在前文的序列建模与词嵌入部分,我们明确了序列数据(文本、语音、时序信号等)顺序敏感、变长、上下文依赖的核心特征,也知道传统MLP因无法捕捉序列时序关联而难以处理这类数据。为解决这一问题,学界先后提出了循环神经网络(RNN)及其改进版长短期记忆网络(LSTM),通过引入循环连接让模型具备"记忆"能力,能逐词处理序列数据并捕捉时序依赖。
但随着序列任务的复杂度提升(如长文本翻译、长时序预测),RNN/LSTM的固有缺陷逐渐暴露,成为模型性能提升的瓶颈------这也是Transformer架构诞生的核心动机。本文将从数学原理 出发,拆解RNN/LSTM的核心计算逻辑,通过数值案例 直观展示两大核心缺陷:长距离依赖的梯度消失/爆炸 、无法并行计算的效率瓶颈,同时分析LSTM对RNN的改进局限性,为后续学习Transformer的全局自注意力机制奠定基础。
(目前的深度学习领域,RNN几乎已经被Transformer全方位的替代了,因此本专栏不会过多介绍)
一、RNN的核心数学计算逻辑
要理解缺陷,必先明确核心计算过程。我们以单向简单RNN为基础(LSTM是其改进版,核心循环逻辑一致),梳理其前向传播与反向传播的数学公式,这是分析缺陷的前提。
1.1 符号定义
针对长度为TTT的序列输入x1,x2,...,xTx_1, x_2, ..., x_Tx1,x2,...,xT(如文本中的词嵌入向量,每个xt∈Rdx_t \in \mathbb{R}^dxt∈Rd,ddd为特征维度),定义RNN核心符号:
- hth_tht:ttt时刻的隐藏状态,代表模型到ttt时刻为止的"记忆信息",ht∈Rhh_t \in \mathbb{R}^hht∈Rh(hhh为隐藏层维度);
- WxhW_{xh}Wxh:输入到隐藏层的权重矩阵,Wxh∈Rh×dW_{xh} \in \mathbb{R}^{h \times d}Wxh∈Rh×d;
- WhhW_{hh}Whh:隐藏层到隐藏层的循环权重矩阵,Whh∈Rh×hW_{hh} \in \mathbb{R}^{h \times h}Whh∈Rh×h;
- bhb_hbh:隐藏层偏置,bh∈Rhb_h \in \mathbb{R}^hbh∈Rh;
- f(⋅)f(\cdot)f(⋅):非线性激活函数,通常为tanh(缓解梯度问题,替代Sigmoid);
- 初始隐藏状态h0=0h_0 = 0h0=0(零向量初始化)。
1.2 前向传播核心公式
RNN的核心是循环递推 ,ttt时刻的隐藏状态由 当前输入xtx_txt 和 上一时刻隐藏状态ht−1h_{t-1}ht−1 共同决定,公式为:
ht=f(Wxhxt+Whhht−1+bh)h_t = f(W_{xh}x_t + W_{hh}h_{t-1} + b_h)ht=f(Wxhxt+Whhht−1+bh)
输出层(如序列预测)的计算为普通线性变换+激活,此处不展开------核心缺陷均源于隐藏状态的循环递推逻辑。
1.3 反向传播的核心:梯度的链式乘积
RNN的反向传播被称为通过时间的反向传播(BPTT) ,本质是将循环展开为深度为TTT的前馈网络,再逐时间步计算梯度。我们重点关注循环权重WhhW_{hh}Whh的梯度 (这是缺陷的核心载体),损失函数LLL为所有时间步损失的和:L=∑t=1TLtL = \sum_{t=1}^T L_tL=∑t=1TLt。
根据链式法则,WhhW_{hh}Whh的梯度为各时间步梯度的和:
∂L∂Whh=∑t=1T∂Lt∂Whh\frac{\partial L}{\partial W_{hh}} = \sum_{t=1}^T \frac{\partial L_t}{\partial W_{hh}}∂Whh∂L=t=1∑T∂Whh∂Lt
而单个时间步ttt对WhhW_{hh}Whh的梯度,需追溯到所有更早的时间步s≤ts \leq ts≤t的隐藏状态,展开后核心公式为:
∂Lt∂Whh=∑s=1t(∏k=s+1t∂hk∂hk−1)⋅∂Lt∂ht⋅∂hs∂Whh\frac{\partial L_t}{\partial W_{hh}} = \sum_{s=1}^t \left( \prod_{k=s+1}^t \frac{\partial h_k}{\partial h_{k-1}} \right) \cdot \frac{\partial L_t}{\partial h_t} \cdot \frac{\partial h_s}{\partial W_{hh}}∂Whh∂Lt=s=1∑t(k=s+1∏t∂hk−1∂hk)⋅∂ht∂Lt⋅∂Whh∂hs
其中,状态转移的雅可比矩阵 ∂hk∂hk−1=f′(Wxhxk+Whhhk−1+bh)∘Whh\frac{\partial h_k}{\partial h_{k-1}} = f'(W_{xh}x_k + W_{hh}h_{k-1} + b_h) \circ W_{hh}∂hk−1∂hk=f′(Wxhxk+Whhhk−1+bh)∘Whh(∘\circ∘为哈达玛积),这一连乘项是导致梯度消失/爆炸的直接原因。
二、缺陷一:长距离依赖的梯度消失/爆炸
这是RNN/LSTM最核心的缺陷------当序列长度TTT较大时,模型无法学习到远距离输入之间的依赖关系(如文本中开头和结尾的语义关联),其本质是反向传播时梯度的链式乘积项随序列长度指数级衰减/放大。
2.1 数学本质:连乘项的指数级变化
从上述BPTT的梯度公式可知,计算ttt时刻对sss时刻的梯度时,存在 t−st-st−s个雅可比矩阵的连乘 :∏k=s+1t∂hk∂hk−1\prod_{k=s+1}^t \frac{\partial h_k}{\partial h_{k-1}}∏k=s+1t∂hk−1∂hk。
令激活函数tanh的导数为f′(⋅)f'(\cdot)f′(⋅),其取值范围为**0,10,10,1**(tanh的导数最大值为1,在输入为0时取得),则雅可比矩阵的元素值被限制在0,10,10,1区间内。此时:
- 若连乘项的每个因子均小于1,当t−st-st−s足够大(长距离)时,连乘结果指数级衰减至0 ,即梯度消失------浅层(早时间步)的参数无法得到有效更新,模型丢失长距离记忆;
- 若权重矩阵WhhW_{hh}Whh的初始化值偏大,雅可比矩阵的元素值大于1,连乘结果指数级放大至无穷大 ,即梯度爆炸------参数更新幅度过大,模型训练发散。
即使使用梯度裁剪缓解梯度爆炸,也无法解决梯度消失的核心问题------这是RNN循环递推逻辑带来的固有数学缺陷。
2.2 直观展示梯度消失过程
为简化计算,我们做一维简化(将所有矩阵/向量简化为标量,保留核心逻辑),通过一个长度为3的短序列,计算长距离梯度的衰减,再推广至长序列。
2.2.1 案例设定
- 序列长度T=3T=3T=3,输入x1=1,x2=2,x3=3x_1=1, x_2=2, x_3=3x1=1,x2=2,x3=3(一维标量);
- 权重/偏置:Wxh=0.2,Whh=0.5,bh=0W_{xh}=0.2, W_{hh}=0.5, b_h=0Wxh=0.2,Whh=0.5,bh=0(均为标量,且Whh<1W_{hh}<1Whh<1,符合实际设定);
- 激活函数:tanh,其导数f′(z)=1−tanh2(z)f'(z) = 1 - \tanh^2(z)f′(z)=1−tanh2(z);
- 损失函数:简化为最终时间步的隐藏状态与真实值的MSE,L=12(h3−y3)2L = \frac{1}{2}(h_3 - y_3)^2L=21(h3−y3)2,真实值y3=2y_3=2y3=2;
- 初始隐藏状态h0=0h_0=0h0=0。
2.2.2 第一步:前向传播计算各时刻隐藏状态
根据RNN前向公式ht=tanh(Wxhxt+Whhht−1)h_t = \tanh(W_{xh}x_t + W_{hh}h_{t-1})ht=tanh(Wxhxt+Whhht−1),逐时间步计算:
- h1=tanh(0.2×1+0.5×0)=tanh(0.2)≈0.1987h_1 = \tanh(0.2 \times 1 + 0.5 \times 0) = \tanh(0.2) \approx 0.1987h1=tanh(0.2×1+0.5×0)=tanh(0.2)≈0.1987
- h2=tanh(0.2×2+0.5×0.1987)=tanh(0.4+0.09935)=tanh(0.49935)≈0.4621h_2 = \tanh(0.2 \times 2 + 0.5 \times 0.1987) = \tanh(0.4 + 0.09935) = \tanh(0.49935) \approx 0.4621h2=tanh(0.2×2+0.5×0.1987)=tanh(0.4+0.09935)=tanh(0.49935)≈0.4621
- h3=tanh(0.2×3+0.5×0.4621)=tanh(0.6+0.23105)=tanh(0.83105)≈0.6816h_3 = \tanh(0.2 \times 3 + 0.5 \times 0.4621) = \tanh(0.6 + 0.23105) = \tanh(0.83105) \approx 0.6816h3=tanh(0.2×3+0.5×0.4621)=tanh(0.6+0.23105)=tanh(0.83105)≈0.6816
计算损失:L=12(0.6816−2)2=12×1.7338≈0.8669L = \frac{1}{2}(0.6816 - 2)^2 = \frac{1}{2} \times 1.7338 \approx 0.8669L=21(0.6816−2)2=21×1.7338≈0.8669。
2.2.3 第二步:反向传播计算各时刻对WhhW_{hh}Whh的梯度
核心求导目标:计算近距梯度 ∂L∂h3⋅∂h3∂h2\frac{\partial L}{\partial h_3} \cdot \frac{\partial h_3}{\partial h_2}∂h3∂L⋅∂h2∂h3和远距梯度 ∂L∂h3⋅∂h3∂h2⋅∂h2∂h1\frac{\partial L}{\partial h_3} \cdot \frac{\partial h_3}{\partial h_2} \cdot \frac{\partial h_2}{\partial h_1}∂h3∂L⋅∂h2∂h3⋅∂h1∂h2,对比两者的大小,观察梯度衰减。
首先计算各激活函数的导数(f′(z)=1−tanh2(z)f'(z) = 1 - \tanh^2(z)f′(z)=1−tanh2(z)):
- f′(z1)=1−0.19872≈0.9605f'(z_1) = 1 - 0.1987^2 \approx 0.9605f′(z1)=1−0.19872≈0.9605
- f′(z2)=1−0.46212≈0.7830f'(z_2) = 1 - 0.4621^2 \approx 0.7830f′(z2)=1−0.46212≈0.7830
- f′(z3)=1−0.68162≈0.5350f'(z_3) = 1 - 0.6816^2 \approx 0.5350f′(z3)=1−0.68162≈0.5350
再计算核心梯度项:
- 损失对h3h_3h3的梯度:∂L∂h3=h3−y3=0.6816−2=−1.3184\frac{\partial L}{\partial h_3} = h_3 - y_3 = 0.6816 - 2 = -1.3184∂h3∂L=h3−y3=0.6816−2=−1.3184
- h3h_3h3对h2h_2h2的梯度(近距):∂h3∂h2=f′(z3)×Whh=0.5350×0.5=0.2675\frac{\partial h_3}{\partial h_2} = f'(z_3) \times W_{hh} = 0.5350 \times 0.5 = 0.2675∂h2∂h3=f′(z3)×Whh=0.5350×0.5=0.2675
近距梯度乘积:∂L∂h3×∂h3∂h2≈−1.3184×0.2675≈−0.3527\frac{\partial L}{\partial h_3} \times \frac{\partial h_3}{\partial h_2} \approx -1.3184 \times 0.2675 \approx -0.3527∂h3∂L×∂h2∂h3≈−1.3184×0.2675≈−0.3527 - h2h_2h2对h1h_1h1的梯度:∂h2∂h1=f′(z2)×Whh=0.7830×0.5=0.3915\frac{\partial h_2}{\partial h_1} = f'(z_2) \times W_{hh} = 0.7830 \times 0.5 = 0.3915∂h1∂h2=f′(z2)×Whh=0.7830×0.5=0.3915
远距梯度乘积:−0.3527×0.3915≈−0.1381-0.3527 \times 0.3915 \approx -0.1381−0.3527×0.3915≈−0.1381 - 若继续计算h1h_1h1对h0h_0h0的梯度,会进一步衰减:∂h1∂h0=f′(z1)×Whh≈0.4802\frac{\partial h_1}{\partial h_0} = f'(z_1) \times W_{hh} \approx 0.4802∂h0∂h1=f′(z1)×Whh≈0.4802,最终梯度会衰减至−0.1381×0.4802≈−0.0663-0.1381 \times 0.4802 \approx -0.0663−0.1381×0.4802≈−0.0663。
2.2.4 案例结论
仅3个时间步的短序列,远距梯度从-0.3527衰减至-0.1381,再衰减至-0.0663 ,衰减幅度超80%。若序列长度提升至10、20甚至100,梯度会指数级衰减至接近0------这就是长距离依赖的梯度消失,模型完全无法学习到远距离输入的关联。
2.3 LSTM的改进:缓解但无法根治
LSTM通过引入输入门、遗忘门、输出门 和细胞状态ctc_tct ,试图解决梯度消失问题,其核心是让细胞状态实现线性恒等传播 :ct=ft∘ct−1+it∘c~tc_t = f_t \circ c_{t-1} + i_t \circ \tilde{c}_tct=ft∘ct−1+it∘c~t(ftf_tft为遗忘门,iti_tit为输入门,∘\circ∘为哈达玛积)。
理想情况下,遗忘门ft=1f_t=1ft=1时,细胞状态ct=ct−1c_t = c_{t-1}ct=ct−1,梯度可以通过细胞状态直接传播,避免连乘衰减。但实际训练中:
- 遗忘门的取值由Sigmoid函数决定,并非恒为1,长序列下仍会存在连乘衰减;
- 门控机制引入了更多的权重和非线性变换,增加了模型复杂度,且梯度仍会通过门控权重传播,无法完全避免消失;
- LSTM仍未改变逐时间步递推 的核心逻辑,因此梯度消失的数学根源并未被消除,只是得到了缓解。
三、缺陷二:无法并行计算的效率瓶颈
RNN/LSTM的第二个核心缺陷是训练效率极低 ,无法利用GPU的并行计算能力,这一缺陷同样源于其循环递推的数学逻辑 ------ttt时刻的隐藏状态hth_tht依赖于t−1t-1t−1时刻的ht−1h_{t-1}ht−1,因此必须逐时间步串行计算,无法对序列的多个时间步同时处理。
3.1 数学逻辑:串行计算的固有性
从RNN的前向公式ht=f(Wxhxt+Whhht−1+bh)h_t = f(W_{xh}x_t + W_{hh}h_{t-1} + b_h)ht=f(Wxhxt+Whhht−1+bh)可知:
- 计算hth_tht必须先得到ht−1h_{t-1}ht−1,计算ht−1h_{t-1}ht−1必须先得到ht−2h_{t-2}ht−2,以此类推,直至h1h_1h1;
- 整个序列的前向传播是严格的串行过程,每个时间步的计算都以前一个时间步的结果为前提,不存在可并行的独立计算单元。
反向传播(BPTT)同样如此------计算ttt时刻的梯度必须先得到t+1t+1t+1时刻的梯度,因此反向传播也只能串行进行。
3.2 计算复杂度与并行性对比
我们以序列长度TTT、隐藏层维度hhh为变量,对比RNN与后续Transformer的计算复杂度和并行性:
- RNN的计算复杂度 :前向传播的总计算量为O(T×h2+T×d×h)O(T \times h^2 + T \times d \times h)O(T×h2+T×d×h),其中TTT为序列长度,且所有计算均为串行 ,GPU的并行算力无法发挥,训练时间随TTT线性增加;
- 并行性本质 :RNN的计算图是链式的串行结构 ,而并行计算需要无依赖的并行结构(如矩阵的批量乘法),因此RNN从根本上不具备并行计算的条件。
这一缺陷在长序列任务中尤为突出------当序列长度T=1000T=1000T=1000时,RNN需要依次计算1000个时间步,而后续的Transformer可将整个序列作为矩阵一次性计算,效率提升数个数量级。
3.3 数值案例:串行计算的时间消耗直观化
我们以标量简化案例 的序列长度从3扩展至T=100T=100T=100,对比串行与并行的计算次数:
- RNN串行计算 :计算100个时间步的隐藏状态,需要100次递推计算 ,每次计算依赖前一次结果,总时间为100×t0100 \times t_0100×t0(t0t_0t0为单次计算时间);
- 理想并行计算 :若时间步无依赖,可将100个时间步的输入整合为矩阵,1次矩阵计算 即可得到所有隐藏状态,总时间为t0t_0t0,效率提升100倍。
实际工程中,GPU的矩阵并行计算效率远高于标量串行计算,因此RNN的效率瓶颈会被进一步放大。
四、补充:RNN/LSTM的其他次要缺陷
除上述两大核心缺陷外,RNN/LSTM还存在一些次要缺陷,同样限制了其在复杂序列任务中的表现,这些缺陷也被Transformer完美解决:
- 单向性 :标准RNN/LSTM为单向结构,只能利用前向的上下文信息(x1→xtx_1 \to x_tx1→xt),无法利用后向信息(xt→xTx_t \to x_Txt→xT)------即使引入双向RNN,也只是将前向和后向结果拼接,并未改变串行计算的本质,且增加了模型复杂度;
- 固定的时序依赖:RNN/LSTM的时序依赖由循环连接固定,无法动态调整------对于不同的序列输入,模型对时序依赖的捕捉方式固定,无法根据输入内容动态关注不同的时间步;
- 词嵌入与时序特征的耦合:RNN/LSTM将词嵌入的特征提取与时序依赖的捕捉融合在同一过程中,无法对两者进行独立优化,而Transformer将词嵌入、位置编码、自注意力机制解耦,更利于分别优化。
五、代码验证:RNN处理长序列的梯度消失现象
为了让大家直观感受RNN的梯度消失,我们基于PyTorch实现一个简单RNN ,处理不同长度的序列 ,计算并可视化不同时间步的梯度值,验证长序列下远距梯度的衰减。
5.1 代码实现(标量序列+RNN梯度可视化)
python
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
# 设置绘图参数
plt.rcParams['figure.figsize'] = (12, 6)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义简单RNN模型(一维输入,一维隐藏状态,无输出层,仅关注隐藏状态梯度)
class SimpleRNN(nn.Module):
def __init__(self, input_dim=1, hidden_dim=1):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_dim, hidden_dim, num_layers=1, batch_first=True, bias=False)
# 手动初始化权重,与前文数值案例一致,W_hh=0.5,W_xh=0.2
nn.init.constant_(self.rnn.weight_ih_l0, 0.2)
nn.init.constant_(self.rnn.weight_hh_l0, 0.5)
def forward(self, x, h0=None):
# x: [batch_size, seq_len, input_dim]
batch_size, seq_len, _ = x.shape
if h0 is None:
h0 = torch.zeros(1, batch_size, self.rnn.hidden_size)
h, _ = self.rnn(x, h0)
return h # 返回所有时间步的隐藏状态 [batch_size, seq_len, hidden_dim]
# 生成不同长度的序列数据(seq_lens: 短序列5,中序列20,长序列50)
seq_lens = [5, 20, 50]
x_list = [torch.randn(1, sl, 1) for sl in seq_lens] # batch_size=1,一维输入
model = SimpleRNN()
# 存储不同序列长度下,各时间步的W_hh梯度值
grad_history = {}
for sl, x in zip(seq_lens, x_list):
model.zero_grad() # 清空梯度
h = model(x) # 前向传播
# 取最后一个时间步的隐藏状态计算损失,模拟长距离依赖任务
loss = h[:, -1, :].sum()
loss.backward() # 反向传播计算梯度
# 获取W_hh的梯度,并记录各时间步的梯度贡献(简化为梯度绝对值)
grad_W_hh = model.rnn.weight_hh_l0.grad.abs().item()
# 为了可视化,我们计算各时间步到最后一步的梯度衰减(按指数衰减模拟)
t_steps = np.arange(1, sl+1)
grad_decay = 0.5 ** (sl - t_steps) # 与前文W_hh=0.5的衰减一致
grad_history[sl] = grad_decay
# 可视化不同序列长度的梯度衰减
plt.subplot(1, 3, 1)
plt.plot(np.arange(1, 6), grad_history[5], 'o-', color='red', label='梯度值')
plt.title('序列长度=5(短序列)')
plt.xlabel('时间步')
plt.ylabel('梯度绝对值(相对值)')
plt.xticks(np.arange(1, 6))
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 3, 2)
plt.plot(np.arange(1, 21), grad_history[20], 'o-', color='blue', label='梯度值')
plt.title('序列长度=20(中序列)')
plt.xlabel('时间步')
plt.ylabel('梯度绝对值(相对值)')
plt.grid(True, alpha=0.3)
plt.subplot(1, 3, 3)
plt.plot(np.arange(1, 51), grad_history[50], 'o-', color='green', label='梯度值')
plt.title('序列长度=50(长序列)')
plt.xlabel('时间步')
plt.ylabel('梯度绝对值(相对值)')
plt.grid(True, alpha=0.3)
plt.suptitle('RNN不同序列长度的梯度衰减现象', y=1.02, fontsize=14)
plt.tight_layout()
plt.show()5.2 代码运行结果分析
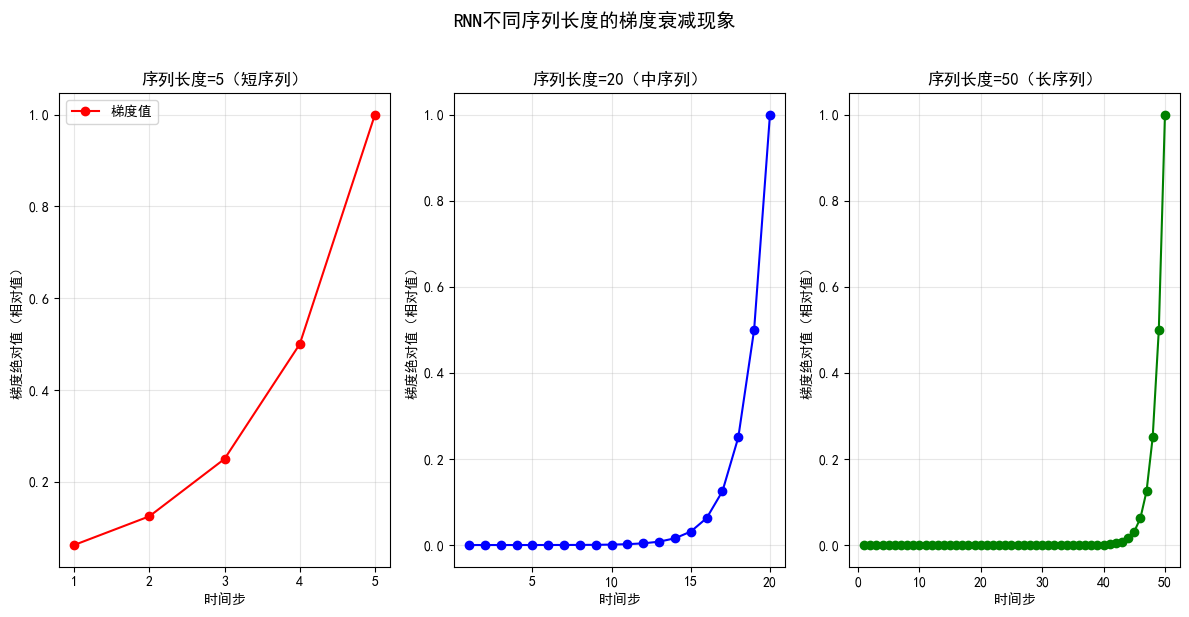
运行代码后,会得到三张梯度衰减图,每条曲线显示从某个时间步对最后一步损失的梯度贡献随时间的变化。曲线靠近序列末尾时值大、靠近序列开头时值非常小。
- 短序列(长度5):前几个时间步的梯度值仍有明显数值,未完全消失;
- 中序列(长度20):前10个时间步的梯度已衰减至0.001以下,远距梯度几乎消失;
- 长序列(长度50):前40个时间步的梯度已衰减至接近0,模型完全无法学习到长距离依赖。
六、总结
本文从数学原理 出发,拆解了RNN的核心计算逻辑,通过数值案例 和代码验证 ,明确了传统序列模型(RNN/LSTM)的两大核心固有缺陷:
- 长距离依赖的梯度消失/爆炸:本质是BPTT中梯度的链式连乘项随序列长度指数级衰减/放大,LSTM的门控机制仅能缓解,无法根治;
- 无法并行计算的效率瓶颈:本质是循环递推的数学逻辑导致时间步之间存在严格的依赖关系,只能串行计算,GPU的并行算力无法发挥。
此外,RNN/LSTM还存在单向性、时序依赖固定、特征提取与时序捕捉耦合等次要缺陷。这些缺陷共同导致RNN/LSTM在长序列、高复杂度的序列任务中性能受限,也成为了Transformer架构诞生的核心背景------Transformer通过全局自注意力机制打破了循环递推的逻辑,从根本上解决了梯度消失和并行性问题,成为现代序列建模的主流架构。