一、章节介绍
本节围绕Apache ZooKeeper官方核心文档展开,系统讲解这款开源分布式协调服务的定位、设计理念、数据模型、核心机制、集群架构、性能特性与落地价值。ZooKeeper是解决分布式系统协作难题的基础组件,可规避分布式场景下竞争条件、死锁等常见问题,依托轻量化数据结构与强一致性保障,支撑各类高阶分布式功能开发。课程聚焦原理与实战结合,贴合开发架构设计、工程落地及面试高频考察场景,帮助学习者吃透底层逻辑与应用要点。
| 核心知识点 | 面试频率 |
|---|---|
| ZooKeeper定位与设计目标 | 高 |
| ZNode数据模型与节点分类 | 高 |
| Watch监听机制原理 | 高 |
| 五大一致性保障特性 | 高 |
| 集群架构(领导者/跟随者) | 高 |
| 读写流程与同步协议 | 中 |
| 性能特点与适用场景 | 中 |
| 生产落地应用场景 | 中 |

二、知识点详解
1. ZooKeeper基础定位与设计目标
- 核心定义:开源分布式协调服务,专为分布式应用提供同步、配置管理、服务命名、集群成员管理能力。
- 解决痛点:原生自研分布式协调极易出现竞态条件、死锁,ZooKeeper封装底层复杂逻辑,降低开发成本。
- 四大设计核心:
- 极简架构:类文件系统树形结构,数据常驻内存,实现高吞吐、低延迟;
- 集群复制:多节点部署,过半节点可用则服务不宕机,杜绝单点故障;
- 全局有序:所有事务分配全局唯一序号,支撑分布式锁、队列等同步原语;
- 读优性能:适配10:1读写比例的主流协调场景,读请求极速响应。
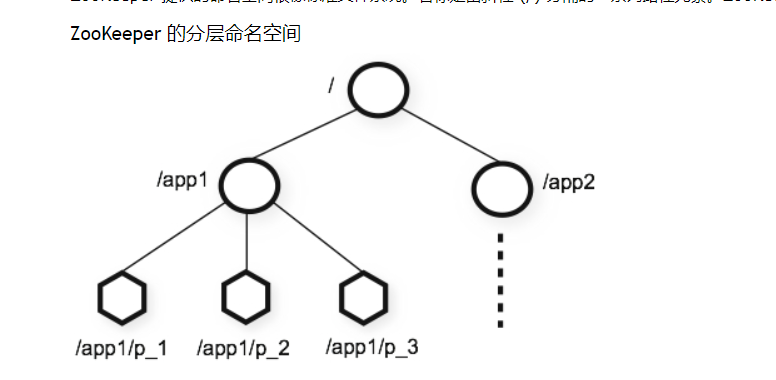
2. 数据模型与ZNode节点详解
- 分层命名空间:采用
/分隔路径,全路径唯一标识节点,贴合开发者熟悉的文件系统逻辑。 - ZNode核心特性:
- 兼具文件+目录属性:节点可存少量协调数据(字节~KB级),同时可挂载子节点;
- 版本管控:自带stat结构体,包含数据版本、时间戳,实现乐观锁,保障并发更新安全;
- 权限隔离:集成ACL访问控制列表,精细化管控节点读写权限。
- 关键节点分类:
- 持久节点:创建后永久存储,手动删除才会销毁,用于存固定配置;
- 临时节点:绑定客户端会话,会话失效(断开/超时)自动删除,常用于服务注册、临时选主。
3. Watch监听机制
- 基础原理:客户端可给节点注册监听,节点数据/子节点变更时,主动推送事件通知,触发后单次失效;
- 版本升级:3.6.0新增永久递归监听,支持持续监控当前节点及所有子节点变更,无需重复注册;
- 实战价值:实现配置热更新、服务上下线感知、分布式事件通知。
4. 五大核心一致性保障(面试高频)
- 顺序一致性:客户端请求严格按发送顺序执行;
- 原子性:更新操作全成功或全回滚,无中间状态;
- 单系统映像:客户端切换集群节点,看到的数据视图完全一致,无旧数据;
- 可靠性:数据更新生效后,永久保留,直至主动覆盖修改;
- 及时性:集群数据同步有时效保障,客户端不会长期读取过期数据。
5. 极简API与核心操作
官方仅提供7类基础操作,轻量化易集成:
- create:创建节点;delete:删除节点;exists:判断节点是否存在;
- get data:读取节点数据;set data:修改节点数据;
- get children:获取子节点列表;sync:强制数据同步,确保读取最新数据。
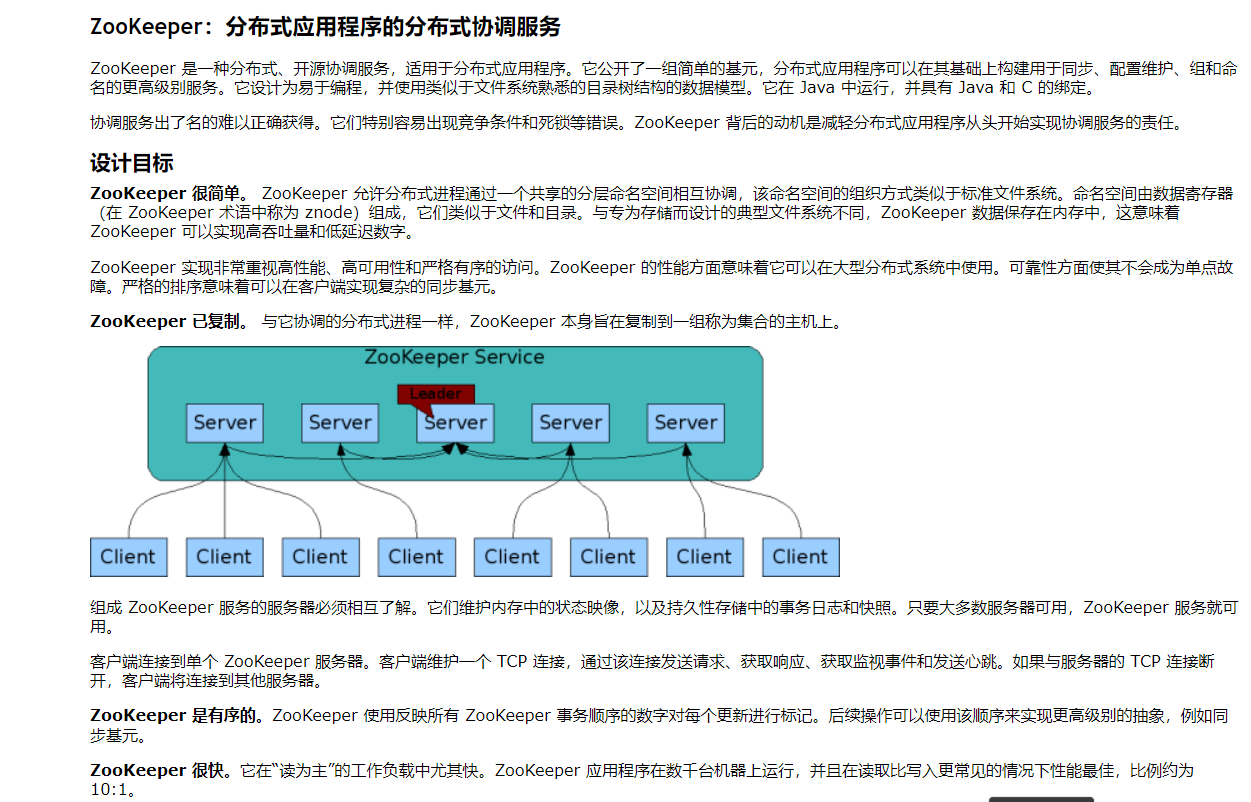
6. 集群架构与读写实现
- 角色划分:
- 领导者(Leader):统一处理所有写请求,发起事务投票,同步全局数据;
- 跟随者(Follower):处理读请求,同步Leader数据,参与领导者选举;
- 存储机制:全量数据存入内存,事务日志、快照落地磁盘,故障可快速恢复;
- 读写流程:读请求本地节点直接响应,高并发高效;写请求统一转发Leader,通过原子广播协议同步至全集群,保障一致性。
7. 性能与可靠性
- 性能优势:读多写少场景性能极强,3.2版本较旧版性能翻倍;
- 故障容错:领导者选举耗时低于200ms,节点宕机、重启不影响核心服务,故障恢复后自动扩容吞吐量。
三、章节总结
- ZooKeeper本质是分布式协调中间件,核心优势是强一致性、高可用、轻量化,聚焦解决分布式协作难题;
- 树形ZNode数据模型+临时节点+Watch监听,是实现配置中心、服务注册、分布式锁的三大核心支撑;
- 集群采用主从架构,读写分离设计,兼顾一致性与高性能,适配大规模分布式集群;
- 严格的五大事务保障,奠定了复杂分布式同步逻辑的底层基础;
- 广泛应用于大数据组件(Hadoop/Kafka)、微服务架构,是分布式开发的必备基础组件。
四、知识点补充
1. 拓展补充知识点
- 领导者选举:基于ZAB原子广播协议,保障选举过程数据不丢失、不一致;
- 会话机制:客户端与服务端长连接维系会话,心跳检测判断会话有效性,关联临时节点生命周期;
- 快照与事务日志:定期生成快照固化全量数据,事务日志记录增量操作,加速故障恢复;
- 观察者节点(Observer):无投票权,仅同步数据、处理读请求,用于扩容集群读能力,不影响选举效率;
- ZAB协议:ZooKeeper核心一致性协议,替代Paxos,兼顾效率与可靠性,支持崩溃恢复。
2. 生产最佳实践(300字+)
在企业生产环境中,ZooKeeper集群部署必须遵循奇数节点原则,推荐3节点、5节点架构,保障过半投票机制生效,避免脑裂问题。严格隔离读写压力,核心业务写操作控制频次,利用Observer节点承接海量读请求,提升集群并发能力。数据存储层面,务必将事务日志与系统磁盘、快照磁盘物理分离,避免IO争抢导致延迟增高;定期清理过期快照与日志,防止磁盘溢出。配置调优上,合理设置会话超时时间,避免网络抖动导致临时节点误删;关键配置节点启用ACL权限管控,防止误操作篡改核心数据。监控体系需全覆盖:节点存活状态、会话连接数、watch事件堆积、事务吞吐量、磁盘IO,异常告警及时触发。同时禁止在ZNode存储大数据,严格控制数据大小在KB级,贴合组件设计初衷,保障集群低延迟、高稳定运行。
3. 编程思想指导(300字+)
学习ZooKeeper核心要建立「分布式状态统一」的编程思维,摒弃单机开发的数据独享逻辑,所有协作逻辑都要依托全局共享的ZNode状态实现。首先,理解轻量化设计思想:ZooKeeper不做海量数据存储,只聚焦协调元数据,开发中要拆分业务数据与协调数据,各司其职,不滥用节点存储业务大文件。其次,强化乐观锁思维,依托ZNode版本号实现并发更新控制,替代传统悲观锁,适配分布式高并发场景,减少锁等待阻塞。再者,建立事件驱动思维,基于Watch监听实现解耦开发,服务间无需轮询探活、拉取配置,通过事件推送实现实时感知,降低系统开销。同时,树立容错设计思维,开发代码时必须处理节点宕机、连接断开、会话过期、监听失效等异常,做好重试机制与降级兜底。最后,遵循极简依赖思想,基于原生API封装通用工具类(分布式锁、配置读取、服务注册),复用基础能力,避免重复造轮子,提升分布式系统开发效率与稳定性。
五、程序员面试题(含答案)
1. 简单题
题目:简述ZooKeeper的核心作用?
答案:ZooKeeper是Apache开源的分布式协调中间件,主要为分布式应用提供配置管理、服务注册与发现、分布式锁、集群选主、事件监听、数据同步等能力,解决分布式系统中竞态条件、死锁、数据不一致等协作难题,依靠强一致性、高可用特性,保障集群稳定运行。
2. 中等题1
题目:ZooKeeper临时节点和持久节点的区别?
答案:①生命周期:持久节点永久存在,手动删除才销毁;临时节点绑定客户端会话,会话超时/断开自动删除;②使用场景:持久节点存固定配置、基础元数据;临时节点用于服务注册、动态选主、临时任务标记;③权限管控:两者均支持ACL权限控制;④数据存储:均存储小体量协调数据,不支持大数据存储。
3. 中等题2
题目:ZooKeeper五大一致性保障分别是什么?
答案:①顺序一致性:客户端请求按发送顺序执行;②原子性:更新操作要么全成功,要么全失败;③单系统映像:客户端切换集群节点,数据视图一致;④可靠性:数据更新生效后永久保留,直至主动修改;⑤及时性:集群数据同步有时效,不会长期读取过期数据。
4. 高难度题1
题目:讲解ZooKeeper集群读写流程,为什么读快写慢?
答案:读流程:客户端连接任意节点,读请求直接读取当前节点内存数据,无需集群同步,响应极速;写流程:所有写请求转发Leader节点,Leader生成事务,通过ZAB协议投票,过半Follower确认后,再同步数据至全集群,提交生效。读快是因为本地化读取、无集群协商;写慢是因为必须保证全集群数据一致性,需要投票、同步、确认多步操作,牺牲部分写入性能,换取强一致性,贴合读多写少的协调场景。
5. 高难度题2
题目:Watch监听有什么特性?生产使用有哪些注意事项?
答案:核心特性:①一次性触发:基础监听触发后自动销毁,需重新注册;②3.6.0支持永久递归监听,可持续监控多级子节点;③事件异步推送,客户端被动接收变更通知。生产注意事项:①监听仅推送变更事件,不返回详细数据,需主动拉取最新数据;②网络抖动易导致监听丢失,关键业务需定时轮询兜底;③避免大量监听注册,防止集群事件堆积、性能下降;④递归监听慎用,子节点过多会触发海量事件,加重客户端压力。
ZooKeeper 深度问答
基础认知篇
Q1:为什么分布式系统非要用 ZooKeeper,自己写代码协调不行吗?
A:你可以试着自己写------多台服务抢任务、注册上线、同步配置,一定会遇到竞态条件、死锁、节点感知不一致、脑裂 问题。原生网络不可靠,心跳、重试、数据同步、时序排序极难拿捏。ZooKeeper 把十几年踩坑沉淀的强一致性、时序有序、事件通知、集群容错封装成极简能力,让开发者只关心业务,不用重复造极易出错的协调轮子。
Q2:ZooKeeper 明明能存数据,为什么官方强调只存小数据?
A:它底层设计是全量数据放内存,追求低延迟、高吞吐。如果存大文件、业务大数据,内存爆掉、快照膨胀、同步变慢,整个集群都会卡顿。它定位是「协调元数据管家」,不是数据库/对象存储,各司其职才稳定。
数据模型 & ZNode 篇
Q3:ZooKeeper 的树形节点,和普通文件目录有本质区别吗?
A:有。普通目录只负责归档,ZNode 既是文件又是目录;自带版本号、事务序号、ACL权限;所有修改全局有序、原子生效。它不是用来存文件的目录,是用来做「分布式状态标记」的结构化共享内存。
Q4:临时节点为什么跟着会话走,断开就删?设计初衷是什么?
A:核心是自动探活。服务注册、主从选主、临时抢占资源,最怕服务挂了还留旧数据,造成脏数据、死锁。会话+临时节点,天然实现:服务宕机→会话失效→节点自动清理,不用人工删、不用轮询判活。
Q5:ZNode 的版本号有什么用?不加版本直接改数据不行吗?
A:不行,会并发覆盖。版本号是分布式乐观锁:你改数据必须带当前版本,别人中途改了版本就变了,你的写入直接失败。避免多人同时修改把数据互相覆盖,解决并发争抢安全问题。
Watch 监听机制篇
Q6:Watch 为什么默认是一次性触发,而不是永久监听?
A:为了性能与容错。如果默认永久监听,集群几万节点、几万客户端堆积事件,会拖垮推送、挤占内存、引发风暴。一次性倒逼开发者:收到变更→拉新数据→重新注册监听,流程可控、压力可控。
Q7:3.6.0 新增递归永久 Watch,是不是可以无脑随便用?
A:绝对不能。递归会监听当前节点+所有子孙节点,子节点频繁新增删除,会疯狂推送事件,客户端被轰炸、网络打满。只适合固定层级、变更极少的核心配置场景。
一致性 & 核心保障篇
Q8:ZooKeeper 凭什么敢保证多节点看到的数据一模一样?
A:靠两大核心:①全局事务有序编号,所有修改串行化;②写统一走Leader+ZAB协议,过半节点确认才生效,再同步全集群。哪怕客户端切连接、换服务器,永远看不到旧快照,保证单一系统视图。
Q9:顺序一致性、原子性这些保障,实际开发能落地感受到吗?
A:能。比如做分布式锁:创建临时节点抢锁,谁先创建成功谁拿到锁;依靠有序性杜绝插队,依靠原子性杜绝锁分裂,依靠可靠性保证锁状态不丢。没有这五层保障,分布式锁根本不敢上生产。
集群架构 & 读写原理篇
Q10:为什么读能超快,写却明显慢?背后公平吗?
A:公平,是取舍。读直接查本地内存,不用集群协商,所以秒回;写必须全员共识、投票、同步,牺牲写入速度,换全局强一致。ZooKeeper本身就是为「读多写少」的协调场景设计,贴合绝大多数分布式业务。
Q11:Leader 挂了业务会崩吗?200ms 选举背后藏着什么逻辑?
A:不会崩。集群自动快速选举新Leader,耗时极低;选举期间Follower依旧能提供读服务,只暂停写入一小会儿。设计目的:故障无感、吞吐量不掉底,保证高可用不成为系统短板。
Q12:Observer 节点存在的意义是什么,直接加 Follower 不行吗?
A:Follower要参与投票、影响选举效率;Observer只同步数据、扛读流量,不参与表决。业务读压力爆炸时,加Observer横向扩容读能力,又不破坏集群投票稳定性,性价比极高。
实战落地 & 编程思想篇
Q13:做微服务注册、配置中心,用 ZooKeeper 核心靠哪几个能力?
A:三样必杀技:临时节点做服务上下线自动剔除、Watch做配置热更新、有序节点做主从负载/序号编排。组合起来就能实现轻量级注册中心+配置中心。
Q14:学习 ZooKeeper,最该转变什么编程思维?
A:丢掉单机「内存变量独占」思维,建立全局共享状态+事件驱动+容错兜底 思维:
所有协作不靠硬编码轮询,靠节点状态变更通知;所有并发不靠悲观锁,靠版本乐观控制;所有服务上下线不靠人工维护,靠会话自动回收。
高阶反思篇
Q15:现在有 Nacos、Etcd,为什么大厂还保留 ZooKeeper?
A:第一,大数据生态(Hadoop/Kafka/Hive)深度绑定,换不动;第二,ZAB协议+时序强有序,做选主、分布式锁、队列极度稳;第三,成熟老旧系统多年验证,容错、故障恢复极其靠谱,稳定性优先场景不敢轻易替换。