一、二叉搜索树的概念
二叉搜索树又称二叉排序树,它的定义非常明确:它要么是一棵空树,要么是具有以下三个核心性质的二叉树,这也是判断一棵二叉树是否为BST的关键依据:
1.若它的左子树不为空,则左子树上所有结点的值都小于等于根结点的值;
2.若它的右子树不为空,则右子树上所有结点的值都大于等于根结点的值;
3.它的左、右子树也分别为二叉搜索树(递归定义)。
这里需要重点说明:二叉搜索树是否支持插入相等的值,没有固定规则,完全取决于使用场景。后续我们学习的STL容器中,map、set不支持插入相等值,而multimap、multiset支持插入相等值,本质就是基于二叉搜索树的规则调整实现的。
直观示例
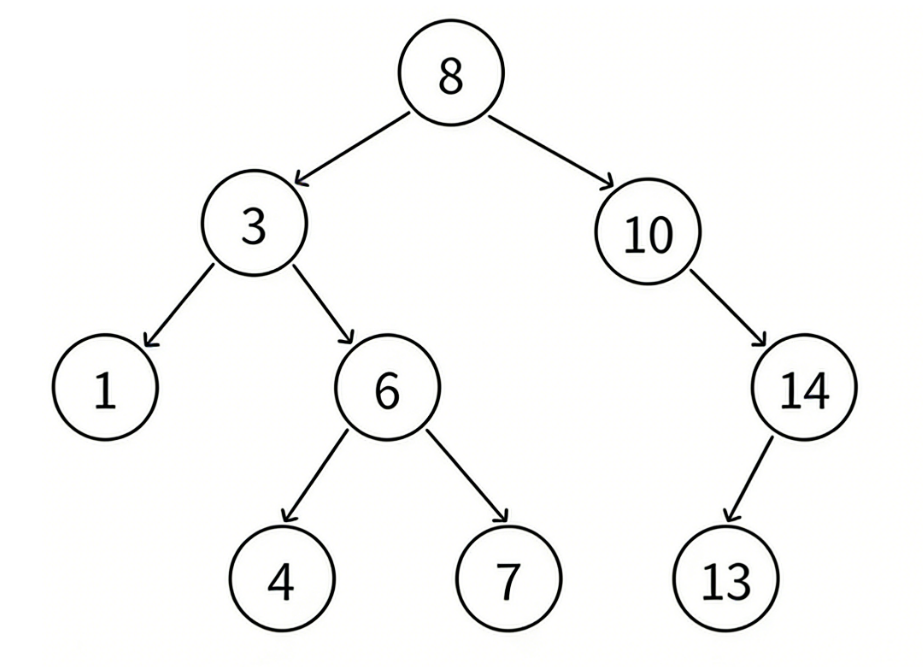
下面这棵树是典型的二叉搜索树,对照性质可直接验证。
8
/ \
3 10
/ \ \
1 6 14
/ \ /
4 7 13
二、二叉搜索树的性能分析
二叉搜索树的核心价值的是高效的增删查改操作,但性能好坏完全取决于树的结构,主要分为两种情况:
最优情况下 ,⼆叉搜索树为完全⼆叉树(或者接近完全⼆叉树),其⾼度为:log2N
最差情况下 ,⼆叉搜索树退化为单⽀树(或者类似单⽀),其⾼度为:N
所以综合⽽⾔⼆叉搜索树增删查改时间复杂度为: O(N) 那么这样的效率显然是⽆法满⾜我们需求的,我们后面会学到⼆叉搜索树的变形,平衡⼆ 叉搜索树AVL树和红⿊树,才能适⽤于我们在内存中存储和搜索数据。
另外需要说明的是,⼆分查找也可以实现O(logN) 2级别的查找效率,但是⼆分查找有两⼤缺陷:
-
需要存储在⽀持下标随机访问的结构中,并且有序。
-
插⼊和删除数据效率很低,因为存储在下标随机访问的结构中,插⼊和删除数据⼀般需要挪动数 据。
这⾥也就体现出了平衡⼆叉搜索树的价值。
三、⼆叉搜索树的插⼊
插⼊的具体过程如下:
-
树为空,则直接新增结点,赋值给root指针
-
树不空,按⼆叉搜索树性质,插⼊值⽐当前结点⼤往右⾛,插⼊值⽐当前结点⼩往左⾛,找到空位 置,插⼊新结点。
-
如果⽀持插⼊相等的值,插⼊值跟当前结点相等的值可以往右⾛,也可以往左⾛,找到空位置,插 ⼊新结点。(要注意的是要保持逻辑⼀致性,插⼊相等的值不要⼀会往右⾛,⼀会往左⾛)
cpp
int a[] = {8, 3, 1, 10, 6, 4, 7, 14, 13};代码实现:
cpp
//BinarySearch.h
#include<iostream>
using namespace std;
template<class K>
struct BSTNode//树节点
{
K _key;
BSTNode<K>* _left;
BSTNode<K>* _right;
BSTNode(const K& key)
:_key(key)
,_left(nullptr)
,_right(nullptr)
{ }
};
template<class K>
class BSTree
{
using Node = BSTNode<K>;//和typedef Node = BSTNode<K>;一样的作用
public:
//插入
bool Insert(const K& key)
{
//空树情况
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
//树非空,查找插入位置
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key<key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;// 遇到重复值,插入失败(不支持重复值)
}
}
// 找到空位置,创建新节点,插入到父节点的左/右
cur = new Node(key);
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
private:
Node* _root = nullptr;
};四、 ⼆叉搜索树的查找
-
从根开始⽐较,查找x,x⽐根的值⼤则往右边⾛查找,x⽐根值⼩则往左边⾛查找。
-
最多查找⾼度次,⾛到到空,还没找到,这个值不存在。
-
如果不⽀持插⼊相等的值,找到x即可返回。
-
如果⽀持插⼊相等的值,意味着有多个x存在,⼀般要求查找中序的第⼀个x。
代码实现:
cpp
//查找
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (key > cur->_key)
{
cur = cur->_right;
}
else if (key < cur->_key)
{
cur = cur->_left;
}
else
{
return true;
}
}
return false;
}五、⼆叉搜索树的删除
⾸先查找元素是否在⼆叉搜索树中,如果不存在,则返回false。
如果查找元素存在则分以下四种情况分别处理:(假设要删除的结点为N)
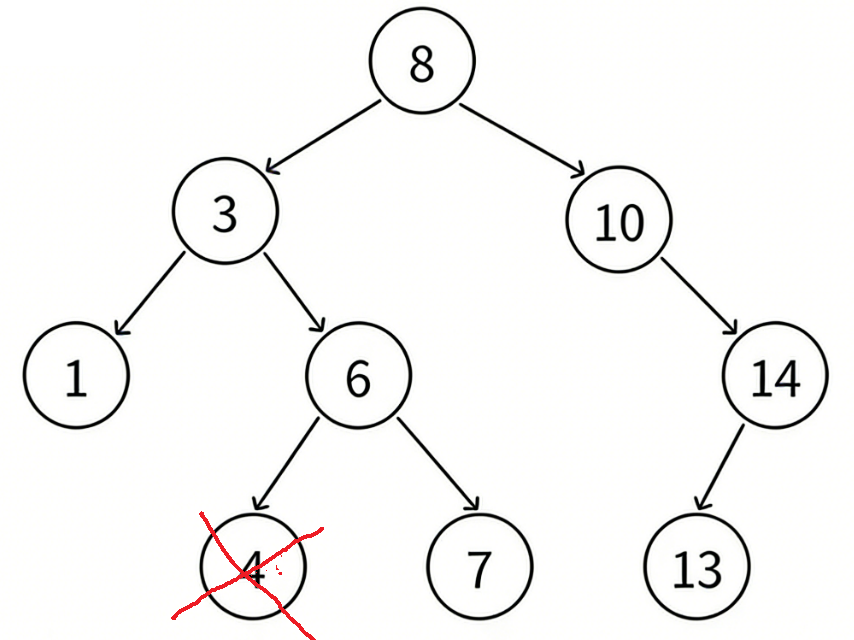
- 要删除结点N左右孩⼦均为空
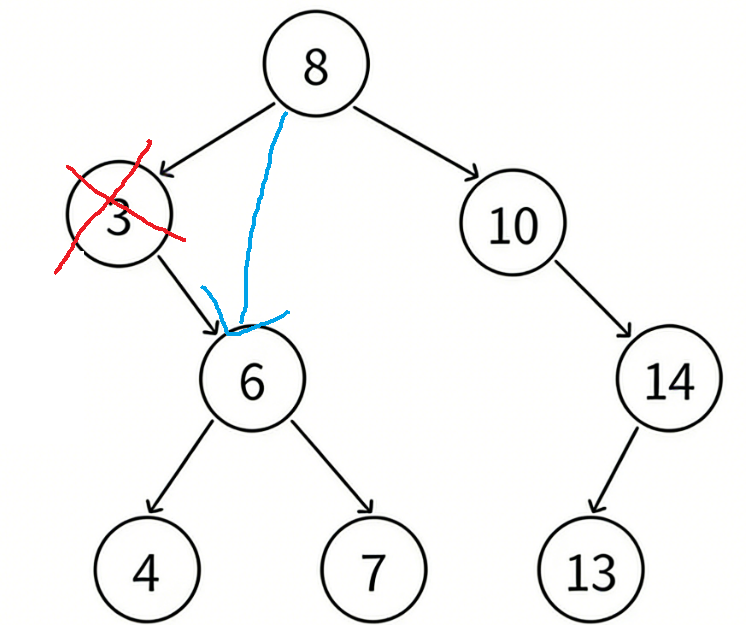
- 要删除的结点N左孩⼦位空,右孩⼦结点不为空
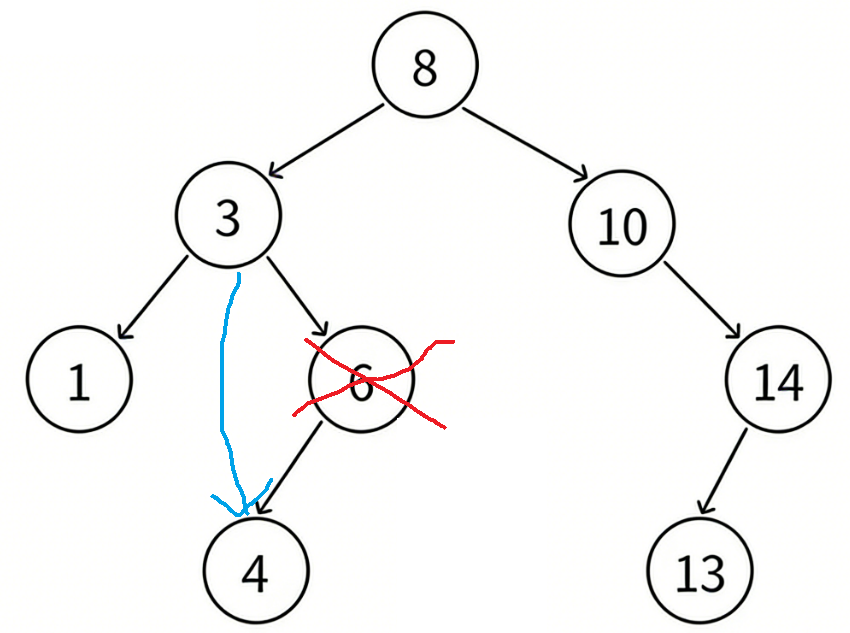
- 要删除的结点N右孩⼦位空,左孩⼦结点不为空
- 要删除的结点N左右孩⼦结点均不为空,这是最复杂的情况,也是本章难点。
对应以上四种情况的解决⽅案:
-
把N结点的⽗亲对应孩⼦指针指向空,直接删除N结点(情况1可以当成2或者3处理,效果是⼀样 的)
-
把N结点的⽗亲对应孩⼦指针指向N的右孩⼦,直接删除N结点
-
把N结点的⽗亲对应孩⼦指针指向N的左孩⼦,直接删除N结点
-
⽆法直接删除N结点,因为N的两个孩⼦⽆处安放,只能⽤替换法删除。
对应要删除的N节点:
1.找到N的左子树的最大值进行替换,然后删除N;
2.找到N的右子树的最小值进行替换,然后删除N;
以上两种方法任意一个都可以。
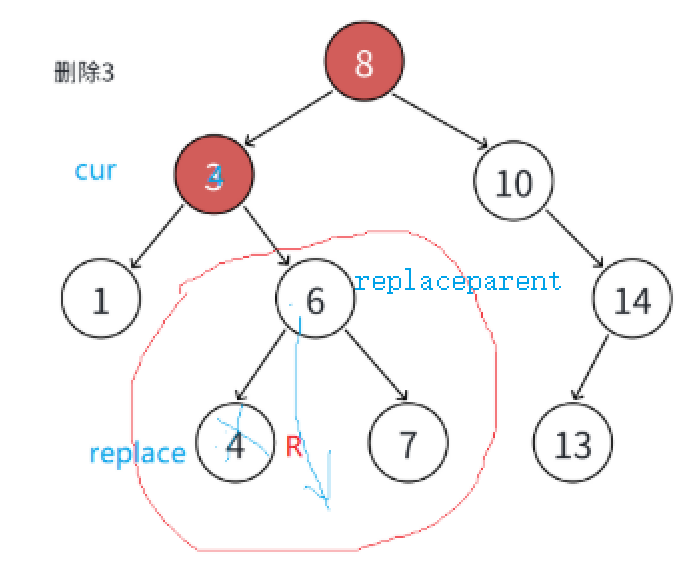
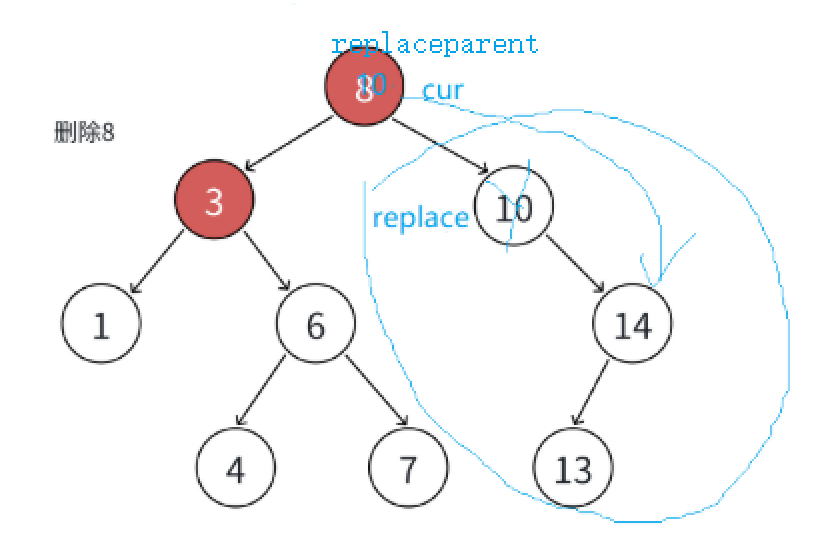
假设使用方法2:
找到被删节点(cur)的右子树最小节点当替换节点(replace),替换后让replac的父亲节点(replaceparent)指向replace的右子树,最后删除replace。
情况1:replace在replaceparent的左子树,replaceparent就指向replace的右子树。
情况2:replace在replaceparent的右子树,replaceparent就指向replace的右子树。
代码实现:
cpp
//删除
bool Erase(const K& key)
{
if (Find(key)==0)
return false;
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
//查找
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
//删除
if (cur->_left == nullptr)//被删节点左为空的情况
{
if (cur == _root)
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)//在父亲的左边
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
}
else if (cur->_right == nullptr)//被删节点右为空的情况
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
}
else
{
//被删节点左右子树都不为空
//找其右子树最左节点
Node* replaceParent = cur;
Node* replace = cur->_right;
while (replace->_left)
{
replaceParent = replace;
replace = replace->_left;
}
cur->_key = replace->_key;
if (replaceParent->_left == replace)
replaceParent->_left = replace->_right;
else
replaceParent->_right = replace->_right;
delete replace;
}
return true;//成功找到要删除的节点并删除
}
}
return false;//未找到要删除的节点
}六、二叉搜索树的两种使用场景(key / key-value)
二叉搜索树主要有两种使用场景,对应两种节点结构,我们分别说明并实现key-value场景的代码。
6.1 key搜索场景
核心特点:结构中只存储key(关键码),核心需求是判断key是否存在,支持增删查,但不支持修改key(修改key会破坏BST的有序性)。
典型应用场景

-
小区无人值守车库:将业主车牌号作为key存入BST,车辆进入时扫描车牌,查找是否在BST中,在则抬杆,不在则禁止进入;
-
英文单词拼写检查:将词库中所有单词作为key存入BST,读取文章中的单词,查找是否在BST中,不在则提示拼写错误。
我们前面实现的BSTree<K>,就是典型的key搜索场景。
cpp
#include"BinarySearch.h"
int main()
{
key_value::BSTree<string, string> dict;
dict.Insert("left", "左边");
dict.Insert("right", "右边");
dict.Insert("insert", "插入");
dict.Insert("string", "字符串");
string str;
while (cin >> str)
{
auto ret = dict.Find(str);
if (ret)
{
cout << "->" << ret->_value << endl;
}
else
{
cout << "无此单词,请重新输入" << endl;
}
}
return 0;
}6.2 key-value搜索场景
核心特点:每个key对应一个value(值),节点中需要同时存储key和value,增删查仍以key为关键字,支持修改value(不支持修改key),核心需求是通过key快速找到对应的value。
典型应用场景

-
简单中英互译字典:key为英文单词,value为中文释义,输入英文key,快速查找对应的中文释义;
-
商场无人值守车库:key为车牌号,value为入场时间,出场时通过车牌号(key)查找入场时间,计算停车时长和费用;
-
单词出现次数统计:key为单词,value为出现次数,读取单词时,若key不存在则插入(key, 1),若存在则将value++。
cpp
int main()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉" };
key_value::BSTree<string, int> countTree;
for (const auto& str : arr)
{
// 先查找水果在不在搜索树中
// 1、不在,说明水果第一次出现,则插入<水果, 1>
// 2、在,则查找到的结点中水果对应的次数++
auto ret = countTree.Find(str);
if (ret == nullptr)
{
countTree.Insert(str, 1);
}
else
{
// 修改value
ret->_value++;
}
}
countTree.Inorder();
return 0;
}七、全文总结
二叉搜索树是C++数据结构的重点,也是后续高级树形结构的基础,核心要点总结如下:
-
概念:二叉搜索树要么是空树,要么满足"左子树≤根,右子树≥根",左右子树也为BST;是否支持重复值,取决于使用场景。
-
性能:最优情况(完全二叉树)时间复杂度 \(O(log _{2} N)\),最差情况(单支树)退化到 \(O(N)\),后续需学习AVL树、红黑树优化。
-
核心操作: - 插入:按BST性质查找空位置,插入新节点,不支持重复值则返回false; - 查找:按BST性质缩小范围,最多查找树的高度次; - 删除:分4种场景,核心是"替换法"处理左右子树均非空的情况,删除后保持BST有序。
-
使用场景: - key场景:只判断key是否存在,不支持修改key; - key-value场景:通过key找value,支持修改value,不支持修改key。
-
关键验证:中序遍历结果为严格递增序列,是判断BST的核心方法。
二叉搜索树的难点在于删除操作的4种场景,建议大家多敲几遍代码,尤其是场景4的替换法,理解替代节点的选择逻辑和删除逻辑。掌握了二叉搜索树,后续学习AVL树、红黑树就会轻松很多,也能更好地理解STL容器的底层实现。