打破"像素级"扫描瓶颈:聚类驱动的4K图像恢复新范式 (解读 Scan Clusters, Not Pixels)
在图像恢复(Image Restoration)领域,如何在获得全局感受野的同时保持计算的高效性,始终是一个核心难题。从早期的卷积神经网络(CNN)到近年的视觉Transformer(ViT),算力与精度的博弈从未停止。最近,状态空间模型(State Space Models, SSMs,如Mamba)凭借其线性的计算复杂度(O(N)O(N)O(N))备受瞩目。
然而,面对超高清(Ultra-High-Definition, UHD,如4K)图像,即便复杂度降至O(N)O(N)O(N),像素级的串行扫描依然会导致显存溢出(OOM)和难以承受的计算负担。现有的妥协方案,如多尺度下采样或分块处理,往往会以牺牲全局上下文或产生边界伪影为代价。
2026年2月,挂在arxiv的论文《Scan Clusters, Not Pixels: A Cluster-Centric Paradigm for Efficient Ultra-high-definition Image Restoration》提出了一种具有启发性的破局思路:既然自然图像存在大量的语义冗余(如大面积相似的天空或墙壁),我们是否可以放弃对每一个像素的逐一扫描,转而聚焦于少数几个"聚类中心"?
本文将深入拆解这篇论文的核心模块------C2C^2C2SSM(Cluster-Centric State Space Model),探讨其如何通过概率分布建模实现算力与精度的双重突破,并分析该架构在实际工程部署中可能面临的挑战。
一、 从"像素级"到"聚类级"的范式转换
在探讨具体模型前,我们先理解该论文的出发点。传统的Mamba模型(如VSSM)将图像展平为一维序列,然后逐像素进行状态空间方程的迭代。对于包含超过800万像素的4K图像,这种操作极其昂贵。图 1是现有基于Mamba的方法(全像素扫描)与本文提出的聚类扫描策略(Cluster-Centric Scanning)在扫描路径和计算量上的直观对比。
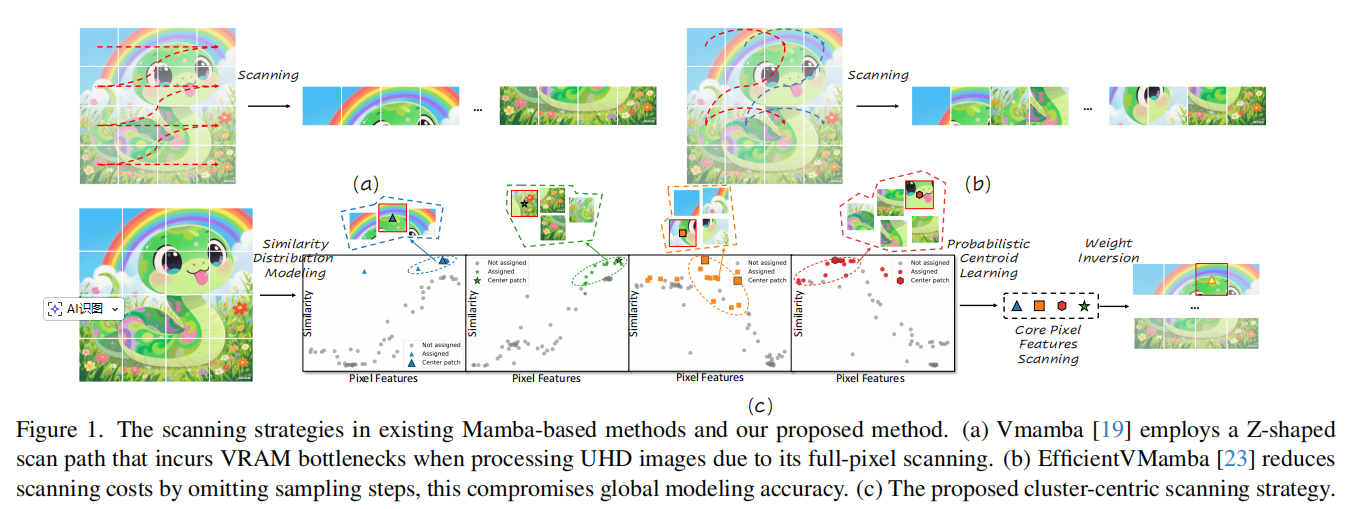
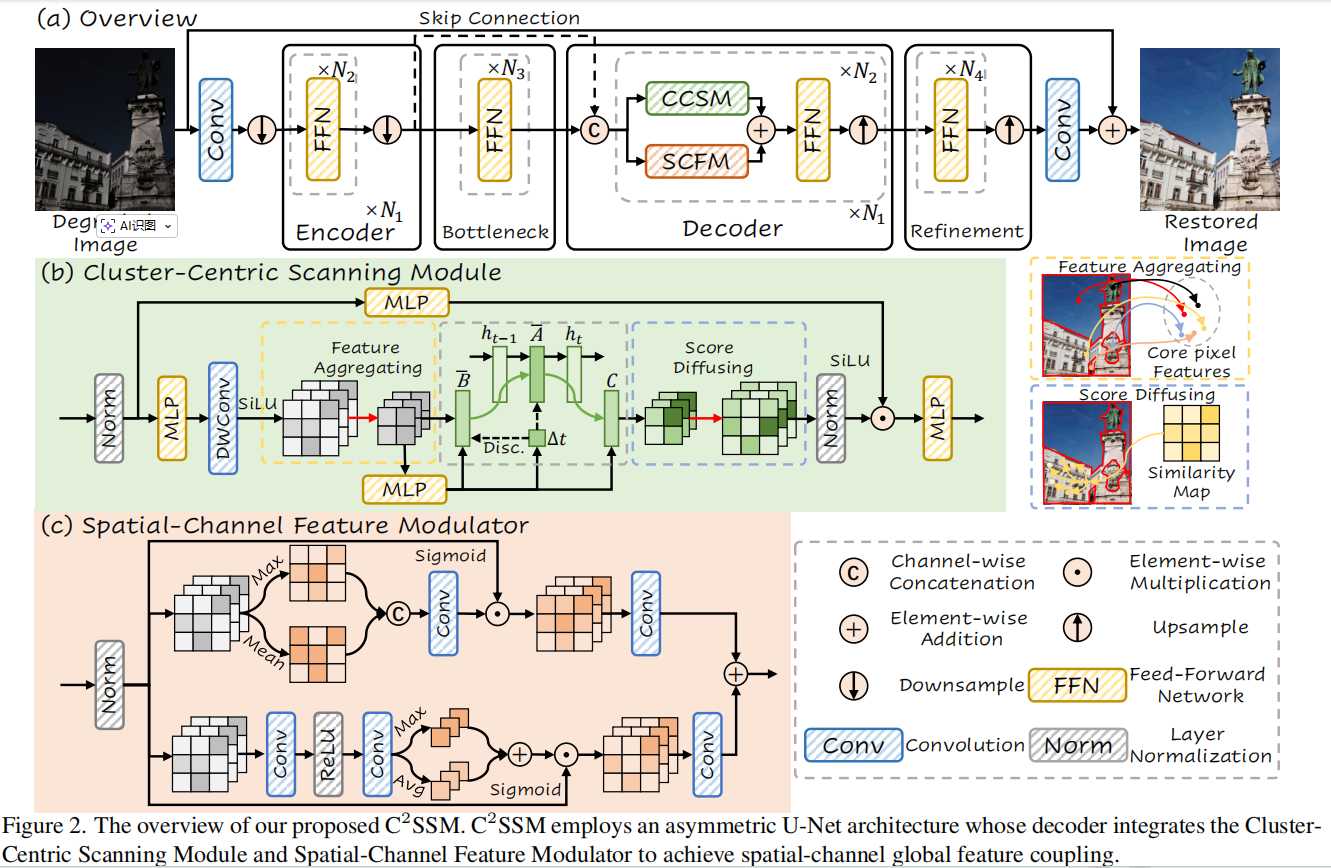
该论文的核心观察是:在特征空间中,许多像素的特征是高度趋同的。因此,可以通过聚类将这800万个像素浓缩为nnn个(实验中通常为4个)代表性的语义中心。如果Mamba只去处理这几个中心点,计算复杂度将从令人望而生畏的 O(C⋅H2W2)O(C \cdot H^2W^2)O(C⋅H2W2) 骤降至微不足道的 O(C⋅n2)O(C \cdot n^2)O(C⋅n2)。为了实现这一设想,作者在解码器中设计了两个并行的核心模块:聚类中心扫描模块(CCSM)和空间-通道特征调制器(SCFM)。
二、 CCSM模块拆解:概率驱动的全局推理("代表大会"机制)
CCSM(Cluster-Centric Scanning Module)是实现低复杂度全局建模的关键。它的运行机制并非传统的K-Means硬聚类,而是一个基于概率分布的软聚合与反演过程。我们可以将其分为三个阶段:
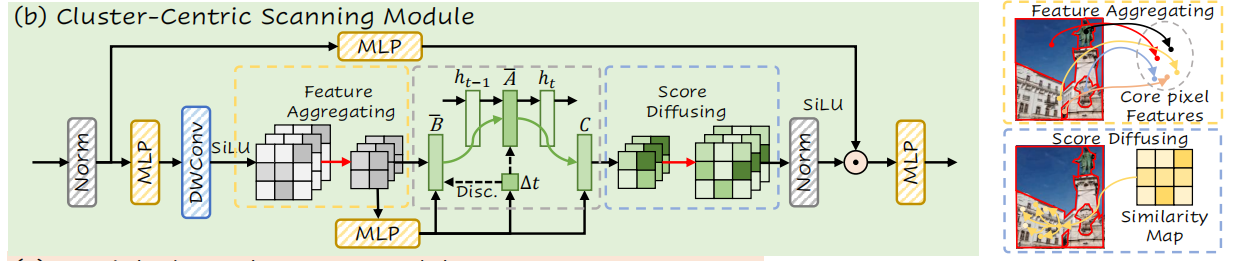
1. 特征聚合(Feature Aggregating):寻找语义代表
首先需要在特征空间中确定nnn个初始中心。为了增强这些中心的代表性和抗噪能力,模型在随机采样位置后,会计算其K近邻(K-nearest neighbor)特征的聚合值作为初始锚点。这使得初始中心不仅代表孤立的像素,更能反映局部区域的平均属性。
随后,模型计算全图所有像素与这nnn个初始中心的余弦相似度,构建出一个nnn维的相似度分布。最精妙的一步在于"中心微调(Centroid Refinement)":通过一个带有可学习参数(α,β\alpha, \betaα,β)的门控激活函数,网络能够自适应地将高相似度的像素特征加权融合到中心点上。这一机制使得中心点在端到端的训练中,自动演化为高度纯化的语义代表。
2. 核心扫描(Core Pixel Features Scanning):轻量级的全局交互(开大会)
在提取出nnn个微调后的中心后,模型仅将这nnn个中心 送入Mamba的核心S6模块。此时,Mamba的任务不再是扫描整张图像,而是捕捉这nnn个宏观语义(如"天空"中心与"建筑"中心)之间的长程依赖关系。这一步输出了带有全局上下文信息的权重矩阵WWW。
3. 权重反演(Weight Inversion):将全局信息还原至像素(下达精神)
Mamba仅输出了nnn个中心的权重,如何将这些信息赋予全图的数百万个像素?作者引入了统计学中的"全概率公式"。
利用第一阶段构建的相似度分布,通过带有温度参数的Softmax函数,计算出每个像素严格归属于各个中心的分配概率(即后验概率)。随后,根据全概率公式,计算每个像素的最终全局权重------即nnn个中心权重在其对应分配概率下的数学期望。
三、 SCFM模块:高频细节的补偿机制
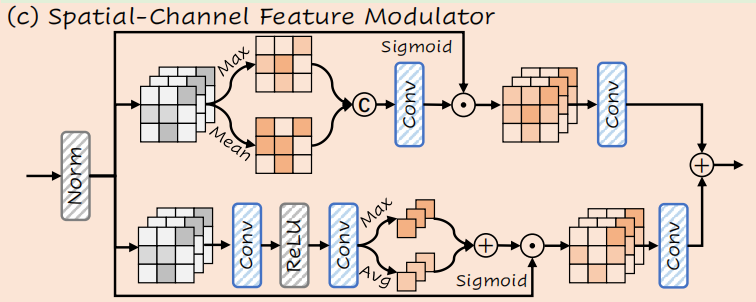
聚类本质上是一种低秩近似(Low-rank approximation),它能够有效捕捉宏观大趋势(低频信息),但不可避免地会抹平局部的细微纹理和锐利边缘(高频信息)。如果仅依靠CCSM,恢复出的图像可能会显得平滑且缺乏质感。
为了解决这一信息瓶颈,论文设计了空间-通道特征调制器(SCFM),并使其与CCSM的权重反演阶段完全并联运行。
SCFM采用经典的双分支注意力机制,借鉴了CBAM:
- 空间注意力分支: 沿着通道维度进行最大池化和平均池化,定位图像中响应强烈的突变点,生成空间权重图,以此引导网络关注高频纹理的位置。
- 通道注意力分支: 沿着空间维度进行特征压缩,生成通道权重向量,强化那些对高频细节敏感的特定通道。
通过SCFM的局部CNN操作,模型有效地补偿了在聚类过程中丢失的微观保真度。CCSM负责"大局观",SCFM负责"抠细节",两者相加,最终输出高质量的恢复图像。
四、 实验表现与工程视角的审视
在五项4K图像恢复任务(暗光增强、去雨、去模糊、去雾、去雪)的测试中,C2SSM展现了极具竞争力的表现。在极低的FLOPs(浮点运算次数)下,其客观评价指标(如PSNR、SSIM)显著超越了现有的基于CNN、Transformer以及其他Mamba变体的模型。
如果从工程部署方面审视论文,仍需关注几个潜在的工程隐患:
- "低FLOPs"与"高内存带宽(Memory Bound)"的悖论: 虽然CCSM在Mamba扫描阶段省下了巨量的计算,但在第一阶段计算余弦相似度和第三阶段进行Softmax加权反演时,模型依然需要进行全分辨率尺寸的张量点乘运算。对于4K图像,此类操作极其消耗GPU的内存读写带宽。这可能导致模型在理论算力需求极低的情况下,实际的推理延迟(Latency)仍受制于访存速度。
- 初始中心采样的稳定性: 初始中心点基于随机采样生成。对于特征分布极其复杂的真实世界4K图像,如果随机选取的点未能均匀覆盖各个关键频段(例如全都落在平缓区域),可能会导致高频区域的聚类分配失真。尽管网络包含可学习的自适应微调机制,但在连续视频帧的处理中,这种随机性仍有可能引发一定程度的闪烁。
- 并联CNN模块的算力占比: 为了弥补高频信息的丢失,并联的SCFM模块内部包含了全分辨率的卷积操作。在4K级别下,即便是一个基础的3×3卷积,其计算量和显存占用也不容小觑。这也意味着,该模型在实际运行中,相当一部分算力开销被分配给了辅助性的CNN特征提取。
小结
本文通过显式的概率分布建模,将"像素级的穷举扫描"转换为"基于语义锚点的聚类抽象",为超高分辨率图像的长程依赖建模提供了一条全新的路径。
尽管其在大规模部署时的访存效率和细节极限还原能力还有待进一步的工业检验,但这种"将复杂视觉问题转化为概率推理"的设计哲学,无疑为未来的高效基础模型研究提供了极具价值的参考。