目录
-
- 前言
- [1. 项目介绍](#1. 项目介绍)
- [2. 开发环境搭建](#2. 开发环境搭建)
- [3. s01: The Agent Loop](#3. s01: The Agent Loop)
-
- [3.1 问题](#3.1 问题)
- [3.2 解决方案](#3.2 解决方案)
- [3.3 Agent Loop 流程图](#3.3 Agent Loop 流程图)
- [3.4 工作原理(代码分析)](#3.4 工作原理(代码分析))
- [3.5 变更内容](#3.5 变更内容)
- [3.6 Q & A](#3.6 Q & A)
- [3.7 小结](#3.7 小结)
- [4. s02: Tool Use](#4. s02: Tool Use)
-
- [4.1 问题](#4.1 问题)
- [4.2 解决方案](#4.2 解决方案)
- [4.3 Tool Dispatch Map 分析](#4.3 Tool Dispatch Map 分析)
- [4.4 工作原理(代码分析)](#4.4 工作原理(代码分析))
- [4.5 相对 s01 的变更](#4.5 相对 s01 的变更)
- [4.6 小结](#4.6 小结)
- 结语
- 参考
前言
最近发现一个非常不错的开源项目 learn-claude-code,跟着他的教程文档一起来学习如何从 0 到 1 搭建一个简易版 Claude Code,深入理解 Agent 构建原理,记录下个人学习笔记,和大家一起分享交流😄
Note:本篇文章主要学习记录教程第一部分 Tools & Execution 即 s01: The Agent Loop 和 s02: Tool Use 两个章节的内容。
github :https://github.com/shareAI-lab/learn-claude-code
reference :https://platform.claude.com/docs
reference :https://chatgpt.com/
1. 项目介绍
Learn Claude Code 是 GitHub 上一个从 0 到 1 构建 AI 编程 Agent 的开源教学项目,其核心目标不是教你 "使用" 智能体,而是教你 "构建" 智能体,地址是:https://github.com/shareAI-lab/learn-claude-code。
整个项目结构如下:
shell
learn-claude-code/
|
|-- agents/ # Python 参考实现 (s01-s12 + s_full 总纲)
|-- docs/{en,zh,ja}/ # 心智模型优先的文档 (3 种语言)
|-- web/ # 交互式学习平台 (Next.js)
|-- skills/ # s05 的 Skill 文件
+-- .github/workflows/ci.yml # CI: 类型检查 + 构建项目通过 12 个递进式章节,从最基础的 Agent Loop(仅几十行代码)出发,逐步引入工具调用、任务规划、上下文管理、多 Agent 协作等机制,最终构建出一个完整的 Claude Code-like Agent 系统。
| 课程 | 主题 | 格言 |
|---|---|---|
| s01 | Agent 循环 | One loop & Bash is all you need |
| s02 | Tool Use | 加一个工具, 只加一个 handler |
| s03 | TodoWrite | 没有计划的 agent 走哪算哪 |
| s04 | 子智能体 | 大任务拆小, 每个小任务干净的上下文 |
| s05 | Skills | 用到什么知识, 临时加载什么知识 |
| s06 | Context Compact | 上下文总会满, 要有办法腾地方 |
| s07 | 任务系统 | 大目标要拆成小任务, 排好序, 记在磁盘上 |
| s08 | 后台任务 | 慢操作丢后台, agent 继续想下一步 |
| s09 | 智能体团队 | 任务太大一个人干不完, 要能分给队友 |
| s10 | 团队协议 | 队友之间要有统一的沟通规矩 |
| s11 | 自治智能体 | 队友自己看看板, 有活就认领 |
| s12 | Worktree + 任务隔离 | 各干各的目录, 互不干扰 |
与传统教程不同,该项目提出了一个非常关键的工程思想:Agent 的核心不在于模型本身,而在于其运行环境(Harness)。模型负责决策与推理,而 Harness 负责提供工具、上下文、知识以及执行能力。
从工程角度看,Learn Claude Code 实际上是在教你如何设计一个 "Agent 操作系统",其设计模式不仅适用于 Claude Code,也适用于 Codex、OpenCode 等各类 AI Agent 系统。
对于希望深入理解 AI Agent 内部原理的开发者来说,这是一个非常优秀的入门到进阶实践路径。
2. 开发环境搭建
Learn Claude Code 项目的开发环境搭建非常简单,没有什么依赖,我们跟着 REAMDE 文档来就行。
首先,我们需要 git clone 项目并安装必要的包:
shell
git clone https://github.com/shareAI-lab/learn-claude-code
cd learn-claude-code
pip install -r requirements.txt接着,我们需要编辑下环境变量:
shell
cp .env.example .env # 编辑 .env 填入你的 ANTHROPIC_API_KEY如果你有 Anthropic 官方的 API Key 直接填入即可,这里博主没有,因此采用的是 DeepSeek 模型做替代,此时需要把注释的 DeepSeek 相关的 URL 和 MODEL_ID 打开,完整的 .env 如下:
shell
# API Key (required)
# Get yours at: https://console.anthropic.com/
ANTHROPIC_API_KEY=sk-xxx
# Model ID (required)
# MODEL_ID=claude-sonnet-4-6
# Base URL (optional, for Anthropic-compatible providers)
# ANTHROPIC_BASE_URL=https://api.anthropic.com
# =============================================================================
# Anthropic-compatible providers
#
# Provider MODEL_ID SWE-bench TB2 Base URL
# --------------- -------------------- --------- ------ -------------------
# Anthropic claude-sonnet-4-6 79.6% 59.1% (default)
# MiniMax MiniMax-M2.5 80.2% - see below
# GLM (Zhipu) glm-5 77.8% - see below
# Kimi (Moonshot) kimi-k2.5 76.8% - see below
# DeepSeek deepseek-chat 73.0% - see below
# (V3.2)
#
# SWE-bench = SWE-bench Verified (Feb 2026)
# TB2 = Terminal-Bench 2.0 (Feb 2026)
# =============================================================================
# ---- International ----
# MiniMax https://www.minimax.io
# ANTHROPIC_BASE_URL=https://api.minimax.io/anthropic
# MODEL_ID=MiniMax-M2.5
# GLM (Zhipu) https://z.ai
# ANTHROPIC_BASE_URL=https://api.z.ai/api/anthropic
# MODEL_ID=glm-5
# Kimi (Moonshot) https://platform.moonshot.ai
# ANTHROPIC_BASE_URL=https://api.moonshot.ai/anthropic
# MODEL_ID=kimi-k2.5
# DeepSeek https://platform.deepseek.com
ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
MODEL_ID=deepseek-chat
# ---- China mainland ----
# MiniMax https://platform.minimax.io
# ANTHROPIC_BASE_URL=https://api.minimaxi.com/anthropic
# MODEL_ID=MiniMax-M2.5
# GLM (Zhipu) https://open.bigmodel.cn
# ANTHROPIC_BASE_URL=https://open.bigmodel.cn/api/anthropic
# MODEL_ID=glm-5
# Kimi (Moonshot) https://platform.moonshot.cn
# ANTHROPIC_BASE_URL=https://api.moonshot.cn/anthropic
# MODEL_ID=kimi-k2.5
# DeepSeek (no regional split, same endpoint globally)
# ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
# MODEL_ID=deepseek-chatNote :ANTHROPIC_API_KEY 需要填入你的 DeepSeek API Key,如果是其他模型(如 MiniMax、GLM)填入对应的 API Key 然后打开相应的 URL 和 MODEL_ID 注释即可,这里博主不再赘述了。
设置好环境变量之后,我们就可以运行相应脚本测试下,指令如下:
shell
python agents/s01_agent_loop.py
可以看到我们请求了几个问题都有相应的回答,这说明整个流程链路是没有问题的,接下来我们就可以跟着文档教程愉快的学习了🤗。
当然该项目还提供了一个 Web 平台用于交互式可视化、分步动画、源码查看器以及查看每个课程的文档。
运行指令如下:
sh
cd web && npm install && npm run dev # http://localhost:3000执行后进入 http://localhost:3000 即可打开这个 Web 平台:
点击 Start Learning → 之后我们就可以查看对应的章节目录:
例如我们想看 s01 章节,我们可以点击 Learn More → 来学习本章节具体的内容:
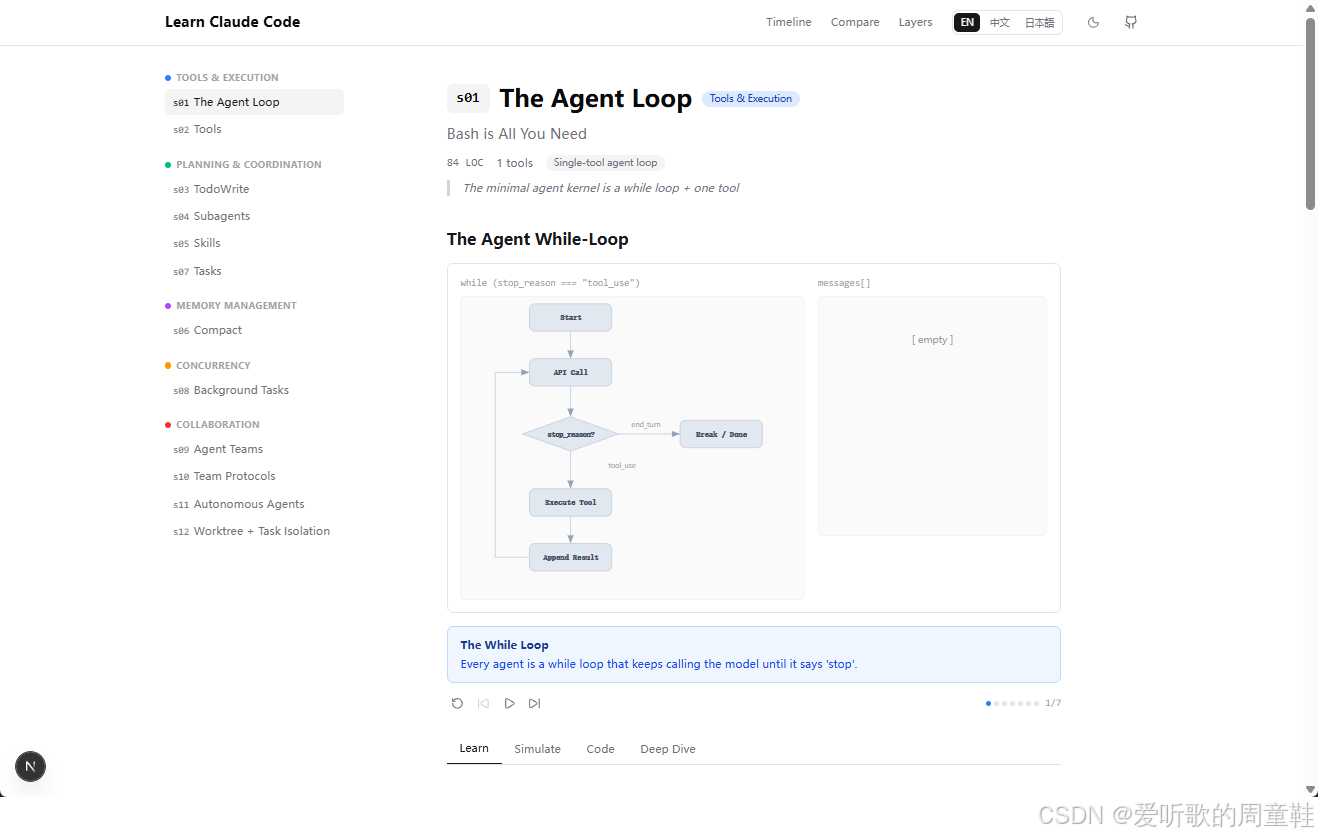
OK,下面我们就跟着这些章节教程一起来看看如何从 0 到 1 构建一个简易的 Claude Code😄。
3. s01: The Agent Loop
第一章节最核心的一句话就是:
One loop & Bash is all you need
这句话几乎概括了本节的全部内容,所谓 Agent,在这一节里并没有什么复杂的规划系统,也没有什么多工具调度,更没有记忆压缩、子智能体协作这些后面章节才会逐步加入的能力。它只有两样东西:一个循环 ,再加上 一个可以接触世界的工具:
The minimal agent kernel is a while loop + one tool
教程里把这个工具选成了 bash,也就是 shell 命令执行器;而循环,就是我们后面要看到的 while True + stop_reason 这一套控制逻辑。
如果只从字面去理解,可能会觉得这句话有点 "故弄玄虚",一个循环怎么就能变成智能体了呢?🤔但如果我们把视角放在 LLM 的能力边界上,就会发现这句话其实一点也不夸张。因为普通的语言模型虽然能够推理、能够写代码、能够分析问题,但它有一个天然缺陷:它碰不到真实世界。
也就是说,语言模型虽然能推理代码,但不能读文件、不能跑测试、不能看报错,如果没有循环,每次工具调用都需要用户手动去做,用户自己其实就是那个循环。
我们平时在网页上和 ChatGPT 聊天的时候,模型给我们的感觉是 "一问一答"。你提一个问题,它回答一次,这一轮就结束了。如果它回答得不对,你就得自己继续追问。如果它需要某个外部信息,比如某个文件内容、某个终端输出、某个测试结果,它自己拿不到,这时候就只能由人来补这个环节:你去终端里执行命令,把结果复制回来,再贴给模型。换句话说,这个过程中真正承担 "执行 → 反馈 → 再执行" 闭环的人,不是模型,而是用户自己 。
所以从工程角度看,所谓 Agent,最本质的变化并不是 "模型突然更聪明了",而是 程序在模型外面加了一层 Harness 。前面我们提到过,Learn Claude Code 一个非常重要的观点就是:Agent 的核心不在于模型本身,而在于运行环境(Harness)。
模型负责做决策和推理,而 Harness 负责把工具、上下文和执行能力组织起来,让模型不再只是 "说",而是可以 "做"。而这一节里的 Agent Loop,其实就是这个 Harness 的第一块基石。
OK,那接下来我们就按照教程文档的思路,先看这一节想解决的问题,再看它提出的最小解法,然后再结合教程文档提供的流程图和具体代码,把整个过程彻底串起来。
3.1 问题
我们先看一个很朴素的问题:为什么要有 loop?
这个问题如果从表明看,好像答案很明显 --- 因为模型要多轮调用工具。但如果我们再往下追问一步,就会发现它实际上触碰到的是 Agent 和传统 ChatBot 最根本的差别。
普通 ChatBot 的执行模式大概是:用户输入 → 模型生成回复 → 结束。
这是一种单轮闭环,它只在 "语言" 这个空间里打转,模型拿到输入,生成输出,这轮任务就完成了。它的输入输出都是文本,中间不会真的去执行什么外部动作。
而 Agent 的执行模式不一样,Agent 并不是把 "回答" 当成最终目标,而是把 "完成任务" 当成最终目标。注意这两者是有区别的,举个最简单的例子,用户说一句:
shell
Create a file called hello.py that prints "Hello, World!"如果这是普通 ChatBot,它可能会回复你一段 Python 代码,并告诉你 "你可以新建一个 hello.py 文件,把下面内容写进去"。
但如果这是 Agent,它应该做的不是 "告诉你怎么做",而是直接去执行:
shell
echo 'print("Hello, World!")' > hello.py这就意味着,Agent 在内部必须有一种机制,让模型先决定 "我要调用工具",然后程序真的去调用工具,再把结果交还给模型,看它是否还要继续下一步。
如果这个机制不存在,那么模型即使知道应该读文件、应该运行测试、应该修改代码,它也没有办法真正落地,于是整条链路就会断在 "想到了,但做不到" 这一步。
所以教程文档提到:没有循环,每次工具调用你都得手动把结果粘回去,你自己就是那个循环。所谓 Agent Loop,本质上不是为了 "炫技",而是为了把原本需要用户亲自参与的那部分执行闭环,交给程序自己完成。
3.2 解决方案
教程给出的解法也非常朴素,用一句话概括:只要模型还在调用工具,就继续循环;直到模型不再调用工具为止,这个闭环过程如下所示:
shell
+--------+ +-------+ +---------+
| User | ---> | LLM | ---> | Tool |
| prompt | | | | execute |
+--------+ +---+---+ +----+----+
^ |
| tool_result |
+----------------+
(loop until stop_reason != "tool_use")这个设计其实非常优雅,因为它没有引入复杂的状态机,没有额外维护一套冗长的执行图,而是直接借助模型 API 自己返回的一个字段,决定要不要继续往下走。
换句话说,整个最小 Agent 的运行规则其实可以浓缩为一句伪代码:
python
while response.stop_reason == "tool_use":
执行工具
把工具结果喂回模型你会发现,这个模式和很多复杂系统背后的控制逻辑非常像,它并不要求程序预先知道模型总共会调用几次工具,也不要求程序提前规划好接下来一定要做哪几步。
程序只需要完成一件事:每一轮把模型产生的工具请求执行掉,然后把结果原样反馈返回,至于下一轮模型还想不想继续、要不要换工具、要不要直接结束,都由模型根据新的上下文自己判断。
也正因为这样,我们可以用不到 30 行的代码就能构建一个智能体,后面 11 个章节都在这个循环上叠加机制,而循环本身始终不变。后面的工具系统、任务规划、子智能体、技能加载、上下文压缩,所有这些东西的本质,其实都只是往这个最小闭环里不断增加 "附加能力"。但最底层的运行骨架,并不会改变。
3.3 Agent Loop 流程图
Web 平台提供了一个 Agent Loop 可视化的流程图,它把 While-Loop 动态地拆成了一个个可视化步骤,下面我们不着急看代码,先按照流程图把整个过程走一遍。
先看第一张图:
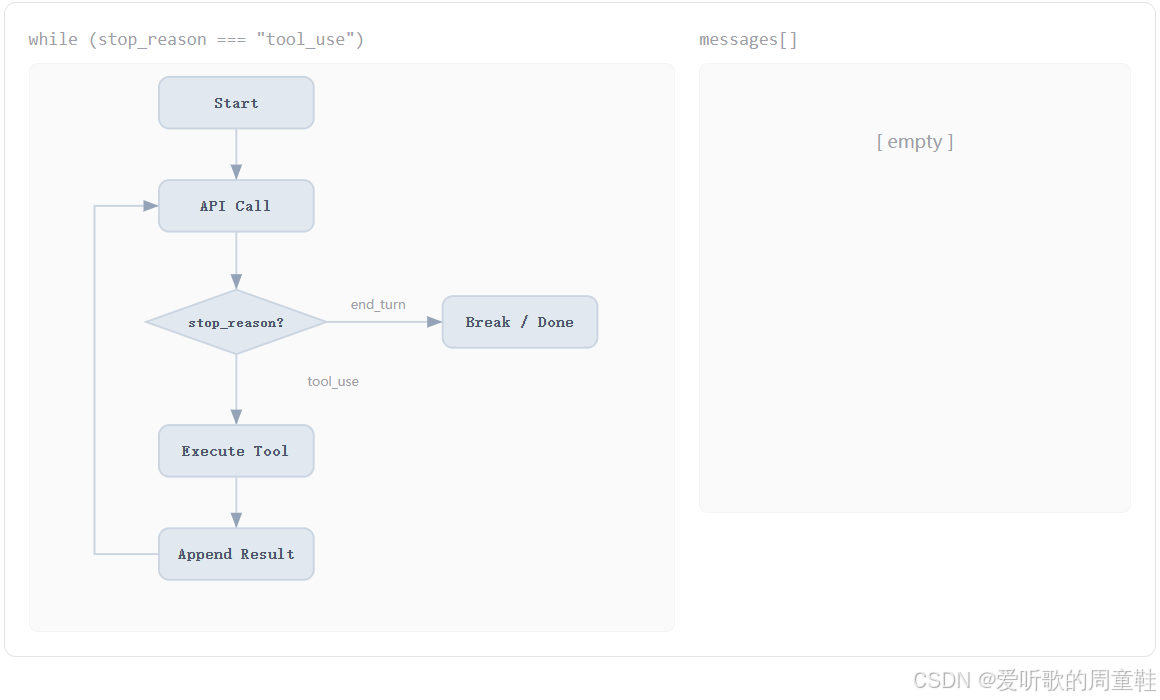
这个时候整个系统刚刚启动,左边是一条流程主线,右边的 messages[] 还是空的,说明此时对话上下文里什么都没有。
这其实对应的是一个非常原始的状态:Agent 还没接收到用户请求,自然也还没法调用模型,这个阶段没有什么复杂逻辑,它更像是整个循环的准备态。
接下来看第二张图:
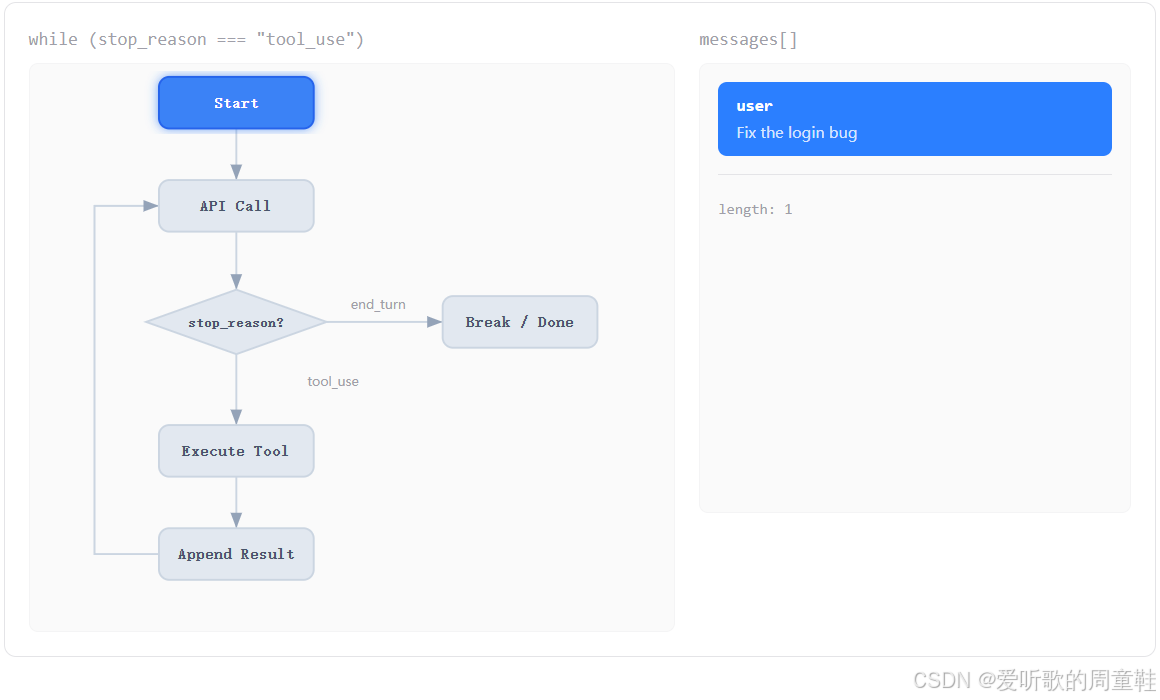
第二张图里,右侧的 messages[] 出现了一条蓝色信息:
shell
user
Fix the login bug同时左边流程图的 Start 被高亮了,说明整个 Agent 开始工作了,这一步非常关键,因为它说明 Agent 的一切后续动作,都是从 把用户请求加入 messages 开始的。
这里其实也已经暗示了一个很重要的工程设计:在这个最小实现里,并没有单独定义什么 "任务对象" 或者 "指令结构体",而是直接把用户输入放进一个统一的消息列表里。后续模型的回答、工具调用、工具执行结果,都会不断追加到这个列表里。
也就是说,这个 messages 列表在整个系统中承担了一个非常核心的角色:它既是上下文,也是状态。
接着第三张图:
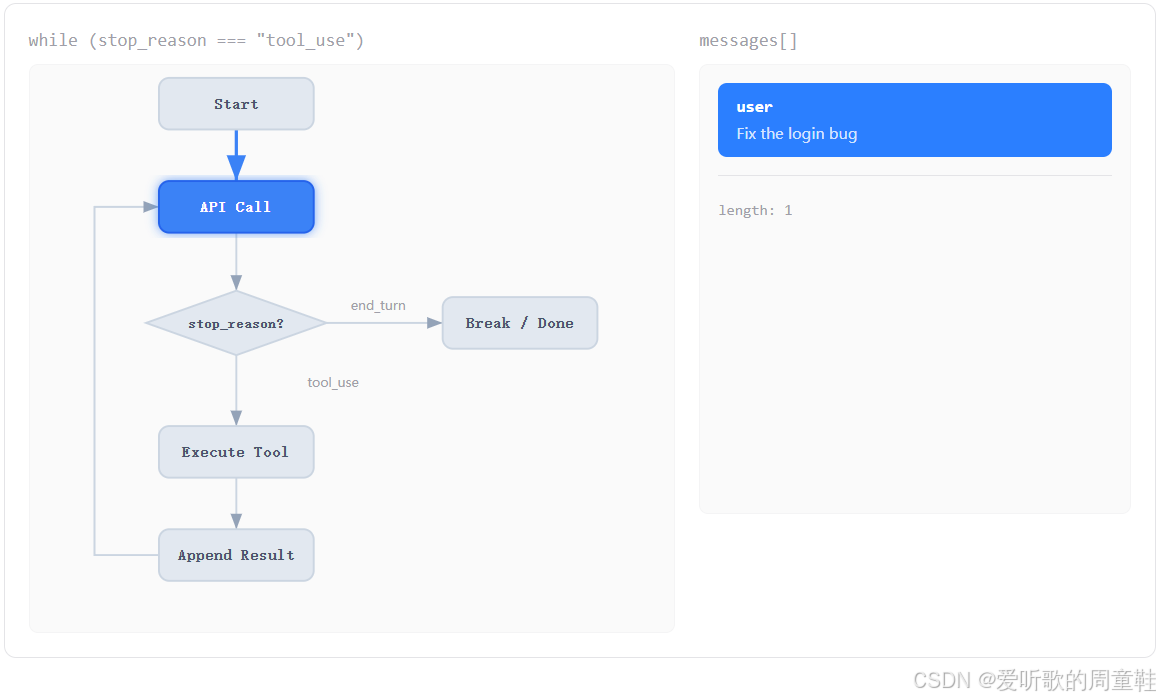
第三张图里,左边的 API Call 被高亮了,这个阶段对应的就是:程序把当前 messages 和 tools 一起发给模型,此时模型会做一件事:根据已有对话上下文判断下一步该怎么走。如果它觉得已经能直接回答了,那这轮就结束;如果它觉得还需要读取文件、执行命令、查看环境,那它就会生成一个 tool_use 类型的输出。
接着第四张图:
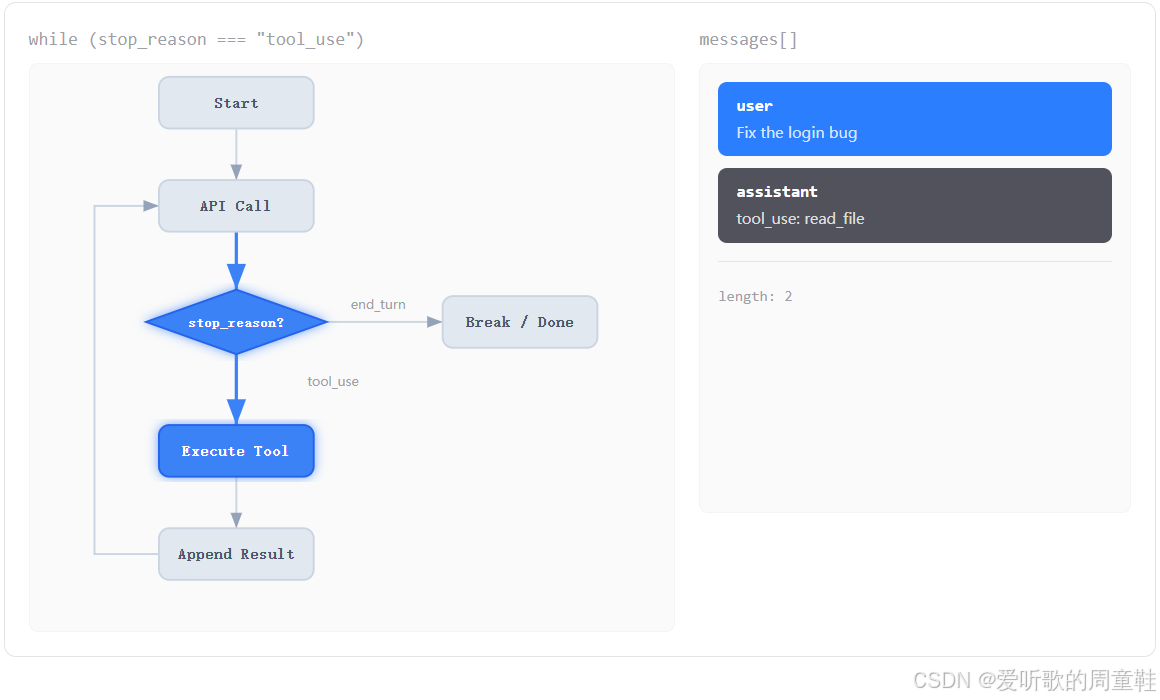
到了第四张图,右边就已经出现了第二条消息:
shell
assistant
tool_use: read_file此时左边 stop_reason? 这个菱形节点也被点亮了,并且下方的 Execute Tool 进入高亮。这说明当前这一轮 API 调用之后,模型并没有选择结束,而是明确要求调用一个叫做 read_file 的工具。
接着第五张图:
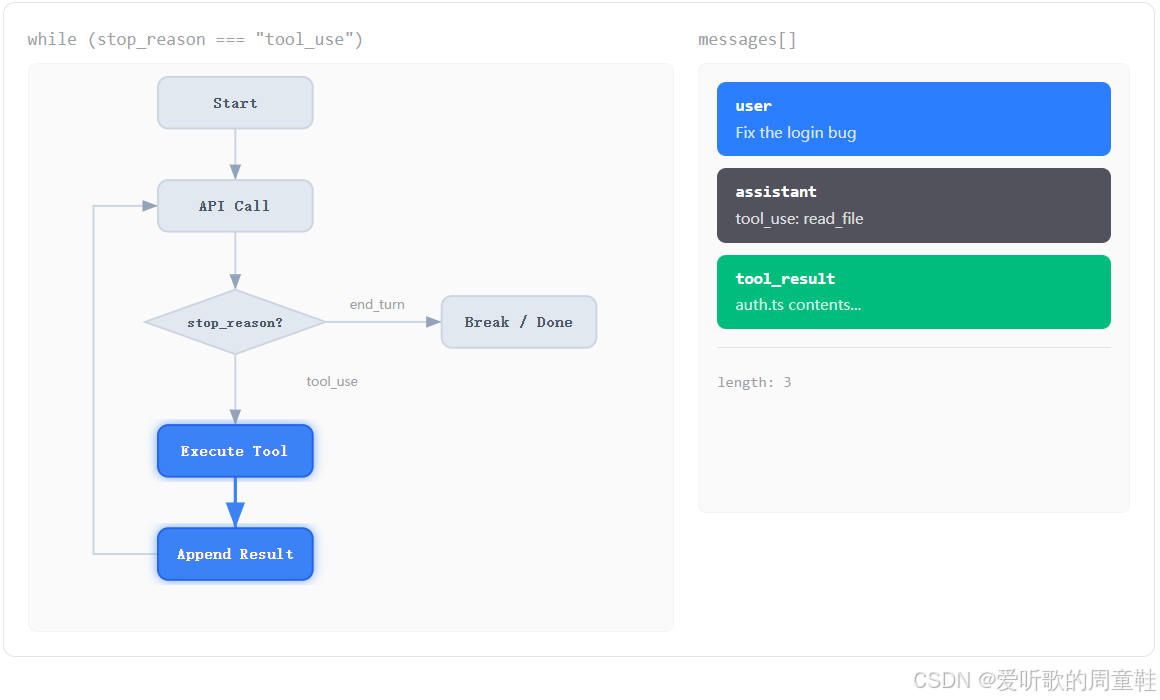
第五张图里,右边又多了一条绿色消息:
shell
tool_result
auth.ts contents...这一步就是整个 Agent Loop 的灵魂。因为从模型的角度来说,它虽然 "发起了工具调用",但它并不会自动知道工具的执行结果是什么。必须由外部程序把结果显式地组织成一个 tool_result 消息,重新塞回上下文,它才能在下一轮继续利用这些信息推理。
也正因为这样,Agent 才真正具备了 "接触世界" 的能力。否则模型只是说了一句 "请帮我读一下 auth.ts",但读完之后发生了什么,它自己是感知不到的。
接着第六张图:
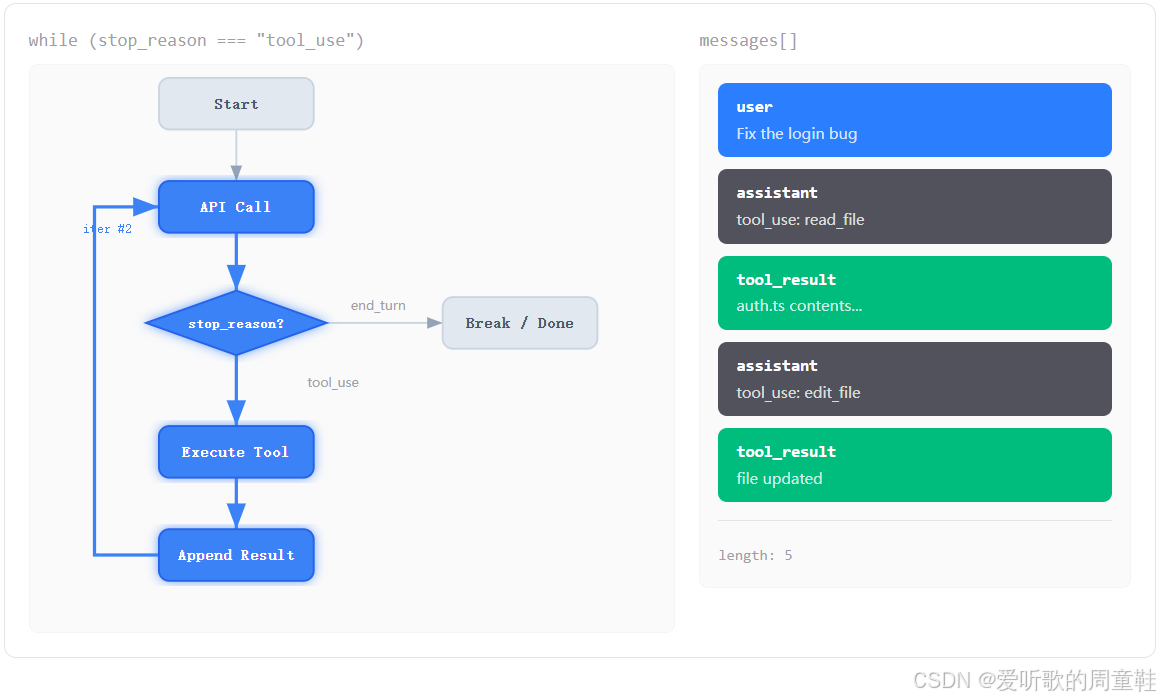
第六张图里,循环已经继续了一轮。你会看到右侧消息列表进一步增长,出现了新的 assistant 工具调用和新的 tool_result。这说明系统又回到了最开始的 API Call,只不过这一次的输入上下文已经不再是 "只有用户的一句 Fix the login bug",而是变成了:
- 用户原始请求
- 模型上一轮发出的工具调用
- 程序执行工具得到的结果
- 以及模型基于结果又做出的新决策
这就是为什么 messages 会随着循环不断变长。因为 Agent 的每一步都不是孤立的,而是建立在前面每一轮积累起来的上下文基础上。
最后第七张图:
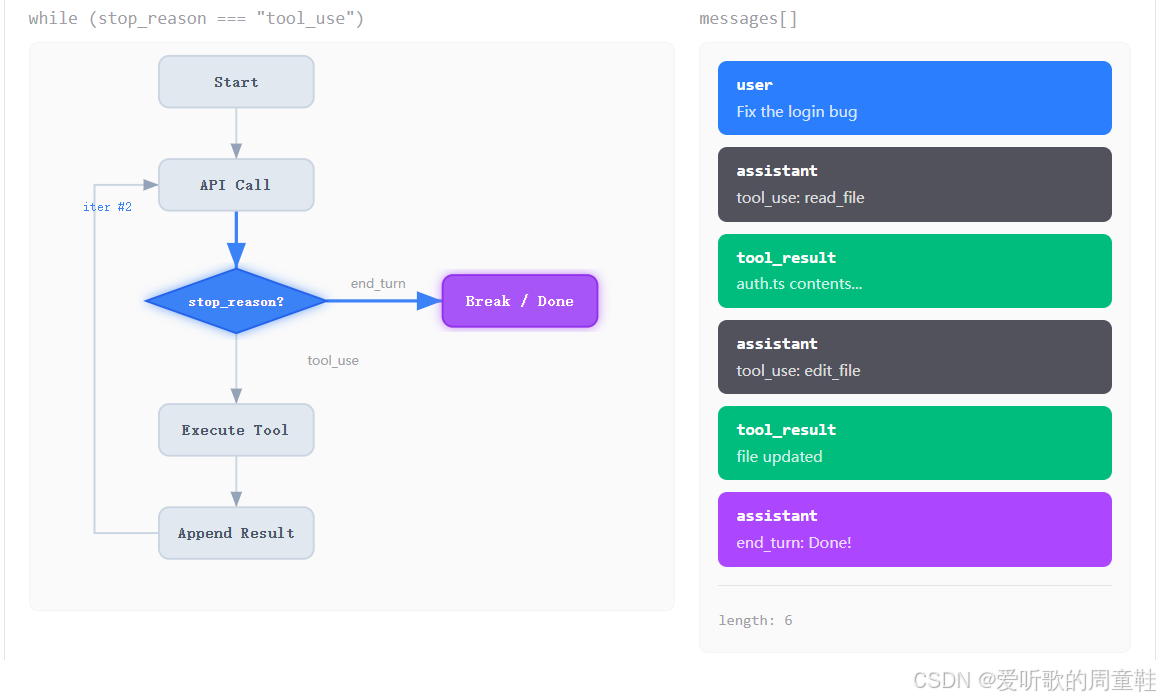
在第七张图里,右侧出现了一条紫色的 assistant 消息:
shell
assistant
end_turn: Done!与此同时,左边 Break / Done 节点被高亮。这就意味着模型这一轮不再请求工具调用,而是直接给出最终回答。也就是说,此时 stop_reason != "tool_use",循环可以安全退出,整个 Agent Loop 至此完成。
如果把这 7 张图串起来,其实就是下面这样一条非常清晰的主线:
shell
用户消息进入上下文
↓
调用模型
↓
如果模型请求工具 → 程序执行工具
↓
把工具结果追加回上下文
↓
再次调用模型
↓
直到模型不再请求工具,循环结束看到这里其实就能理解,为什么教程会把这一节叫做 The Agent Loop。因为 "Loop" 才是真正的关键。工具当然重要,但如果没有这层循环,工具也只是一个孤零零的函数而已;模型当然重要,但如果它发出的工具请求得不到自动执行,也仍然只是一个会说不会做的系统。正是这条循环,把 "模型的决策" 与 "外部世界的执行" 真正接到了一起。
3.4 工作原理(代码分析)
OK,看完流程图之后,接下来我们正式进入代码。参考实现就在 agents/s01_agent_loop.py 里,整个文件并不长,但结构很清晰,基本可以分成四部分:
- 第一部分是环境初始化和模型客户端构造;
- 第二部分是系统提示词和工具定义;
- 第三部分是工具执行函数
run_bash; - 第四部分才是这一节最核心的
agent_loop以及最下面的命令行交互主循环。
在代码文件的最顶部解释了整个脚本的意图:
python
#!/usr/bin/env python3
# Harness: the loop -- the model's first connection to the real world.
"""
s01_agent_loop.py - The Agent Loop
The entire secret of an AI coding agent in one pattern:
while stop_reason == "tool_use":
response = LLM(messages, tools)
execute tools
append results
+----------+ +-------+ +---------+
| User | ---> | LLM | ---> | Tool |
| prompt | | | | execute |
+----------+ +---+---+ +----+----+
^ |
| tool_result |
+---------------+
(loop continues)
This is the core loop: feed tool results back to the model
until the model decides to stop. Production agents layer
policy, hooks, and lifecycle controls on top.
"""Harness 层的第一个连接真实世界的能力,就是这个 loop。换句话说,这份代码在明确告诉你:如果你想从 0 开始做一个最小的 AI coding agent,那么最核心的秘密其实就是这么一个模式 --- 调用模型、执行工具、追加结果、继续循环,直到模型自己停下来。
然后往下看初始化部分:
shell
load_dotenv(override=True)
if os.getenv("ANTHROPIC_BASE_URL"):
os.environ.pop("ANTHROPIC_AUTH_TOKEN", None)
client = Anthropic(base_url=os.getenv("ANTHROPIC_BASE_URL"))
MODEL = os.environ["MODEL_ID"]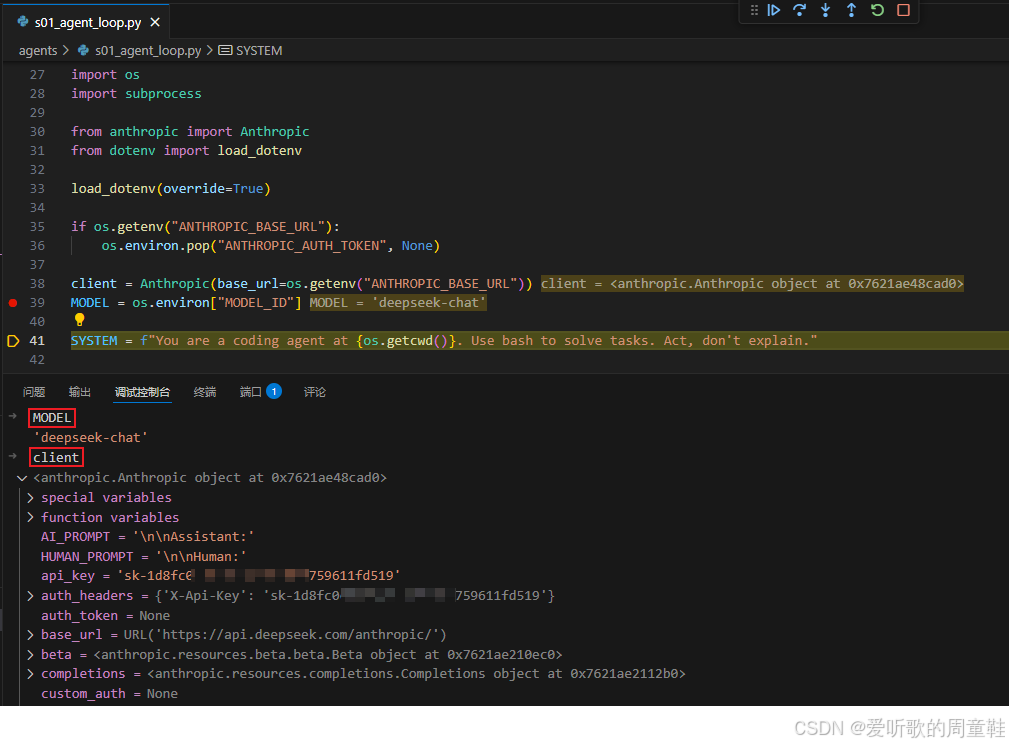
这段代码我们前面在配置环境时其实已经接触过了。它做的事情并不复杂:先从 .env 加载环境变量,然后根据当前是否设置了 ANTHROPIC_BASE_URL 来决定走哪种 API 兼容方式,最后创建一个 Anthropic 风格的客户端,并从环境变量里读出模型 ID。博主是用 DeepSeek 兼容 Anthropic 协议来运行的,所以调试过程中我们也能发现模型 ID 是 deepseek-chat。
接着看系统提示词和工具定义部分的代码:
python
SYSTEM = f"You are a coding agent at {os.getcwd()}. Use bash to solve tasks. Act, don't explain."
TOOLS = [{
"name": "bash",
"description": "Run a shell command.",
"input_schema": {
"type": "object",
"properties": {"command": {"type": "string"}},
"required": ["command"],
},
}]这里我们先看 SYSTEM。这一句系统提示词其实短得有点惊人,但写得非常有力。它没有给模型一大堆冗长的角色说明,也没有告诉模型什么复杂规则,而是直接规定了三件事:
第一,你现在是一个 coding agent,而不是聊天助手;第二,你工作的当前目录就是 os.getcwd() 对应的这个项目路径;第三,你解决任务的方式是 Use bash to solve tasks ,并且 Act, don't explain。
这几句话一加上去,模型的行为模式其实就和普通聊天完全不一样了,因为它不再被鼓励去 "解释怎么做",而是被鼓励去 "真的做"。这也是为什么后面我们在命令行里给它输入一些任务之后,模型很容易直接生成命令,而不是先写长篇解释。这里虽然只有一句 system prompt,但它已经在很大程度上塑造了 Agent 的整体风格。
接着看 TOOLS。这部分定义的是 Agent 当前拥有的工具集合,在 s01 里,这个集合里只有一个工具,就是 bash。在 shell 世界里,bash 本身就几乎是一个万能工具入口 ,你要读文件,可以 cat;要查看目录,可以 ls;要写文件,可以 echo;要跑测试,可以 pytest 或 npm test。所以对 "最小 Agent" 来说,一个 bash 其实就够了。
更关键的是,这个工具定义里不仅写了名字和描述,还写了一个 input_schema。这意味着模型并不是随便说一句 "请帮我运行命令",而是要按照一个结构化的 JSON 输入格式,明确给出它要传给工具的参数。也就是说,从这一层开始,工具调用已经不是纯自然语言了,而是 受 schema 约束的结构化调用。
在有了工具定义之后,下一个问题自然就是:模型如果真的请求了 bash,那谁去执行?答案就在 run_bash 这个函数里:
python
def run_bash(command: str) -> str:
dangerous = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"]
if any(d in command for d in dangerous):
return "Error: Dangerous command blocked"
try:
r = subprocess.run(command, shell=True, cwd=os.getcwd(),
capture_output=True, text=True, timeout=120)
out = (r.stdout + r.stderr).strip()
return out[:50000] if out else "(no output)"
except subprocess.TimeoutExpired:
return "Error: Timeout (120s)"这个函数在整个脚本里的定位非常清晰:它不是让模型 "以为自己执行了 bash",而是真的替模型去执行 bash。这里要非常明确地区分一个概念:模型本身不会执行工具,模型能做的只是 "生成一条工具调用请求"。真正和操作系统交互、真正去运行命令的,是我们写在外面的这个 Python 函数。
先看最前面的 dangerous 列表。这其实是一个极简版的安全防护。因为一旦你把 shell 权限交给模型,哪怕只是一个 demo,也至少要挡住最明显、最危险的命令,比如 rm -rf /、sudo、关机重启之类。
这里的做法非常朴素:直接按字符串匹配做黑名单拦截。它当然不是严密的安全沙箱,但对我们这个 demo 来说已经足够表达出一个很重要的工程意识 --- 给模型工具能力的同时,必须考虑边界。
然后往下看真正执行命令的部分:
python
subprocess.run(command, shell=True, cwd=os.getcwd(),
capture_output=True, text=True, timeout=120)这里面几个参数都很有意义:
shell=True说明允许把字符串当作 shell 命令执行;cwd=os.getcwd()说明命令执行的当前目录就是脚本所在工作目录,也就是 Agent 当前 "操作项目"的根位置;capture_output=True和text=True则是为了方便把 stdout 和 stderr 一起拿回来,变成文本返回给上层;timeout=120则是一个执行时间上限,避免某条命令卡死整个 Agent。
这一步完成之后,函数会把 stdout 和 stderr 拼起来,去掉首尾空白,并且最多只保留前 50000 个字符。这最后这个截断也很关键,因为在 Agent 场景里,工具结果最终是要重新喂给模型的。如果某条命令输出太长,比如 find . 或 cat 一个大文件,原样回传就很容易把上下文顶爆。所以这里用一个非常简单的裁剪,控制单次工具结果的体积。
看到这里,我们其实就能意识到:这个 run_bash 虽然不长,但它已经包含了 Agent 工具执行层最重要的几个工程要点:安全、超时、输出捕获、长度控制。后面你再去看各种成熟 Agent 系统的工具执行器,本质上都逃不开这些问题,只不过会做得更完善而已。
我们接着看整份代码最关键的部分:
python
def agent_loop(messages: list):
while True:
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return
results = []
for block in response.content:
if block.type == "tool_use":
print(f"\033[33m$ {block.input['command']}\033[0m")
output = run_bash(block.input["command"])
print(output[:200])
results.append({"type": "tool_result", "tool_use_id": block.id,
"content": output})
messages.append({"role": "user", "content": results})这一段代码建议大家反复看,因为它几乎可以说是本项目后面所有章节的 "母体",我们一行一行来拆。
首先最外层是一个 while True。这说明程序在进入这个函数之后,并不会默认只调用模型一次,而是准备不断执行,直到遇到明确的退出条件为止。这个退出条件不是循环次数,也不是工具调用数量,而是模型返回的 stop_reason。这一点我们在前面已经说得很清楚了,循环持续运行,直到模型不再调用工具。
循环体的第一步就是调用模型:
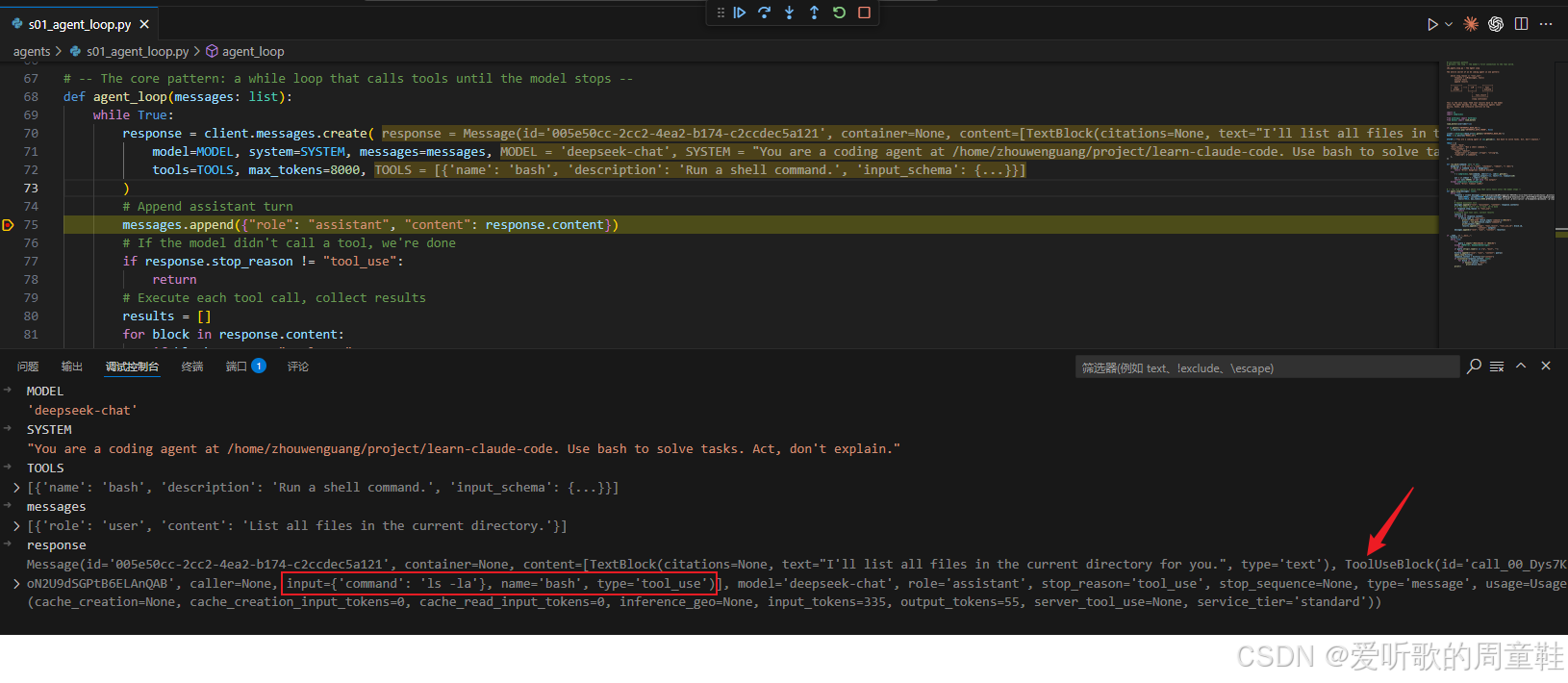
python
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,
)
这里博主给 Agent 的提示词是:
shell
List all files in the current directory.让它把当前目录下的文件都列出来。
这里我们会看到,程序每一轮并不是只把 "最新一条用户输入" 发给模型,而是把整个 messages 历史都发过去。同时,还会把 tools=TOOLS 一并带上。这就意味着,模型在这一轮看到的并不是一个孤立问题,而是一个完整上下文:前面发生过什么、执行过哪些命令、工具返回过什么结果,它全都能看到。也正因为这样,模型才有可能基于上一步的执行结果,决定下一步该怎么走。
从上图中我们可以看到模型的输出中有请求调用工具的动作,给的 shell 指令是 ls -la。
紧接着,程序会立刻把模型这一轮的原始输出追加到 messages 里:
python
messages.append({"role": "assistant", "content": response.content})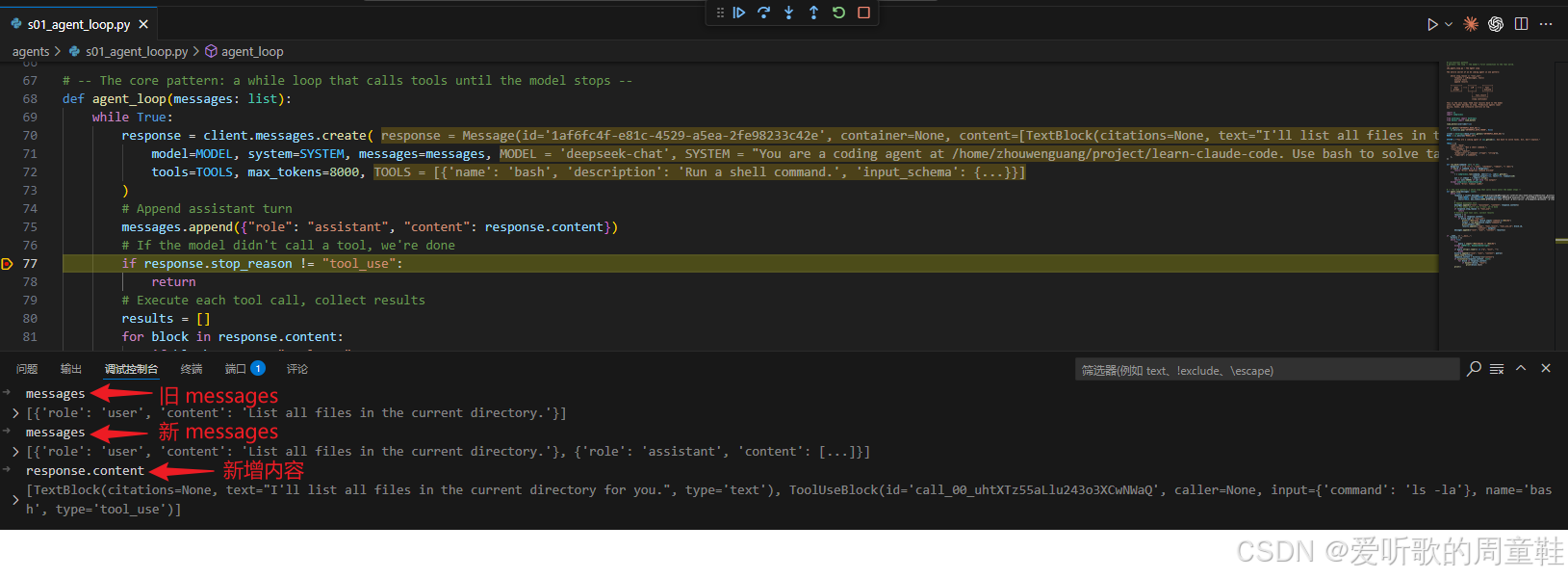
这一句很重要,因为它体现出这个最小 Agent 的状态管理方式:状态几乎全部外化到了 messages 里。程序本身没有另建一个复杂的执行树,也没有单独维护什么 "当前步骤对象",而是让每一轮 assistant 输出都沉淀在消息列表中。这样一来,后续任何一轮模型调用,都可以完整地 "回看" 自己之前说过什么、请求过什么。
然后就来到关键判断:
python
if response.stop_reason != "tool_use":
return这句可以说是整个 Agent Loop 的退出开关。如果模型这一轮的停止原因不是 tool_use,那就说明它没有继续请求工具,要么已经直接给出了最终回答,要么这一轮不需要外部动作了,那么整个循环可以结束。
这里的设计极其简洁,但也极其漂亮。因为程序不用猜测模型是不是 "回答完了",也不用靠字符串规则去判定 "像不像最终答案",而是直接利用 API 已经提供的结构化字段做控制流判断。
如果判断结果说明模型确实在请求工具,那么接下来程序就进入工具执行阶段:
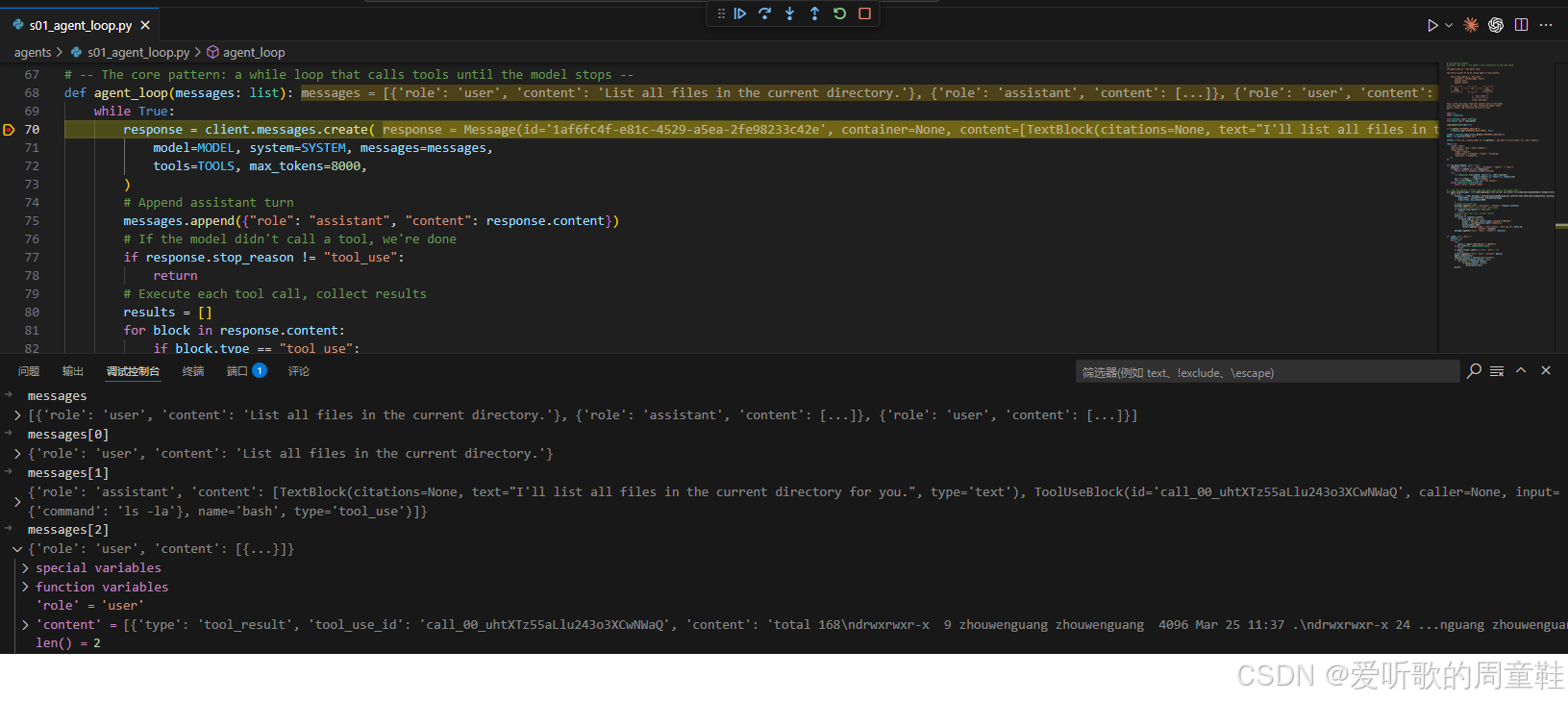
python
results = []
for block in response.content:
if block.type == "tool_use":
print(f"\033[33m$ {block.input['command']}\033[0m")
output = run_bash(block.input["command"])
print(output[:200])
results.append({"type": "tool_result", "tool_use_id": block.id,
"content": output})
这里有两个细节值得特别注意:
第一个细节是:程序并没有假设 response.content 里一定只有一个工具调用,而是显式遍历所有 block,然后找出其中类型为 tool_use 的那些块。这说明在协议层面,模型一次回复里理论上是可以包含多个内容块的,工具调用只是其中一种类型。这个设计是比较通用的,也为后面更复杂的工具系统留下了空间。
第二个细节是:每次工具执行结果都被封装成了一个带 tool_use_id 的结构。这个 tool_use_id 非常关键,因为它把 "哪一次工具调用" 和 "哪一条工具结果" 显式关联起来了。换句话说,不是简单地往上下文里扔一句 "命令输出如下",而是告诉模型:这是针对你刚才发起的那次具体工具调用的结果。这让整个工具协议在多轮、多工具场景下仍然能够保持清晰可追踪。
最后,所有工具结果会被统一追加到 messages 里,而且角色是 user:
python
messages.append({"role": "user", "content": results})这一点第一次看可能会稍微觉得奇怪:为什么工具结果不是以某种特殊角色单独追加,而是作为 user 内容加入?🤔其实这是由 Anthropic 这套消息协议的工具交互方式决定的。
对模型来说,上一轮 assistant 发起了工具调用,下一轮外部世界把工具结果返回给它,这个 "返回动作" 是通过一条新的 user 消息来完成的。也就是说,在协议层面,工具结果是用户这边把外部执行结果喂回给模型。所以虽然逻辑上它是 tool_result,但封装在消息序列里时,仍然是 user 这一侧提供的新输入。
而一旦这条 tool_result user 消息被加进去,循环就重新回到最开头,再次调用模型,此时我们就会看到传到模型中的 message 既包括最初始用户提供的 prompt,还包括模型的第一次输出以及工具调用的结果:
至此,整个闭环就闭合了,在这一次的回复中模型并没有请求调用工具,而是整理了之前的内容并给出了最终的答案:
那通过对整个过程的分析,大家会发现,这里根本没有任何复杂的 "Agent 框架感"。它就是一个 while 循环,外加一段协议适配代码。但恰恰就是这么简单的结构,把模型、工具和上下文三者接成了一个能自主跑起来的系统。
Q & A
Q :在这一节的代码里,我们会看到模型返回的 response.content 并不是一个简单的字符串,而是一个可以被遍历的列表,那这里的 block 到底是什么?它的内部结构又是什么样的?🤔
A:如果只站在最传统的聊天接口视角去理解,我们很容易默认模型返回的就是 "一整段文本"。但在支持工具调用之后,这种理解就不够用了。因为现在 assistant 的一轮输出里,已经不一定只有自然语言文本,还可能夹杂工具调用请求、thinking 块,甚至别的结构化内容。
Anthropic 在官方文档 docs 中把这一层统一抽象成了 content blocks ,也就是说,一条消息的 content 本质上不是 "一个字符串",而是 "一个由多个 block 组成的数组";不同 block 的 type 不同,它们的结构也会不同。官方文档明确提到,messages 可以包含多个 content blocks,并且这些 block 可能是 text、tool_use、thinking 等不同类型。
那 block 到底该怎么理解呢?其实我们可以把它理解为:一轮消息里的最小内容单元 。如果一整条 assistant 回复是一个容器,那么 block 就是这个容器里的一个个片段。这个片段可能是一段普通文本,也可能是一次工具调用,也可能是别的特殊内容类型。也就是说,block 不是 "消息外面附加的一层元数据",而是 消息内容本身的组织方式。
在我们当前这个工具调用场景里,最值得关注的其实是两类 block:

第一类是 text block。这种 block 表示一段普通自然语言文本,它最核心的字段通常就是 type="text",以及实际的文本内容。
第二类是 tool_use block。这种 block 表示模型不是在继续输出自然语言,而是在正式发起一次工具调用。
如果再往 tool_use block 内部看,它通常至少会包含这样几类信息:
- 第一是
type,用来说明它是不是一个tool_use。 - 第二是
id,这是这次工具调用的唯一标识。 - 第三是工具名称,也就是要调用哪个工具。
- 第四是
input,也就是传给工具的结构化参数。
总的来说,block 本质上就是 Anthropic Messages API 中一条消息内部的内容片段;在工具调用场景里,我们最常见的 block 类型就是普通文本块和工具调用块。前者承载自然语言,后者承载结构化的工具请求。
Q & A
Q:那这种形式是不是 Anthropic 协议规定的消息格式?如果是的话,它为什么要设计成这样,而不是直接让模型返回一段 JSON,或者干脆返回一整段文本让我们自己解析呢?🤔
A :是的,至少在当前 Anthropic 官方 Messages API 的工具调用设计里 docs,这就是它明确支持并推荐使用的消息组织方式。 官方文档写得很清楚,工具调用会以 tool_use content block 的形式出现在 API 请求或响应里,而工具执行结果则以 tool_result content block 的形式出现在后续请求里;并且当 Claude 正在请求工具时,stop_reason 会返回 tool_use,提醒客户端去执行工具并继续会话。
那为什么要这么设计?这里面有三层原因:
第一层原因,是为了让 一条 assistant 回复能够同时容纳多种内容类型。
如果接口只允许 assistant 返回 "一个纯文本字符串",那工具调用这件事就会非常别扭。因为模型可能既想先说一句解释性文本,又想紧接着发起一次工具调用;或者它未来还可能混入 thinking、引用、搜索结果等别的结构化内容。
第二层原因,是为了让 工具调用从 "文本约定" 升级为 "结构化协议"。
如果不用这种 block 设计,最原始的做法当然也可以是:让模型输出一段 JSON 字符串,比如:
json
{"tool":"bash","command":"ls -la"}然后客户端再从文本里把 JSON 解析出来。这样不是不行,但非常脆弱。因为一旦模型在 JSON 前后多说一句解释,或者字段名拼错一点,客户端这边就容易解析失败。而现在这种设计本质上是在协议层直接区分出 "自然语言块" 和 "工具调用块",等于是在 API 级别就承认:工具调用不是普通文本,而是一种一等公民级别的结构化内容,这会让程序的控制流稳定得多。
第三层原因,是为了让 工具调用和工具结果之间建立明确的一一对应关系。
这也是为什么 tool_use block 里会有 id,而 tool_result 里又必须带上 tool_use_id。如果没有这一层显式关联,那么一旦一轮里出现多个工具调用,或者后面会话继续延长,程序和模型就都很难搞清楚 "这条工具结果到底是对应哪一次调用的"。现在通过 tool_use_id 绑定之后,客户端和模型都能非常明确地知道:这个结果就是回给刚才那次调用的。
总的来说,Anthropic 把消息内容设计成 content blocks,并把工具调用 / 工具结果纳入同一套结构化协议,本质上是为了把"自然语言回复"和"外部动作请求"统一进同一个消息模型里。这样既能支持一轮消息中混合多种内容类型,又能让工具调用具备稳定的结构化语义,同时还能通过 id / tool_use_id 把调用与结果严格对应起来,从而非常自然地支撑 Agent Loop 这种多轮工具执行闭环。
看完 agent_loop 之后,我们来看下最下面的命令行主循环又在做什么:
python
if __name__ == "__main__":
history = []
while True:
try:
query = input("\033[36ms01 >> \033[0m")
except (EOFError, KeyboardInterrupt):
break
if query.strip().lower() in ("q", "exit", ""):
break
history.append({"role": "user", "content": query})
agent_loop(history)
response_content = history[-1]["content"]
if isinstance(response_content, list):
for block in response_content:
if hasattr(block, "text"):
print(block.text)
print()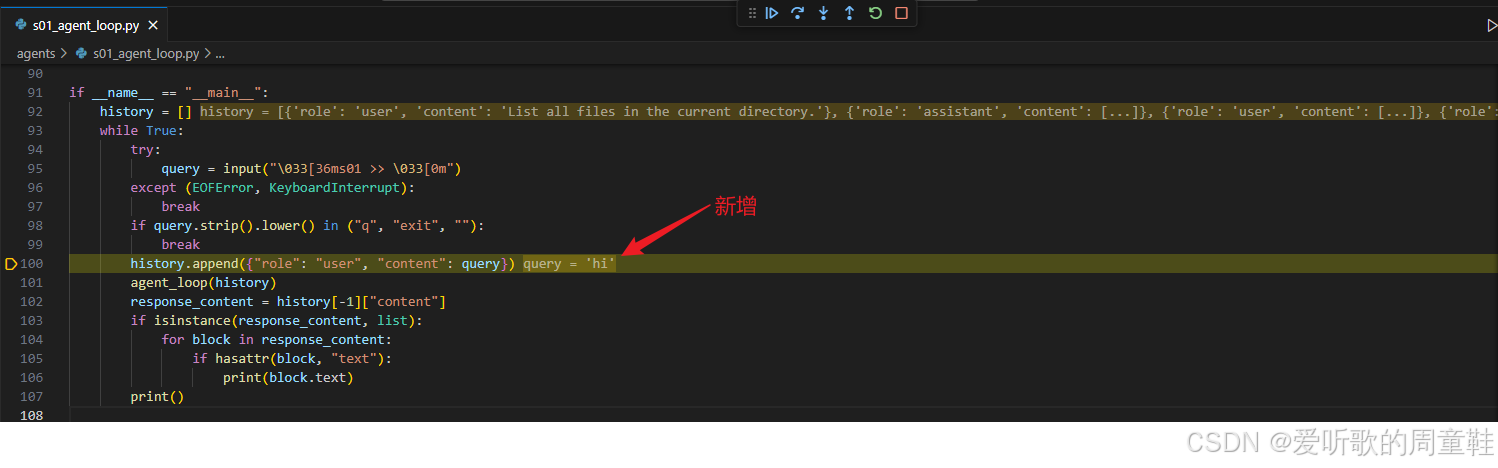
这一段其实就是给整个 Agent Loop 包了一层最简单的 CLI 交互壳子。它维护了一个 history 列表,用来保存整个会话的历史消息;每次你在命令行里输入一句新请求,它就把这条请求追加进 history,然后调用一次 agent_loop(history)。等 agent_loop 自己跑完之后,也就是模型已经不再请求工具、循环结束之后,程序再尝试把最后一轮 assistant 输出中的文本部分打印出来。
这里有个很有意思的地方:history 是在最外层主循环里长期存在的,而不是每次新输入都重新置空。也就是说,这个 demo 虽然简单,但它天然已经支持 多轮会话上下文延续。你第一轮让它创建一个文件,第二轮再问它当前目录里有什么,它其实是带着前面那一轮历史一起继续跑的。
OK,以上就是 Agent Loop 工作原理的完整分析了。
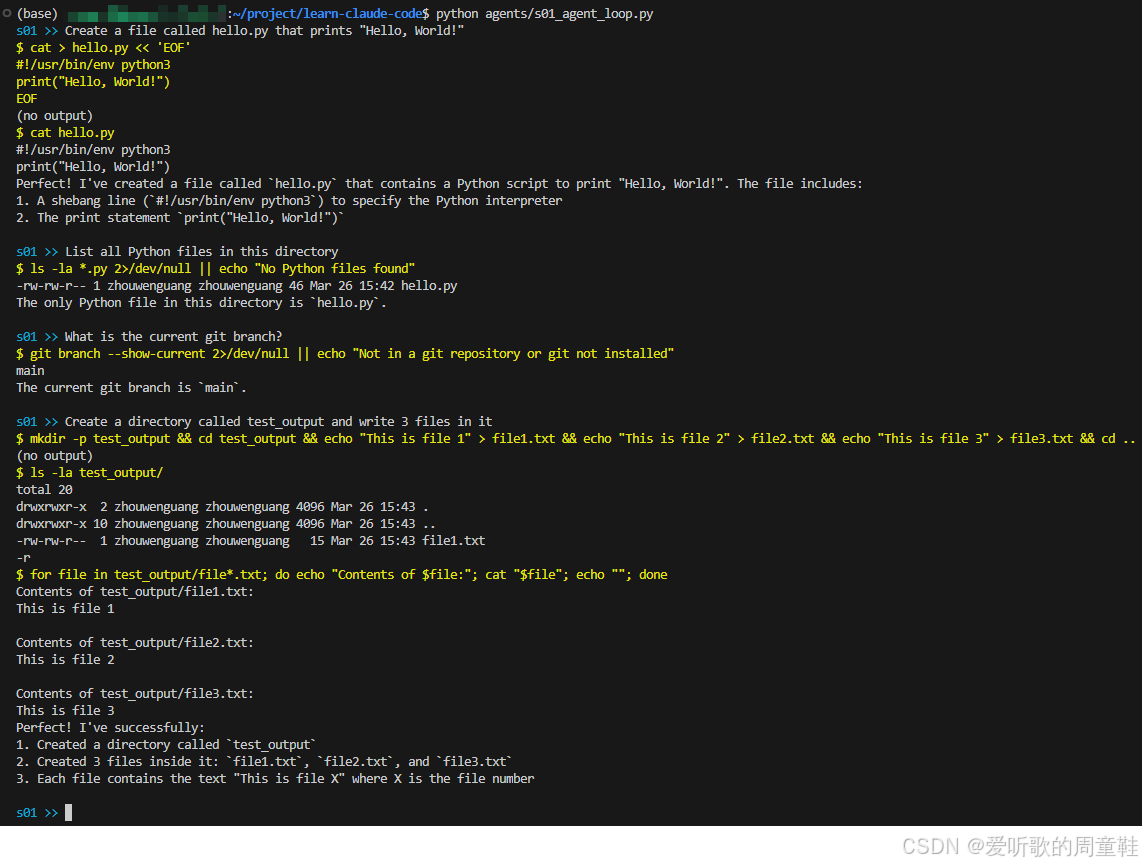
那大家感兴趣的话可以试试下面这些 prompt 感受下这个简易 Agent 的功能:
1. Create a file called hello.py that prints "Hello, World!"
2. List all Python files in this directory
3. What is the current git branch?
4. Create a directory called test_output and write 3 files in it
博主体验后的输出如下:
3.5 变更内容
| 组件 | 之前 | 之后 |
|---|---|---|
| Agent loop | (无) | while True + stop_reason |
| Tools | (无) | bash (单一工具) |
| Messages | (无) | 累积式消息列表 |
| Control flow | (无) | stop_reason != "tool_use" |
3.6 Q & A
Q :我们一起来思考一个问题:很多聊天系统内部也有对话历史,也会把用户消息和 assistant 回复不断追加到 messages 里,那这种 "消息循环" 和 Agent Loop 到底差在哪呢?🤔
A:差别主要有两层:
第一层差别在于,普通聊天循环虽然也维护消息历史,但它的每一轮边界通常是 "用户发一句,模型答一句"。每一轮结束时,程序就停下来了,等待用户下一次输入。也就是说,真正推动系统继续往下走的是 "新的用户输入"。
但 Agent Loop 不一样。在 Agent Loop 里,一次用户输入可能会触发多轮内部自循环。用户只说了一句 "修复登录 bug",程序内部却可能已经自动跑了很多轮:先读文件,再跑测试,再编辑代码,再重新跑测试,最后才把结果交还给用户。
也就是说,真正推动系统继续往下走的不再只是用户,而是模型自己发起的工具调用和程序回填的执行结果。这个差别非常本质,因为它意味着系统拥有了一种 内部自治执行能力。
第二层差别在于,普通聊天系统的上下文基本都是 "语言世界里的痕迹",而 Agent Loop 的上下文中混入了 "真实执行结果"。比如 shell 命令输出、文件内容、测试报错、环境状态,这些都不是模型凭空生成的语言,而是外部世界反馈回来的真实信息。于是整个系统的推理链路,不再只是语言到语言,而变成了:语言决策 → 外部执行 → 真实反馈 → 基于反馈继续推理。一旦这个闭环形成,Agent 的性质就和普通聊天系统明显不一样了。
3.7 小结
如果只看代码量,s01 确实很 "小"。它没有复杂抽象,没有漂亮架构图背后的大规模组件协作,甚至连工具都只有一个 bash。但也正因为它小,反而特别适合作为整个项目的起点。因为它把所有外层装饰都剥掉之后,剩下的就是最硬的骨架:模型、工具、消息、循环、退出条件。
从教程文档来看,这一节的目标也非常明确:让你先接受一个最根本的事实 --- Agent 并不神秘,它最底层就是一个会不断把工具结果重新喂回模型的循环 。从代码实现来看,s01_agent_loop.py 则把这个思想压缩成了一个几乎不能再小的参考实现,并且已经包含了最基础的工程意识:环境初始化、工具 schema、安全过滤、超时控制、输出裁剪、消息累积、循环控制。
所以,s01 虽然只是整个 Learn Claude Code 教程的第一节,但它的重要性一点都不低。因为从这一节开始,你其实就已经看见了后面所有章节的 "祖先形态"。后面无论工具怎么扩展、上下文怎么压缩、任务怎么拆、团队怎么协作,它们最终都还是要落回这个最基本的问题:模型做了什么决策,程序如何执行它的决策,执行结果又如何反馈回模型。
而这个问题的最小答案,就是这一节的 Agent Loop。
4. s02: Tool Use
如果说 s01 让我们第一次看清了 Agent 最小可运行形态,那么 s02 其实是在回答一个更进一步的问题:当这个 Agent 真正开始做事时,它应该用什么方式和外部世界交互?
在上一节里,我们已经有了一个完整的 Agent Loop。模型可以接收用户请求,可以根据上下文决定是否调用工具,程序也会在收到 tool_use 之后真正去执行命令,再把执行结果作为 tool_result 塞回消息历史中,直到 stop_reason != "tool_use" 为止。也就是说,从 "循环能不能跑起来" 这个角度看,s01 的目标其实已经完成了,s01 最大的贡献,是把 Agent 最底层的闭环骨架先搭了出来:模型、工具、消息、循环、退出条件。
但 s01 同时也留下了一个非常明显的 "后遗症":整个系统只有一个工具,那就是 bash。
在教学上,这种做法当然是合理的,因为只保留一个工具,注意力就不会被工具系统本身分散掉,我们可以先把最核心的 loop 看清楚。但从工程角度看,这种设计很快就会暴露出问题。因为只要所有能力都压缩进 bash 里,模型虽然表面上 "什么都能做",可程序真正接收到的,始终只是一段要交给 shell 执行的字符串。
也就是说,模型说的是 "我要读文件"、"我要写文件"、"我要编辑代码",但系统听到的其实只是 cat xxx、echo xxx > file、sed ... 这种命令文本。语义在模型这一侧,执行在 shell 那一侧,中间没有真正结构化的能力边界。
因此,当系统里只有 bash 时,所有操作都走 shell,而 shell 既不稳定,也不安全,专用工具才是真正适合 Agent 的接口形态。
4.1 问题
所以进入 s02 之后,我们首先想解决的,已经不是 "为什么要有 loop" 了,而是另一个更偏工程实现层的问题:为什么不能一直只用 bash?🤔
如果单从表面看,bash 其实是一个非常强的工具。你要读文件,可以 cat;你要查看目录,可以 ls;你要写文件,可以 echo、tee、heredoc;你要编辑文件,可以 sed、awk、perl -pi;你要跑测试,可以直接调用 pytest、npm test、make。
从"能力覆盖面"来说,一个 bash 的确足以把很多事情都做掉。所以在 s01 里,我们才会刻意只保留它,因为这样最容易说明:一个循环 + 一个能触达外部世界的工具,就已经足以构成最小 Agent。
但问题在于,bash 虽然强,却不是一个好的 Agent 接口。原因很简单:bash 对人类开发者来说很自然,因为我们能理解 shell 生态里隐含的大量默认规则;但对 Agent 系统来说,bash 的输入和输出都太 "松散" 了。
比如读取文件时,如果模型调用的是 cat requirements.txt,那程序只能把这整段字符串原封不动交给 shell。程序并不知道模型想表达的其实是 "读取这个路径对应的文件",它只知道 "执行这条命令"。一旦命令写错、路径转义有问题、输出太长,或者模型用了某些特殊字符,整个过程就会变得不可控。
文档里其实已经明确点出了两个特别典型的问题。第一个问题是 稳定性 :cat 的输出可能被截断,sed 在遇到特殊字符时极其脆弱,这些问题对人类开发者来说也许只是 "小麻烦",但对依赖上下文继续推理的模型来说,却会直接影响下一轮决策。第二个问题是 安全性:只要每次都是让模型自由拼接 bash 命令,那么工具层实际上就暴露了一个非常宽的攻击面。
也就是说,我们这一节真正想解决的问题可以概括为一句话:
Agent 不能只会 "调用 shell",它需要一组真正结构化、可控、可扩展的工具。
4.2 解决方案
明确问题之后,s02 给出的解法非常直接:把原本藏在 bash 里的能力,一项一项拆成独立工具,如下所示:
shell
+--------+ +-------+ +------------------+
| User | ---> | LLM | ---> | Tool Dispatch |
| prompt | | | | { |
+--------+ +---+---+ | bash: run_bash |
^ | read: run_read |
| | write: run_wr |
+-----------+ edit: run_edit |
tool_result | } |
+------------------+
The dispatch map is a dict: {tool_name: handler_function}.
One lookup replaces any if/elif chain.所以这一节里,系统不再只有一个 bash,而是开始引入:
read_filewrite_fileedit_file- 以及保留的
bash
文档里对这个设计的总结也非常干脆:加工具,不需要改循环,只需要给这个新工具增加一个 handler,然后把它注册进 dispatch map 里。
这里最值得注意的,并不是 "工具从 1 个变成了 4 个",而是工具的表达方式发生了根本变化。在 s01 中,模型调用的是:
json
{
"name": "bash",
"input": {
"command": "cat requirements.txt"
}
}而到了 s02,模型可以调用的就不再只是 "一段命令字符串",而是更接近函数调用的结构,比如:
json
{
"name": "read_file",
"input": {
"path": "requirements.txt",
"limit": 100
}
}这一步变化的意义非常大。因为从这时起,程序接收到的已经不再只是 "要交给 shell 的字符串",而是 一个带明确语义和明确参数的能力请求。也就是说,系统第一次真正开始知道:模型此时不是在 "执行命令",而是在 "读取文件"。
这正是 s02 和 s01 的根本区别之一:s01 里,工具的能力边界几乎完全依赖 prompt 和 bash 本身;而 s02 里,能力边界第一次被提升到了代码层和 schema 层。
4.3 Tool Dispatch Map 分析
前面我们提到要把工具从 bash 里拆出来了,也看到了系统里不再只有一个工具,而是变成了 read_file、write_file、edit_file 以及保留下来的 bash,我们来分析下这些工具的调度:
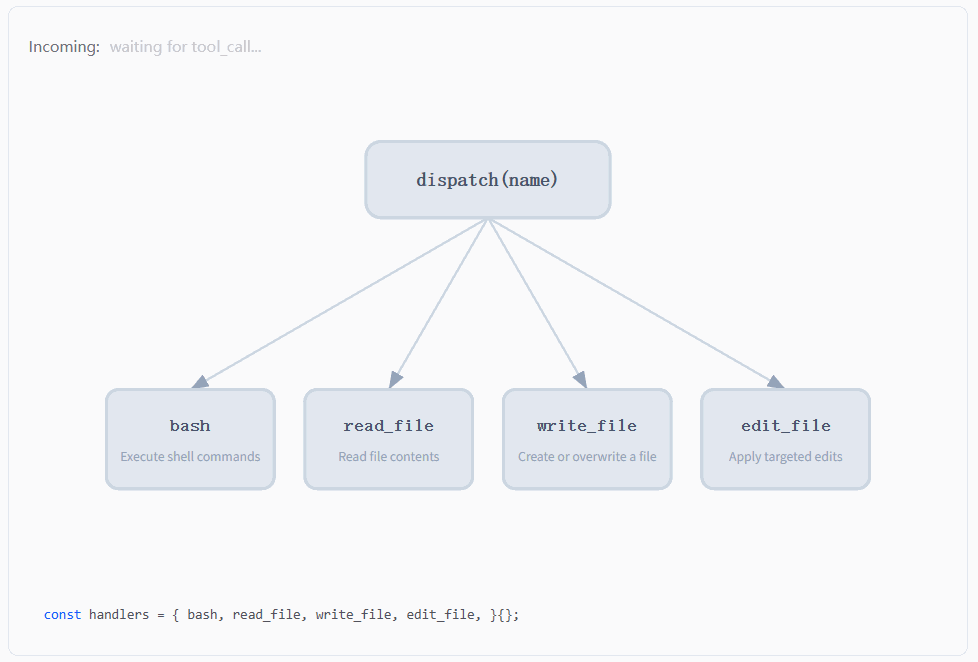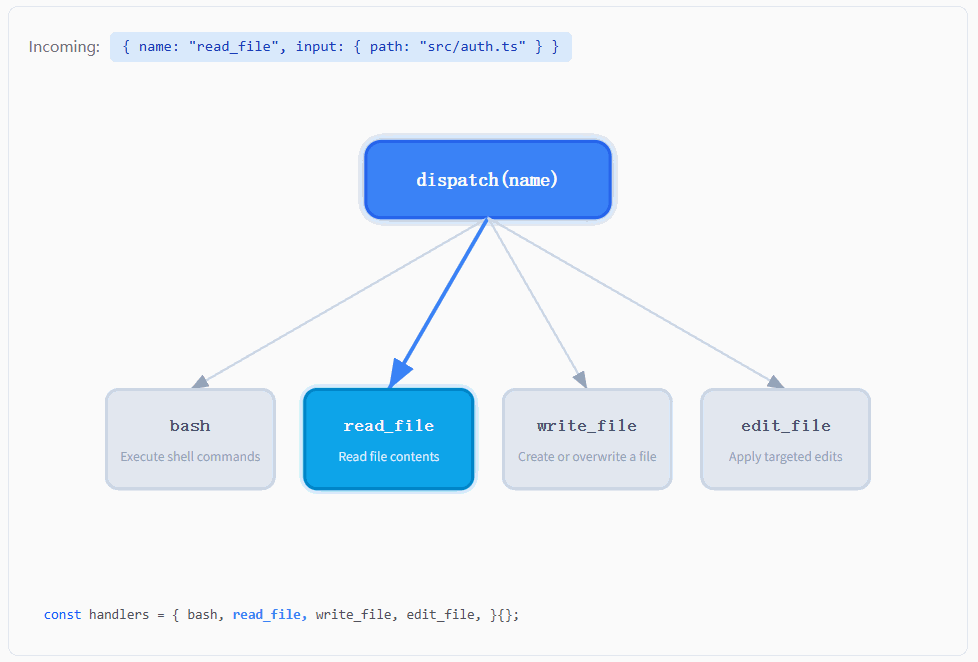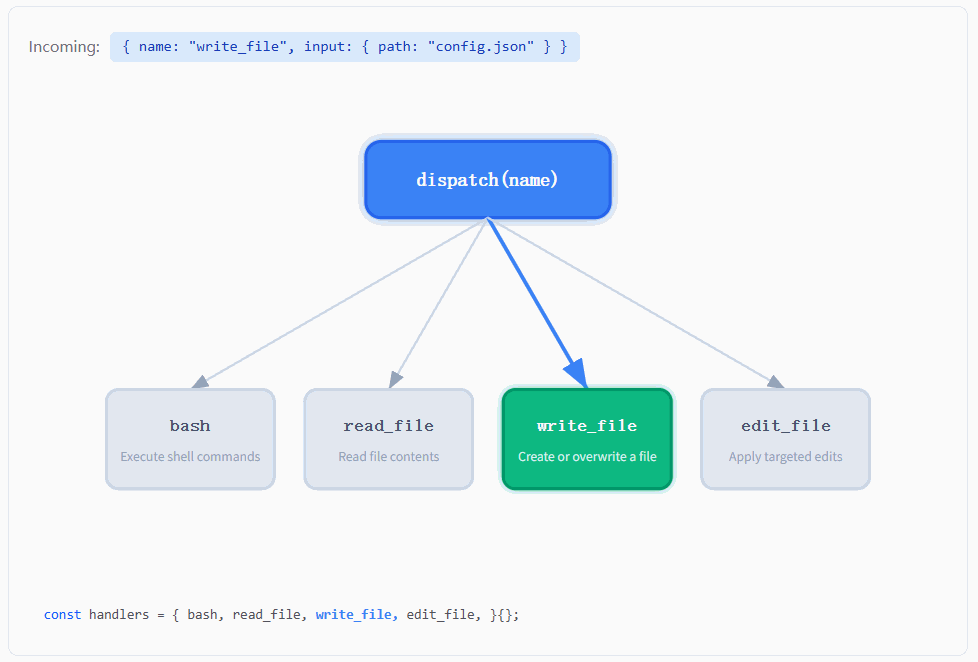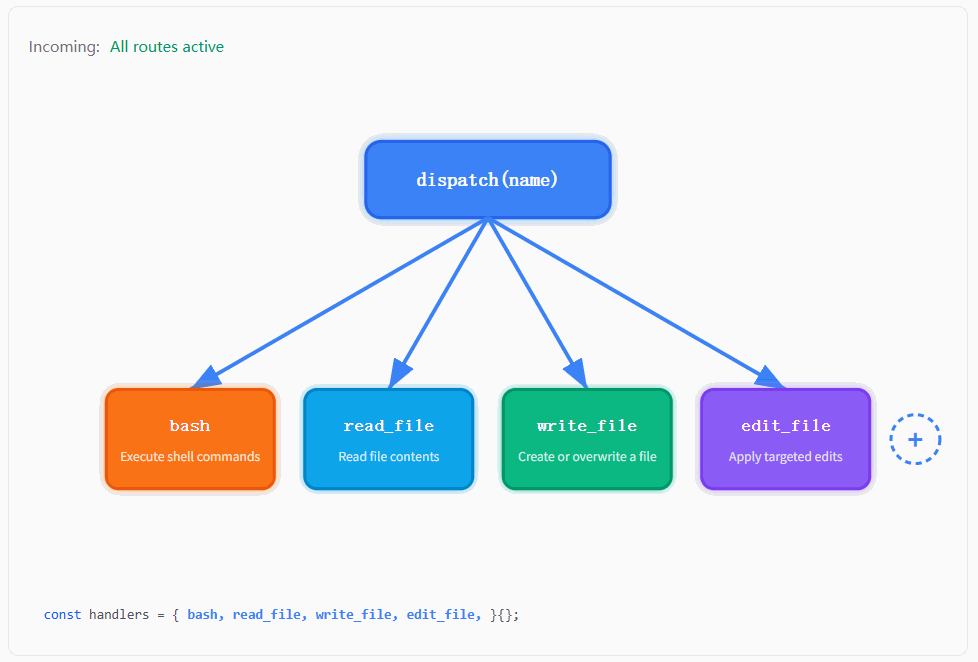
如图所示,最上面是一个 dispatch(name),下面分叉到四个工具节点,随着输入的 tool name 不同,高亮路径会在不同的分支之间切换,而整个系统始终沿着同一条逻辑在运行。
也就是说,无论模型这一轮输出的是 bash、read_file、write_file 还是 edit_file,系统内部发生的事情始终是一样的:先拿到这个 name,然后交给 dispatch 层去做一次查找,找到对应的 handler,再把输入参数传进去执行,最后把执行结果包装成 tool_result 再喂回模型。工具在变化,但这条路径本身没有发生任何改变。
这和 s01 的实现形成了一个非常鲜明的对比。在 s01 里,因为只有一个工具,所以程序里根本不需要 "选择",直接写死调用 bash 就可以了。也就是说,"用哪个工具" 这件事在代码里是硬编码的。而到了 s02,这一层选择被完整地抽出来,变成了一次运行时的动态决策:模型只负责给出 name,程序再通过一张映射表去找到真正的执行函数。
4.4 工作原理(代码分析)
理解了工具调度图之后,再去看 s02_tool_use.py 的源码,就会发现它和 s01_agent_loop.py 的整体结构其实非常像。文件顶部依然是环境初始化、加载 .env、构造 Anthropic 客户端、读取 MODEL_ID。这些部分和 s01 基本一致,因为它们都属于 "运行时准备层",而不是这一节真正变化的重点,这里我们就跳过了。
真正开始体现 s02 主题的,是这一句系统提示词:
python
SYSTEM = f"You are a coding agent at {WORKDIR}. Use tools to solve tasks. Act, don't explain."如果你和 s01 对比,就会发现一个细微但非常关键的变化。s01 里写的是 Use bash to solve tasks ,而到了 s02,这里已经变成了 Use tools to solve tasks。也就是说,从系统提示词层面,这个 Agent 的心智模型就已经发生了变化:它不再被定义成 "一个会用 bash 的 coding agent",而是被定义成 "一个会用一组 tools 的 coding agent"。
接下来就进入了这一节新增的第一个核心部分:路径沙箱。
在 s01 里,bash 工具的安全边界主要靠简单黑名单,比如拦截 rm -rf /、sudo 之类命令。这种方式当然能挡住最明显的危险情况,但它本质上还是 "命令级补丁"。到了 s02,随着 read_file、write_file、edit_file 这些专用文件工具出现,终于可以把一部分安全控制从 prompt 层和命令层,真正下沉到工具实现层了。
最典型的就是这个函数:
python
def safe_path(p: str) -> Path:
path = (WORKDIR / p).resolve()
if not path.is_relative_to(WORKDIR):
raise ValueError(f"Path escapes workspace: {p}")
return path这个函数不长,但作用非常大。它做的事情其实很简单:无论模型传进来的路径是什么,都先把它解析成一个绝对路径,然后检查这个绝对路径是否还位于当前工作目录 WORKDIR 之内,如果不在,就直接抛异常。
也就是说,从这一刻起,模型虽然仍然 "可以指定路径",但它已经不可能通过 ../../ 这种方式逃逸到工作区外面了。这里最值得注意的一点是:这种安全并不是通过提醒模型 "不要这么做" 实现的,而是通过代码让它 "做不到" 来实现的。
这正是工程系统和提示词工程的一个关键区别,提示词是软约束,代码是硬约束,s02 在工具层第一次加上的,恰恰就是这种硬约束。
有了 safe_path 之后,再来看三个新增工具函数就会非常清楚。
先看 run_read:
python
def run_read(path: str, limit: int = None) -> str:
try:
text = safe_path(path).read_text()
lines = text.splitlines()
if limit and limit < len(lines):
lines = lines[:limit] + [f"... ({len(lines) - limit} more lines)"]
return "\n".join(lines)[:50000]
except Exception as e:
return f"Error: {e}"这个函数其实很能体现 "结构化工具" 相对于 bash 的优势。首先,它先通过 safe_path 约束路径;其次,它支持 limit 参数,允许只读取前面若干行;最后,它还会统一截断输出长度,避免把超长内容原样塞回上下文。也就是说,读取文件这件事,第一次被系统定义成了一个受控的能力,而不是一条随意拼接的 shell 命令。
再看 run_write:
python
def run_write(path: str, content: str) -> str:
try:
fp = safe_path(path)
fp.parent.mkdir(parents=True, exist_ok=True)
fp.write_text(content)
return f"Wrote {len(content)} bytes to {path}"
except Exception as e:
return f"Error: {e}"这个函数相比 shell 写文件更加稳定。因为通过 echo、cat <<EOF 之类方式写文件时,shell 会引入转义、引号、多行内容格式这些额外问题,而 run_write 则把整个过程变成了非常直接的 "路径 + 内容" 二元操作。程序知道模型要写什么,也知道写到哪里,过程中不再需要借助 shell 的那些隐式规则。
最后看 run_edit:
python
def run_edit(path: str, old_text: str, new_text: str) -> str:
try:
fp = safe_path(path)
content = fp.read_text()
if old_text not in content:
return f"Error: Text not found in {path}"
fp.write_text(content.replace(old_text, new_text, 1))
return f"Edited {path}"
except Exception as e:
return f"Error: {e}"这个工具特别值得注意,我们并没有一上来就设计一个复杂的 patch 系统或者 AST 编辑器,而是采用了一个非常教学化、非常容易理解的思路:精确替换一段旧文本。 如果旧文本找不到,就直接返回错误。
当然,s02 最重要的新增并不只是多了三个工具函数,而是多了这段映射关系:
python
TOOL_HANDLERS = {
"bash": lambda **kw: run_bash(kw["command"]),
"read_file": lambda **kw: run_read(kw["path"], kw.get("limit")),
"write_file": lambda **kw: run_write(kw["path"], kw["content"]),
"edit_file": lambda **kw: run_edit(kw["path"], kw["old_text"], kw["new_text"]),
}这段代码其实就是前面 Tool Dispatch Map 图的源码落地版。它做的事情非常明确:把工具名字映射到具体 handler。程序后面不需要写一长串 if/elif 去判断工具名,也不需要对每个工具单独写一个特殊分支,而是只需要做一次字典查找。
这里最关键的不是 "字典比 if/elif 更简洁",而是这段映射让系统第一次拥有了一个真正统一的工具调度层。也就是说,从这一刻起,加工具这件事不再意味着 "改循环",而只意味着 "往这张表里加一项" 。这正是教程那句格言 Adding a tool means adding one handler 的真正含义。
有了 handler 映射还不够,因为 handler 只是程序这一侧的执行实现;模型这一侧还必须知道 "有哪些工具可用,以及这些工具的参数是什么"。这就是 TOOLS 数组存在的意义:
python
TOOLS = [
{"name": "bash", "description": "Run a shell command.",
"input_schema": {"type": "object", "properties": {"command": {"type": "string"}}, "required": ["command"]}},
{"name": "read_file", "description": "Read file contents.",
"input_schema": {"type": "object", "properties": {"path": {"type": "string"}, "limit": {"type": "integer"}}, "required": ["path"]}},
{"name": "write_file", "description": "Write content to file.",
"input_schema": {"type": "object", "properties": {"path": {"type": "string"}, "content": {"type": "string"}}, "required": ["path", "content"]}},
{"name": "edit_file", "description": "Replace exact text in file.",
"input_schema": {"type": "object", "properties": {"path": {"type": "string"}, "old_text": {"type": "string"}, "new_text": {"type": "string"}}, "required": ["path", "old_text", "new_text"]}},
]在 s02_tool_use.py 里,TOOLS 明确列出了四个工具,每个工具都包含:
namedescriptioninput_schema
比如 read_file 的 schema 就定义了 path 和可选的 limit,write_file 的 schema 定义了 path 和 content,edit_file 的 schema 定义了 path、old_text、new_text。
这里其实又体现出一个很重要的系统分层:
TOOLS:给模型看,让模型知道 "能调什么"TOOL_HANDLERS:给程序用,让程序知道 "怎么执行"
也就是说,同一个工具系统,同时面向两个世界:面向模型的是 schema,面向运行时的是 handler。 这两个层面一一对应,但职责并不相同。
理解了工具定义和 dispatch map 之后,再去看 agent_loop 我们会发现最底层几乎没变:
python
def agent_loop(messages: list):
while True:
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return
results = []
for block in response.content:
if block.type == "tool_use":
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input) if handler else f"Unknown tool: {block.name}"
print(f"> {block.name}: {output[:200]}")
results.append({"type": "tool_result", "tool_use_id": block.id, "content": output})
messages.append({"role": "user", "content": results})这段代码里最外层的 while True 没变,每轮先调用模型没变,把 assistant 的输出追加进 messages 没变,通过 stop_reason != "tool_use" 判断是否结束也没变,执行完工具之后再把 tool_result 作为新的 user 消息加回上下文同样没变。
真正变化的,只有工具执行那一小段:s01 里是直接 run_bash(...),而 s02 里变成了 "先通过 block.name 查 handler,再执行 handler"。
也正因为这样,s02 才第一次把一个特别重要的架构思想讲透了:Agent 的核心骨架不是工具本身,而是那个能持续驱动 "决策 → 执行 → 反馈" 的 loop。工具系统只是挂在这个 loop 上的能力层。
OK,以上就是 Tool 工作原理的完整分析了。
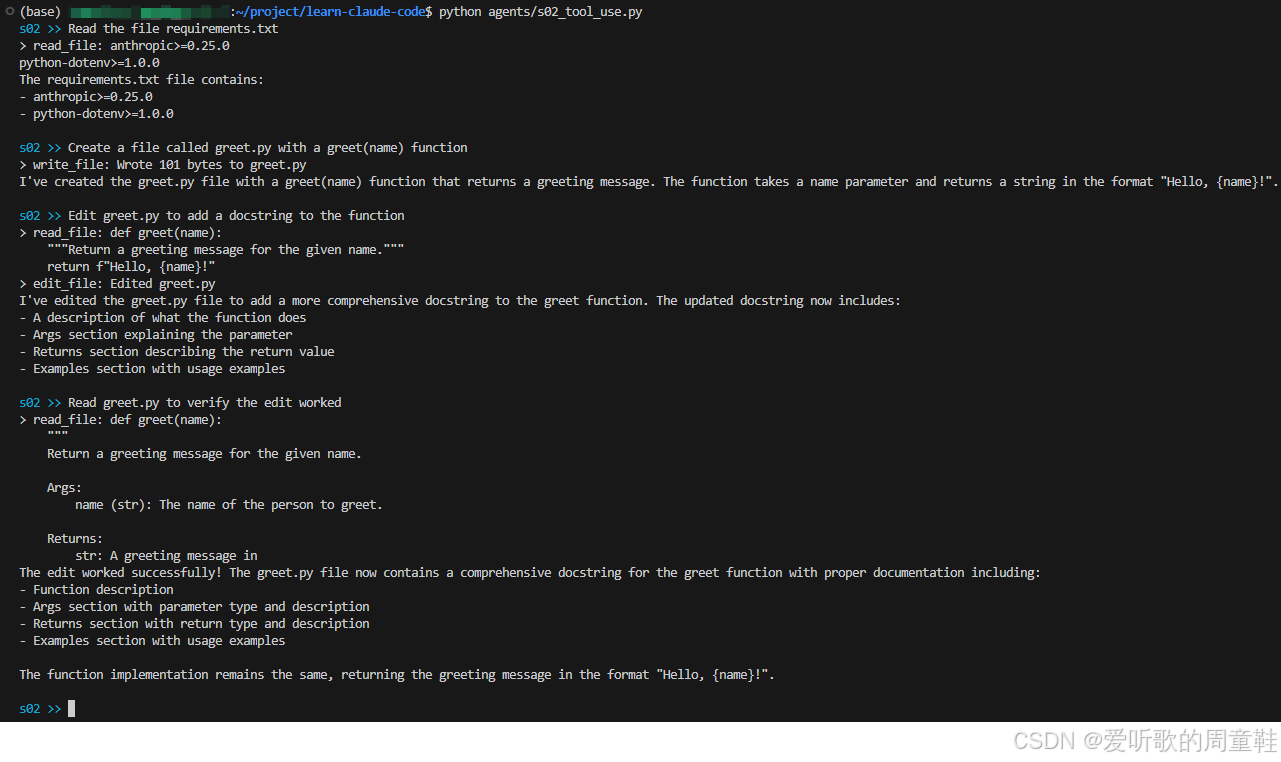
那大家感兴趣的话可以试试下面这些 prompt 感受下这个新增的 Tools 功能:
1. Read the file requirements.txt
2. Create a file called greet.py with a greet(name) function
3. Edit greet.py to add a docstring to the function
4. Read greet.py to verify the edit worked
博主体验后的输出如下:
4.5 相对 s01 的变更
| 组件 | 之前 (s01) | 之后 (s02) |
|---|---|---|
| Tools | 1 (仅 bash) | 4 (bash, read, write, edit) |
| Dispatch | 硬编码 bash 调用 | TOOL_HANDLERS 字典 |
| 路径安全 | 无 | safe_path() 沙箱 |
| Agent loop | 不变 | 不变 |
4.6 小结
如果说 s01 最大的贡献,是让我们接受一个最基本的事实 --- Agent 本质上就是一个不断把工具结果重新喂回模型的循环 ,那么 s02 的贡献就是让我们进一步看到:这个循环真正要变得可用,必须挂上一层结构化的工具系统。
从教程文档来看,这一节的核心结论其实非常集中:只有 bash 时,所有操作都走 shell,既不稳定也不安全;而引入专用工具之后,系统终于可以在工具层做路径沙箱、做参数约束、做输出控制,更重要的是,加工具不再需要改 loop,只需要给 dispatch map 增加一项映射。
所以,s02 的真正价值并不只是教我们写出 run_read、run_write、run_edit 这几个函数,而是第一次把 "工具系统" 从一个模糊概念,真正落实成了一套清晰的工程结构:schema + handler + dispatch map + 不变的 agent loop。从这一节开始,这个项目才真正开始显露出一种 "Agent 操作系统" 的雏形。
OK,以上就是本期想要分享的全部内容了。
结语
这篇文章我们从 Learn Claude Code 项目的前两个章节出发,重点梳理了 Agent 的最小运行形态:Agent Loop 与 Tool Use。
在 s01 中,我们通过一个极简的 while-loop,把 "决策 → 执行 → 反馈" 连接成闭环,让模型从 "只能生成文本" 真正变成 "可以执行任务";而在 s02 中,我们进一步将执行能力从不稳定的 bash 提升为结构化工具系统,使整个 Agent 在工程上变得更加可控与可扩展。
这两部分叠加之后,一个关键变化已经发生:模型不再只是参与对话,而是开始在一个真实环境中持续行动,并根据执行结果不断修正自己的决策路径。
从工程视角来看,本篇最重要的收获并不是具体代码实现,而是一个核心认知:Agent 的能力边界,取决于模型外部的运行环境(Harness),而不是模型本身。模型负责 "想做什么",而系统负责 "如何做到,以及如何保证过程稳定运行"。
同时,这里也隐含了后续章节的一个关键设计原则:控制流保持简单,能力层不断扩展。无论是任务规划、子智能体还是技能加载,本质上都只是围绕这一条最小 loop 逐步增强,而不是重新设计一套新的执行框架。
也正因为如此,这个项目真正想教会我们的,并不是如何 "调用模型",而是如何从最小闭环出发,一步一步构建出一个可演进的 Agent 系统。
接下来,我们将进入一个新的阶段:当任务不再简单时,Agent 如何进行规划与拆解,敬请期待🤗。