text{SKILLBANK} \cup S_{new}. SKILLBANK←SKILLBANK∪Snew.
这创造了一个良性循环:随着智能体改进,它遇到新挑战,驱动技能库扩展,从而实现进一步改进。
基于 RL 的策略优化。 我们使用 GRPO 优化技能增强策略。对于每个具有描述 d d d 的任务,智能体首先检索相关技能,然后从当前策略 π θ \pi_\theta πθ 采样 G G G 个完整轨迹 { τ ( 1 ) , . . . , τ ( G ) } \{\tau^{(1)}, ..., \tau^{(G)}\} {τ(1),...,τ(G)}。每个轨迹 τ ( i ) \tau^{(i)} τ(i) 接收二元奖励 R i = r ( τ ( i ) ) ∈ { 0 , 1 } R_i = r(\tau^{(i)}) \in \{0, 1\} Ri=r(τ(i))∈{0,1} 表示任务成功。每个轨迹的归一化优势计算为:
A i = R i − mean ( { R j } j = 1 G ) std ( { R j } j = 1 G ) . ( 8 ) A_i = \frac{R_i - \text{mean}(\{R_j\}{j=1}^G)}{\text{std}(\{R_j\}{j=1}^G)}. \quad (8) Ai=std({Rj}j=1G)Ri−mean({Rj}j=1G).(8)
策略根据以下更新:
J ( θ ) = E d , { τ ( i ) } 1 G ∑ i = 1 G min ( ρ i A i , clip ( ρ i , 1 − ϵ , 1 + ϵ ) A i ) − β D K L ( π θ ∥ π r e f ) , ( 9 ) J(\theta) = \mathbb{E}_{d, \{\tau^{(i)}\}} \\frac{1}{G} \\sum_{i=1}\^G \\min(\\rho_i A_i, \\text{clip}(\\rho_i, 1 - \\epsilon, 1 + \\epsilon) A_i) - \\beta D_{KL}(\\pi_\\theta \\\| \\pi_{ref}) , \quad (9) J(θ)=Ed,{τ(i)}G1i=1∑Gmin(ρiAi,clip(ρi,1−ϵ,1+ϵ)Ai)−βDKL(πθ∥πref),(9)
其中 ρ i = π θ ( τ ( i ) ∣ d , S g , S r e t ) π o l d ( τ ( i ) ∣ d , S g , S r e t ) \rho_i = \frac{\pi_\theta(\tau^{(i)}|d, S_g, S_{ret})}{\pi_{old}(\tau^{(i)}|d, S_g, S_{ret})} ρi=πold(τ(i)∣d,Sg,Sret)πθ(τ(i)∣d,Sg,Sret) 是在技能增强上下文上计算的重要性比率。锚定到 π r e f = π θ s f t \pi_{ref} = \pi_{\theta_{sft}} πref=πθsft 的 KL 惩罚确保 RL 优化在提高任务性能的同时保留学到的技能利用能力。完整的训练过程总结在算法 1 中。
算法 1 SKILLRL: 递归技能增强 RL
要求: 基础模型 π b a s e \pi_{base} πbase, 教师 M T M_T MT, 环境 E E E
确保: 训练策略 π θ ∗ \pi_{\theta^*} πθ∗, 进化技能库 SKILLBANK ∗ \text{SKILLBANK}^* SKILLBANK∗
1: ▹ \triangleright ▹ 基于经验的技能蒸馏
2: T + , T − ← Rollout ( π b a s e , E ) \mathcal{T}^+, \mathcal{T}^- \leftarrow \text{Rollout}(\pi_{base}, E) T+,T−←Rollout(πbase,E)
3: for all τ + ∈ T + \tau^+ \in \mathcal{T}^+ τ+∈T+ do
4: s + ← M T ( τ + ) \quad s^+ \leftarrow M_T(\tau^+) s+←MT(τ+)
5: end for
6: for all τ − ∈ T − \tau^- \in \mathcal{T}^- τ−∈T− do
7: s − ← M T ( τ − ) \quad s^- \leftarrow M_T(\tau^-) s−←MT(τ−)
8: end for
9: ▹ \triangleright ▹ 分层技能库构建
10: S g ← S_g \leftarrow Sg← 来自蒸馏经验的通用技能
11: for all 任务类型 k k k do
12: S k ← \quad S_k \leftarrow Sk← 类别 k k k 的任务特定技能
13: end for
14: SKILLBANK ← S g ∪ ⋃ k S k \text{SKILLBANK} \leftarrow S_g \cup \bigcup_k S_k SKILLBANK←Sg∪⋃kSk
15: ▹ \triangleright ▹ 通过 RL 递归技能进化
16: // 冷启动初始化
17: D S F T ← M T ( E , SKILLBANK ) \mathcal{D}_{SFT} \leftarrow M_T(E, \text{SKILLBANK}) DSFT←MT(E,SKILLBANK)
18: θ ← SFT ( π b a s e , D S F T ) ; π r e f ← π θ \theta \leftarrow \text{SFT}(\pi_{base}, \mathcal{D}{SFT}); \pi{ref} \leftarrow \pi_\theta θ←SFT(πbase,DSFT);πref←πθ
19: // 带递归进化的 RL
20: for epoch = 1 = 1 =1 to N N N do
21: \quad for all 任务 d d d do
22: S r e t ← Retrieve ( d , SKILLBANK ) \quad \quad S_{ret} \leftarrow \text{Retrieve}(d, \text{SKILLBANK}) Sret←Retrieve(d,SKILLBANK)
23: \quad \quad Sample { τ ( i ) } i = 1 G ∼ π θ ( ⋅ ∣ d , S g , S r e t ) \{\tau^{(i)}\}{i=1}^G \sim \pi\theta(\cdot|d, S_g, S_{ret}) {τ(i)}i=1G∼πθ(⋅∣d,Sg,Sret)
24: \quad \quad Compute { R i } i = 1 G \{R_i\}_{i=1}^G {Ri}i=1G
25: \quad end for
26: \quad if validation epoch then
27: T v a l − ← \quad \quad \mathcal{T}^-_{val} \leftarrow Tval−← 失败的验证轨迹
28: S n e w ← M T ( T v a l − , SKILLBANK ) \quad \quad S_{new} \leftarrow M_T(\mathcal{T}^-_{val}, \text{SKILLBANK}) Snew←MT(Tval−,SKILLBANK)
29: SKILLBANK ← SKILLBANK ∪ S n e w \quad \quad \text{SKILLBANK} \leftarrow \text{SKILLBANK} \cup S_{new} SKILLBANK←SKILLBANK∪Snew
30: \quad end if
31: end for
32: return π θ , SKILLBANK \pi_\theta, \text{SKILLBANK} πθ,SKILLBANK
4. 实验
我们在九个具有挑战性的 LLM 智能体基准上评估 SKILLRL:ALFWorld、WebShop 和七个搜索增强 QA 任务。我们的实验解决以下问题:1) SKILLRL 与最先进方法相比如何?2) 每个组件的贡献是什么?3) 技能库在训练期间如何进化?4) 技能是否加速模型收敛?
4.1. 实验设置
环境。 ALFWorld (Shridhar et al.) 是一个与 ALFRED 具身 AI 基准对齐的基于文本的游戏。智能体必须通过文本命令导航并与对象交互来完成家庭任务。WebShop (Yao et al., 2022a) 模拟网页购物。智能体导航真实的网页界面以查找和购买匹配用户规格的产品。此外,我们还在搜索增强 QA 任务上评估 SKILLRL 的性能,包括单跳 QA 数据集 (NQ (Kwiatkowski et al., 2019), TriviaQA (Joshi et al., 2017), 和 PopQA (Mallen et al., 2023)) 和多跳 QA 数据集 (HotpotQA (Yang et al., 2018), 2Wiki (Ho et al., 2020), MuSiQue (Trivedi et al., 2022), 和 Bamboogle (Press et al., 2023))。
基线。 我们将 SKILLRL 与四类竞争方法进行比较。首先,我们包括闭源 LLM, specifically GPT-4o (OpenAI, 2024) 和 Gemini-2.5-Pro (Comanici et al., 2025),它们代表通用推理和指令遵循的最先进水平。其次,我们评估基于提示的智能体或基于记忆的方法,包括 ReAct (Yao et al., 2022b) 和 Reflexion (Shinn et al., 2023),它们依赖上下文提示进行多步推理,以及 Mem0 (Chhikara et al., 2025), ExpeL (Zhao et al., 2024), 和 MemP (Fang et al., 2025),它们利用外部记忆或经验池来指导行为而不进行参数更新。第三,我们考虑基于 RL 的方法,包括基于组的在线 RL 算法,如 RLOO (Ahmadian et al., 2024) 和 GRPO (Shao et al., 2024),它们通过轨迹组上的优势估计优化策略。最后,我们与基于记忆的 RL 方法进行比较,例如 EvolveR (Wu et al., 2025), MemRL (Zhang et al., 2026), 以及 Mem0+GRPO 和 SimpleMem (Liu et al., 2026)+GRPO 的组合,它们将持久记忆机制直接集成到强化学习优化过程中以处理长期依赖。对于搜索增强 QA,我们将 SKILLRL 与 R1-Instruct, Search-o1 (Li et al., 2025), Search-R1 (Jin et al., 2025), ZeroSearch (Sun et al., 2025), 和 StepSearch (Zheng et al., 2025) 进行比较。
实现细节。 我们使用 Qwen2.5-7B-Instruct (Bai et al., 2023) 作为基础模型,OpenAI o3 (OpenAI, 2025a) 作为技能蒸馏和 SFT 数据生成的教师模型。对于 RL 训练,我们使用 GRPO,学习率 1 × 10 − 6 1 \times 10^{-6} 1×10−6,batch size 16,组大小 8,和 4 个梯度累积步骤。我们设置 K = 6 K=6 K=6 用于任务特定技能检索, δ = 0.4 \delta=0.4 δ=0.4 用于收集失败轨迹。有关训练超参数的更多详细信息,请参见附录 B.1。
4.2. 主要结果
与基线的比较。 如表 1 所示,我们在两个基准上将 SKILLRL 与基线方法进行比较。我们的方法始终优于所有基线,主要观察结果如下:1) 显著优于基于提示的方法。 SKILLRL 在 ALFWorld 上 achieves 89.9% 成功率,在 WebShop 上 achieves 72.7%,以大幅优势优于最佳基于提示的基线。这一差距表明,虽然上下文学习可以利用过去的经验,但它通常无法从冗长的轨迹中提炼可操作的知识或根本性地调整智能体的策略。
-
优于 Vanilla RL。 RL 训练带来显著增益,但 SKILLRL 始终超越标准 RL 基线。与 PPO, RLOO, 和 GRPO 相比,SKILLRL 实现了最佳整体性能。值得注意的是,由于 SKILLRL 利用 GRPO 作为其基础优化器,ALFWorld 上超过 GRPO 的 12.3% 绝对改进(从 77.6% 到 89.9%)直接归因于我们的技能增强机制,而不是算法方差。在 Cool 和 Pick2 等复杂子任务中,SKILLRL 分别优于 GRPO 23.0% 和 22.8%,证明结构化技能先验有效地加速并增强了稀疏奖励环境中的策略学习。
-
优于基于记忆的 RL。 SKILLRL 显著优于现有的基于记忆的 RL 框架,它们在管理和更新经验方面有所不同。MemRL 仅使用 RL 更新其记忆库而保持策略冻结,无法适应复杂环境,在 ALFWorld 上仅产生 21.4%。EvolveR 联合更新策略和记忆库,显示改进 (43.8%) 但仍受限于其对粗糙轨迹存储的依赖。为了提供更具竞争力的基线,我们实现了 Mem0+GRPO,它将最先进的基于提示的记忆机制与优化的策略模型相结合。虽然这种混合方法将 ALFWorld 上的性能提高到 54.7%,WebShop 上提高到 37.5%,但它仍然大幅落后于 SKILLRL(约 35.2% 绝对成功率差距)。
这些结果验证了我们的核心假设:有效的经验转移需要高层技能抽象和共同进化的库,而不是简单的轨迹压缩或基于提示的记忆检索。
与闭源模型的比较。 值得注意的是,使用 Qwen2.5-7B-Instruct 的 SKILLRL 显著优于大得多的闭源模型,如表 1 所示。在 ALFWorld 上,我们的方法超过 GPT-4o (OpenAI, 2024) 41.9%,超过 Gemini-2.5-Pro (Comanici et al., 2025) 29.6%。这表明有效的技能学习可以补偿模型规模,使较小的开源模型能够通过结构化经验知识实现卓越的任务性能。
搜索增强 QA 上的性能。 如表 2 所示,SKILLRL 实现了 47.1% 的最先进平均分,显著优于 Search-R1 (38.5%) 和 EvolveR (43.1%)。主要观察结果包括:1) ** superior multi-hop Reasoning:** SKILLRL 在复杂任务如 Bamboogle 中表现出色,超过 EvolveR 19.4%。这表明分层技能有效地指导多步信息合成。2) 强泛化性: 尽管在有限数据集 (NQ, HotpotQA) 上训练,SKILLRL 在 OOD 任务如 TriviaQA 和 2Wiki 上保持竞争性性能,证实蒸馏的搜索策略是任务无关的。
4.3. 分析
在本节中,我们提供每个模块有效性和技能进化动态的详细分析。
消融研究。 我们进行消融实验以评估每个组件的贡献,结果在表 3 中。根据结果:(1) 移除分层结构(即仅任务特定技能)使 ALFWorld 性能降低 13.1%,WebShop 降低 11.3%,表明通用战略原则提供 essential foundational guidance。(2) 用原始轨迹替换技能库导致最大退化(高达 25%),这直接支持我们的动机,即抽象优于记忆。原始经验引入显著冗余和噪声,阻碍有效知识转移。(3) 冷启动 SFT 证明是关键(没有它下降 20%),证实基础模型需要初始显式演示阶段来学习如何自适应检索和利用抽象技能,然后进入 RL 阶段。(4) 动态进化贡献了 5.5% 的改进,确保技能库是动态组件而不是静态数据库。这种共同进化允许智能体通过解决初始技能集未覆盖的新兴失败模式来迭代细化其内部策略。
ALFWorld 上的每任务分析。 表 1 按任务类型分解了 ALFWorld 性能。最大增益在 PickTwo (+23%), Cool (+22%) 和 Heat (+15%) 上,这些是最具挑战性的任务,需要多步规划和状态跟踪。任务特定技能在这里特别有价值,捕捉策略如"当 picking 两个对象时,在搜索第二个之前验证第一个已固定",解决常见失败模式。
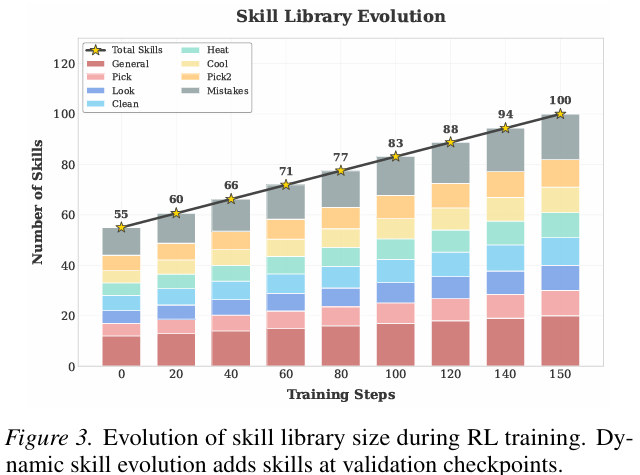
技能库增长。 图 3 显示技能库在训练期间如何进化。初始技能库包含 55 个技能(12 个通用,43 个任务特定)。通过动态进化,这在训练结束时增长到 100 个技能(步骤 150)。增长主要由任务特定技能驱动(从 43 增加到 80),而通用技能显示更稳定的增加(从 12 到 20)。值得注意的是,我们观察到各种任务类别的平衡扩展,确保智能体为每个环境 rollout 发展专业知识。这种整体扩展反映了智能体细化其储备并在特定任务类型内处理多样化场景的能力 increasing。
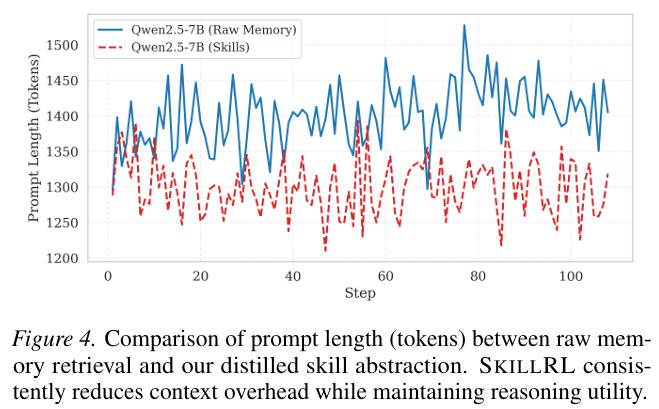
上下文效率。 为了评估技能抽象对推理开销的影响,我们将 SKILLRL 的平均提示长度与使用原始轨迹的基于记忆的基线 (Qwen2.5-7B with Raw Memory) 在图 4 中进行比较。结果显示,虽然原始记忆方法遭受高且波动的 token footprint(平均 \\sim1,450 tokens),SKILLRL 保持显著更 lean 的提示(平均 \<1,300 tokens),实现约 10.3% 的上下文长度减少。这种效率源于我们的蒸馏机制,它将冗长的环境交互压缩为高密度、可操作的技能。值得注意的是,SKILLRL 需要比基于记忆的基线更少的上下文来实现 superior performance,表明技能抽象有效地缓解了传统基于记忆的智能体中常见的 context-bloat 问题。
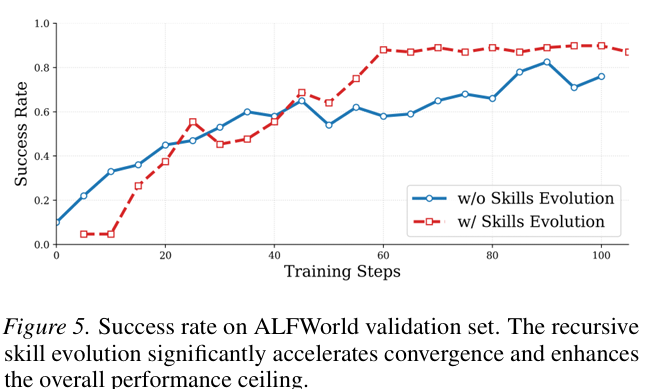
进化动态。 图 5 说明了有无递归技能进化机制的强化学习训练曲线。我们观察到,虽然无进化的 SKILLRL 显示稳定改进,但带技能进化的 SKILLRL 表现出显著更高的学习率和 superior asymptotic performance。具体而言,SKILLRL 在 60 个训练步骤内实现超过 80% 的成功率,而基线需要约 90 个步骤才能达到较低的峰值。这种收敛加速表明,新技能的动态引入和现有技能的细化有效地为智能体提供 timely strategic guidance 以克服局部最优。此外,更高的性能 ceiling 验证了技能库和策略的共同进化允许智能体适应静态记忆方法无法解决的 increasingly complex task scenarios。
定性分析。 为了进一步调查 SKILLRL 如何利用学到的知识,我们在图 6 中可视化了 ALFWorld 和 WebShop 上的推理过程。案例研究表明,我们训练的智能体可以有效地从 SKILLBANK 检索和执行相关技能以指导其决策。例如,在 WebShop 任务中,智能体调用通用策略如"Prioritize Core Keywords"以及任务特定启发式"Focus Key Query"以确保产品满足有限预算内的所有约束。同样,在 ALFWorld 中,智能体协调分层技能,即使用"Progressive Goal Decomposition"进行高层规划,以及"No Appliance Before Object"以避免常见逻辑陷阱。这种通用和特定技能的无缝集成证实了智能体不仅仅记忆轨迹,而是发展了对任务逻辑的结构化理解,允许更 robust 和 efficient problem-solving。

5. 相关工作
LLM 智能体。 能力强的 LLM 的出现催化了自主智能体系统的快速发展 (Wei et al., 2026)。ReAct (Yao et al., 2022b) 交错推理和动作, enabling chain-of-thought style planning during interaction,而 Reflexion (Shinn et al., 2023) 通过对过去失败的自我反思引入 verbal reinforcement。像 AutoGen (Wu et al., 2024) 和 CAMEL (Li et al., 2023) 这样的框架展示了通用多智能体能力,具有 automated orchestration 和 diverse tool integration。虽然最初的努力集中在 coding 或 basic arithmetic 等受限任务上,但这些方法主要依赖 in-context learning (ICL) (Dong et al., 2024)。然而,随着任务变得更加复杂,这些智能体难以扩展,因为它们将每次交互视为孤立事件,并且必须从头开始每个新任务而不任何 prior knowledge。
智能体中的记忆机制。 为了克服有限上下文窗口的限制和智能体无法从经验中学习的问题,外部记忆架构已成为智能体设计的 cornerstone (Hu et al., 2025; Wang, 2025)。早期系统主要利用静态 RAG 范式或将原始轨迹存储为 few-shot 示例 (Wang et al.; Chhikara et al., 2025; Zhang et al., 2025a; Wang et al., 2024)。然而,原始轨迹通常是 token-heavy 并包含显著冗余和噪声,这可能导致性能下降。当前研究已转向 self-improving memory,将交互蒸馏为高层见解或 procedural tips (Wang & Chen, 2025; Tang et al., 2025; Fang et al., 2025; Zhao et al., 2024; Ouyang et al., 2025; Wei et al., 2025)。虽然一些最近的工作探索通过在线训练更新记忆库以提高效率 (Zhang et al., 2025b; 2026),但许多现有方法仍然难以区分高价值经验和噪声,或者未能提炼可以指导内部决策的核心原则。
智能体技能与强化学习的进化。 智能体技能 (Anthropic, 2024) 的发展,即捕捉子任务本质的 compact, reusable strategies,越来越多地通过 Continual Learning (CL) 和 RL 的视角来看待。传统 CL (Parisi et al., 2019) 专注于预定义任务中的知识保留,但 self-evolving agents (Gao et al., 2025; Xia et al., 2025; Liu et al., 2025) 旨在 open-ended environments 中的 active skill acquisition (Fang et al., 2025; Wang et al., 2025)。虽然 RL 广泛用于 align LLMs (Schulman et al., 2017; Ouyang et al., 2022),或通过 rule-based verifiers 提高推理 (Shao et al., 2024),但由于 sparse rewards 和 long horizons,将其应用于智能体技能仍然具有挑战性。与先前将记忆视为静态或辅助源的基于记忆的 RL 不同,最近的趋势表明,高效经验转移的关键在于抽象 (Wu et al., 2025)。我们的工作在此基础上,将技能库视为与智能体策略共同进化的动态组件,利用 RL 通过递归失败分析细化结构化技能。
6. 结论
我们介绍了 SKILLRL,这是一个 LLM 智能体中技能增强强化学习的框架。通过将原始轨迹蒸馏为 compact, reusable skills 并在训练期间启用 dynamic skill evolution,SKILLRL 在 ALFWorld 和 WebShop 上实现了最先进的性能,同时使用比基于记忆的方法 substantially less context。我们的工作表明,从经验到技能的抽象是构建 capable, sample-efficient agents 的强大原则。
致谢
这项工作部分得到了 Amazon Research Award, Cisco Faculty Research Award, NEC Laboratories America Research Grant, 和 Coefficient Giving 的支持。
参考文献
(此处保留原文参考文献列表,格式略作调整以符合中文语境,但内容保持英文以便引用)
Ahmadian, A., et al. Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024.
Anthropic. The claude 3 model family: Opus, sonnet, haiku, 2024.
... (其余参考文献略,保持原样)
附录 A. 提示
在本节中,我们提供了框架不同阶段使用的完整提示模板。这些模板旨在确保一致的智能体行为和跨各种环境的结构化数据生成。
A.1. 智能体执行提示
以下提示用于在线推理阶段。这些模板为智能体提供当前任务描述、先前交互历史和一组检索到的技能(经验)以指导其决策过程。
提示明确强制在动作选择之前进行 Chain-of-Thought (CoT) 推理步骤。
提示 A.1: 带技能的 ALFWorld 智能体执行系统提示:
你是一个在 ALFRED 具身环境中操作的专家智能体。你的任务是:{任务描述}
检索到的相关经验
{检索到的记忆}
当前进度
在此步骤之前,你已经采取了 {步数} 步。以下是最近的 {历史长度} 个观察和你采取的相应动作:{动作历史} 你现在处于步骤 {当前步骤},你的当前观察是:{当前观察} 你当前情况的可允许动作是:{可允许动作}。
现在轮到你采取动作。你应该首先逐步推理当前情况。此推理过程 MUST 被 enclosed within <think></think> 标签。一旦你完成推理,你应该为当前步骤选择一个可允许动作并在 <action></action> 标签内呈现它。
提示 A.2: 带技能的 WebShop 智能体执行系统提示:
你是一个在 WebShop 电子商务环境中操作的专家自主智能体。你的任务是:{任务描述}。
检索到的相关经验
{检索到的记忆}
当前进度
在此步骤之前,你已经采取了 {步数} 步。以下是最近的 {历史长度} 个观察和你采取的相应动作:{动作历史} 你现在处于步骤 {当前步骤},你的当前观察是:{当前观察} 你当前情况的可允许动作是:{可用动作}。
现在轮你为当前步骤采取一个动作。你应该首先逐步推理当前情况,然后仔细思考哪个可允许动作最好地推进购物目标。此推理过程 MUST 被 enclosed within <think></think> 标签。一旦你完成推理,你应该为当前步骤选择一个可允许动作并在 <action></action> 标签内呈现它。
A.2. 技能生成和蒸馏提示
这些提示用于技能发现和库初始化阶段。它们指导高能力教师模型分析交互轨迹,识别失败模式,并将可重用、可操作的技能蒸馏为结构化 JSON 格式。
提示 B.1: 来自失败的动态技能发现
分析这些失败的 {环境描述} 智能体轨迹并建议添加 NEW 技能。
失败轨迹:{失败示例} 现有技能标题:{现有标题}
生成 1-3 个 NEW 可操作技能以帮助避免这些失败。每个技能必须有:技能 id, 标题 (3-5 词), 原则 (1-2 句), 何时应用。技能 id 应唯一并遵循模式:"dyn_001", "dyn_002", 等。
仅返回技能的 JSON 数组,无其他文本。
提示 B.2: 初始技能蒸馏 (ALFWorld)
你是将智能体行为模式蒸馏为简洁、可操作技能的专家。分析这些来自在家庭环境 (ALFWorld) 中操作的具身 AI 智能体的成功和失败轨迹。
成功轨迹:{成功模式} 失败轨迹:{失败模式} 生成 8-12 个适用于 ALL 任务类型的通用技能。这些应该是:1. 简洁; 2. 可操作; 3. 可转移; 4. 失败感知。关注:导航,对象操作,状态跟踪,错误恢复,和容器交互规则。
仅返回 JSON 数组,无其他文本。
提示 B.3: 初始技能蒸馏 (WebShop)
你是将智能体行为模式蒸馏为简洁、可操作技能的专家。分析这些来自在线购物环境 (WebShop) 中操作的 AI 智能体的成功和失败轨迹。
成功轨迹:{成功模式} 失败轨迹:{失败模式}
生成 10-15 个通用技能。关注:搜索查询 formulation,产品选择启发式,选项配置 (大小,颜色等),约束验证,导航模式,和价格处理。
仅返回 JSON 数组,无其他文本。
A.3. 冷启动轨迹生成提示
为了弥合基础模型和目标性能之间的差距,我们使用以下提示生成高质量合成轨迹用于 Supervised Fine-Tuning (SFT)。这些提示指导教师模型解决任务,同时显式演示特定技能的应用,从而为学生模型提供清晰的学习信号。
提示 C.1: 合成轨迹生成 (ALFWorld)
你是 ALFRED 具身环境中的专家智能体。你将获得一个任务和相关技能以应用。你的目标是生成一个演示这些技能 proper use 的成功轨迹。
你应该生成一个逐步轨迹,其:1. 适当使用提供的技能; 2. 在环境中采取现实动作; 3. 成功完成任务; 4. 演示良好规划和系统探索。
对于每个步骤,你应该:
• 使用 <think></think> 标签思考当前情况。
• 使用 <action></action> 标签选择适当动作。
• 动作应该是简单命令如"go to cabinet 1", "open drawer 2", "take apple 1", "put apple 1 in/on countertop 1"。
生成从开始到结束的完整轨迹。任务完成时停止。
提示 C.2: 合成轨迹生成 (WebShop)
你是 WebShop 电子商务环境中的专家购物智能体。你将获得一个购物任务和相关技能以应用。你的目标是生成一个演示这些技能 proper use 的成功轨迹。
你应该生成一个逐步轨迹,其:1. 适当使用提供的技能; 2. 在 WebShop 环境中采取现实动作; 3. 成功找到并购买请求的产品; 4. 演示良好搜索策略和产品评估。
对于每个步骤,你应该:
• 使用 <think></think> 标签思考当前情况。
• 使用 <action></action> 标签选择适当动作。
• 动作可以是:searchquery, clickelement, 或 buy now。
生成从开始到结束的完整轨迹。购买完成时停止。
附录 B. 附加实验细节
B.1. 超参数
表 4. SKILLRL 超参数。
| 超参数 | 值 |
|---|---|
| 冷启动 SFT | |
| 学习率 | 1 × 10 − 4 1 \times 10^{-4} 1×10−4 |
| Batch size | 16 |
| Epochs | 3 |
| SFT 示例 | 7,500 (AlfWorld) / 2,400 (WebShop) |
| RL 训练 | |
| 学习率 | 1 × 10 − 6 1 \times 10^{-6} 1×10−6 |
| Batch size | 64 |
| KL loss Coef | 0.01 |
| Invalid Action Penalty Coef | 0.1 |
| Max Prompt Length | 6,000 |
| Max Response Length | 1,024 |
| Epoch | 150 |
| 技能检索 | |
| Top-K retrieval | 6 |
| Validation interval | 5 Steps |
| Update Threshold δ \delta δ | 0.4 |
| Max failures analyzed | 10 (SR < 0.4) / 5 (SR > 0.4) |
| Max new skills per evolution | 3 |
B.2. 计算资源
所有实验在具有 8 个 NVIDIA H100 80GB GPUs 的集群上进行。训练时间:
• 轨迹收集:3 小时
• 技能蒸馏:0.5 小时
• 冷启动 SFT:2 小时
• RL 训练:24 小时
总 wall-clock 时间:每个实验约 30 小时。
附录 C. 技能库说明
在本节中,我们提供了 ALFWorld 和 WebShop 环境的蒸馏技能和一些错误分类的示例目录。表 5 和 7 详细说明了分别为具身操作和基于网络的购物蒸馏的通用技能,强调了系统探索和约束满足所需的可操作原则。
此外,我们在表 6 和表 8 中提供了失败案例的结构化分析,分类了常见错误,从 ALFWorld 中的空间推理循环到 WebShop 中的价格转变疏忽,以及它们的根本原因和提出的缓解策略。
表 5. ALFWorld 的 SKILLBANK 示例蒸馏技能。 本表总结了从原始轨迹 derived 的通用模式和应用逻辑。
| ID | 技能标题 | 原则 (可操作模式) | 何时应用 |
|---|---|---|---|
| 通用探索与获取技能 | |||
| gen_001 | 系统探索 | 在重新访问之前 exactly once 搜索每个 plausible surface 或 container; 优先未见位置。 | 任何时候目标计数未满足且未探索区域 remaining。 |
| gen_002 | 即时获取 | 一旦所需对象变得 visible 和 reachable,立即获取它。 | 首次视觉确认目标相关对象时。 |
| gen_003 | 目的地优先策略 | 拾取目标对象后,直接导航到 known target receptacle 并放置它。 | 持有任何目标对象而目标位置 identified 时。 |
| 状态改变与空间关系技能 | |||
| gen_005 | 早期使用状态改变工具 | 获取对象,然后立即使用 nearest suitable appliance (heat/cool/clean) before placement。 | 拾取需要温度或清洁度改变的对象后。 |
| gen_006 | 首先建立空间关系 | 首先 locate 参考对象,adjust its state if needed,然后在 specified region 搜索或放置。 | 包含介词如"under", "inside", 或"on"的任务。 |
| 可靠性与错误恢复 | |||
| gen_014 | 循环逃脱触发 | 如果最后 3--5 个动作不改变状态,switch to an untried search branch or action type。 | 几个连续 no-progress 观察后。 |
| gen_015 | 动作前健全性检查 | 在执行 manipulative commands 之前确认 prerequisites (hand free, capacity, power)。 | 在任何可能 legally fail 的命令之前。 |
表 6. ALFWorld 的常见智能体失败和缓解策略。
| ID | 失败描述 | 根本原因 (为何发生) | 缓解 (如何避免) |
|---|---|---|---|
| err_001 | 冗余重新访问 | 缺乏 explored areas 的显式记忆; 策略 degenerate into local loops。 | 维护 exploration map; 优先 unvisited candidates。 |
| err_006 | 跳过状态改变 | conflates object presence with goal satisfaction; 省略 cleanliness/temp checks。 | 在 placement 之前将 state precondition checks 集成到 planner 中。 |
表 7. WebShop 导航的示例蒸馏技能。 这些技能代表智能体用于处理大规模产品搜索和约束满足的战略模式。
| ID | 技能标题 | 原则 (可操作模式) | 何时应用 |
|---|---|---|---|
| 搜索与查询工程 | |||
| gen_001 | 优先核心关键词 | 包括 product type, 1-2 functional attributes, 和 hard constraints; 省略 secondary descriptors。 | 在发出 first search 或 refining over-specific queries 之前。 |
| gen_002 | 迭代细化 | 调整 keywords 或 apply site filters 而不是 repeating the same failed query。 | 当结果 irrelevant 或 repeat 尽管多次搜索。 |
| 产品评估与验证 | |||
| gen_003 | 点击前扫描 | 在 results 中阅读 titles, thumbnails, 和 prices 以确保 plausibility before opening a link。 | 在搜索结果页面上 choosing the next product to inspect 时。 |
| gen_004 | 早期验证,快速中止 | 立即 check category, attributes, 和 price on the product page; 如果 any constraint is violated 则 leave。 | 在每个 product detail page 上的 first observation 内。 |
| gen_006 | 确认隐藏属性 | 打开 Description/Features sections 以确保 non-visible specs (e.g., material) meet constraints。 | 当 constraints 从 title 或 variant list 不明显时。 |
| 配置与交易 | |||
| gen_005 | 设置强制变体 | 在 evaluating price or purchasing 之前 Always select required options (size, color, etc.)。 | 在 confirming product match 但 before any purchase action 后。 |
| gen_007 | 检查变体定价 | 对于 price ranges,select the exact variant combination 以 verify the specific price is within budget。 | Whenever price changes with variant selection or shows as a range。 |
| gen_013 | 果断购买 | 一旦 all constraints and prices are confirmed on a variant,立即 Execute 'Buy Now'。 | 在 validating every constraint on the current product variant 后。 |
表 8. 基于网络的购物任务中的常见失败。
| ID | 失败描述 | 根本原因 | 缓解策略 |
|---|---|---|---|
| err_001 | 查询中 missing constraints | 省略 size 或 price caps,leading to overwhelming or irrelevant result sets。 | 首先 assemble full requirement list; 确保 every hard constraint is in the query string。 |
| err_004 | 价格转变疏忽 | fails to notice price changes after selecting a specific size or color variant。 | 在 every option change 后 re-read the price element before proceeding to checkout。 |
| err_005 | 过早购买 | 在 setting mandatory variants 之前 Clicks "Buy Now",leading to errors or wrong items。 | 在 buying 之前 Validate that every required dropdown/radio option is explicitly selected。 |
| err_009 | 忽略库存状态 | 通过 ignoring disabled buttons or stock labels attempts to purchase out-of-stock items。 | verify that the 'Add to Cart' button is enabled and no 'Out of Stock' message is present post-selection。 |
| err_011 | 赞助链接分心 | clicks loosely matched ads, diverting the workflow from organic, suitable products。 | implement ad-label detection; prioritize organic listings for higher constraint reliability。 |
附录 D. 附加案例
案例 1: WebShop 鞋类 (功能约束)
任务:我想要一双男士黑色防滑工作鞋,尺码 10,橡胶底,价格低于 $50.00。
技能 foo_002 在描述中验证特征; foo_004 在变体选择后确认价格。
避免 err_001 省略价格上限; err_003 选择错误的产品类别。
带技能引导推理的智能体轨迹
步骤 1 观察:WebShop 主页。
思考:根据 gen_001,我将在查询中包含关键约束 (类型,功能,颜色,价格)。
动作:searchmen black slip resistant work shoes rubber sole under 50
步骤 2 观察:结果:1 Chef Shoes 38.99; \[2\] Kitchen Shoes 42.50; 3 Steel Toe Boots $55.99。
思考:gen_003 物品 1 在预算内并匹配功能。物品 3 超预算 (跳过)。
动作:clickItem 1
步骤 3 观察:产品页面。价格:35.99-45.99。颜色:黑色,白色。尺码:7-12。
思考:foo_002 描述确认橡胶底。现在选择黑色和尺码 10 foo_003。
动作:clickBlack → click10
步骤 5 观察:已选:黑色,尺码 10。价格更新为 $38.99。
思考:foo_004 38.99 \< 50。所有约束 (颜色,尺码,功能,价格) 满足。
动作:clickBuy Now
结果:成功------以 $38.99 购买。关键技能:foo_002 (验证), foo_004 (价格检查)。
案例 2: 电子产品 (带中止和重试的扬声器)
任务:我需要一个便携式蓝牙扬声器,防水,黑色,价格低于 $30.00。
技能 ele_001 约束丰富搜索; ele_004 快速退出不匹配; gen_002 迭代细化。
避免 err_002 搜索中 overly specific variant names; ele_006 避免点击循环。
智能体轨迹:处理缺失约束
步骤 1 观察:WebShop 主页。
思考:ele_001 打包所有 mandatory attributes: portable, bluetooth, waterproof, black, <$30。
动作:searchportable bluetooth speaker waterproof black under 30
步骤 2 观察:结果:1 Waterproof Speaker 28.99; \[2\] Mini LED Speaker 19.99; 3 20W Speaker $35.50。
思考:ele_005 物品 1 匹配 most keywords 和 price。
动作:clickItem 1
步骤 3 观察:产品页面 (物品 1)。颜色:蓝色,红色,绿色,军绿色。黑色不可用。
思考:gen_004 早期验证,快速中止:无黑色选项!ele_004 立即退出以找到另一个 candidate。
动作:clickBack to Search
步骤 4 观察:回到搜索结果。
思考:gen_002 迭代细化。物品 2 $19.99 是 next best candidate。
动作:clickItem 2
步骤 5 观察:产品页面 (物品 2)。颜色:黑色,蓝色,红色。规格:IPX5 防水。
思考:ele_002 黑色可用!IPX5 确认防水。选择黑色。
动作:clickBlack
步骤 6 观察:黑色已选。最终价格:$19.99。
思考:ele_003 19.99 \< 30。所有规格 (黑色,便携式,防水) 验证。
动作:clickBuy Now 结果:成功------通过 early exit 高效处理属性不匹配。应用的关键技能:gen_004 (快速中止), ele_004 (不匹配退出)。
案例 1: ALFWorld 清洁任务 (生菜→水槽→台面)
任务:清洁一些生菜并把它放在台面上。
核心技能 cle_001 阶段排序计划 (定位→清洁→放置); cle_006 使用位置先验 (食物在冰箱)。
避免的错误 err_002 跳过封闭容器; err_003 忽略可见目标对象。
步骤 1-3 观察:冰箱 1 是封闭的。动作:open fridge 1 → take lettuce 1
推理:根据 cle_006,食物可能在冰箱里。gen_002 一见生菜立即抓取。
步骤 4-6 观察:到达 sinkbasin 1。动作:clean lettuce 1 with sinkbasin 1
推理:根据 cle_001 阶段 2:带到水源。cle_003 直接去水槽。
步骤 7 观察:到达 countertop 1。动作:put lettuce 1 in/on countertop 1
推理:根据 gen_003 目的地优先:立即放置清洁对象以完成。
结果:成功 (7 步)------使用的技能:gen_010 (分解), cle_003 (水槽优先)。
案例 2: ALFWorld 加热任务 (鸡蛋→微波炉→台面)
任务:加热一些鸡蛋并把它放在台面上。
核心技能 hea_001 首先固定确切目标; hea_003 打开 - 放置 - 加热序列; hea_004 对象前无电器。
步骤 1-3 观察:台面 1 (无鸡蛋) → 台面 2 (发现鸡蛋)。动作:take egg 1
推理:hea_004 持有对象前避免微波炉。hea_002 表面系统搜索。
步骤 4-6 观察:微波炉 1 是封闭的。动作:open microwave 1 → heat egg 1
推理:hea_003 正确序列:首先开门,然后 initiate state change。
步骤 7-8 观察:鸡蛋已加热。动作:go to countertop 1 → put egg 1
推理:hea_005 直接加热后放置:移动到目标无 detours。
结果:成功 (8 步)------使用的技能:hea_001 (目标优先), hea_004 (序列控制)。
案例 3: ALFWorld 检查任务 (铅笔 ⊕ 台灯→成功)
任务:看台灯下的铅笔。
核心技能 loo_001 寻找灯表面 (桌子/边桌); loo_002 打开灯; exa_001 早期配对对象 (目标 & 工具 co-location)。
避免的错误 err_003 忽略 reachable targets; loo_005 防止动作循环 (仅 toggle 一次)。
智能体轨迹:高效 Co-location 处理
步骤 1 观察:房间中间。可见:desk 1/2, drawer 1-3, sidetable 1, 等。
推理:loo_001 台灯通常坐在桌子上。优先 desk 1 以一次找到铅笔和灯。
动作:go to desk 1
步骤 2 观察:在 desk 1 上:alarmclock 1, desklamp 1, pencil 1。
推理:exa_001 成功 co-location! 两个对象都存在。exa_002 在与工具交互前先拾取目标。
动作:take pencil 1 from desk 1
步骤 3 观察:持有 pencil 1。
推理:loo_002 Toggle 灯状态以满足"under light"条件。exa_004 单次 toggle 规则确保无重复动作。
动作:use desklamp 1 结果:成功 (最优 3 步)------展示 superior spatial reasoning 和 zero-waste navigation。关键技能:exa_001 (对象配对), loo_001 (空间先验)。