👨⚕️ 主页: gis分享者
👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅!
👨⚕️ 收录于专栏:AI大模型原理和应用面试题

文章目录
- [一、🍀OpenClaw 核心组件详解](#一、🍀OpenClaw 核心组件详解)
-
- [1.1 ☘️入口层:Channels 通道适配器 & 自动化触发器](#1.1 ☘️入口层:Channels 通道适配器 & 自动化触发器)
- [1.2 ☘️控制平面:Gateway 网关(系统核心中枢)](#1.2 ☘️控制平面:Gateway 网关(系统核心中枢))
- [1.3 ☘️执行平面:Agent Runtime 智能体运行时(系统大脑)](#1.3 ☘️执行平面:Agent Runtime 智能体运行时(系统大脑))
- [1.4 ☘️能力层:Providers 模型适配层 & Tools 工具系统](#1.4 ☘️能力层:Providers 模型适配层 & Tools 工具系统)
- [1.5 ☘️数据层:Persistence & Memory 持久化与记忆系统](#1.5 ☘️数据层:Persistence & Memory 持久化与记忆系统)
- 二、🍀核心组件之间的关系
-
- [2.1 ☘️层级架构关系:自上而下的依赖与自下而上的反馈](#2.1 ☘️层级架构关系:自上而下的依赖与自下而上的反馈)
- [2.2 ☘️核心协同关系:以 Gateway 为核心的星型协同架构](#2.2 ☘️核心协同关系:以 Gateway 为核心的星型协同架构)
- [2.3 ☘️端到端完整执行链路:一次用户指令的全组件协同](#2.3 ☘️端到端完整执行链路:一次用户指令的全组件协同)
- [2.4 ☘️解耦设计的核心优势](#2.4 ☘️解耦设计的核心优势)
- 三、🍀追问
一、🍀OpenClaw 核心组件详解
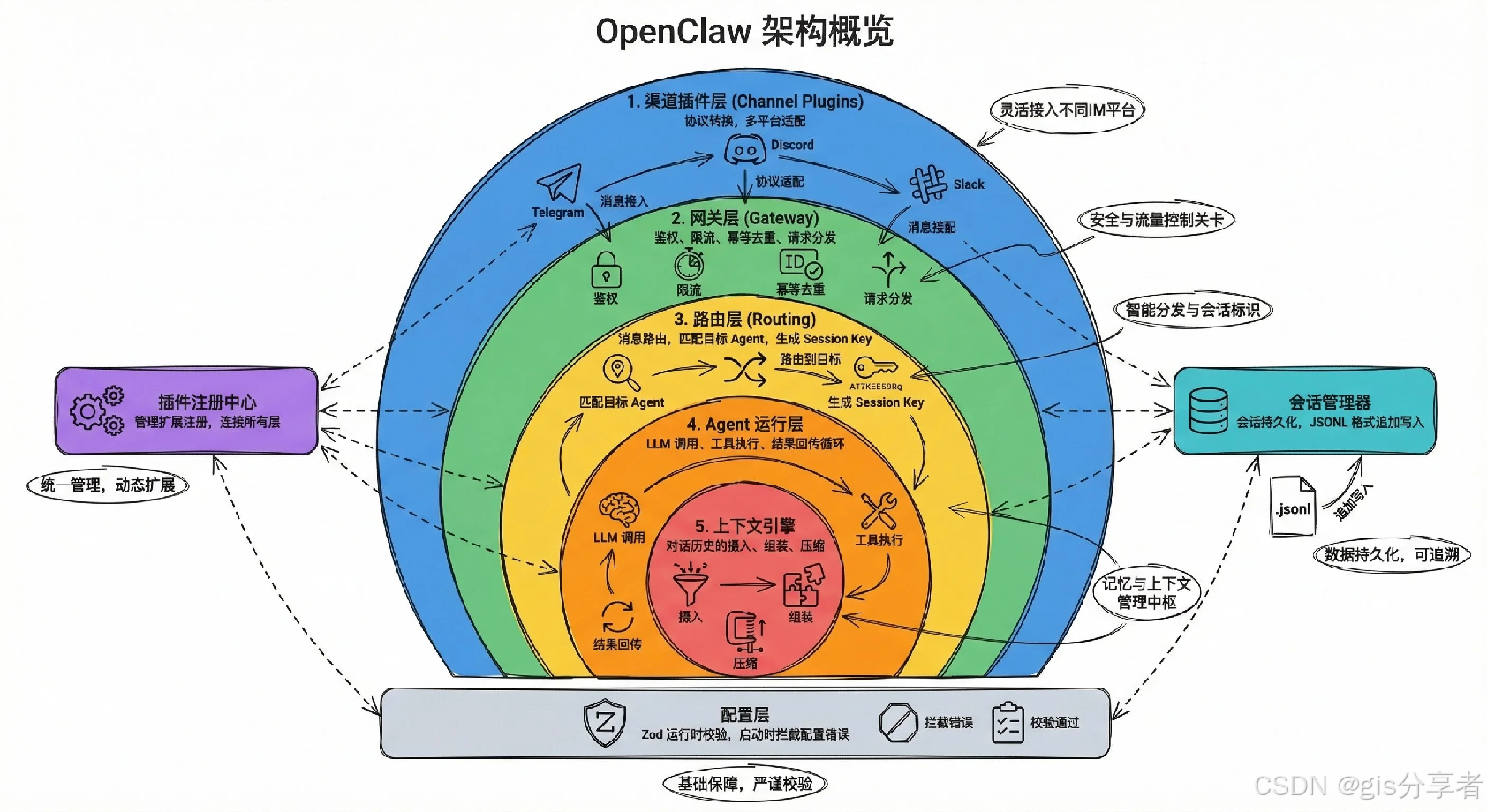
OpenClaw 采用分层解耦的架构设计,官方定义了从入口到数据的五层核心架构,核心组件可按职责划分为五大核心模块,各模块职责单一、可独立扩展,同时通过标准化协议完成协同,共同实现自然语言指令到任务执行的端到端闭环。
1.1 ☘️入口层:Channels 通道适配器 & 自动化触发器
定位: 用户与系统交互的统一入口,是所有指令的「起点」,也是最终结果的「出口」,核心目标是抹平多渠道的协议与格式差异。
核心子组件:
- Channels 通道适配器: 原生支持 Telegram、Discord、飞书、钉钉、WhatsApp 等 50+ 主流 IM 平台,每个平台对应独立的适配器,实现不同平台消息协议与 OpenClaw 内部标准化消息格式的双向转换。
- 自动化触发器: 包括 Cron 定时任务、Webhook 事件触发器、Heartbeat 心跳值守模块,支持非用户主动触发的自动化任务执行(如定时报表、异常监控告警)。
核心职责: 将所有外部输入(用户消息、定时事件、第三方回调)统一收敛为标准化的内部消息上下文,同时将 Agent 的执行结果原路返回给对应渠道,实现「一次部署,全平台可用」。
1.2 ☘️控制平面:Gateway 网关(系统核心中枢)
定位: OpenClaw 的核心常驻 Node.js 进程,是整个系统的「交通枢纽与调度中心」,也是所有组件协同的唯一核心纽带,是 OpenClaw 架构的绝对核心。
核心职责:
- 生命周期管理:维护与所有 Channels、Providers、Agent 实例的长连接与运行生命周期,保障各组件的稳定运行。
- 统一鉴权与安全边界:处理所有请求的 token 鉴权、访问权限控制,定义远程访问、跨设备调用的安全边界。
- 路由与会话管理:通过 sessionKey 实现消息的精准路由与分桶,决定不同来源的消息归属的会话与 Agent
实例,避免多会话「串线」。 - 并发与队列调度:基于 Lane 队列机制实现「同会话串行、跨会话并行」,避免会话串扰与任务冲突,同时管理任务优先级与重试策略。
- 状态广播与事件分发:暴露 WebSocket/HTTP API,处理内部事件的广播与分发,对接 Control
UI、第三方系统的观测与控制需求。
1.3 ☘️执行平面:Agent Runtime 智能体运行时(系统大脑)
定位: OpenClaw 的决策与执行核心,是实现 AI 自主思考、任务规划、流程闭环的「大脑」,严格遵循 ReAct「思考-行动」循环范式。
核心子组件:
- Agent Loop 执行循环: 核心执行引擎,驱动完整的「意图理解→任务拆解→工具调用→结果校验→回复生成」全流程循环。
- 上下文构建器(Context Builder): 动态整合用户指令、会话历史、系统提示词、可用工具描述、记忆数据,生成符合模型要求的完整
Prompt。 - 任务编排与纠错模块: 负责将用户的自然语言指令拆解为可执行的多步骤任务,同时处理执行过程中的异常、重试、动态路径调整。
- 流式输出控制器: 负责执行过程中的实时状态反馈、中间结果流式推送,保障用户能实时看到任务执行进度。
核心职责: 接收 Gateway 路由的任务,完成智能决策与任务全流程执行,是实现「一句话交付结果」的核心模块。
1.4 ☘️能力层:Providers 模型适配层 & Tools 工具系统
定位: 为 Agent Runtime 提供「思考的算力」与「行动的手脚」,是 Agent 能力边界的核心载体,直接决定了 AI 的推理上限与执行范围。
两大核心子模块:
- Providers 模型适配层(算力提供者)
- 定位:Agent Runtime 与大语言模型之间的桥梁,是 OpenClaw「模型无关」设计的核心支撑。
- 核心职责:统一封装所有主流 LLM 的 API 接口,兼容 OpenAI
GPT、Claude、Gemini、国产大模型、本地开源模型;实现模型自动降级、故障转移、负载均衡,保障推理服务的高可用;将 Agent
的上下文请求转换为对应模型的标准格式,同时将模型的输出解析为 Agent 可执行的结构化指令。
- Tools 工具系统(执行手脚)
- 定位:定位:将大模型的文本决策转化为真实系统操作的执行单元,是打通「能说」到「能做」的核心。
- 核心职责:内置 75+ 原生工具,覆盖 Shell 命令执行、文件读写、浏览器自动化、API 调用、向量检索、消息发送等全场景操作;基于沙箱机制实现工具执行的安全隔离与权限控制;支持自定义 Skill 插件的动态注册、热重载,无限扩展执行能力;负责工具执行的结果采集、异常捕获,将执行结果反馈给 Agent Runtime。
1.5 ☘️数据层:Persistence & Memory 持久化与记忆系统
定位: 系统的「数据底座」,负责所有状态、会话、记忆、日志的持久化存储与检索,保障系统状态可追溯、可延续。
核心子组件:
- 会话存储(Sessions): 持久化所有会话的历史消息、执行记录、全链路追踪数据,实现跨会话的上下文延续。
- **记忆系统(Memory): **基于向量检索引擎实现长程记忆的存储与精准召回,解决 Agent
长任务「健忘」问题;支持工作区隔离、记忆编辑与管理,保障不同任务的记忆互不干扰。 - 配置管理(Config): 加密存储所有渠道凭证、模型 API 密钥、系统配置、Agent
人格与规则文件(SOUL.md、AGENTS.md 等)。 - 审计与日志系统: 全链路记录系统运行日志、工具执行记录、模型调用日志,支持全流程可追溯、可审计,同时为故障排查提供数据支撑。
核心职责: 为整个系统提供数据持久化能力,保障系统重启后状态不丢失,同时为 Agent 的决策提供历史上下文与记忆支撑。
二、🍀核心组件之间的关系
2.1 ☘️层级架构关系:自上而下的依赖与自下而上的反馈
OpenClaw 的五大核心组件呈严格的分层架构,上层组件依赖下层组件的能力,下层组件为上层组件提供核心支撑,同时执行结果自下而上逐层反馈,形成完整的业务闭环:
- 入口层是最外层,仅负责与外部交互,所有输入必须向下传递给 Gateway 网关,无法直接对接其他核心组件;
- Gateway 网关是架构的核心中枢,承上启下,是唯一能与所有其他组件直接交互的模块,所有组件之间的跨层通信都必须经过 Gateway
中转; - Agent Runtime 执行平面是核心逻辑层,向上接收 Gateway 分发的任务,向下依赖能力层的 Providers
获取推理能力、依赖 Tools 获取执行能力,同时向数据层读写会话与记忆数据; - 能力层是执行与算力支撑层,为 Agent Runtime 提供核心能力,无法主动发起任务,仅能响应 Agent Runtime
的调用请求; - 数据层是最底层的底座,为所有上层组件提供数据持久化与检索能力,所有组件的状态、配置、日志都会持久化到数据层,同时上层组件可按需从数据层读取对应数据。
2.2 ☘️核心协同关系:以 Gateway 为核心的星型协同架构
所有组件以 Gateway 网关为核心,形成星型协同结构,而非简单的线性串联,各组件的核心协同链路如下:
- 入口层 ↔ Gateway: 双向强绑定,入口层仅与 Gateway 通信,将所有外部输入标准化后传递给 Gateway,同时接收
Gateway 回传的执行结果,发送给对应用户/渠道; - Gateway ↔ Agent Runtime: 核心调度链路,Gateway 将路由后的任务分发给对应的 Agent Runtime
实例,同时管控 Agent 的并发、生命周期、状态广播,Agent Runtime 将执行进度、最终结果回传给 Gateway; - Agent Runtime ↔ 能力层: 决策-执行闭环链路,Agent Runtime 向 Providers
发起推理请求,获取模型的决策输出;基于模型的决策,向 Tools 发起执行调用,获取工具执行结果,形成「思考-行动」的 ReAct
循环; - 全组件 ↔ 数据层: 全局数据读写链路,Gateway 的会话配置、Agent 的执行记录、Providers 的模型调用日志、Tools
的执行日志、入口层的消息记录,全部持久化到数据层,同时各组件可按需从数据层读取对应的配置、历史、记忆数据; - 能力层 ↔ Gateway: 状态与故障管理链路,Providers 与 Tools 的运行状态、可用性、故障信息,都会同步给
Gateway,Gateway 可基于这些信息实现故障转移、流量调度、权限管控。
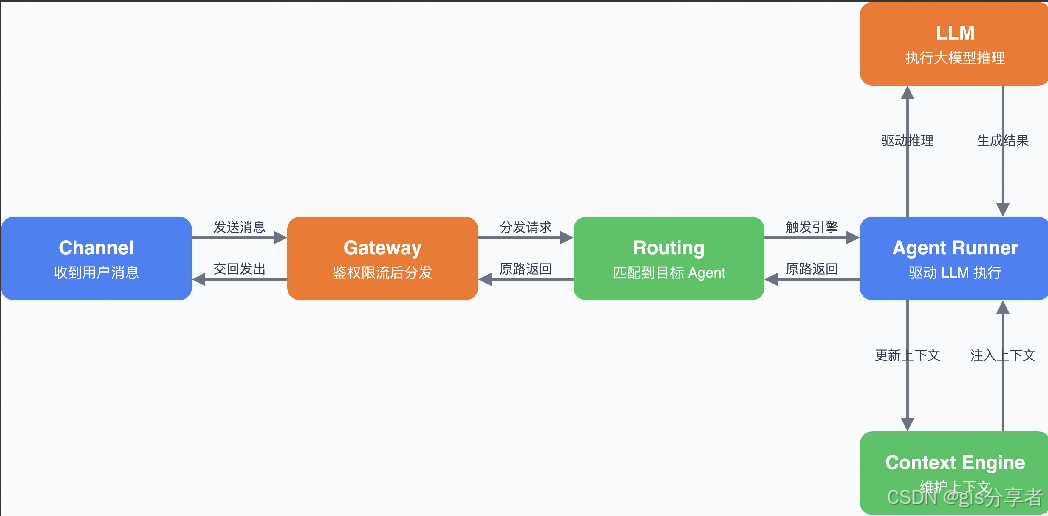
2.3 ☘️端到端完整执行链路:一次用户指令的全组件协同
通过一次完整的用户指令执行,可清晰直观地看到各组件的协同关系:
-
指令输入:用户在 Telegram/飞书等渠道发送自然语言指令,对应 Channel 适配器接收消息,将其转换为 OpenClaw内部标准化的消息格式,传递给 Gateway 网关;
-
路由与调度:Gateway 基于消息来源生成 sessionKey,完成鉴权后,将消息放入对应会话的 Lane队列,按串行规则分发给对应的 Agent Runtime 实例;
-
上下文构建与推理:Agent Runtime 的上下文构建器从数据层拉取该会话的历史记录、系统提示词、可用工具描述、用户记忆,拼接成完整Prompt,调用能力层的 Providers,将 Prompt 发送给指定的大语言模型,获取模型的推理与决策结果;
-
工具调用与执行:Agent Runtime 解析模型的决策,若需要执行操作,则调用能力层的 Tools
工具系统,在沙箱环境中执行对应的系统操作/浏览器自动化/API 调用等,捕获执行结果,回传给 Agent Runtime;
-
循环迭代与结果生成:Agent Runtime 基于工具执行结果,再次调用 Providers
进行推理校验,判断任务是否完成,若未完成则重复「推理-工具调用」的 ReAct 循环,直至任务完成,生成最终的结果回复;
-
结果回传与持久化:Agent Runtime 将最终结果回传给 Gateway,Gateway 将结果路由给对应的 Channel适配器,由适配器转换为对应平台的消息格式,发送给用户;同时,本次任务的全链路数据全部持久化到数据层,更新会话历史与记忆系统,为后续任务提供上下文支撑。
2.4 ☘️解耦设计的核心优势
这种分层解耦的架构,让各组件可独立扩展、替换,无需改动核心系统:
- 新增 IM 渠道,仅需开发对应的 Channel 适配器,无需修改 Gateway、Agent 等核心组件;
- 更换大模型,仅需在 Providers 中新增配置,无需修改 Agent 执行逻辑;
- 新增自定义能力,仅需开发对应的 Tool 插件,无需改动 OpenClaw 核心代码。
三、🍀追问
提问:如果要给 OpenClaw 新增一个微信渠道,大概要改哪些地方?
回答:只需要在 Channel 层新增一个微信插件,实现消息收发的协议转换接口就行,核心就是把微信的 XML 消息格式转成 OpenClaw 内部的统一消息结构,再把回复转回微信格式。Gateway 往下的所有组件都不用动,这就是分层的好处。具体来说需要实现 ChannelPlugin 接口(定义在 src/channels/plugins/types.plugin.ts),它采用 adapter 模式,按能力拆分为 messaging(消息收发)、outbound(外发)、streaming(流式输出)、gateway(网关集成)等多个适配器,按需实现即可。
提问:Context Engine 说可以插拔替换,那默认实现和自定义实现的边界在哪?
回答:src/context-engine/types.ts 里定义了接口契约,核心就三件事:摄入新消息(ingest)、组装 Prompt 上下文(assemble)、压缩历史记录(compact)。默认的 legacy.ts 实现比较直白:ingest 是 no-op(消息持久化由 SessionManager 负责),assemble 直接透传消息列表,compact 委托给 compaction 模块做 LLM 摘要压缩。如果业务需要更复杂的策略,比如按语义相关性检索历史、或者接入向量数据库做 RAG,只要实现同一套接口,在配置里切换就行。
提问:Agent Runner 的执行循环什么时候终止?有没有防死循环的机制?
回答:Agent Runner 每次循环就是调 LLM 拿到响应,如果响应里包含工具调用就去执行工具,把结果喂回 LLM 继续下一轮。终止条件是 LLM 返回纯文本回复、不再请求调用工具。防死循环靠多层保护:执行超时时间、工具循环检测(tool-loop-detection.ts 内置多种检测策略:generic_repeat 检测连续调同一工具同一参数、ping_pong 检测两个工具交替调用、known_poll_no_progress 检测轮询无进展、global_circuit_breaker 全局断路器兜底)、以及 context overflow 时的自动 compaction 和降级。超过限制就强制终止,返回一个兜底回复。
提问:Gateway 的幂等去重是怎么做的?
回答:消息平台经常会重复推送同一条消息,比如 Telegram 的 Webhook 超时重试。Gateway 拿到每条消息后会提取一个唯一标识,在本地缓存里做去重判断,如果已经处理过就直接丢弃。这样下游组件压根不用关心重复消息的问题,鉴权和去重全在入口收敛掉了。