上一篇文章完成了 BERT 在 ChnSentiCorp 上的微调训练 ,并保存了验证集最优参数与最后一轮参数。训练时的 loss、验证集 acc 只能说明「学得好不好」,还要关注模型判得准不准:
模型上线后,能否达到甲方要求?负面评价漏检多少?差评被错判成好评的有多少?
微调阶段中还有一个重要的步骤------模型测试 :设计评估指标,在测试集上验收微调效果,并给出可落地的验收口径。
上一篇文章快速导航:《(五)模型微调训练:基于 BERT 的中文评价情感分析附源码》(mp.weixin.qq.com/s/l28Efd2gH...)
需要本章配套源码和数据集的同学,可以点赞 + 关注,我会把完整工程发给你。
1. 为什么要做效果评估?
从数据 → 训练 → 测试。训练阶段用验证集(validation)调参、选最优权重;
测试集(test)只在最终验收时用一次,避免「背答案」导致指标虚高。
| 数据集 | 用途 | 是否用于最终报告 |
|---|---|---|
| train | 更新模型参数 | 否 |
| validation | 选最优 epoch、早停 | 否(仅训练过程参考) |
| test | 对外汇报的正式成绩 | 是 |
对甲方或业务方,通常不会只看「准确率 90%」,还会关注:
- 整体准确率 ≥ 88%
- 负面(label=0)召回率 ≥ 85%(少漏检差评)
- 正面(label=1)精确率 ≥ 90%(少把好评判成差评)
指标选对了,验收才有据可查。
为了更直观理解「为什么要同时关注漏判和误判」,先看几个常见业务场景。
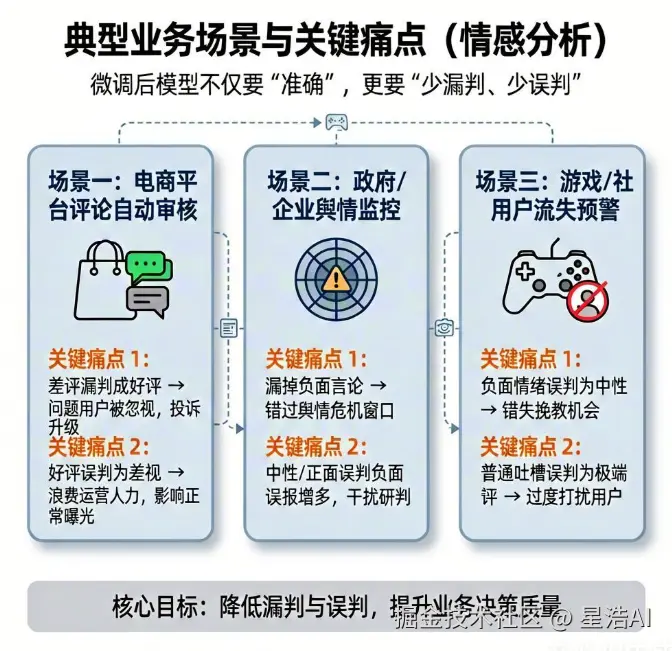
场景一:电商平台的评论区自动审核
每天数百万条用户评价,平台希望自动筛选出差评,优先推送给运营处理(如联系客户、补偿解决)。
关键痛点:
- 差评漏判成好评:问题用户被忽视,投诉升级,甚至引发公关危机
- 好评误判为差评:浪费运营人力,影响正常商品曝光
场景二:政府/企业的舆情监控系统
监测微博、公众号、投诉平台中关于某品牌/政策的负面声音,要求第一时间发现负面苗头,防患于未然。
关键痛点:
- 漏掉一条负面言论:可能错过舆情危机发酵的关键窗口
- 将中性或正面内容标为负面:严重干扰研判,导致误报泛滥
场景三:游戏/社交产品的用户流失预警
用户在卸载、挂机、打差评前的一句话反馈,系统需实时判断是否弹出安抚问卷或赠送礼包。
关键痛点:
- 把负面情绪误判为中性:失去挽回高价值用户的黄金机会
- 把普通吐槽误判为极端差评:过度打扰用户,反而加速流失
可以看到,不同场景对「漏判」和「误判」的容忍度不同。
下面进入指标部分,看看如何用准确率、精确率、召回率、F1 和混淆矩阵把这些痛点量化出来。
2. 分类任务的核心指标
中文情感分析基准数据集(ChnSentiCorp)是一个典型的二分类 文本情感分析数据集:label=0 为负面,label=1 为正面。标签定义见数据集 dataset_info.json:
json
"features": {
"text": {
"dtype": "string",
"id": null,
"_type": "Value"
},
"label": {
"num_classes": 2,
"names": [
"negative",
"positive"
],
"id": null,
"_type": "ClassLabel"
}
}标签含义:
0:负面情感(negative)1:正面情感(positive)
2.1 混淆矩阵
混淆矩阵 (Confusion Matrix)是一张「预测结果对照表」:横轴(或列)表示模型预测的标签 ,纵轴(或列)表示数据真实的标签,每个格子填的是「落在这一类组合上的样本数」。
- 对角线:预测与真实一致,即判对的样本
- 非对角线:预测与真实不一致,即判错的样本
它不会直接给出一个百分比,但能把错在哪一类、错多少一眼看清楚,是计算准确率、精确率、召回率、F1 的基础。
二分类混淆矩阵的结构如下图表示:
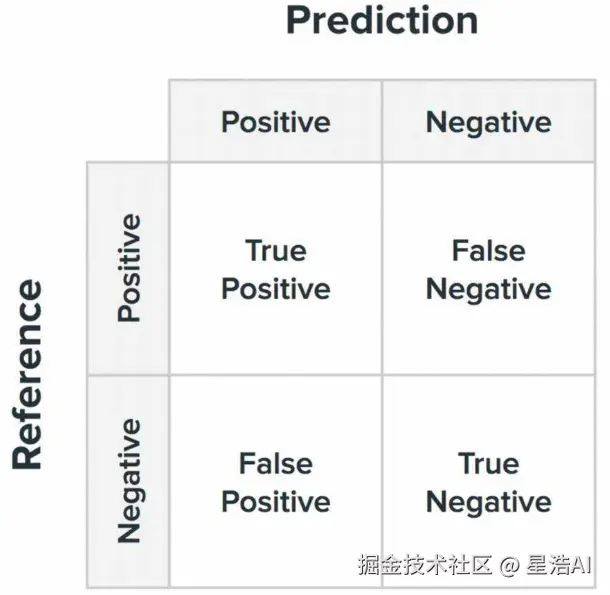
| 实际为正面 | 实际为负面 | |
|---|---|---|
| 预测为正面 | TP | FP |
| 预测为负面 | FN | TN |
- TP:真正例(预测正确,且为正)
- TN:真负例(预测正确,且为负)
- FP :假正例(预测错误,实际为负,但预测为正)(差评被错判为好评)
- FN :假负例(预测错误,实际为正,但预测为负)(漏掉好评 ;若正类改为「负面」则对应漏检差评)
举例说明
假设在测试集上抽 100 条评价跑完模型,统计结果如下(行=模型预测,列=真实标签):
| 实际为正面 | 实际为负面 | 行合计 | |
|---|---|---|---|
| 预测为正面 | 42(TP) | 6(FP) | 48 |
| 预测为负面 | 8(FN) | 44(TN) | 52 |
| 列合计 | 50 | 50 | 100 |
对应到具体业务含义:
| 格子 | 数量 | 含义 | 示例 |
|---|---|---|---|
| TP | 42 | 好评判对了 | 真实「物流很快,满意」→ 预测正面 ✓ |
| TN | 44 | 差评判对了 | 真实「质量太差,不推荐」→ 预测负面 ✓ |
| FP | 6 | 差评被错判成好评 | 真实「非常失望」→ 却预测正面 ✗ |
| FN | 8 | 好评被错判成差评 | 真实「性价比不错」→ 却预测负面 ✗ |
由此可以快速读出:
- 一共判对 :42 + 44 = 86 条 → 准确率 = 86 / 100 = 86%
- 实际 50 条正面里 ,模型找出了 42 条 → 正面召回率 = 42 / 50 = 84%(有 8 条好评被漏判成差评)
- 模型预测 48 条为正面里 ,真正是好评的有 42 条 → 正面精确率 = 42 / 48 = 87.5%(有 6 条差评被混进来)
结合混淆矩阵,对照 2.2 的基础评估指标,轻松评估微调效果。
2.2 基础评估指标
| 指标 | 别名 | 公式 | 含义 |
|---|---|---|---|
| 准确率 Accuracy | 正确率 | (TP + TN) / 总数 | 总体预测正确的比例 |
| 精确率 Precision | 查准率 | TP / (TP + FP) | 预测为正例中,实际为正的比例 |
| 召回率 Recall | 查全率 | TP / (TP + FN) | 实际为正例中,被正确预测的比例 |
| F1 F1 Score | F 值 | 2 × P × R / (P + R) | 精确率与召回率的调和平均 |
2.2.1 准确率(Accuracy)
- 定义:正确预测的样本数占总样本数的比例。
- 公式:Accuracy = (TP + TN) / (TP + TN + FP + FN)
- 适用场景:各类别样本数量接近、误判代价相近时,用来看「整体猜对多少」最直观。
- 局限性:类别不平衡时容易「虚高」------例如 90% 是正面,模型全猜正面也能有 90% 准确率,但负面几乎全错。
举例:判对 86 条、共 100 条 → Accuracy = 86%。
2.2.2 精确率(Precision)
- 定义 :在所有被模型预测为正例的样本里,真正是正例的比例(查准率:预测得准不准)。
- 公式:Precision = TP / (TP + FP)
- 适用场景 :更在意假正例 FP 时优先看精确率。情感分析中若把正类定为「正面」,高精确率意味着:模型说是好评的,多半真是好评,较少把差评错判成好评。
- 业务类比:垃圾邮件检测------宁可漏掉少量垃圾邮件,也不能把正常邮件大量标成垃圾(减少「误报」)。
举例:预测为正面的 48 条里,真好评 42 条 → Precision = 42 / 48 ≈ 87.5%。
2.2.3 召回率(Recall)
- 定义 :在所有实际为正例的样本里,被模型正确找出来的比例(查全率:找得全不全)。
- 公式:Recall = TP / (TP + FN)
- 适用场景 :更在意假负例 FN 时优先看召回率。正类为「正面」时,高召回率意味着:实际好评里大部分都被识别出来,少漏判。
- 业务类比 :疾病筛查------宁可多查一些疑似阳性,也不能大量漏掉真患者(减少「漏检」)。若验收重点是不能漏掉差评 ,应把正类设为「负面」,重点看负面召回率。
举例:实际好评 50 条里,找出 42 条 → Recall = 42 / 50 = 84%。
2.2.4 F1 分数(F1 Score)
- 定义 :精确率 P 与召回率 R 的调和平均数,同时兼顾「准」和「全」。
- 公式:F1 = 2 × P × R / (P + R)
- 适用场景 :需要在精确率与召回率之间折中,或类别略有不平衡、不宜只盯准确率时,常用 F1 作综合指标。P、R 有一项很低,F1 也会被拉低。
- 说明:为何用「调和平均」而不是算术平均?因为调和平均对较低的那一项更敏感,能避免「一项很高、一项很差」仍得到好看的整体分数。
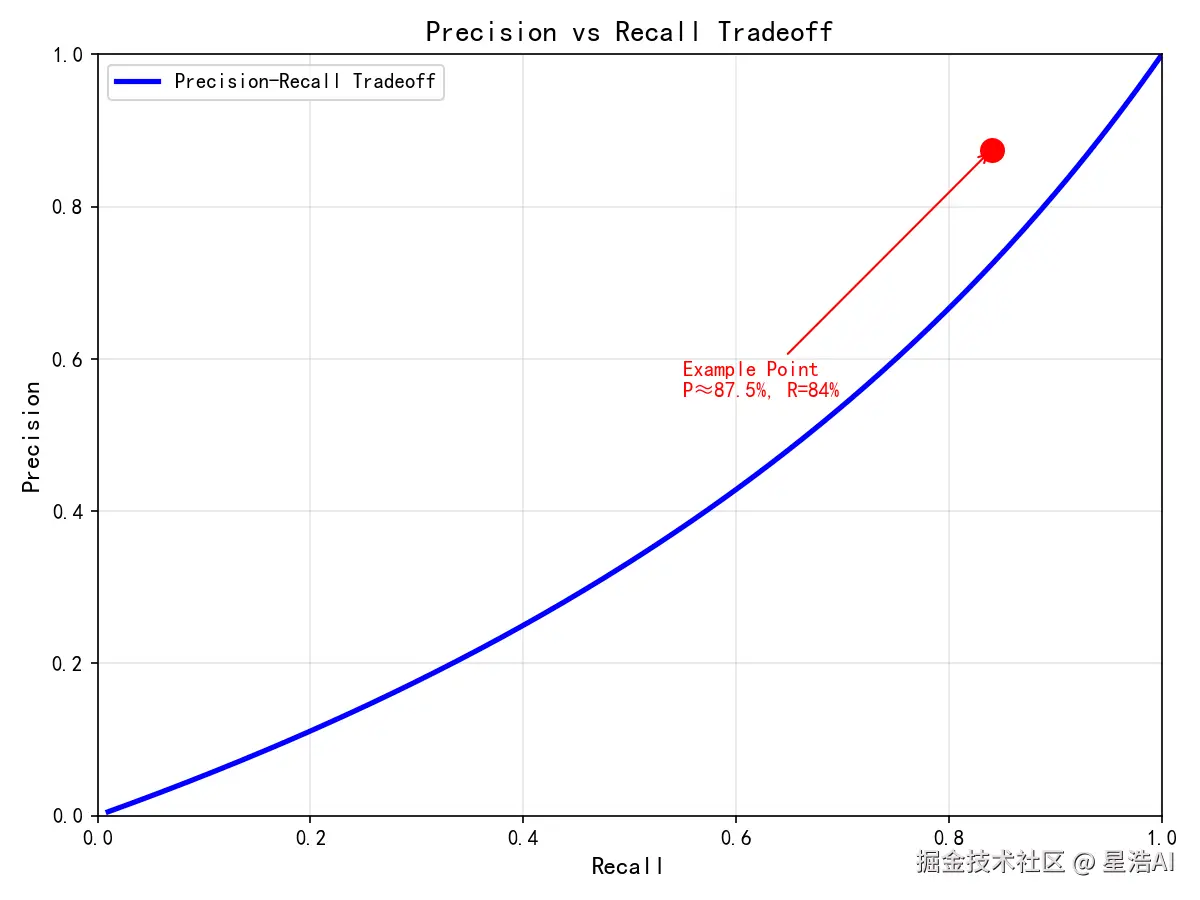
举例:P ≈ 87.5%、R = 84% → F1 ≈ 2 × 0.875 × 0.84 / (0.875 + 0.84) ≈ 85.7%。
怎么选指标?
| 场景 | 推荐指标 | 原因 |
|---|---|---|
| 类别平衡 | 准确率 | 直观反映整体正确率 |
| 类别不平衡 | F1 宏平均 | 平等对待各类别 |
| 假正例敏感 | 精确率 | 减少错误肯定 |
| 假负例敏感 | 召回率 | 减少错误否定 |
| 大类别主导 | F1 加权平均 | 考虑样本分布 |
对照本案例(二分类情感分析):
- ChnSentiCorp 正负样本大致类别平衡 → 准确率仍有参考价值。
- 若甲方强调不能漏检差评 (FN 代价大)→ 看负面召回率(假负例敏感)。
- 若强调不能把差评错判成好评 (FP 代价大)→ 看正面精确率或负面一侧的精确率(假正例敏感)。
- 上线验收时仍建议同时看 F1 与混淆矩阵,避免单一指标「好看但业务翻车」。
若业务要扩展为「好评 / 中评 / 差评」等多分类,模型改动与评估策略见 第 5 章。
2.3 精确率与召回率的权衡
markdown
预测质量 ↑
│ 高召回(阈值低,多判为正)
│ ↗
│ ↗ 理想平衡点(F1 最大附近)
│ ↗
│ ↗
└────────────────────────→ 预测覆盖范围
高精确(阈值高,少判为正)阈值调高 → 精确率升、召回率降;业务若更怕漏检,可适当偏向召回。
3. BERT 微调效果测试
这一节目标很简单:把「训练好的模型」在测试集上完整跑通,并得到可读的评估结果。
加载已训练的验证集最优参数 ,在 test 划分上完成批量推理与验收。
模型评估测试流程:
3.1 加载分词器
定义计算设备,必须加载与训练阶段相同的 BertTokenizer。
python
# 定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载字典和分词器
token = BertTokenizer.from_pretrained(
r"D:\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f"
)3.2 准备测试集
从磁盘读取数据集 ChnSentiCorp,本节只用于效果验收,所以固定使用 test。
python
from torch.utils.data import DataLoader
def collate_fn(data):
sents = [i[0] for i in data]
labels = [i[1] for i in data]
enc = token(
sents,
truncation=True,
max_length=512,
padding="max_length",
return_tensors="pt",
return_length=True
)
return (
enc["input_ids"],
enc["attention_mask"],
enc["token_type_ids"],
torch.LongTensor(labels),
)
test_dataset = MyDataset("test")
# 构建 DataLoader
test_loader = DataLoader(
dataset=test_dataset,
batch_size=100,
shuffle=False, # 评估不打乱
drop_last=False, # 保留全部样本
collate_fn=collate_fn,
)collate_fn 负责 batch 编码(要求与训练时参数一致),是批量评估的前置步骤。
ChnSentiCorp 的 test 约 1200 条。
测试集内容如下:
arduino
('外观,配置,价格,三个组合起来看是绝对超值的东东 我4699入手,抢到了', 1)
('已经贴完了,又给小区的妈妈买了一套。最值得推荐', 1)
('看到推荐的很好,就买了。宝宝好像不喜欢,连看也不看就扔到沙发后面了。郁闷阿', 0)
('一般一般,以后肯定不会再住这里了,服务一般', 0)3.3 加载最优权重
直接加载训练阶段保存的最优权重:
python
model = MyModel().to(DEVICE)
model_path = "params/最优参数文件"
model.load_state_dict(torch.load(model_path, map_location=DEVICE))
model.eval()最优参数文件来自训练阶段在验证集上表现最好的 epoch。
3.4 评估模型(批量评估)
这一部分只做一件事:遍历 test_loader,拿到预测结果,然后计算评估指标。
python
# pip install scikit-learn
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
confusion_matrix, classification_report,
)下图展示了 scikit-learn 库 metrics 模块中,分类任务最常用的模型评估指标函数。
| 函数 | 核心作用 | 适用场景 |
|---|---|---|
accuracy_score |
准确率:预测正确的样本占总样本的比例 | 样本均衡时的最直观评估 |
precision_score |
精确率:预测为正的样本中,实际为正的比例 | 重视「查准」,如垃圾邮件拦截 |
recall_score |
召回率:实际为正的样本中,被正确预测的比例 | 重视「查全」,如疾病筛查 |
f1_score |
F1分数:精确率和召回率的调和平均数 | 需要同时兼顾查准和查全时 |
confusion_matrix |
混淆矩阵:以矩阵形式展示预测结果(TP, FP, FN, TN) | 深入分析模型在各类别上的具体表现 |
classification_report |
分类报告:一次性输出所有类别的精确率、召回率、F1和支持数 | 快速生成完整的模型评估概览 |
python
# 评估模型
def evaluate_model(model, test_loader, device):
model.eval()
all_preds, all_labels = [], []
# 前向传播
with torch.no_grad():
for input_ids, attention_mask, token_type_ids, labels in test_loader:
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
token_type_ids = token_type_ids.to(device)
outputs = model(input_ids, attention_mask, token_type_ids)
preds = torch.argmax(outputs, dim=1)
# 收集预测结果
all_preds.extend(preds.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
# 计算评估指标
return {
"accuracy": accuracy_score(all_labels, all_preds),
"confusion_matrix": confusion_matrix(all_labels, all_preds),
"classification_report": classification_report(all_labels, all_preds, digits=4),
}
outputs = model(...)会自动调用模型类里的forward,完成前向推理。
想继续扩展的话,可在这个函数里再加 precision、recall、f1(macro / weighted)。
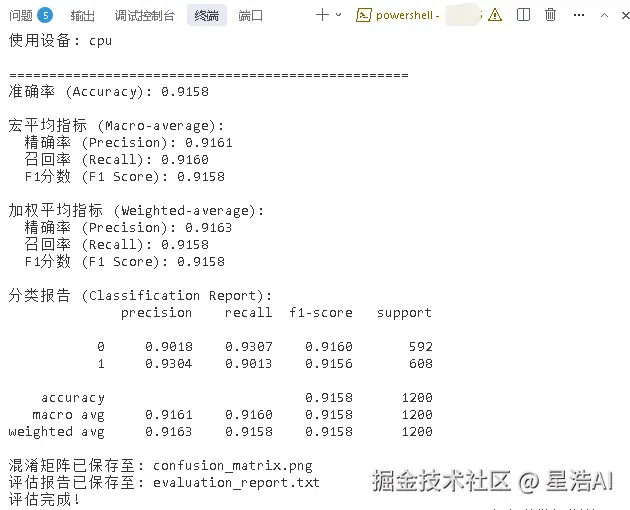
3.5 打印评估结果
python
metrics = evaluate_model(model, test_loader, DEVICE)
print(f"准确率 (Accuracy): {metrics['accuracy']:.4f}")
print("\n分类报告 (Classification Report):")
print(metrics['classification_report'])classification_report 中 0 对应负面、1 对应正面。
3.6 可视化混淆矩阵
python
import matplotlib.pyplot as plt
import seaborn as sns
class_names = ["负面", "正面"] # label=0 负面,label=1 正面
def plot_confusion_matrix(cm, class_names, save_path=None):
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=class_names, yticklabels=class_names)
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('混淆矩阵')
if save_path:
plt.savefig(save_path, bbox_inches='tight')
print(f"混淆矩阵已保存至: {save_path}")
plt.show()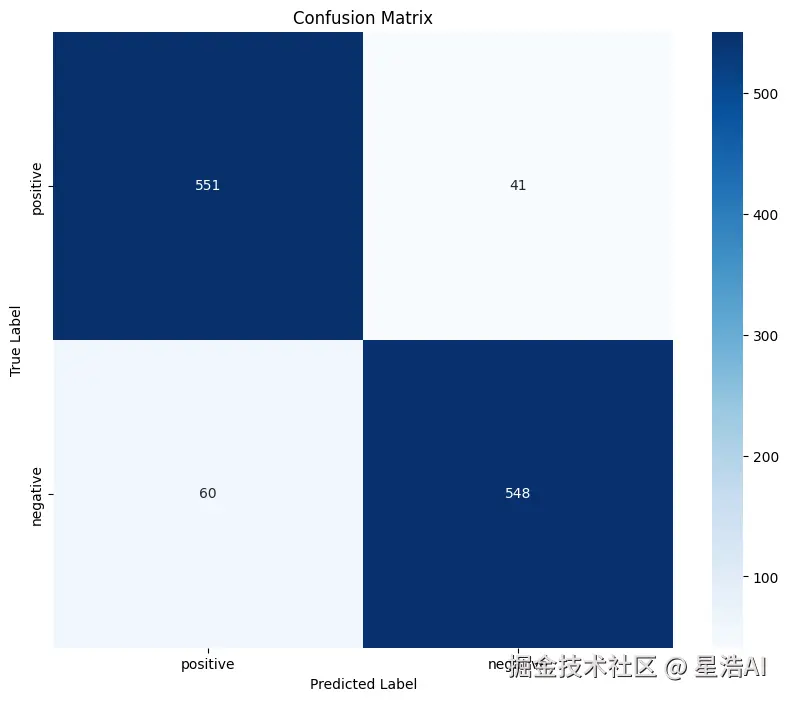
读图要点:
- 行 = 真实标签 ,列 = 预测标签
- 对角线:判对的样本数
- 非对角线:误判;例如「真实负面、预测正面」是把差评当成好评
- 若某一格特别大,可回到上一章训练部分抽 bad case 分析原因
3.7 综合评估报告
将指标与混淆矩阵写入文本文件,便于归档给甲方:
python
import numpy as np
save_path = "evaluation_report.txt"
with open(save_path, "w", encoding="utf-8") as f:
f.write("模型评估报告\n")
f.write("=" * 50 + "\n")
f.write(f"准确率 (Accuracy): {metrics['accuracy']:.4f}\n\n")
f.write("分类报告 (Classification Report):\n")
f.write(metrics["classification_report"])
f.write("\n\n混淆矩阵 (Confusion Matrix):\n")
np.savetxt(f, metrics["confusion_matrix"], fmt="%d")如何对照甲方口径?
| 指标 | 对应 | 业务含义 |
|---|---|---|
| 整体准确率 | accuracy |
全部样本判对比例 |
| 差评漏检 | label 0 的 recall |
漏检率 ≈ 1 − recall |
| 好评可信度 | label 1 的 precision |
判为好评时的可信度 |
| 样本量 | 各类 support |
应与 test 条数一致 |
3.8 验收流程小结
- 按流程完成测试评估,在固定测试集上只评一次正式指标
- 用
classification_report对齐甲方口径(label 0/1 对应负面/正面) - 用混淆矩阵定位薄弱类,再决定是加数据、改阈值还是继续训练
4. 验证模型训练效果
上一章节是客观评估 (测试集指标);本章节主观验证:手动输入几条评论,看模型判定是否符合直觉。
主观验证流程:
4.1 准备模型与标签映射
python
import torch
from transformers import BertTokenizer
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
token = BertTokenizer.from_pretrained(
r"D:\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f"
)
model = Model().to(DEVICE)
names = ["负向评价", "正向评价"] # 0 -> 负向,1 -> 正向为什么「负向评价、正向评价」顺序不能反?
- 模型预测结果是数字
0或1,names[pred]按下标取名称。 - 数据集约定:
0= 负面,1= 正面(与 §2 一致)。 - 因此
names[0]必须是负向,names[1]必须是正向;写反则显示与真实标签相反。
4.2 编码单条输入文本
python
def collate_one(text):
enc = token.batch_encode_plus(
[text],
truncation=True,
max_length=512,
padding="max_length",
return_tensors="pt",
)
return enc["input_ids"], enc["attention_mask"], enc["token_type_ids"]4.3 交互式验证
python
model_path = "params/最优参数文件"
model.load_state_dict(torch.load(model_path, map_location=DEVICE))
model.eval()
while True:
text = input("请输入测试数据(输入 q 退出):")
if text.lower() == "q":
print("测试结束")
break
input_ids, attention_mask, token_type_ids = collate_one(text)
input_ids = input_ids.to(DEVICE)
attention_mask = attention_mask.to(DEVICE)
token_type_ids = token_type_ids.to(DEVICE)
with torch.no_grad():
logits = model(input_ids, attention_mask, token_type_ids)
pred = logits.argmax(dim=1).item()
print("模型判定:", names[pred], "\n")针对正向 、负向 、以及无明显情感关键词三类句子做了主观试跑,示例结果如下。
正向测试
| 输入文本 | 模型判定 |
|---|---|
| 这个价格能买到这样的配置,我觉得值了。 | 正向评价 |
| 已经安利给三个朋友了。 | 正向评价 |
负向测试
| 输入文本 | 模型判定 |
|---|---|
| 包装上写的是全新,打开明显有划痕。 | 负向评价 |
| 买回来第一周就送去维修了。 | 负向评价 |
无明显情感关键词
| 输入文本 | 模型判定 |
|---|---|
| 用了一个月,没出现过任何让我想退货的念头。 | 正向评价 |
| 看到别人晒单的图,再看看我手里的,沉默了一分钟。 | 负向评价 |
| 你这搞啥呢,我谢谢你哟 | 负向评价 |

情感词明显时,关键词规则也能判;情感藏在上下文里时,微调模型更靠谱。
这一节用于演示与快速抽检;正式验收仍以第 3 章测试集指标为准。
5. 二分类延伸为多分类
ChnSentiCorp 与本章代码是二分类 (正面 / 负面)。实际业务里常需要更细粒度,例如「好评 / 中评 / 差评」三分类 ,甚至更多类别。下面把多分类相关的模型改动、混淆矩阵、评估策略、手算示例与代码集中说明。
5.1 模型与数据要改什么
| 改动点 | 二分类 | 多分类(如 N 类情感) |
|---|---|---|
| 输出层 | Linear(768, 2) |
Linear(768, K),K 为类别数 |
| 损失函数 | CrossEntropyLoss |
相同 |
| 标签 | 0 / 1 | 0 ... K-1 |
| 评估 | average="binary" |
average="macro" / "weighted" / "micro" |
| 报告 | 2 行 per-class | K 行 per-class |
数据加载、Tokenizer、训练循环与前一篇文章中使用一致:换标签体系、改输出维度后重训,按测试流程加载最优参数即可。
5.2 多分类混淆矩阵
二分类是 2×2 矩阵;n 分类 对应 n×n 矩阵(行=预测类别,列=真实类别):
- 对角线 TPi:第 i 类判对的样本数
- 非对角线 FPi→j:真实为 i、却判成 j 的样本数(类别间混淆情况)
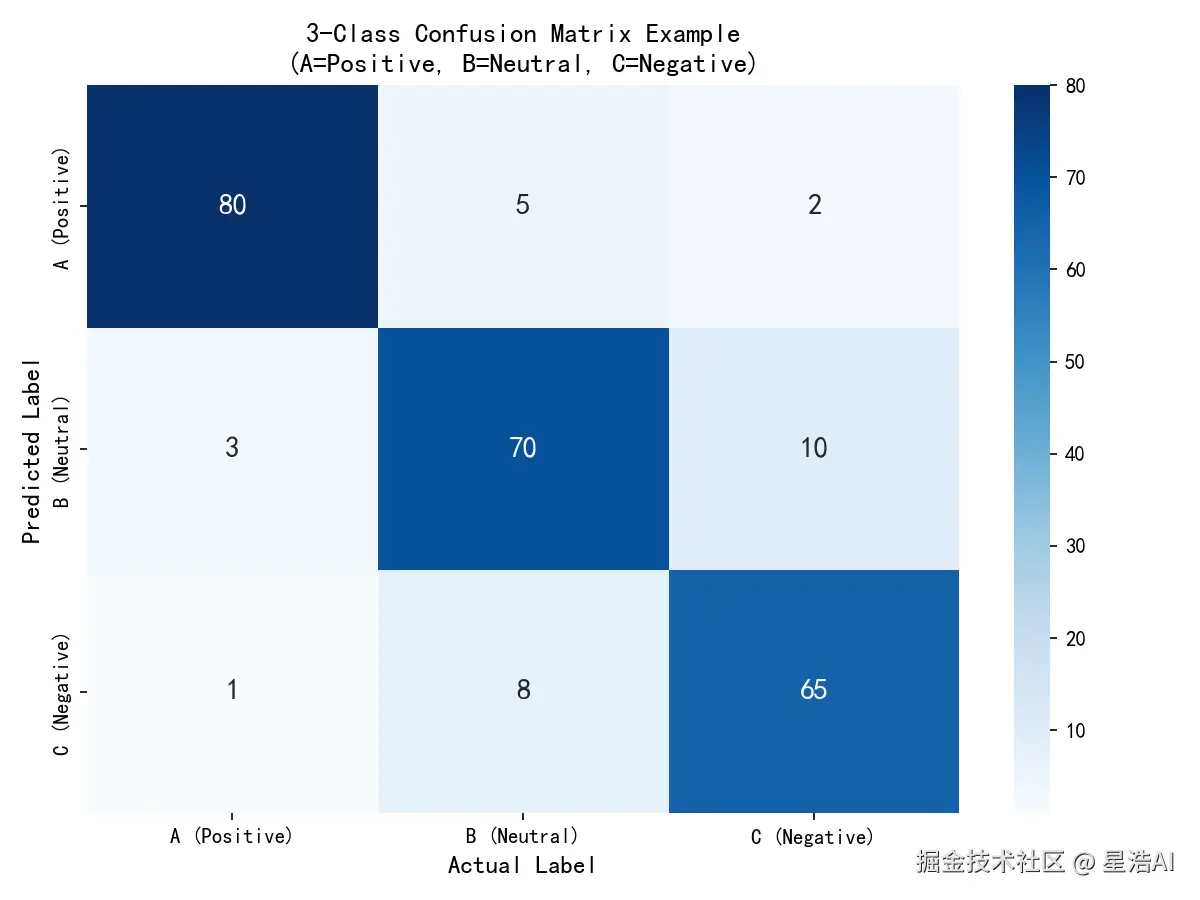
三分类示例(A=好评,B=中评,C=差评):
| 预测\实际 | A | B | C |
|---|---|---|---|
| A | TPA | 误判为 A | 误判为 A |
| B | 误判为 B | TPB | 误判为 B |
| C | 误判为 C | 误判为 C | TPC |
先看哪一格数字大,就知道模型常把哪两类搞混。
5.3 多分类评估策略:宏 / 加权 / 微平均
多分类时,需先对每一个类别 分别算精确率 Pi、召回率 Ri、F1 分数 F1i(做法与二分类相同:把当前类视为「正类」,其余类合并为「负类」),再聚合成一个总指标:
| 平均策略 | 精确率公式 | 召回率公式 | F1 分数公式 | 适用场景 |
|---|---|---|---|---|
| 宏平均 (Macro-average) | (P1+P2+⋯+Pn)/n | (R1+R2+⋯+Rn)/n | (F1,1+F1,2+⋯+F1,n)/n | 各类别权重相同,小类与大类同等重要 |
| 加权平均 (Weighted-average) | ∑(Pi×wi) wi = 类别 i 样本数 / 总样本数 | ∑(Ri×wi) | ∑(F1i×wi) | 考虑类别不平衡,样本多的类权重大 |
| 微平均 (Micro-average) | ∑TP/(∑TP+∑FP) | ∑TP/(∑TP+∑FN) | 2×(Micro-P×Micro-R)/(Micro-P+Micro-R) | 整体性能评估,先汇总全局 TP/FP/FN 再计算 |
怎么理解?
- 宏平均:先算各类指标再算术平均;适合「每一类都不能太差」。
- 加权平均:按各类样本占比加权;适合不平衡数据且要反映真实分布。
- 微平均:全局汇总 TP/FP/FN 后计算;大类主导,接近整体判对率思路。
sklearn.metrics.classification_report 默认输出每个类别的 P/R/F1,以及 macro avg 、weighted avg ;average='micro' 需在 precision_recall_fscore_support 中单独指定。
| 场景 | 推荐指标 |
|---|---|
| 各类样本量接近 | 宏平均 F1 |
| 类别不平衡 | 加权平均 F1 |
| 看整体、大类主导 | 微平均 |
| 关心某一具体类 | 该类单独的 P / R / F1 |
5.4 三分类指标演算示例
假设测试集共 244 条,混淆矩阵如下(行=预测,列=真实):
| 预测\实际 | A | B | C |
|---|---|---|---|
| A | 80 | 5 | 2 |
| B | 3 | 70 | 10 |
| C | 1 | 8 | 65 |
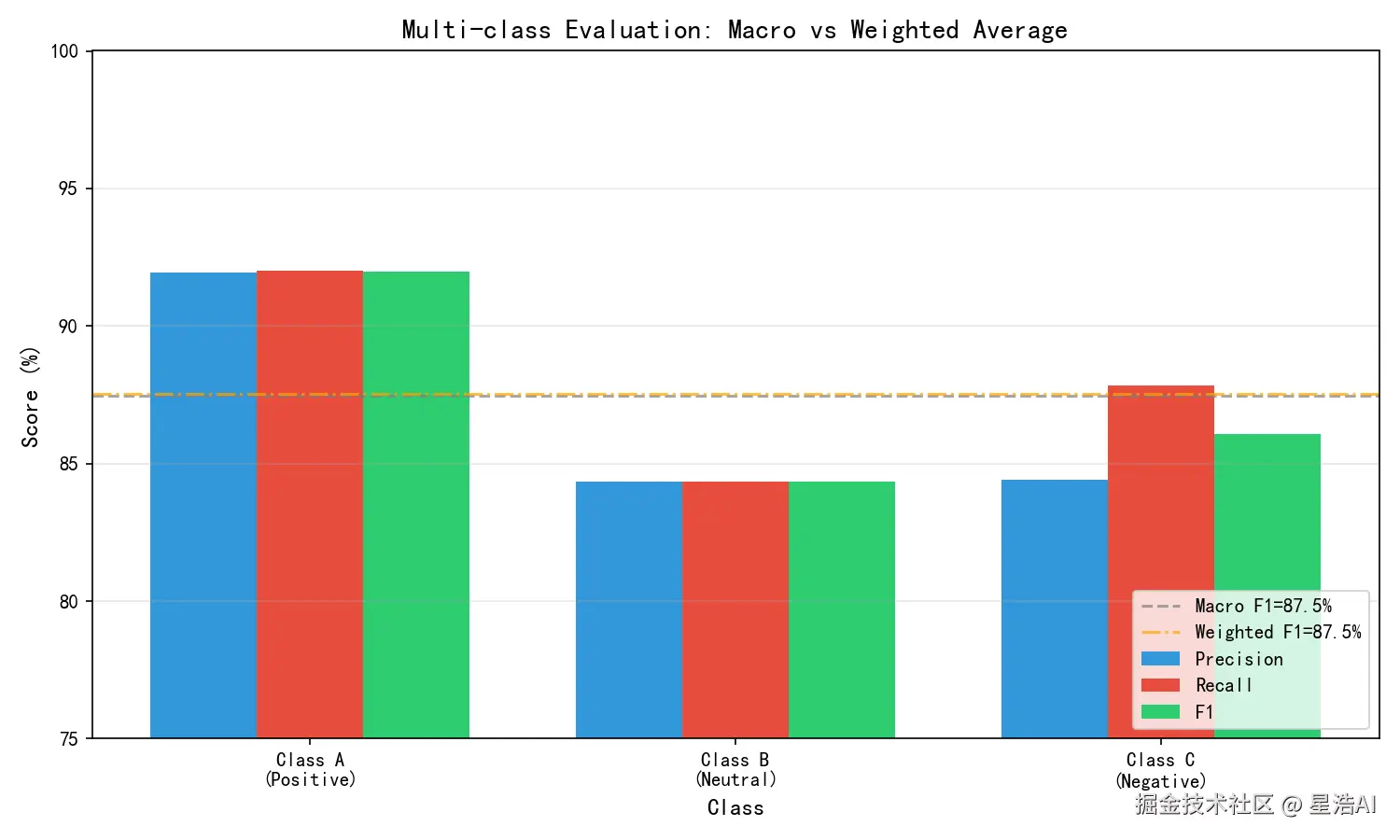
类别 A (把 A 当正类):
P = 80/(80+3+1) ≈ 91.95% ,R = 80/(80+5+2) ≈ 92.00% ,F1 ≈ 91.97%,support = 87
类别 B :
P = 70/(5+70+8) ≈ 84.34% ,R = 70/(3+70+10) ≈ 84.34% ,F1 ≈ 84.34%,support = 83
类别 C :
P = 65/(2+10+65) ≈ 84.42% ,R = 65/(1+8+65) ≈ 87.84% ,F1 ≈ 86.08%,support = 74
宏平均 (各类同等权重):
精确率 ≈ (91.95% + 84.34% + 84.42%) / 3 ≈ 86.90%
召回率 ≈ (92.00% + 84.34% + 87.84%) / 3 ≈ 88.06%
F1 ≈ (91.97% + 84.34% + 86.08%) / 3 ≈ 87.46%
加权平均 (按 support 加权):
F1 ≈ (91.97%×87 + 84.34%×83 + 86.08%×74) / 244 ≈ 87.54%
微平均 :
全局 TP = 80+70+65 = 215,总样本 244 → 整体准确率 ≈ 88.11%;微平均下 P、R 相等,F1 与之相同。
与二分类相比,多分类多了一层「按类拆解 → 再聚合 」;classification_report(..., average=None) 会自动给出每类一行及 macro / weighted 汇总。
5.5 多分类评估代码示例
python
from sklearn.metrics import precision_recall_fscore_support, classification_report
class_names = ["好评", "中评", "差评"] # K=3
# 宏平均 / 加权平均 / 微平均
for avg in ["macro", "weighted", "micro"]:
p, r, f1, _ = precision_recall_fscore_support(
all_labels, all_preds, average=avg
)
print(f"{avg}: P={p:.4f}, R={r:.4f}, F1={f1:.4f}")
# 每个类别明细 + macro / weighted 行
print(classification_report(all_labels, all_preds, target_names=class_names, digits=4))训练侧只需将 DL5 中 self.fc = torch.nn.Linear(768, 2) 改为 Linear(768, 3),标签改为 0/1/2,其余流程不变。
6. 常见问题
Q1:为什么有人说分类数据最好 1:1?
分类本质上在估计各类别的条件概率;严重不平衡 时,模型容易「全猜大类」,准确率虚高但小类全废。ChnSentiCorp 相对均衡;若业务数据极不平衡,应优先 重采样 / 类别权重 / 看 F1 与各类召回,而不是只追准确率。
Q2:验证集 acc 很高,测试集掉很多怎么办?
常见原因:过拟合、验证集与测试分布不一致、或验证集上偶然选到「幸运」epoch。应对:加强正则、早停、换 best 选择依据(如验证集 F1 而非 acc),并在测试集上做一次最终确认。
Q3:训练 acc 和测试 acc 差多少算正常?
没有固定数字,取决于数据量、任务难度和是否过拟合。一般以测试集报告为准对外验收;训练集指标仅作调试参考。
7. 小结
- 本章把「微调后怎么验收」完整走通:测试集评估 + 分类报告 + 混淆矩阵。
- 第 3 章看客观指标,第 4 章做主观抽检,两者结合更接近真实业务验收。
- 业务扩展到多分类时,核心改动是输出层维度、标签体系和评估聚合策略(macro / weighted / micro)。
需要本章配套源码和数据集的同学,可以点赞 + 关注,我会把完整工程发给你。