sigmoid 和 softmax 到底在做什么?为什么输出层需要它们?
在分类模型中,输入经过前面的计算之后,最后并不会天然地变成"这是 3"或者"这是猫"这样的最终答案。更常见的情况是,模型先得到一组原始数值,再由输出层把这些数值转换成更适合分类任务使用的结果。
很多人第一次接触 sigmoid 和 softmax 时,通常会记住一句话:二分类常用 sigmoid,多分类常用 softmax。这个结论本身没有问题,但如果只停留在这个层面,后面一遇到输出层、损失函数和训练过程,就很容易只会套公式,不知道它们为什么会出现在这里。
真正值得先想清楚的是:模型为什么不能直接输出类别,而要先输出一组分数,再交给 sigmoid 或 softmax 处理?
原因在于,分类任务中的类别编号本质上只是标签,不是可以直接优化的连续数值。比如数字分类里的 0、1、2、3、4,并不表示类别之间存在真实的大小关系。真实标签是 3 时,预测成 2 和预测成 8,从分类角度看都只是预测错误,并不能简单理解成"2 比 8 更接近 3,所以错得更少"。如果模型直接输出类别编号,就很难表达每个类别各自有多大可能性,也不方便进一步和真实标签比较,更无法自然地进入训练过程。
因此,分类模型通常不会直接输出最终类别,而是先输出一组原始分数。输出层的作用,就是把这些原始分数整理成更容易解释、更方便比较、也更适合训练的形式。这正是 sigmoid 和 softmax 要解决的问题。
1. 模型最后输出的,为什么常常不是"答案"?
先看一个简单例子。假设一个三分类模型对某个样本输出了下面这组值:
python
[2.1, 0.3, -1.2]如果只看大小,第一个类别显然更有优势,因为它的分数最高。
但这组数值本身仍然存在明显的问题:
- 它们可能是负数
- 它们不一定落在 0 到 1 之间
- 它们加起来也不等于 1
这意味着,这些值虽然能够表示"谁更大",却不适合直接当成概率来理解。
而在分类任务里,更自然的表达方式通常是:
- 第 0 类概率 81%
- 第 1 类概率 13%
- 第 2 类概率 6%
这样不仅更容易看懂,也更方便后续和真实标签比较。
sigmoid 和 softmax 的作用,本质上就是把模型的原始输出转换成更适合分类问题使用的形式。
2. softmax 在分类模型中的位置
在完整的分类流程里,softmax 并不是整个模型本身,而是位于输出层后面的一步处理。模型前面的部分先完成前向计算,得到一组原始分数(logits),softmax 再把这组分数转换成概率分布,最后根据最大概率得到预测类别。
输入样本 x
模型前向计算
logits
数字0: 2.1
数字1: 0.3
数字2: -1.2
Softmax
概率分布
数字0: 81.66%
数字1: 13.49%
数字2: 4.85%
选择最大概率
预测结果: 数字0
图 1: softmax 在分类模型中的位置。模型先输出一组原始分数(logits),softmax 再把这组分数转换成概率分布,最后根据最大概率得到预测类别。
这张图有助于说明一个容易混淆的点:
softmax 不是替代整个模型做分类,而是把模型前面已经算出来的结果,整理成更适合解释和比较的形式。
3. sigmoid 在做什么?
sigmoid 的核心作用,可以概括为一句话:
把一个原本可能很大、很小,甚至为负数的值,压缩到 0 到 1 之间。
它的公式是:
\\sigma(x) = \\frac{1}{1 + e\^{-x}}
这个公式的行为有几个很明显的特点:
- 当输入很大时,输出接近 1
- 当输入很小时( 不是接近0的意思,是负无穷大),输出接近 0
- 当输入等于 0 时,输出正好是 0.5
也就是说,sigmoid 会把一个原始分数转换成一个更接近"发生概率"的值。
看下面这段最小代码:
python
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
inputs = np.array([-5, -1, 0, 1, 5])
outputs = sigmoid(inputs)
for x, y in zip(inputs, outputs):
print(f"输入: {x}, sigmoid输出: {y:.4f}")输出:
log
输入: -5, sigmoid输出: 0.0067
输入: -1, sigmoid输出: 0.2689
输入: 0, sigmoid输出: 0.5000
输入: 1, sigmoid输出: 0.7311
输入: 5, sigmoid输出: 0.9933从结果可以直接看出:
- 输入越大,输出越接近 1
- 输入越小,输出越接近 0
- 输入在 0 附近时,输出变化最明显
sigmoid 最适合处理的是"是或不是"这种问题。
例如:
- 这是不是垃圾邮件?
- 这是不是猫?
- 这个用户会不会点击?
这类任务最终只关心一个类别是否成立,因此只需要输出一个值,再把它压到 0 到 1 之间,就可以把它解释成"属于正类的可能性"。
4. sigmoid 的函数图像
sigmoid 的图像是一条非常典型的 S 形曲线。它最直观地展示了一个特点:输入可以在整个实数范围内变化,但输出始终被限制在 0 到 1 之间。这也是它特别适合二分类任务的原因。
python
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.linspace(-10, 10, 500)
y = sigmoid(x)
plt.figure(figsize=(8, 5))
plt.plot(x, y, label="sigmoid(x)", color="royalblue")
plt.axhline(0.5, color="gray", linestyle="--", linewidth=1)
plt.axvline(0, color="gray", linestyle="--", linewidth=1)
plt.scatter([0], [0.5], color="red", zorder=5)
plt.title("Sigmoid 函数图像")
plt.xlabel("输入 x")
plt.ylabel("输出 sigmoid(x)")
plt.legend()
plt.grid(alpha=0.3)
plt.show()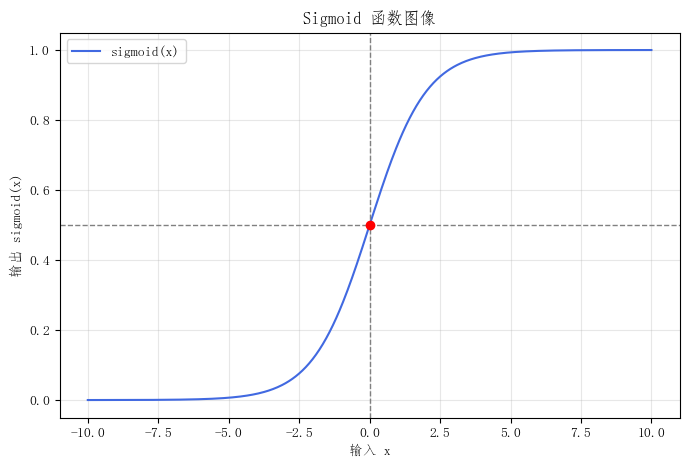
图 2: sigmoid 函数图像。输入越大,输出越接近 1;输入越小,输出越接近 0;当输入为 0 时,输出正好是 0.5。
从这张图可以看出三个很重要的直觉:
4.1 输出范围固定
不管输入有多大或多小,输出始终落在 0 到 1 之间。
4.2 中间区域更敏感
输入在 0 附近变化时,输出变化最快;两端则逐渐变平。
4.3 更像"倾向度转换器"
原始分数越大,模型越倾向于认为样本属于正类;原始分数越小,模型越倾向于认为样本不属于正类。
因此,sigmoid 并不是简单地"把数压缩一下",而是在把原始打分转换成更适合二分类任务解释的结果。
5. softmax 在做什么?
如果任务从二分类变成多分类,sigmoid 就不够用了。
例如在手写数字识别中,模型不是只回答"这是不是 3",而是要在 0 到 9 这十个类别中选一个最可能的结果。
这时候,问题不再是"某一个类别像不像",而是"所有类别里谁最像"。
softmax 的作用,就是把一整组原始分数变成一整组概率,并满足两个条件:
- 每个值都在 0 到 1 之间
- 所有值加起来等于 1
它的公式是:
\\text{softmax}(x_i) = \\frac{e\^{x_i}}{\\sum_j e\^{x_j}}
这个公式最关键的特点是:
它不是独立处理某一个值,而是把整组输出一起处理。
这意味着,一个类别的概率不仅取决于它自己的分数,也取决于其他类别的分数。
某个类别分数越高,它分到的概率就越大;与此同时,其他类别的概率会相应减小。
下面看一个最小例子:
python
import numpy as np
def softmax(x):
exp_x = np.exp(x)
return exp_x / np.sum(exp_x)
scores = np.array([2.1, 0.3, -1.2])
probs = softmax(scores)
print("原始分数:", scores)
print("softmax输出:", probs)
print("概率和:", np.sum(probs))输出:
log
原始分数: [ 2.1 0.3 -1.2]
softmax输出: [0.8166 0.1349 0.0485]
概率和: 1.0这时结果就非常容易理解了:
- 第一个类别概率最高
- 第二个类别次之
- 第三个类别最小
- 所有类别加起来正好是 1
这说明 softmax 的真正作用,不只是"压缩范围",而是把一组原始分数整理成一个标准的概率分布。
6. softmax 的概率变化图
和 sigmoid 不同,softmax 不是处理单个值,而是处理一整组分数。因此它没有一条像 sigmoid 那样固定的单变量函数曲线。更合理的可视化方式,是固定其他类别分数,只让某一个类别的分数变化,观察它对应的概率如何变化。
下面这段代码中,固定三个类别分数为 [x, 1, 0],只让第一个类别的分数 x 从 -5 变化到 5,观察三个类别对应的 softmax 概率如何变化。
python
import numpy as np
import matplotlib.pyplot as plt
def softmax(z):
exp_z = np.exp(z - np.max(z))
return exp_z / np.sum(exp_z)
x_values = np.linspace(-5, 5, 300)
p1, p2, p3 = [], [], []
for x in x_values:
scores = np.array([x, 1.0, 0.0])
probs = softmax(scores)
p1.append(probs[0])
p2.append(probs[1])
p3.append(probs[2])
plt.figure(figsize=(8, 5))
plt.plot(x_values, p1, label="类别1 概率", color="royalblue")
plt.plot(x_values, p2, label="类别2 概率", color="tomato")
plt.plot(x_values, p3, label="类别3 概率", color="seagreen")
plt.title("Softmax 下各类别概率的变化")
plt.xlabel("类别1的原始分数 x")
plt.ylabel("概率")
plt.legend()
plt.grid(alpha=0.3)
plt.show()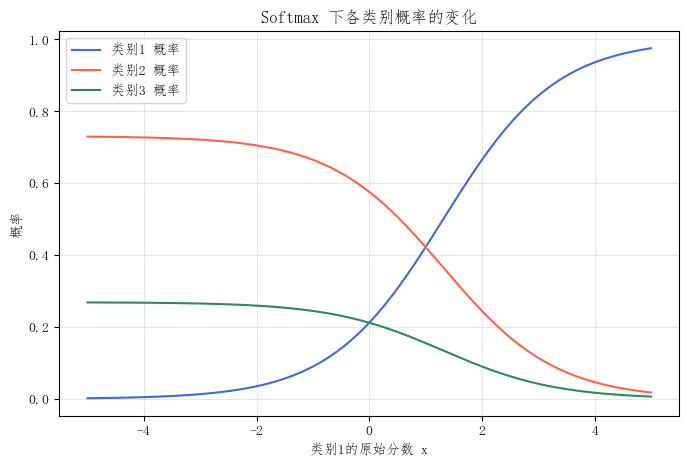
图 3: softmax 下各类别概率的变化。固定其他类别分数不变,只让某一个类别的分数变化,可以看到该类别分数上升时,它自己的概率会上升,而其他类别的概率会被压缩。
这张图很好地展示了 softmax 的本质:
6.1 类别之间存在竞争关系
一个类别概率上升时,其他类别概率会相应下降。
6.2 输出是整体性的
softmax 处理的不是一个值,而是一整组值,因此每个类别的结果都和其他类别有关。
6.3 适合单标签多分类
在数字识别、图像分类这类任务中,样本最终只能属于一个类别,因此这种"总和为 1 的竞争分配"非常自然。
7. 为什么 softmax 更适合多分类?
多分类任务和二分类的最大区别在于:
类别之间通常是互斥的。
例如手写数字识别里,一张图片不可能同时既是 3,又是 8。
它最终只能属于一个类别。
这时候需要的不是"每个类别各自像不像",而是"所有类别一起比较之后,哪个类别最像"。
softmax 正好满足这个要求:
- 所有类别共同参与比较
- 概率总和固定为 1
- 某个类别概率增大时,其他类别概率会相应减小
这种机制特别适合单标签多分类任务。
因为它天然体现了"多个候选类别竞争同一个最终结果"的特点。
8. sigmoid 和 softmax 的核心区别是什么?
很多人都会把它们简单记成"两个把输出变成概率的函数"。
这个记法不算错,但还不够。
更本质的区别在于:
8.1 sigmoid
- 处理单个数值
- 每个输出彼此独立
- 更适合判断"这个类别成不成立"
8.2 softmax
- 处理一整组数值
- 所有输出彼此关联
- 更适合判断"多个类别里哪个最可能"
看下面这段对比代码会更直观:
python
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x):
exp_x = np.exp(x)
return exp_x / np.sum(exp_x)
scores = np.array([2.0, 1.0, 0.1])
print("对每个值分别做 sigmoid:")
print(sigmoid(scores))
print("\n对整组值做 softmax:")
print(softmax(scores))输出:
log
对每个值分别做 sigmoid:
[0.8808 0.7311 0.5250]
对整组值做 softmax:
[0.6590 0.2424 0.0986]可以看到:
- sigmoid 是各算各的,因此结果之间没有竞争关系
- softmax 是整组一起算,因此结果之间会互相影响
这也是为什么在单标签多分类中,softmax 通常比 sigmoid 更合理。
9. 为什么输出层必须有这一步,而不能停在原始分数?
如果只考虑最终预测类别,原始分数配合 argmax 的确也能得到一个结果。
但如果把问题放到完整训练过程里,就会发现这还远远不够。
输出层需要 sigmoid 或 softmax,主要有三个原因:
9.1 让输出结果更容易解释
原始分数可以比较大小,但并不直观。
而经过变换后的结果更接近概率,更容易理解模型的判断倾向。
9.2 让类别之间的关系表达得更清楚
尤其是多分类任务中,softmax 能明确表达各类别之间的竞争关系。
9.3 让后续训练更自然
模型训练不是只看"猜没猜对",而是要衡量"离正确答案差多远"。
sigmoid 和 softmax 把输出整理成适合比较的形式之后,后续的损失函数才能顺利接上。
因此,输出层不是一个可有可无的装饰步骤,而是分类模型从"原始计算结果"走向"可训练分类结果"的关键一环。
10. 最容易混淆的几个点
10.1 sigmoid 和 softmax 可以互换
不能简单互换。
它们虽然都能把输出变成更像概率的形式,但适用的任务和处理方式并不相同。
10.2 sigmoid 输出多个值时,应该加起来等于 1
不一定。
sigmoid 是逐个独立处理每个值的,因此多个输出之间没有总和约束。
10.3 softmax 输出最大的那个值一定是对的
不是。
softmax 只是表示模型当前最倾向哪个类别,是否正确仍然要看真实标签。
10.4 输出层函数只是为了让结果更好看
不是。
输出层函数会直接影响输出形式,也会影响后续损失函数和训练过程 5。
11. 总结
sigmoid 和 softmax 的核心作用,都是把模型原始输出的分数,转换成更适合分类任务解释、比较和训练的形式。
其中:
- sigmoid 更适合回答"某个类别像不像"
- softmax 更适合回答"多个类别中谁最像"
如果把全文压缩成一句话,可以概括为:
模型之所以不能直接输出类别,不是因为做不到,而是因为类别编号本身不可训练、不可比较;因此分类模型需要先输出分数,再通过 sigmoid 或 softmax 把这些分数变成更适合训练和解释的结果。