【PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】】https://www.bilibili.com/video/BV1hE411t7RN?vd_source=7c2b5de7032bf3907543a7675013ce3a
Pytorch环境的配置及安装:
anaconda安装:
首先安装anaconda,安装了anaconda就包含了很多包,包括python
下载python和其对应的anaconda
显卡:起到训练加速的作用
驱动+cuda包
管理环境:
当需要什么版本和环境时,就进入已经创建的环境
通过anaconda prompt来创建环境

python
conda create -n pytorch python=3.6激活环境:

python
conda activate pytorchpytorch安装:
使用1.1之后的版本,1.1之后pytorch加入了tensorboard,可以看到一些训练中的数据和一些损失函数的变化,对训练有很大的帮助
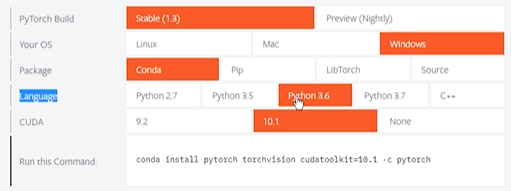

安装后可以使用下方代码浏览已经下载好的包
python
pip list使用import torch 看是否下载成功

使用torch.cuda.is_available()查看gpu能否成功使用

Python编辑器的选择:
pycharm:
pycharm下载将在官网上安装,可直接下载社区版

可以选择已有的环境

jupyter:
从ipython(可交互式)引申出的工具
默认安装在base环境下,如何解决:在pytorch环境下安装jupyter或在jupyter环境下安装pytorch
pytorch工具包:
dir():打开
python
dir(torch)
dir(torch.cuda)
dir(torch.cuda.is_available)help():说明书
python
help(torch.cuda.is_available)python文件:pytyhon文件的块是所有行的代码
优:通用,传播方便,适用于大型项目
缺:需要从头运行
python控制台:以任意行为块运行的
优:显示每个变量属性
缺:不利于代码阅读及修改
jupyter:以任意行为块运行
优:利用代码阅读及修改
缺:环境需要配置
Pytorch数据:
定义:
dataset:数据,对零散的数据进行编号,可以为后续网络提供编号进行读取,提供label;提供一种方式去获取数据及其label;如何获取每一个数据及其label;告诉我们总共有多少的数据
python
from torch.utils.data import Datasetdataloader:对数据集进行打包,数据不是一个一个进入,而是以打包的形式;为网络提供给不同的数据形式
如何操作:
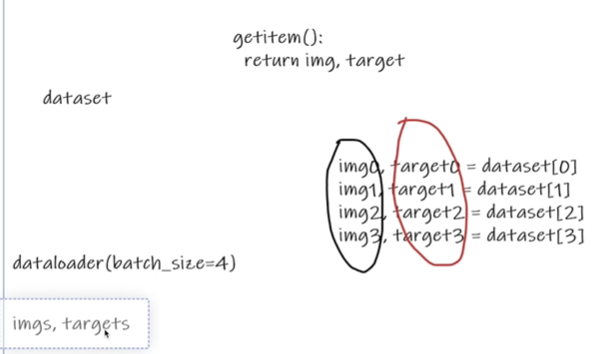
python
for data in test_loader:
imgs,targets = dataTensorboard使用:
通过端口设置可以在web界面打开

python
# 记录图像
writer.add_image()
# 记录标量数值
writer.add_scalar()Transforms使用:
transforms结构及用法:
transforms.py工具箱,包含很多工具,如totensor、resize
针对特定格式的图片,经过工具后输出一个想要的结果(图片变换)
tensor数据类型:张量,简单理解就是多维数组的泛化
python
tool = trasforms.ToTensor()
result = tool(input)为什么需要tensor数据类型:
连接数据 、模型 和硬件加速的桥梁,没有它现代深度学习无法高效运转
常见的函数:关注输入和输出类型,多关注官方文档,关注方法需要什么参数
python
# 将多个变换串联起来,按顺序执行
Compose()
# 将 PIL Image 或 NumPy 数组 → PyTorch Tensor
ToTensor()
# 将数据标准化,加速模型收敛
Normalize(mean, std)
# 将 Tensor → PIL Image(可视化或保存用)
ToPILImage()数据集和transform结合:
自带的一些数据集,可以直接导入

新建训练集和测试集:
python
train_set = torchvision.datasets.CIFAR10(root="路径",train = True, download = True)
test_set = torchvision.datasets.CIFAR10(root="路径",train = False, download = True)常用功能:
python
# 浏览数据集的数据
print(test_set[0])
# 浏览数据集类型
print(test_set.classes)
# 浏览target
print(test_set.classes[target])
# 浏览图片
img.show()与transforms联动使用时,图片需要转化为tensor类型
python
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()])
test_set = torchvision.datasets.CIFAR10(root="路径",train = False, transform = dataset_transform, download = True)网络搭建:
NN:neural network
python
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1,0)
output = tudui(x)
print(output)卷积操作:
nn.Conv2d:
卷积核在输入图像上走格子,按照对应的格子和格子相乘然后相加

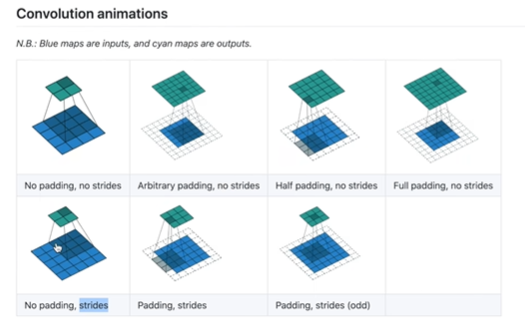
stride:控制卷积核走几步,横向和纵向移动的stride都是设定值
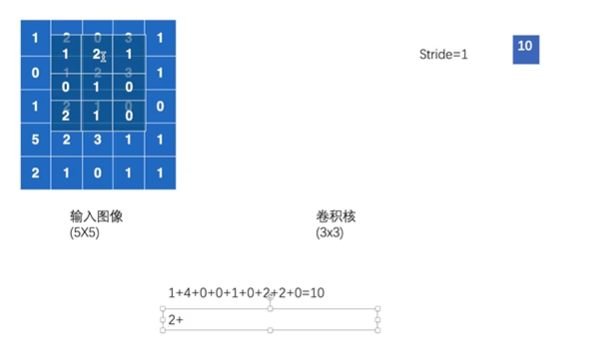
python
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
# 步长
output = F.conv2d(input, kernel, stride = 1)
output = F.conv2d(input, kernel, stride = 2)padding:决定填充的大小,默认不填充
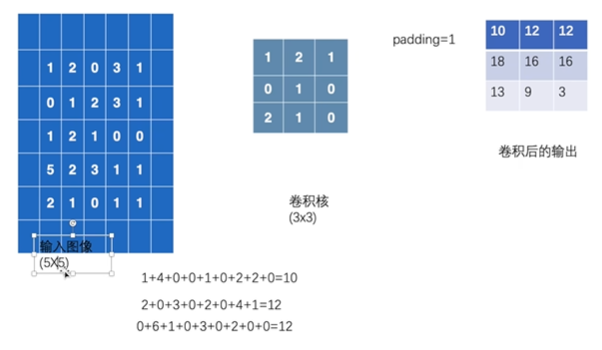
python
output3 = F.conv2d(input, kernel, stride = 1, padding = 1)神经网络:
卷积层:
定义:卷积层是通过可学习的局部卷积核进行权值共享的线性变换层,用于提取局部特征并映射到新的特征空间。
作用:提取局部特征 + 调整通道数 + 可能改变空间尺寸

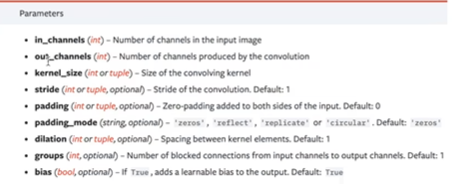
in_channels:输入图像尺寸
out_channels:输出图像尺寸
padding:填充大小
kernel_size:卷积核大小
python
dataset = torchvision.datasets.CIFAR10("../data", train = False, transform=torchvision.transforms.ToTensor(), download = True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels =3,out_channels = 6, kernel_size = 3, stride = 1, padding = 0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
for data in dataloader:
imgs, targets = data
output = tudui(imgs)关键公式:

池化层:
定义:对特征图进行下采样 的运算层,用局部区域的统计值(最大/平均等)代替整个区域。
作用:降采样 + 提取主要特征+ 增强鲁棒性
最大池化一般是保留卷积核覆盖的数字的最大值
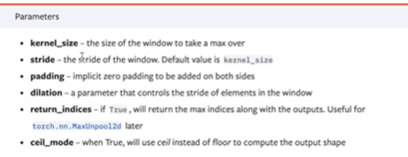
stride:默认值是卷积核的大小
ceil floor:floor向下取整,ceil向上取整
python
# 保留
ceil_model = True
# 不保留
ceil_model = False
python
# 最大池化层
import torch
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
torch.reshape(input, (-1, 1, 5, 5))
print(input.sahpe)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode = True)
def forward(self, input):
output = self.maxpool(input)
return output
tudui = Tudui()
output = tudui(input)
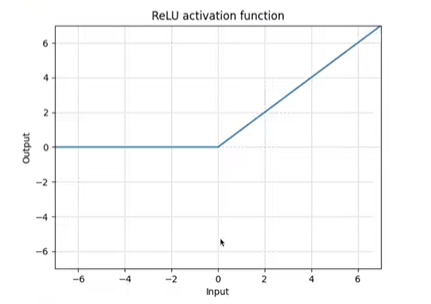
print(output)非线性激活:
定义:对输入进行非线性变换的神经网络层,引入非线性因素,使网络能够学习复杂模式。
作用:给网络引入非线性能力,使其能学习复杂模式,是深度网络的核心组件。
ReLU:输入是n是batchsize
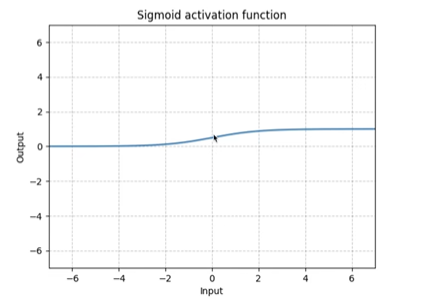
sigmoid:
python
import torch
input = torch.tensor([[1, -0.5],
[-1, 3]])
output = torch.reshape(input, (-1, 1, 2, 2))
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
def forward(self, input):
output = self.relu(input)
return output
tudui = Tudui()
output = tudui(input)线性层及其它层:
正则化层:用到的比较少
Recurrent 层:rnn,lstm用于文字识别中,特定的网络结构,用到不太多
transformer层:特定网络结构中使用
线性层:

定义:对输入进行线性操作
作用:全局特征变换 + 维度映射 + 最终决策
python
import torchvision
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196600, 10)
def forward(self, input):
output = self.linear1(input)
return output
for data in dataloader:
imgs, targets = data
# output = torch.reshape(imgs, (1, 1, 1, -1))
output = torch.flatten(imgs)
output = tudui(output)dropout层:在训练中随机将一些输入元素变成"0",概率为"p",主要用于防止过拟合
sparse层:特定网络,有用到时再关注
sequential:
损失函数和反向传播:
1.计算实际输出和目标之间的差距
2.为我们更新输出提供一定的依据(反向传播)
Loss值越小越好
python
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 3], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# L1损失
loss = L1Loss(reduction = 'sum')
result = loss(inputs, targets)
# MSE损失
loss_mse = nn.MSELoss()
result_mse = loss(inputs, targets)
# 交叉熵损失
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss
result_cross = loss_cross(inputs, targets)优化器:
不同的优化器模型学习参数和速率是不同的
params:模型参数
lr:学习速率

python
optim = torch.optim.SCG(tudui.parameters(), lr=0.01)
for data in dataloader:
...
optim.zero_grad()
result_loss.backward()
optim.step()
...
模型训练套路:
常见的保存方式:
python
# 保存方式1 保存模型结构+模型参数
torch.save(vgg16, "vgg16_method.pth")
# 方式1的加载模型
model = torch.load("vgg16_method.pth")
# 保存方式2 保存模型参数(官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
# 方式2的加载模型
model = torch.load("vgg16_method2.pth")完整的训练套路:
python
import torchvision
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# length长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 利用dataloader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.01
# learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
print("训练次数:{}, Loss: {}".format(total_train_step, loss))
搭建神经网络:
python
# 搭建神经网络 例子为10分类网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x