K8s集群完成部署后, 紧接着要进行POD的创建调度来支持工作负载。工作负载的建立调度才是k8s作为资源调度容器编排的重点功能. 看到这读者容易想起DevOps里与业务继承的自动编排, K8s与CICD的贯通以及自动化, 我们将在后续的篇章里覆盖, 本篇作为系列文章的第二篇, 首先要解决的是K8s的POD的创建与调度, 并了解相关概念,进一步了解k8s。
K8s的层级架构是:k8s集群---Node (物理机或虚拟机) -- POD -- Container. 说到工作负载,先要了解容器和pod的概念:
容器: 容器是运行应用程序的独立运行环境,里面包含应用代码以及它需要的所有依赖。容器与以前的虚拟机对应, 虚拟机通过 Hypervisor 虚拟硬 件 , 每个 VM 都有完整操作系统。容器共享宿主机操作系统内核。容器是为了解决以往虚拟机对硬件依赖,资源消耗大, 弹性扩缩容不便的问题应运而生.
Pod: Pod 就是 Kubernetes 中运行应用的最小单位,相当于一个"应用运行的小房间",里面可以放一个或多个紧密协作的容器。Pod 是 Kubernetes 中最小的可部署和管理的计算单元,代表集群中一个正在运行的应用进程。它不是单个容器,而是一组共享网络、存储和运行环境的容器集合,通常被调度到同一节点上并协同工作。
把服务器想象成一栋楼的话, POD就像一个房间, 容器就是房间里执行任务的设备:
|-----------|--------|-----------|
| 概念 | 类比 | 说明 |
| Node | 一栋楼 | 一台服务器 |
| Pod | 一个房间 | 应用运行的地方 |
| Container | 房间里的设备 | 真正执行任务的程序 |
一. POD的创建与调度过程:
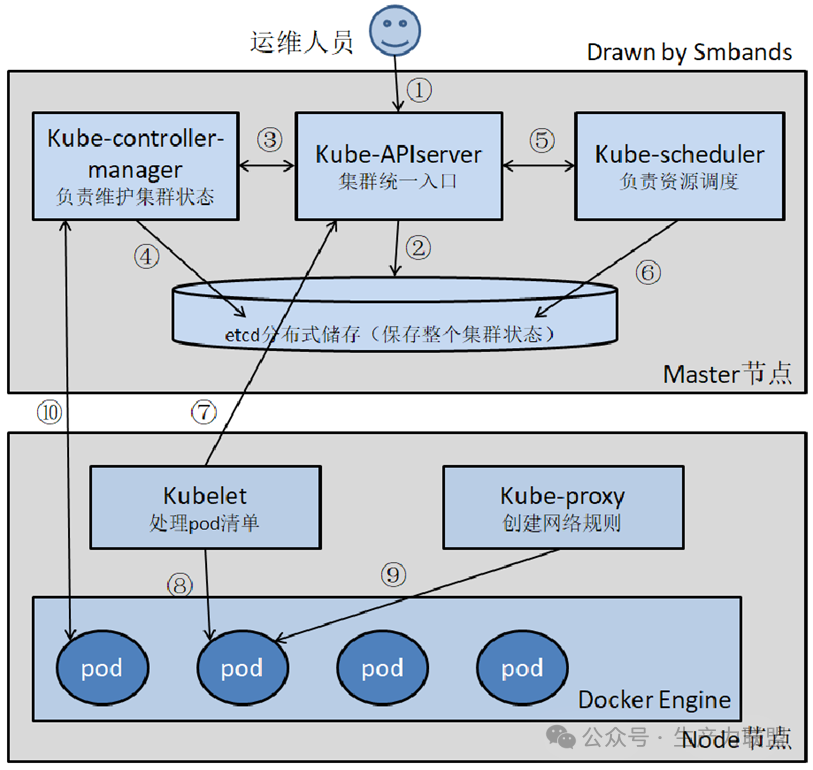
在 Kubernetes (k8s) 集群中,Pod的创建与调度是一个涉及多个组件协同工作的过程。这个过程确保了Pod 能够被正确地创建、调度到合适的节点上,并最终在节点上运行起来。以下是各个组件在此过程中的合作流程:
|--------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1. 用户提交请求: | 用户通过 kubectl 等客户端工具向 API Server 发送创建 Pod 的请求。请求通常包含 Pod 的配置信息(如 YAML 文件)。 |
| 2. API Server 验证与存储: | API Server 接收请求后,首先进行验证(如语法、权限、配额等)。验证通过后,API Server 将 Pod 的定义信息写入 etcd 数据库中。此时,Pod 状态为 Pending(未调度)。 |
| 3.4. Controller Manager 监控与创建副本: | Controller Manager 组件监听 API Server 的事件。如果 Pod 是由 Deployment、ReplicaSet 等控制器管理的,Controller Manager 会根据期望状态(如副本数)创建新的 Pod 副本,并更新到 etcd 中。这一步可能发生在 Pod 初始创建或副本数量调整时。 |
| 5. Scheduler 监听与调度: | Scheduler 组件通过 Watch 机制监听 API Server,专门寻找状态为 Pending 且尚未分配节点(nodeName 为空)的 Pod。它会根据一系列预选(Predicates)和优选(Priorities)策略来选择一个最合适的节点。 预选 (Predicates):过滤掉不满足 Pod 调度要求的节点。例如,节点资源是否足够(CPU、内存)、节点标签是否匹配(NodeSelector、NodeAffinity)、Pod 是否容忍节点的污点(Taints & Tolerations)等。 优选 (Priorities):对通过预选的节点进行打分,考虑因素包括资源利用率(如 LeastRequestedPriority)、资源平衡(如 BalancedResourceAllocation)、镜像本地化(ImageLocalityPriority)等。最终选择得分最高的节点。 |
| 6. Scheduler 更新调度结果: | Scheduler 将选定的节点信息(nodeName)更新到 Pod 的定义中,并通过 API Server 将此更新写入 etcd。这标志着 Pod 已被调度到指定节点。 |
| 7.8.9 Kubelet 执行 Pod 创建: | 每个节点上的 Kubelet 组件通过 Watch 机制监听 API Server,获取分配给本节点的 Pod 信息。当 Kubelet 发现有 Pod 被调度到本节点时,它会执行以下操作: 网络配置:调用 CNI(Container Network Interface)插件为 Pod 创建网络。 容器运行时:调用 CRI(Container Runtime Interface)接口,通过容器运行时(如 Docker、containerd)拉取镜像并创建容器。 存储挂载:如果 Pod 需要持久化存储,Kubelet 会调用 CSI(Container Storage Interface)接口挂载存储卷。 状态监控:Kubelet 持续监控 Pod 及其容器的运行状态,并将状态信息上报给 API Server。 |
| 10. 状态同步与维护: | API Server 将 Pod 的最终状态(如 Running)更新到 etcd 中。Controller Manager 会持续监控 Pod 状态,确保实际状态与期望状态一致。如果 Pod 崩溃或节点故障,Controller Manager 会触发重新调度流程。 |
整个流程中,API Server 作为核心通信枢纽,负责接收请求、存储状态、通知其他组件;etcd作为分布式存储,持久化保存集群状态;Scheduler 负责决策调度;Kubelet负责节点上的具体执行。各组件通过 API Server 和etcd 实现了信息同步和协同工作。
二. POD创建调度实验示例:
那么了解了POD,了解了POD创建调度的过程, 我们来实际看一个POD创建调度的例子.
- 首先我们来看一个示例Yaml,保存为mysql-deploy.yaml(注意把注释注解内容去掉):
apiVersion: apps/v1 #使用的Kubernetes API版本,Deployment资源属于 apps/v1 组
kind: Deployment #定义资源类型,这里创建的是 Deployment 控制器
metadata: #资源的元数据信息
name: mysql # Deployment 的名称,kubectl 中显示为 deployment/mysql
spec: # 资源的期望状态定义
replicas: 1 # 期望运行的 Pod 副本数量,这里只运行1个MySQL Pod
selector: # Deployment 用于查找并管理 Pod 的标签选择器
matchLabels: # 使用 label 精确匹配方式
app: mysql # 选择 label=app:mysql 的 Pod 作为管理对象
template: # Pod 模板,Deployment 会按这个模板创建 Pod
metadata: # Pod 的元数据
labels: # Pod 的标签
app: mysql # Pod 标签,必须与 selector.matchLabels 一致
spec: # Pod 的运行配置
nodeSelector: # 节点选择器,用于限制 Pod 运行在哪些 Node 上
db: mysql # 只有带 label db=mysql 的 Node 才能运行此 Pod
containers: # Pod 内的容器列表
- name: mysql # 容器名称
image: mysql:8 # 使用的容器镜像(DockerHub官方 MySQL 8)
resources: # 容器资源管理配置
requests: # 最小资源请求(调度时保证的资源)
memory: "2Gi" # 至少需要 2GB 内存
cpu: "1" # 至少需要 1 个CPU核心
limits: # 容器可使用的最大资源限制
memory: "4Gi" # 最大可使用 4GB 内存,超过会被 OOMKill
cpu: "2" # 最大可使用 2 个CPU核心,超过会被限速
这里为了验证POD调度, 我们使用了nodeselector方式来指定特定Node运行mysql pod. 比如实验中,我们使用vm04node. 然后用给node打label的方式来实现node选择逻辑:
Kubectl label node vm04node mysql=true
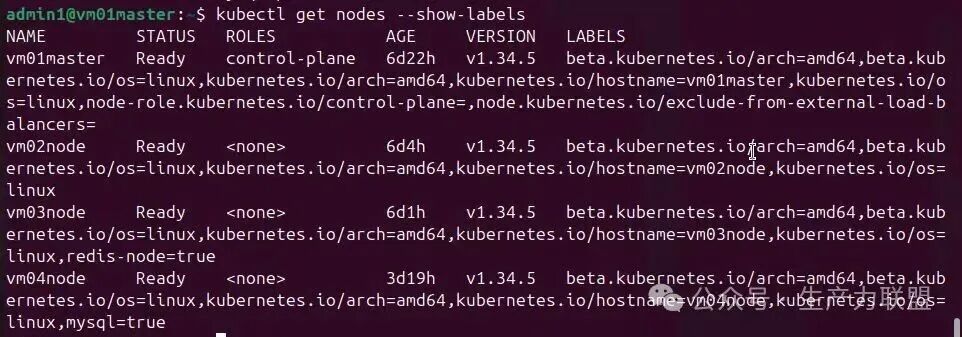
查看node的label情况:
Kubectl get nodes --show-labels
-
在master上运行该命令: kubectl apply -f mysql-deploy.yaml
-
查看mysql 容器是否在vm04node上创建成功: kubectl get pods --o wide
确认pod是调度到了vm04node.

4.确认容器运行状态: kubectl logs mysql-xxx-xxx, 看到mysqld:ready for connections, 说明Mysql 容器启动成功

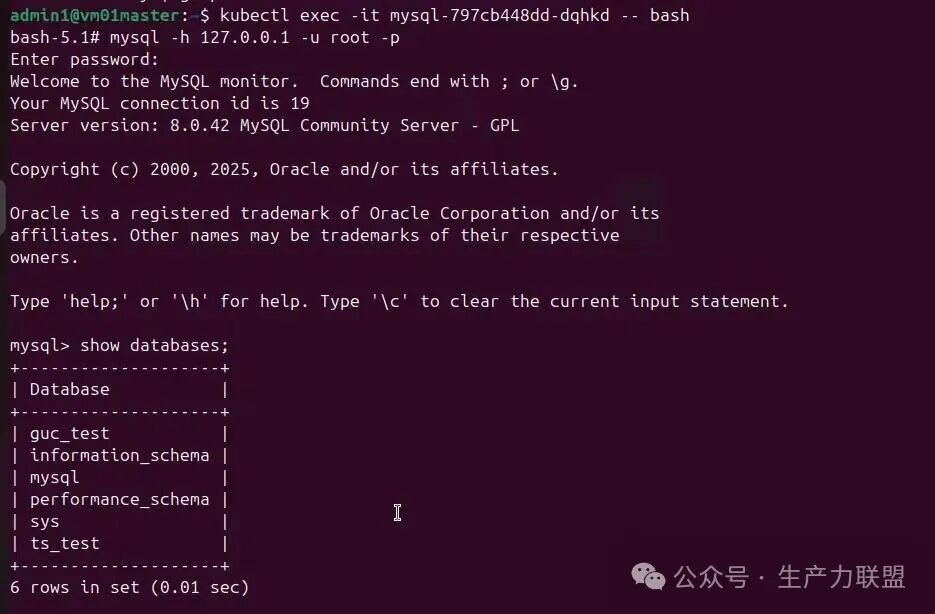
- 查看容器内mysql是否正常起来以及是否可以正常连接: kubectl exec -it mysql-xxx-xxx
容器内执行 mysql -h 127.0.0.1 --u root -p xxxxxx , 运行show databases; 命令展示数据库
- 删除当前的mysql pod : kubectl delete pod --l app=mysql
之后再次展示pod情况: kubectl get pods -A, 发现mysql 已有新的pod在运行, 说明mysql的deployment, 依据yaml定义在维护执行

到这里就跑通了k8s pod的部署调度基本逻辑. 读者可以边实验边了解。后续系列文章中将陆续覆盖容器持久化, devops自动化等企业实践内容。欢迎大家关注生产力联盟, 掌握智能时代新质生产力.
附录 : Kubernetes Workload 类型对比 , 下面整理Workload 类型(运行应用的资源)。
|-------------|------------------------|----------|-----------|----------------|----------|--------------|
| kind | 控制器 | 主要用途 | 是否有状态 | Pod 身份 | 扩容方式 | 典型场景 |
| Deployment | Deployment Controller | 无状态应用 | 否 | 随机 | 任意扩容 | Web API |
| StatefulSet | StatefulSet Controller | 有状态应用 | 是 | 固定 | 顺序扩容 | MySQL |
| DaemonSet | DaemonSet Controller | 每节点运行一个 | 通常无状态 | 随机 | 自动随Node | 日志采集 |
| Job | Job Controller | 一次性任务 | 不适用 | 临时 | 完成后退出 | 数据处理 |
| CronJob | CronJob Controller | 定时任务 | 不适用 | 临时 | 按时间触发 | 定时备份 |
| ReplicaSet | ReplicaSet Controller | 保证Pod数量 | 否 | 随机 | 任意 | Deployment底层 |