数据库连接池:Druid
前言
Druid 连接池是阿里巴巴开源的数据库连接池项目。Druid 连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL 注入,内置Loging 能诊断Hack应用行为。
为什么要用连接池
如果没有连接池,你的代码每次执行 SQL 都会这样:
- 客户端向 MySQL 发起 TCP 连接
- 三次握手
- MySQL 验证账号密码
- 创建连接
- 执行一条 SQL
- 关闭连接
- 四次挥手
下次查询 → 重复上面全部步骤。
创建 / 销毁连接非常耗时(比执行 SQL 慢几十~几百倍),高并发下,大量请求同时建连MySQL 直接卡死,连接不可复用,极度浪费资源。
连接池就是一个 "存放数据库连接的缓存池子"。使用连接池的流程如下:
- 项目启动 → 预先创建好一批连接(
initial-size) - 接口要查询 → 从池子里借一个连接
- 用完 → 还回池子,而不是关闭
- 下一个请求继续复用
- 空闲太久的连接才会被自动销毁
性能提升巨大,避免频繁 TCP 握手、认证,连接统一管理,避免资源泄露,控制连接数量,保护数据库。
对比
从 Spring Boot 2.0 开始,官方就将默认数据库连接池从 Tomcat JDBC Pool 替换为 HikariCP (发音:Hi-ka-ri ),至今(Spring Boot 3.x)依然是默认选择。
-
Tomcat-jdbc 是Apache Tomcat 官方自带的轻量级数据库连接池,核心定位是稳定、简单、与 Tomcat 容器深度集成。曾是 Spring Boot 1.x 默认连接池。
-
HikariCP 被称为 "史上最快的 Java 连接池 ",核心优势:代码量极少(约 130KB),无冗余逻辑,底层做了大量优化(比如锁优化、减少内存分配),依赖少,启动快,对项目体积几乎无影响,也是 Spring 官方选择它的原因。
-
Druid 是Java 语言中最好的数据库连接池。功能丰富度:SQL 监控面板、慢 SQL 记录、SQL 防火墙(防注入)、连接泄露检测、支持配置加密,等
| 功能类别 | Druid | HikariCP | Tomcat-jdbc |
|---|---|---|---|
| 性能(速度) | 性能很强,略低于 Hikari,但业务场景几乎无感知差距 | 极致优化,代码极简,锁粒度细,公认最快 | 稳定够用,但高并发下不如前两者 |
| 配置复杂度 | 可配置项多,不配置也能用,但想用好必须配 | 默认配置极优,几乎不用改 | 简单,但参数老旧 |
| 稳定性 | 连接池内置经过历年双十一超大规模并发验证的ExceptionSorter。在数据库服务器等异常情况下,保证连接池在异常发生时情况下正常工作。 | 极其稳,极少出问题 | 老牌稳定,但高并发下表现一般 |
| 功能丰富度 | 连接池 + 监控 + 防火墙 + 日志 + 加密 + SQL 诊断,全能 | 只做连接池,功能极简 | 基础连接池功能,无额外亮点 |
| 安全性 | 内置 wall 防火墙,防 SQL 注入 | 无安全相关功能 | 无安全相关功能 |
| 监控能力 | 自带 Web 监控页面、慢 SQL、执行次数、TPS连接泄露、事务、数据源状态 | 只暴露 Metrics 指标,无界面 | 基本监控,无界面 |
| 轻量化 & 内存占用 | 功能多,稍重但完全可接受 | 极轻 | 相对笨重 |
| 生态与默认地位 | 阿里开源,国内企业使用率极高 | Spring Boot 2.x/3.x 默认连接池 | Spring Boot 1.x 默认,现已淘汰 |
SpringBoot3整合Druid
xml
<!-- MySQL官方驱动(必须保留) -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<!-- 阿里Druid连接池(Spring Boot 3适配版本) -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-3-starter</artifactId>
<version>1.2.20</version>
</dependency>配置 Druid(application.yml)
yml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test_db?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
# 指定使用阿里Druid连接池(替换默认的HikariCP,非必须,引入依赖后自动排除默认HikariCP)
type: com.alibaba.druid.pool.DruidDataSource
# Druid连接池专属配置(可选,推荐配置)
druid:
initial-size: 5 # 初始化连接数
min-idle: 5 # 最小空闲连接数
max-active: 20 # 最大活跃连接数
max-wait: 60000 # 获取连接的最大等待时间(毫秒)
time-between-eviction-runs-millis: 60000 # 检测空闲连接的间隔时间
min-evictable-idle-time-millis: 300000 # 空闲连接的最小存活时间
validation-query: SELECT 1 FROM DUAL # 验证连接是否有效
test-while-idle: true # 空闲时检测连接有效性
test-on-borrow: false # 获取连接时不检测(提升性能)
test-on-return: false # 归还连接时不检测
pool-prepared-statements: true # 开启PSCache
max-pool-prepared-statement-per-connection-size: 20 # PSCache大小
# 配置监控过滤器(可选,用于Druid监控页面)
filters: stat,wall,log4j2 # stat:监控统计;wall:防SQL注入;log4j2:日志
# 监控页面配置(访问http://localhost:8080/druid/ 即可查看)
web-stat-filter:
enabled: true
url-pattern: /*
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
stat-view-servlet:
enabled: true
url-pattern: /druid/*
# 监控页面登录账号密码(可选)
login-username: admin
login-password: 123456
allow: 127.0.0.1 # 允许访问的IP(默认所有)Druid 配置属性全解析
Druid提供了上百个配置项,但日常开发中只需关注核心的 10+ 个常用配置即可满足 90% 的场景。
基础连接池配置
initial-size:连接池初始化时创建的连接数,默认值:0,常用值:5-10。
项目启动时,Druid一次性创建好的数据库连接数量。设置了,启动时就建好 N 个连接放池子里;不设置,initial-size 默认是 0,用到时才现建连接,会导致刚启动时前几个请求稍慢。
最常用、最稳妥的区间 initial-size: 5 ~ 10,高并发、接口访问频繁10 左右(一般不建议超过 20)
为什么不建议太大?
启动变慢:启动就要一次性创建很多连接
浪费数据库连接:MySQL 总连接数有限,你占多了别人就不够用
连接闲置太久也会被 MySQL 断开,反而没用
min-idle:连接池会保证池子里始终至少有这么多 "空闲可用" 的数据库连接,如果空闲连接数低于这个值,Druid 会自动、异步地创建新连接补充,直到达到min-idle。默认值:0,常用值:5-10。
项目运行中,若池子里只有 3 个空闲连接, Druid 会自动新建 2 个连接,让空闲数回到 5;min-idle 默认值是 0,意味着连接池不会主动维护空闲连接,空闲连接可能被 MySQL 超时断开,下次请求需要时才临时创建,会导致,请求偶尔卡顿,容易出现 "无效连接" 报错。
最佳实践:initial-size ≤ min-idle(比如 initial-size=5,min-idle=5),同样建议不要超过20
max-active:连接池最大活跃连接数(同时最多能使用的连接数) ,默认值:8,常用值:20-50(视业务),超过这个数量的请求,只能排队等待,直到有人归还连接,或者超时报错。
数据库能扛的连接是有限的(MySQL 默认 151 左右)max-active 就是给数据库 "限流",防止把库打挂。
默认 max-active = 8,并发稍微一高就等待、超时、接口卡住 ,一般不建议超过 50~80。
搭配:initial-size ≤ min-idle < max-active,示例配置:
yml
initial-size: 5 # 启动时开几个
min-idle: 5 # 最少留几个空闲
max-active: 20 # 最多同时用几个max-wait:获取连接的最大等待时间(毫秒),超时抛异常,默认值:-1(无限),常用值:5000ms ~ 10000ms。
从连接池里 "借" 连接时,最多允许等多少毫秒。等了这么久还没等到空闲连接,就直接抛异常,不再等了。
报错:Could not get JDBC Connection / wait timeout
同一时间最多 20 个连接在跑,第 21 个请求开始排队,最多等 60 秒,60 秒内有连接归还,继续执行;60 秒还没有 ,直接抛超时异常。
默认 max-wait = -1,无限等待,高并发下会导致:请求大量阻塞、接口一直转圈圈、线程堆积、最后服务直接卡死。设置等待时间太长,问题会被掩盖,最后集中雪崩。
pool-prepared-statements:是否开启 PSCache (PreparedStatement 缓存,提升 SQL 执行效率), 默认值:false,常用值:true。
是否开启 "预编译 SQL 缓存 "(PS Cache )。让数据库只编译一次 SQL,多次复用,从而大幅提升查询速度。
如果执行这样的 SQL:
sql
select * from user where id = ?
select * from user where id = ?
select * from user where id = ?不开启 :数据库每次都要编译 → 慢;开启:数据库编译一次,缓存起来,后面直接用 → 快很多。
max-pool-prepared-statement-per-connection-size:每个数据库连接,最多缓存多少条预编译 SQL (PreparedStatement ),默认值:10,常用值:20-50。
你开启了 pool-prepared-statements=true 后,Druid 会把执行过的 SQL 预编译结果缓存起来,下次相同 SQL 直接复用,不用重新编译。
比如:
sql
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20说明:每条数据库连接,最多缓存 20 条不同的预编译 SQL ;第 21 条新 SQL 进来时,会淘汰最久没用的缓存。
不建议设置太大,会占用内存,也不会明显更快,反而可能内存浪费。
如果你使用了pool-prepared-statements和max-pool-prepared-statement-per-connection-size,就需要再MySQL 连接Url后面加上两个参数:
yml
url: jdbc:mysql://...&cachePrepStmts=true&useServerPrepStmts=truecachePrepStmts:驱动开启缓存
useServerPrepStmts :是否让 MySQL 服务器端做预编译
不加 URL 的 cachePrepStmts + useServerPrepStmts缓存 99% 情况下不生效!等于白开!MySQL 不做服务端预编译,Druid 想缓存也没东西可缓存。
注意:如果使用分库分表(Sharding-JDBC 、MyCat 等),开了服务端预编译, SQL 提前在 MySQL 编译好了,分库分表组件想改表名,改不了了,结果:数据路由到错误的分表(
Table 'xxx.xxx' doesn't exist)
如果是常规后台管理、微服务单库,使用配置就可以;如果是分库分表,那就别开,避免踩坑。
连接有效性检测
检测连接有效性,防止(如数据库超时关闭、防火墙切断、网络中断),导致连接失效,应用拿 "假连接" 执行 SQL 报错(Connection closed/No operations allowed after connection closed等错误)的问题。
validation-query:配置一条极简 SQL ,用于检测连接池中的数据库连接是否还活着、是否有效。(需适配数据库,MySQL 用SELECT 1),默认值:空,常用值:SELECT 1。
必须是SELECT 查询,且至少返回 1 行结果(轻量、无业务逻辑、执行极快)。
常见数据库配置示例:
| 数据库 | 推荐 | 说明 |
|---|---|---|
| MySQL | SELECT 1 |
最简,无表依赖 |
| Oracle | SELECT 1 FROM DUAL |
必须带FROM DUAL |
| PostgreSQL | SELECT 1 / SELECT version() |
前者更轻 |
| SQL Server | SELECT 1 | 通用 |
| DB2 | SELECT 1 FROM SYSIBM.SYSDUMMY1 | 系统虚拟表 |
validation-query是testOnBorrow、testOnReturn、testWhileIdle等连接校验开关的前提:不配置 validation-query,这些开关全部失效。
test-while-idle:空闲时,自动检查检测是否存活(推荐开启,不影响性能),默认值:true,常用值:true。
连接池里的连接如果长时间不用,MySQL 会主动断开(默认 8 小时)。但连接池不知道,还以为连接是好的,你一用就报错:
No operations allowed after connection closed 或者 Connection reset by peer
test-while-idle 让连接池定期检查数据库,把死掉的连接扔掉,保证你拿到的永远是活的。
配套参数:
yml
test-while-idle: true # 开启空闲检测
validation-query: SELECT 1 # 检查用的SQLtest-on-borrow:从线程池获取连接时,检测连接是否存活(开启会降低性能,推荐关闭),活的才给你,死的就扔掉重建,默认值:false,常用值:false。
每次你代码要获取连接时,连接池先执行 validation-query(SELECT 1):
没问题 → 把连接给业务用。
有问题 → 丢弃这个连接,拿一个新的给你。
优点 :非常稳,业务代码几乎不会遇到 connection closed 这类错误。
缺点 :每次获取连接都多一次 SQL 查询,高并发下(QPS 高)性能损耗明显,会增加数据库压力,拖慢接口。
test-on-borrow虽然稳,但影响性能,生产一般关闭。
test-on-return:把连接 "还给" 连接池的时候,检查一下连接是否还正常(开启会降低性能,推荐关闭),默认值:false,常用值:false。
业务执行完 SQL ,归还连接到连接池,连接池执行 validation-query(SELECT 1):
正常 → 放回池里
不正常 → 直接销毁,不丢进池里污染别人
优点:保证池子里永远只存健康的连接。
缺点 :每次用完连接都要多执行一次 SQL ,高并发下性能损耗巨大,接口 RT 明显上升,数据库压力变大。
test-on-return还连接时做健康检查,性能差,生产不要开。
time-between-eviction-runs-millis:控制多久检查一次 "空闲的死连接"(毫秒),默认值:60000,常用值:60000(1 分钟)。
你开启了 test-while-idle 后,连接池不能每时每刻都检查,必须每隔一段时间,统一扫一遍连接。检查空闲太久的连接 和检查失效的连接 进行销毁。
min-evictable-idle-time-millis:控制一个连接,空闲多久之后,才允许被销毁,默认值:300000,常用值:300000(5 分钟)。
连接池里的连接如果一直没人用,不能一直占着资源。但也不能刚空闲 1 秒就销毁(太浪费)。连接空闲超过这个时间,判定为 "闲置无用",销毁回收。
必须配合time-between-eviction-runs-millis(执行者)使用:
yml
# 巡逻频率:1分钟查一次
time-between-eviction-runs-millis: 60000
# 空闲超过5分钟,销毁
min-evictable-idle-time-millis: 300000连接泄露监控
remove-abandoned:是否开启(连接泄露、卡死、忘记归还 )的数据库连接自动回收,默认值:false,常用值:true(测试 / 生产可选)。
项目里可能出现这种 BUG:代码死循环、接口卡死、超时、程序异常没释放连接。导致代码死循环、接口卡死、超时、程序异常没释放连接。
remove-abandoned=true防止连接池被占满,导致整个系统卡死、无法访问数据库。
remove-abandoned-timeout-millis:连接被占用多久没归还的超时时间(毫秒),默认值:300,常用值:180000(3 分钟)。
一个连接被程序 "借走" 后,如果超过这个时间还没还回连接池,就直接当成泄露连接杀掉回收。
防止:慢查询卡死、代码死循环、事务没关、连接忘记释放、导致连接池被占满,整个服务不可用。
配合 remove-abandoned 使用:
yml
remove-abandoned: true # 开启连接泄露自动清理
remove-abandoned-timeout-millis: 180000 # 3分钟log-abandoned:泄露连接时打印日志(包含堆栈,便于排查),默认值:false,常用值:false。
当连接池开启 remove-abandoned=true,强制回收了一个 "超时未归还" 的连接时,log-abandoned=true 就会让 Druid 打印一条详细错误日志:
bash
[WARN] Abandoned connection cleanup detected <-- 发现连接泄露
[WARN] Stack trace of abandoned connection:
java.lang.Exception: Apparent connection leak detected
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1895)
at com.xxx.service.UserService.getUserList(UserService.java:58) <-- 你的代码位置
at com.xxx.controller.UserController.list(UserController.java:25)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at ...
[WARN] Connection abandoned, stack trace:
[WARN] SQL: SELECT * FROM user WHERE status = ? <-- 正在执行的 SQL
[WARN] Connection hold time: 182 seconds <-- 连接占用了多久
[WARN] Stack trace for connection creation:配套参数:
yml
remove-abandoned: true # 开启连接泄露自动清理
remove-abandoned-timeout-millis: 180000 # 3分钟
log-abandoned: true # 必须开启建议只在测试环境设置未开启,利用测试环境发现业务代码中未正常关闭连接的情况
过滤器配置
Druid 的核心优势之一是内置多种过滤器,通过 filters 配置启用:
filters
启用的过滤器(监控、SQL 防火墙、日志、性能统计、防注入),多个用逗号分隔:
yml
# 声明启用哪些过滤器
filters: stat,wall,slf4j,configstat:SQL 监控统计:监控 SQL 执行速度、监控连接池状态、监控慢查询、提供 Druid 监控后台 。
yml
# 声明启用哪些过滤器
filters: stat,wall,slf4j,config
# 手动配置这些过滤器的参数
filter:
stat: 为什么很多项目只写 filter,不写 filters?
因为他们用的是 Spring Boot Starter 自动配置
只要你配了
filter.stat.enabled: true会自动把stat加入filters,如果只配置filters,那么就会生效你配置的内容,并且使用它们默认值。既配
filters,又配filter最规范、最清晰、最保险
(1)是否开启 stat 监控,默认值:true,常用值:true:
yml
filter:
stat:
enabled: true(2)慢 SQL 配置:
log-slow-sql:开启慢SQL 日志,默认值:false,常用值:true。
slow-sql-millis:执行时间超过多少算慢SQL ,默认值:3000,常用值:1000。
slow-sql-log-level:慢SQL 输出的日志级别(DEBUG/INFO/WARN/ERROR),默认值:ERROR,常用值:WARN。。
配置如下:
yml
log-slow-sql: true # 开启慢SQL日志
slow-sql-millis: 1000 # 1秒以上算慢SQL
slow-sql-log-level: WARN # 日志级别(3)SQL 合并统计(推荐开启),默认值:true,常用值:true:
yml
merge-sql: true
select * from t where id=1
select * from t where id=2,合并成一条select * from t where id=?统计,监控面板更干净。
经常用的的stat配置如下:
yml
filter:
stat:
enabled: true # 默认 true
log-slow-sql: true # 默认 false → 建议开
slow-sql-millis: 1000 # 默认 3000 → 建议改1秒
merge-sql: true # 默认 true大部分配置默认值已经是最优的了。
wall:防 SQL 注入:禁止执行危险 SQL (DROP 、TRUNCATE)、拦截非法语句。
(1)基础开关,是否开启 SQL 防火墙,默认值:true,常用值:true。
yml
filter:
wall:
enabled: true下面介绍的都是再filter.wall.config中,用 config 层级清晰区分 "过滤器开关 " 与 "安全规则":
yml
filter:
wall:
enabled: true # 仅开关在 wall 下
config: (2)multi-statement-allow:是否允许一次执行多条 SQL(批量语句),默认值:false,常用值:true。
yml
multi-statement-allow: true项目用到 batch、<foreach> 批量插入时建议设为 true。
(3)增删改查权限(最常用),默认值:true,常用值:true。
yml
select-allow: true # 默认 true 允许查询
insert-allow: true # 默认 true 允许插入
update-allow: true # 默认 true 允许更新
delete-allow: true # 默认 true 允许删除(4)表结构危险操作(默认都禁止,非常安全),默认值:false,常用值:false。
yml
create-table-allow: false # 默认 false 禁止创建表
drop-table-allow: false # 默认 false 禁止删表 ❗高危
alter-table-allow: false # 默认 false 禁止修改表结构
truncate-allow: false # 默认 false 禁止清空表 ❗高危(5)索引操作,默认值:true,常用值:true。
yml
create-index-allow: true # 创建索引,默认 true
drop-index-allow: true # 删除索引,默认 true(6)锁表、存储过程(默认禁止),默认值:false,常用值:false。
yml
lock-table-allow: false # 禁止 lock table
call-allow: false # 禁止 call 存储过程
procedure-allow: false # 禁止创建存储过程(7) SQL 注入防御(核心),默认值:true,常用值:true。
yml
condition-and-always-true-check: true # 检测逻辑与(AND)操作中始终为真的子条件
condition-or-always-true-check: true # 检测逻辑或(OR)操作中始终为真的子条件
condition-on-true-check: true # 识别条件语句中直接使用布尔常量true
condition-constant-equal-check: true # 发现条件中与常量进行的无意义相等比较(8)是否允许 select * 查询,默认值:true,常用值:true。
yml
select-all-column-allow: true # true 运行、false 不允许(9)是否允许 SELECT ... INTO 这种导出数据语句,默认值:false,常用值:false。
yml
select-into-allow: false(10)是否强制所有 SQL 必须使用?占位符,默认值:false,常用值:false。
yml
must-parameterized-query: false # true = 禁止直接拼接 SQL、false = 允许拼接 SQL(MyBatis 正常使用)(11)是否允许 SQL 里写注释,默认值:true,常用值:true。
yml
comment-allow: true(12)是否允许使用 MySQL 危险函数(防注入),默认值:false,常用值:false。
如:sleep ()、load_file ()、database () 等
yml
allow-all-function: false # true 允许,false 不允许(13)单条 SELECT 语句最多返回多少行,默认值:0(不限制),常用值:0。
yml
query-max-row-count: 0 # 0 不限制条数filter.wall的大多数配置都不需要修改使用默认值就行,唯一需要配置一个:
yml
filter:
wall:
config:
multi-statement-allow: true log4j2/slf4j:SQL 日志:输出 SQL 日志、输出连接池日志、输出慢查询日志。用 logback 就用slf4j;用 log4j2 就用log4j2。
配置内容如下:
yml
filters: stat,wall,slf4j,log4j2 # 逗号分隔启用
filter:
slf4j:
enabled: true # 必须显式开启才生效
log4j2:
enabled: true注意:只写
filters=slf4j不够,必须同时设置enabled: true。
绝大多数项目,根本不需要开启 Druid 自带的 slf4j /log4j2,因为 SQL 日志有更好,比如:MyBatis 。比 Druid 的日志更干净、更标准。
config:专门处理配置文件的加密解密、变量替换、远程配置加载等安全与扩展能力。
使用 Druid 提供的 ConfigTools 工具类生成公钥和加密后的密码。执行命令:
bash
java -cp druid-1.2.25.jar com.alibaba.druid.filter.config.ConfigTools [你的密码]该命令会输出生成的 privateKey 和 password。输出示例:
# 仅用于加密,绝不放入配置文件
privateKey: MIICdgIBADANBgkqhkiG9w0BAQEFAASCAmAwggJcAgEAAoGB...
# 放入配置文件,用于运行时解密
publicKey: MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAL...
# 替换配置文件中的明文密码
password: gar1MbijtdJlWY8tcaeEHJ2q12EU1VBTMbz+anqV==...(加密后的密文)启用加密,你的密码使用加密:
yml
spring:
datasource:
url: jdbc:mysql://localhost:3306/test_db?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: gar1MbijtdJlWY8tcaeEHJ2q12EU1VBTMbz+anqVdfV+Csd/iMHIoZwAjBVdJK5XJVQu1eOloTwmYdQDFzNNbQ== # 加密密码
druid:
filters: config # 必须启用 config 过滤器
filter:
config:
enabled: true # 显式开启(默认 true)因为加密方式单一,仅处理 Druid 自身配置,所以很多项目并不会使用该配置。
connection-properties:扩展属性,直接传给连接池、用来控制加密、解密、检测等行为的配置。
给 Druid 底层连接设置附加属性,格式:key=value,多个用 ; 分隔,且必须一行,否则解析失败。
前面我们使用filter.config.enabled开启加密,在运行是需要针对加密密码,进行解密,就需要配置connection-properties,配置如下:
yml
spring:
datasource:
druid:
filters: config
filter:
config:
enabled: true
# 必须一行!不能换行!
connection-properties: config.decrypt=true;config.decrypt.key=[你的私钥]一般都是配合 config 过滤器加密密码才用。
Web 监控配置
Web 监控由WebStatFilter (Web-JDBC 关联统计) 和 StatViewServlet(监控页面)两部分组成:
web-stat-filter.enabled:是否开启 Web 监控过滤器(统计 Web 请求与 SQL 关联),默认值:false,常用值:true。
yml
spring:
datasource:
druid:
web-stat-filter:
enabled: trueweb-stat-filter.url-pattern:监控的 URL 匹配规则,默认值:/*,常用值:/*。
yml
url-pattern: /*web-stat-filter.exclusions:排除监控的 URL(如静态资源),默认值:.js,.gif,.jpg,.css,/druid/*,常用值:/*。
yml
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"stat-view-servlet.enabled:是否开启监控页面 Servlet ,默认值:false,常用值:true。
yml
spring:
datasource:
druid:
stat-view-servlet:
enabled: truestat-view-servlet.url-pattern:监控页面访问路径,默认值:/druid/*,常用值:/druid/*。
yml
url-pattern: /druid/*stat-view-servlet.login-username:监控页面登录账号,默认值:无,常用值:admin。
yml
login-username: adminstat-view-servlet.login-password:监控页面登录密码,默认值:无,常用值:自定义(如 123456)。
yml
login-password: [你的密码]stat-view-servlet.allow:允许访问监控页面的 IP(多个用逗号分隔,0.0.0.0/0允许所有),默认值:127.0.0.1,常用值:192.168.0.0/24(内网)。
yml
allow: 127.0.0.1stat-view-servlet.deny:禁止访问的 IP,默认值:无,常用值:按需配置。
yml
deny: 192.168.0.1reset-enable:是否允许页面上 "重置统计数据" 按钮(生产建议关闭),默认值:false,常用值:false。
yml
reset-enable: falseallow-empty-password:是否允许空密码登录(强烈建议保持默认),默认值:false,常用值:false。
yml
allow-empty-password: false完整配置如下:
yml
# 3. WebStatFilter 配置
web-stat-filter:
enabled: true
url-pattern: /*
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
# 4. StatViewServlet 监控页面配置
stat-view-servlet:
enabled: true
url-pattern: /druid/*
login-username: admin
login-password: Secure@123
allow: 127.0.0.1
reset-enable: false访问地址:http://localhost:8080/druid/index.html,输入 login-username / login-password 登录,如图所示:
可查看:数据源状态、SQL 执行统计、Web 请求统计、Session 统计、SQL 防火墙等
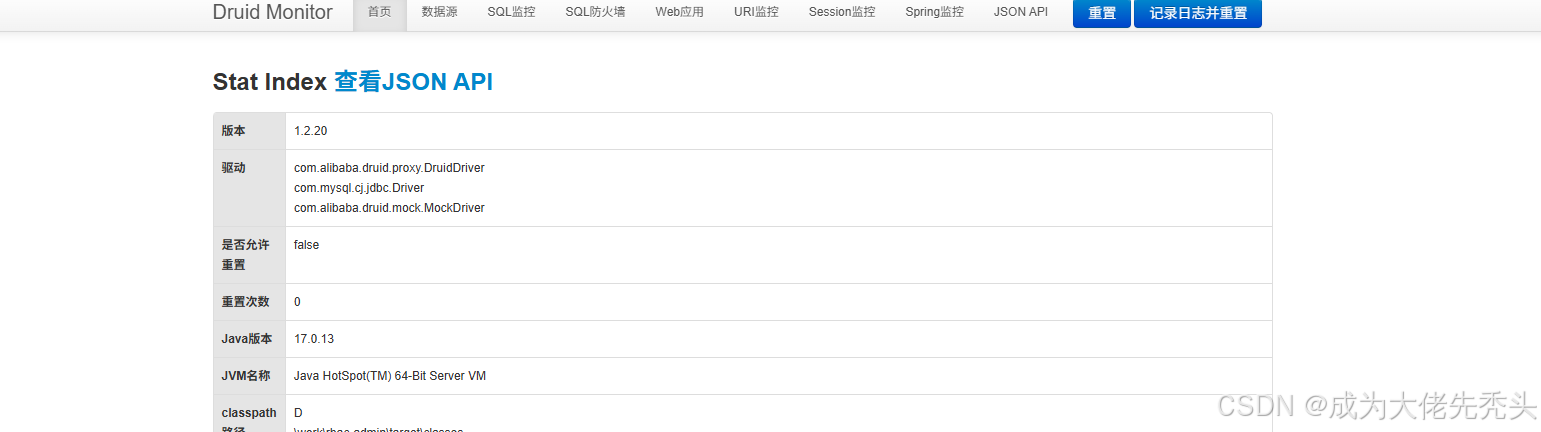
Web 监控只是一个附加调试工具,不是必需项,一般用于学习、本地调试,生产环境基本关闭,相当于把数据库底裤直接露出来。
配置优化建议
- 连接数调优 :
- 单机应用:
max-active建议设为CPU核心数 * 2 + 有效磁盘数(如 8 核 CPU 设为 20); - 微服务集群:每个实例的
max-active不宜过大(如 20-30),避免数据库连接数耗尽。
- 单机应用:
- PSCache :
- 对频繁执行相同 SQL 的场景(如电商订单查询),开启
pool-prepared-statements能大幅提升性能; - 对 SQL 多变的场景(如报表查询),可关闭 PSCache ,避免内存浪费(PSCache 缓存的是固定表名的 SQL 模板,不支持动态表名,每次表名后缀不同,PSCache 会缓存100 个不同的 SQL 模板,大量无用缓存占用内存,反而降低性能,部分连接池会出现缓存污染、SQL 执行错误。分库分表必须关闭 PSCache)。
- 对频繁执行相同 SQL 的场景(如电商订单查询),开启
- 监控配置 :
- 生产环境开启
stat过滤器(SQL 监控)和wall过滤器(防 SQL 注入); - 监控页面建议限制 IP 访问(
allow属性),避免暴露公网。
- 生产环境开启