
Google 在2016年的《Borg, Omega, and Kubernetes》论文总结了他们十年三代容器管理系统的设计与思考。令我感兴趣的是,论文最后留下的真正的开放性问题。因为我多次经历它所描述的问题。
-
• 2020年初,基建团队人数:1,我使用Ansible来部署所有的应用和配置。所有的配置都存储在YAML。在我尽可能的进行抽象后,YAML数量依然难以管理。
-
• 2020年尾,基建团队人数:1,我开始基于VM的Ansible部署,迁移至K8s的Helm部署。配置方面,我只需要将原来的Ansible YAML配置转换成Helm的配置。我开始收获使用代码管理配置的果实。根本不需要把团队搞鸡飞狗跳,我一个人全部就可以搞定。
-
• 2021年,基建团队人数:2,我已经意识到大量的YAML肯定会超过我能管理的复杂程度(事实证明我是正确的,大量的人抱怨YAML的配置地狱)。就开始改成使用Jsonnet来声明所有的配置,同时引入Bazel来管理整个单仓库的构建。
-
• 2021年后,该仓库依然管理着所有的配置,团队人数变成1个人。
可以说,那几年遇到的问题与论文描述的问题完全一致:配置管理系统往往会发明一种领域特定的配置语言。然后这种领域特定语言通常缺少好的开发工具和单元测试框架。
我们"取巧"了,我们不发明配置语言。而选了Jsonnet,基于Jsonnet构建我们自己的配置DSL。并使用Bazel进行构建和执行Jsonnet的单元测试。同时,我们也知道尽可能做到计算与数据分离,来减小配置复杂性。放在通用语言中,意思就是尽可能少用元编程和类型体操。正如论文所说的:
We believe the most effective approach is to accept this need, embrace the inevitability of programmatic configuration, and maintain a clean separation between computation and data.
我们认为最有效的方法是接受这一需求,拥抱程序化配置的必然性,并保持计算与数据之间的清晰分离。
论文中的以下观点,我非常赞同:
It doesn't reduce operational complexity or make the configurations easier to debug or change
它并没有降低运维复杂性或使配置更容易调试和修改
运维复杂性属于核心复杂性,不论何种配置领域特定语言表达,还是使用GUI系统来配置,它都是客观存在的。就像不论使用什么编程语言,电商领域中的扣费逻辑的复杂性都是存在的。
那么"运维复杂性"具体在哪里呢?我认为运维复杂性在于依赖管理。你可能知道构建的本质是依赖管理,但是你可能想不到运维的复杂性的本质也是依赖管理。
论文提到的:
实例化依赖项很少像启动一个新副本那么简单------例如,它可能需要注册为现有服务的消费者(如 Bigtable 即服务),并在这些传递性依赖之间传递认证、授权和计费信息。
在GUI上点击一个按钮,服务器上就多了一个新副本,这看起来是很简单。但是,如果你深入到问题里面,你会发现,它并不简单。你可能需要:
-
- 检查机器容量是否充足
-
- 新副本的连接的数据库的连接数是否足以支持新的连接数
-
- 新副本的连接的Redis的连接数是否足以支持新的连接数
-
- 检查是否需要特定的配置,比如Zookeeper扩容一个实例,需要配置该实例的zid,zid的值需要全Zookeeper集群唯一
不论你是使用GUI,还是使用Jsonnet来配置,你都需要回答以上问题。而以上问题,只是我简单列举的,现实往往有更多问题。
我认为,这些问题的背后就是依赖管理。当依赖不完整、不可见、不可计算时,就无法简单地知道一个变更所带来的影响。
论文中提到的依赖管理的难题,也正是行业里经常遇到问题:如果依赖信息依赖手动提供,就很难保持更新。即人工管理依赖的窘境。
想想那些通过人工维护的CMDB系统的处境。也有通过agent进行自动发现依赖的CMDB系统,但是效果不尽如人意。
所以,如何自动的进行依赖管理呢?
这也是我这些年尝试解决的问题。
我的逻辑非常简单:当你使用Jsonnet来定义配置时,这些配置里天然就把依赖关系说得清清楚楚了。
配置中编码了大量隐式的依赖关系
比如一个Order service使用HTTP调用了Inventory Service,Order service的Env配置就可以写成:
-
•
INVENTORY_HOST: http://$.inventoryService.host -
•
ORDER_DB_HOST: resources.db.orderdb.host
我们需要做的就是将这些依赖关系抽取出来。以下是将依赖抽取出来后的效果:
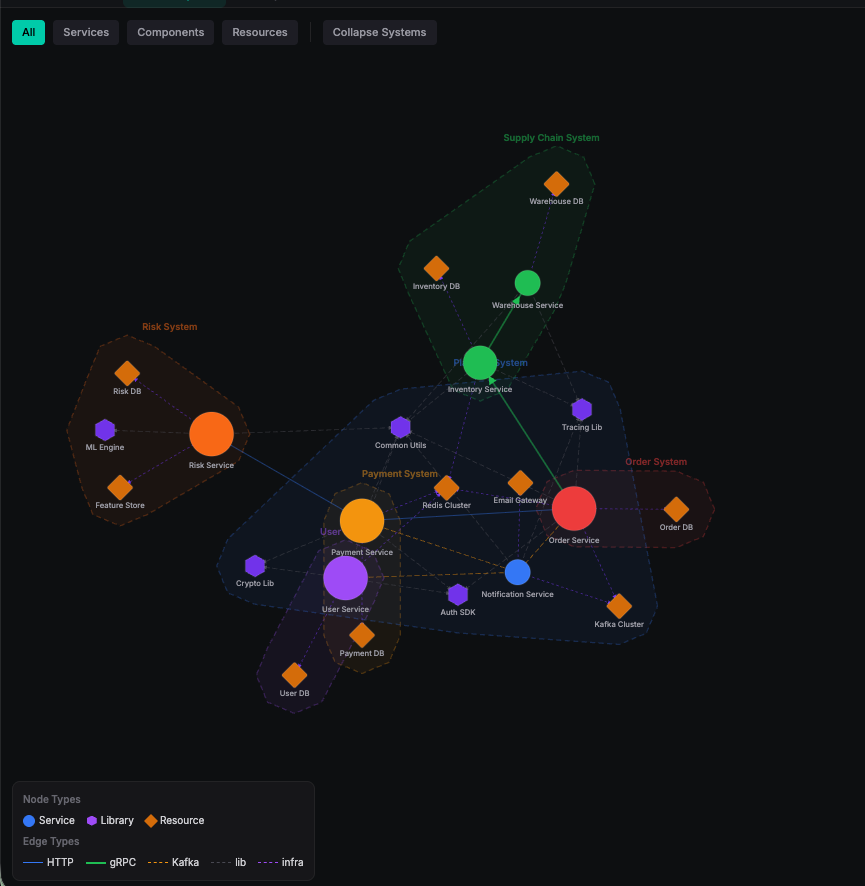
当然,通过IaC的管理所有的配置和依赖关系也会带来新的问题:
-
- 开发人员对这整套机制的接受程度
-
- 配置语言的规范的设计,以及如何设计依赖分析工具,比如我们正在实现从Jsonnet配置中自动分析依赖关系
-
- IaC生态在中国的接受程度不高
-
- Secret的管理问题
论文在2016年说这是"一个开放挑战",10年过去了,现在依然是。
其它文章推荐: