AtomicInteger 是干什么的?
它是 Java 提供的、线程安全的整数工具类 ,专门用来解决多线程同时修改同一个数字时,数据出错的问题。
意思就是加锁的count
// 1. 创建一个原子整数,初始值 0
AtomicInteger count = new AtomicInteger(0);
// 2. 线程安全地 +1 count.incrementAndGet();
// 3. 线程安全地 -1 count.decrementAndGet();
// 4. 获取当前值 int now = count.get();
引入webscoket需要的配置类:
java
@Configuration
public class WebSocketConfig
{
@Bean
public ServerEndpointExporter serverEndpointExporter()
{
return new ServerEndpointExporter();
}
}多例模式:
java
package com.ruoyi.far.websocket;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Service;
import javax.websocket.*;
import javax.websocket.server.PathParam;
import javax.websocket.server.ServerEndpoint;
import java.io.IOException;
import java.util.HashSet;
import java.util.concurrent.CopyOnWriteArraySet;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @描述 WebSocket核心配置类
* @创建人 haoqian
* @创建时间 2021/5/20
*/
/**
* @ServerEndpoint 注解是一个类层次的注解,它的功能主要是将目前的类定义成一个websocket服务器端,
* 注解的值将被用于监听用户连接的终端访问URL地址,客户端可以通过这个URL来连接到WebSocket服务器端。
*/
@Component
@Slf4j
@Service
@ServerEndpoint("/api/websocket/{sid}")
public class WebSocketServer {
//静态变量,用来记录当前在线连接数。应该把它设计成线程安全的。
private static AtomicInteger onlineCount = new AtomicInteger(0);
//concurrent包的线程安全Set,用来存放每个客户端对应的WebSocket对象。
private static CopyOnWriteArraySet<WebSocketServer> webSocketSet = new CopyOnWriteArraySet<>();
//与某个客户端的连接会话,需要通过它来给客户端发送数据
private Session session;
//接收sid
private String sid = "";
/**
* 连接建立成功调用的方法
*/
@OnOpen
public void onOpen(Session session, @PathParam("sid") String sid) {
this.session = session;
webSocketSet.add(this); // 加入set中
this.sid = sid;
addOnlineCount(); // 在线数加1
try {
sendMessage("conn_success");
log.info("有新客户端开始监听,sid=" + sid + ",当前在线人数为:" + getOnlineCount());
} catch (IOException e) {
log.error("websocket IO Exception");
}
}
/**
* 连接关闭调用的方法
*/
@OnClose
public void onClose() {
webSocketSet.remove(this); // 从set中删除
subOnlineCount(); // 在线数减1
// 断开连接情况下,更新主板占用情况为释放
log.info("释放的sid=" + sid + "的客户端");
releaseResource();
}
private void releaseResource() {
// 这里写释放资源和要处理的业务
log.info("有一连接关闭!当前在线人数为" + getOnlineCount());
}
/**
* 收到客户端消息后调用的方法
*
* @Param message 客户端发送过来的消息
*/
@OnMessage
public void onMessage(String message, Session session) {
log.info("收到来自客户端 sid=" + sid + " 的信息:" + message);
// 群发消息
HashSet<String> sids = new HashSet<>();
for (WebSocketServer item : webSocketSet) {
sids.add(item.sid);
}
sendMessage("客户端 " + this.sid + "发布消息:" + message, sids);
}
/**
* 发生错误回调
*/
@OnError
public void onError(Session session, Throwable error) {
log.error(session.getBasicRemote() + "客户端发生错误");
error.printStackTrace();
}
/**
* 群发自定义消息
*/
public static void sendMessage(String message, HashSet<String> toSids) {
// log.info("推送消息到客户端 " + toSids + ",推送内容:" + message);
for (WebSocketServer item : webSocketSet) {
try {
//这里可以设定只推送给传入的sid,为null则全部推送
if (toSids.size() <= 0) {
item.sendMessage(message);
} else if (toSids.contains(item.sid)) {
item.sendMessage(message);
}
} catch (IOException e) {
continue;
}
}
}
/**
* 实现服务器主动推送消息到 指定客户端
*/
public void sendMessage(String message) throws IOException {
this.session.getBasicRemote().sendText(message);
}
/**
* 获取当前在线人数
*
* @return
*/
public static int getOnlineCount() {
return onlineCount.get();
}
/**
* 当前在线人数 +1
*
* @return
*/
public static void addOnlineCount() {
onlineCount.getAndIncrement();
}
/**
* 当前在线人数 -1
*
* @return
*/
public static void subOnlineCount() {
onlineCount.getAndDecrement();
}
/**
* 获取当前在线客户端对应的WebSocket对象
*
* @return
*/
public static CopyOnWriteArraySet<WebSocketServer> getWebSocketSet() {
return webSocketSet;
}
}乐观锁插件 https://baomidou.com/guide/interceptor-optimistic-locker.html我用**最直白、面试能直接说、工作能听懂**的方式,给你重新讲这 3 个 MyBatis-Plus 插件的**作用 + 场景**,不绕弯子。 --- # 1. 分页插件 PaginationInnerInterceptor ## 作用 - 自动帮你做**物理分页** - 自动识别数据库(MySQL、Oracle、SQL Server 等) - 自动拼接 `limit` 等分页语句 - 可以限制**最多一页查多少条**,防止查爆库 ## 使用场景 - 列表查询(用户列表、订单列表、商品列表、日志列表) - 前端需要页码、页数、总条数、总页数 - 不想自己手写 `limit (page-1)*size, size` - 防止有人恶意传超大 pageSize 导致全表查询拖垮服务 --- # 2. 乐观锁插件 OptimisticLockerInnerInterceptor ## 作用 - 解决**并发更新冲突问题** - 靠版本号 `version` 实现: - 更新时检查版本号是否一致 - 一致才更新,不一致就不更新并抛出异常 - 不加锁、性能高 ## 使用场景 - 多个用户/线程**同时修改同一条数据** 例:库存扣减、金额修改、状态修改 - 高并发场景,不想用数据库悲观锁(影响性能) - 需要保证**数据更新安全、不被覆盖** --- # 3. 防全表更新/删除插件 BlockAttackInnerInterceptor ## 作用 - **阻止没有 WHERE 条件的 UPDATE / DELETE** - 避免误操作: - `delete from user` → 全表删光 - `update user set name=xxx` → 全表改掉 - 直接拦截报错,保护数据安全 ## 使用场景 - 开发、测试环境防止手滑、写错代码 - 生产环境**最后一道安全防线** - 团队协作、新人多,必须加的保护插件 - 任何重要业务表都建议开启 --- # 一句话总结(面试背这个) 1. **分页插件**:自动分页,自动拼SQL,限制单页条数,用于列表查询。 2. **乐观锁插件**:解决并发更新冲突,靠版本号保证数据安全,用于高并发修改。 3. **防全表更新删除插件**:阻止无WHERE条件的危险操作,保护数据安全。 --- 需要我给你整理**一段可直接背的面试标准答案**吗?
重试机制:
java
@Retryable(
value = Exception.class,
maxAttempts = 3,
backoff = @Backoff(delay = 1000)
)意思就是当出现这个value的这样的类型的异常的时候就会触发重试,这里是重试三次每隔一秒,如果说这三次里面的第一次成功那就不重试后两次了,如果不成功那就接着重试间隔为一秒。这个value这个异常就是所有异常,只要出现异常就会重试。
死信交换机(消失处理失败重试机制):
问实习经历
key hash 哪些场景有用到
循环依赖
死锁怎么排查

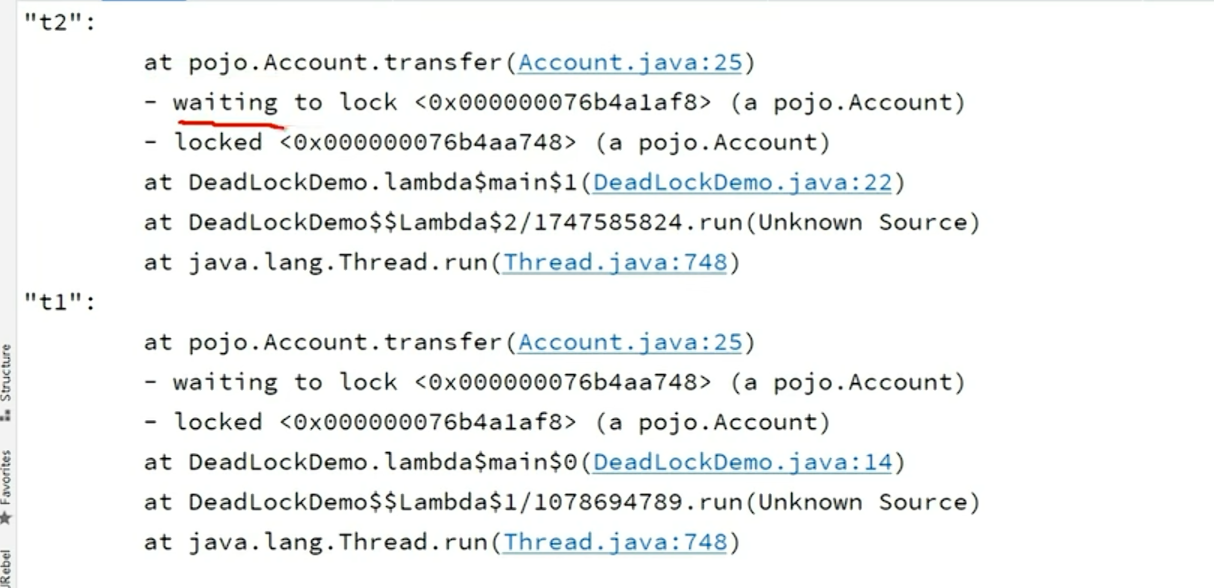
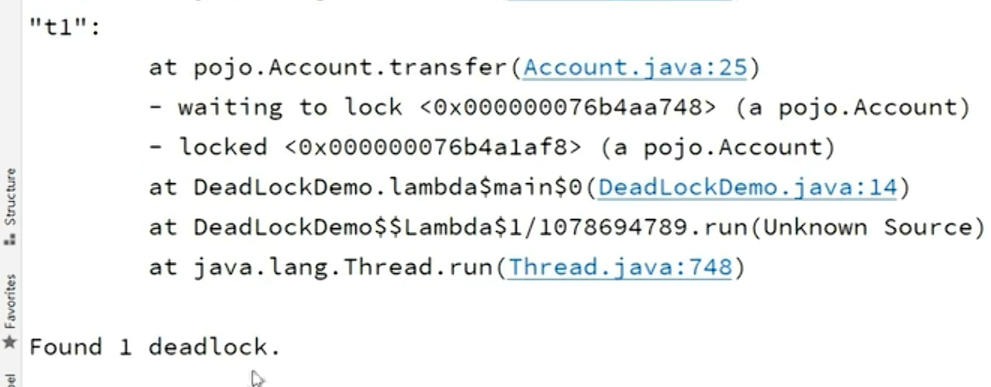
死锁
接口怎么优化
事务失效
全局异常处理器
cocounthashmap底层和扩容
我在项目里是用 Druid 连接池 来监控慢 SQL 的,先配置好慢 SQL 阈值,超过时间的 SQL 会自动在监控页面标记出来。然后我直接在页面里找到慢 SQL,复制拿到数据库执行,用 explain analyze 看执行计划,判断是全表扫描、没走索引还是回表太多。接着根据 SQL 里的 where 条件字段建合适的联合索引,再回去验证耗时,把慢 SQL 从三四百毫秒优化到五六十毫秒。
EXPLAIN数据库
type ------ 索引访问类型(E最重要,没有之一)
你看这一行的值:
ALL→ 全表扫描(慢死,必须优化)index→ 索引全扫描range→ 索引范围扫描ref→ 非唯一索引扫描eq_ref→ 主键 / 唯一索引关联const/system→ 主键 / 唯一索引单点查询
1. String(字符串)
核心定位 :1 个 key 对应 1 个 value,Redis 最基础、读写性能最高的结构,支持原子自增 / 自减、过期时间设置真实业务场景:
- 短信 / 图形验证码:key 为
code:phone:138xxxx1234,value 为 6 位验证码数字,设置 5 分钟过期,实现验证码时效控制 - 接口防重 Token / 幂等号:key 为
idempotent:token:xxxx-uuid,value 为标记位 1,过期时间与订单支付超时时间一致(如 20 分钟),就是你之前说的订单防重复提交场景 - 分布式锁:key 为
lock:order:1001,value 为uuid+线程ID,通过SET key value NX PX 30000命令实现,注意:这里用的是 String 类型,SET 是写入命令,和 Set 集合结构完全无关 - 原子计数器:key 为
view:article:1001(文章浏览量)、like:count:article:1001(点赞总数),value 为数字,通过incr/decr实现原子增减,避免并发计数错误
2. Hash(哈希)
核心定位 :1 个 key 对应多组 field-value 键值对,类似 Java 的 HashMap,适合存储结构化对象,支持单独修改某一个字段,无需全量更新真实业务场景:
- 用户基础信息缓存:key 为
user:info:1001,field 为name、phone、avatar、status,value 为对应字段的值,修改用户头像只需更新对应 field,不用全量读写整个用户信息 - 购物车:key 为
cart:user:1001,field 为商品 skuId,value 为包含商品数量、单价、规格信息的 JSON 串,用户加购、修改数量、删除商品,只需操作对应 skuId 的 field,无需全量操作购物车,完全匹配你之前的理解 - 商品基础属性缓存:key 为
product:info:2001,field 为price、stock、title、category,value 为对应属性值
3. Set(集合)
核心定位 :1 个 key 对应一堆无序、不可重复 的元素,天然去重,支持原子增删、判断元素是否存在,支持交集 / 并集 / 差集运算真实业务场景:
- 帖子 / 商品点赞功能:key 为
like:article:1001,member 为点赞用户的 userId,天然保证一个用户只能点赞一次,取消点赞用SREM,判断用户是否点赞用SISMEMBER,完全匹配你之前说的 "不能重复点赞" 的场景 - 共同关注 / 好友推荐:key 为
follow:user:1001,member 为用户关注的账号 ID,求两个用户的共同关注直接用SINTER命令,实现好友推荐功能

- 黑白名单 / IP 封禁:key 为
blacklist:ip,member 为封禁的 IP 地址,判断请求 IP 是否在黑名单内,直接用SISMEMBER,性能极高
4. List(列表)
核心定位 :1 个 key 对应一堆有序、可重复 的元素,严格保持插入顺序,支持两端插入 / 弹出,类似队列 / 栈结构真实业务场景:
- 简单消息队列 / 异步任务队列:key 为
queue:notify:email,生产者用LPUSH插入邮件发送任务,消费者用BRPOP阻塞式取出任务,严格保证任务按发送顺序执行 - 用户操作流水 / 行为日志:key 为
log:user:1001,用LPUSH插入用户的每一次操作记录,天然按时间倒序排列,查询用户最新 10 条操作,直接用LRANGE 0 9 - 文章评论楼层列表:key 为
comment:article:1001,按评论发布顺序用RPUSH插入,查询评论列表用LRANGE,严格保持楼层顺序,不会乱序 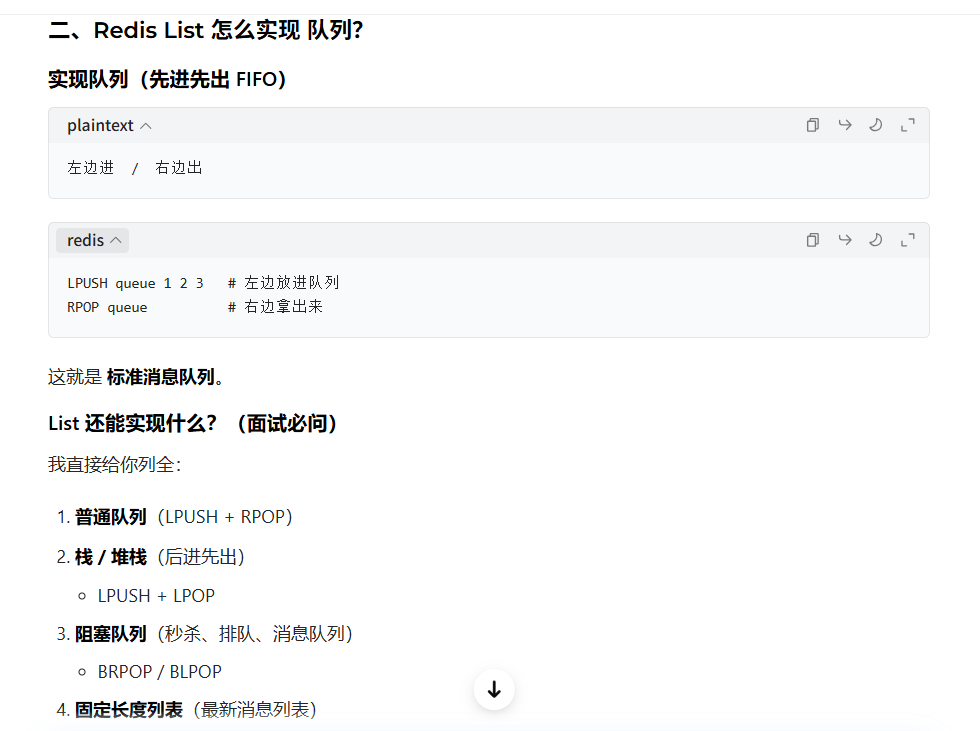
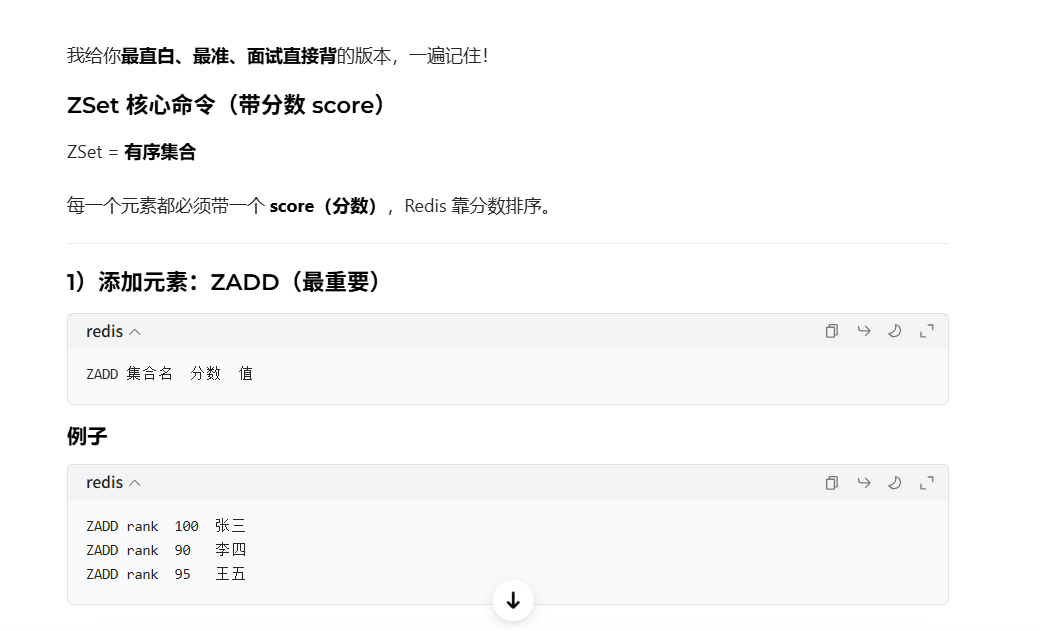
5. ZSet(有序集合)
核心定位 :1 个 key 对应一堆不可重复的 member ,每个 member 绑定一个 score 分数,自动按 score 排序,支持按分数范围查询、排名查询真实业务场景:
- 用户关注 / 粉丝列表(按关注时间排序):key 为
follow:user:1001,member 为被关注用户的 ID,score 为关注时间的时间戳,取最新关注的人用ZREVRANGE,取最早关注的人用ZRANGE,完全匹配你之前的理解 - 业务排行榜:key 为
rank:sales:202603(月度商品销量榜),member 为商品 ID,score 为商品销量,取 TOP10 热销商品直接用ZREVRANGE 0 9,还可以查询单个商品的销量排名 - 延时任务:key 为
queue:delay:task,member 为任务 ID,score 为任务执行的时间戳,定时轮询用ZRANGE取出已到执行时间的任务,实现延时执行
面试一句话速记版(直接背)
- String:存单个值,验证码、防重 Token、分布式锁、计数器都用它
- Hash:存结构化对象,用户信息、购物车都用它
- Set:做去重,点赞、共同关注、黑白名单都用它
- List:做有序队列,消息队列、操作日志、评论列表都用它
- ZSet:做带权重的排序,关注列表、排行榜、延时任务都用它
RabbitMQ 死信 & 延迟队列 终极精华总结
- 死信交换机、死信队列、延迟队列,全都是普通交换机、普通队列,没有特殊类型
- 队列 → 交换机 = 指向(靠配置名字,跟 routing key 无关)
- 交换机 → 队列 = 绑定(绑定时才带 routing key)
- routing key 只有生产者发消息时才有用,消费者根本不用管
- 死信队列:业务队列指向死信交换机 → 死信交换机绑定死信队列(存死信用)
- 延迟队列:自定义队列指向交换机 → 交换机绑定业务队列(过期后直接消费)
- 一个交换机可以绑多个队列,绑的顺序无所谓,只看角色用途
延时队列:
- 建一个普通队列(就叫它「延迟队列 / TTL 队列」)
- 建一个死信交换机(DLX)
- 给这个普通队列配置:
- 消息过期后,转发到这个死信交换机
- 死信交换机再绑定到真正的业务队列
- 生产者发消息 → 直接发到这个普通延迟队列
- 消息在里面等着,直到TTL 过期
- 一过期 → 变成死信 → 自动走死信交换机 → 转发进业务队列
- 消费者监听业务队列,正常消费
下面看代码:
先说明结构(你设计的那套)
- 普通队列 = 延迟队列(TTL 队列):没人消费,等过期
- 死信交换机 = dlxExchange
- 业务队列 = businessQueue:消费者监听它
- 生产者发消息 → 延迟队列 → 过期 → 死信交换机 → 业务队列
java
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DelayedQueueConfig {
// 1. 延迟队列(就是你说的"普通队列")
public static final String DELAY_QUEUE = "delay.queue";
// 2. 死信交换机
public static final String DLX_EXCHANGE = "dlx.exchange";
// 3. 业务队列(真正消费的队列)
public static final String BUSINESS_QUEUE = "business.queue";
// routing key 可以统一用一个
public static final String ROUTING_KEY = "key";
// ==================== 延迟队列(核心)====================
@Bean
public Queue delayQueue() {
Map<String, Object> args = new HashMap<>();
// 关键:消息过期后,转发到死信交换机
args.put("x-dead-letter-exchange", DLX_EXCHANGE);
// 转发时用的 routing key
args.put("x-dead-letter-routing-key", ROUTING_KEY);
// 可选:队列统一过期时间(也可以生产者单独设)
// args.put("x-message-ttl", 10000); // 10秒
return new Queue(DELAY_QUEUE, true, false, false, args);
}
// ==================== 死信交换机 ====================
@Bean
public DirectExchange dlxExchange() {
return new DirectExchange(DLX_EXCHANGE);
}
// ==================== 业务队列 ====================
@Bean
public Queue businessQueue() {
return new Queue(BUSINESS_QUEUE);
}
// ==================== 绑定:死信交换机 → 业务队列 ====================
@Bean
public Binding bindingBusinessQueue() {
return BindingBuilder.bind(businessQueue())
.to(dlxExchange())
.with(ROUTING_KEY);
}
}
java
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import static com.xxx.config.DelayedQueueConfig.DELAY_QUEUE;
@Service
public class DelayProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendDelayMsg(String msg, long delayTime) {
// 直接发到【延迟队列】
rabbitTemplate.convertAndSend(
DELAY_QUEUE, // 队列名
msg,
message -> {
// 设置过期时间(毫秒)
message.getMessageProperties().setExpiration(String.valueOf(delayTime));
return message;
}
);
}
}
java
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import static com.xxx.config.DelayedQueueConfig.BUSINESS_QUEUE;
@Component
public class BusinessConsumer {
// 监听业务队列
@RabbitListener(queues = BUSINESS_QUEUE)
public void consume(String msg) {
System.out.println("消费到延迟消息:" + msg);
}
}你问的重点:需要 routing key 吗?
你这句话是对的:
消费者直接监听业务队列,不需要关心 routing key
但:
- 延迟队列转发到死信交换机时 需要 routing key
- 死信交换机绑定业务队列时 需要 routing key
队列绑定死信交换机 → 死信交换机绑定死信队列消息失败 / 过期 → 进死信队列,你能在 RabbitMQ 控制台看到。
我只改关键部分,其他不变,一眼看懂。
1. 配置类(真正的死信队列版)
java
@Configuration
public class RabbitConfig {
// 业务队列(正常消费的队列)
public static final String BUSINESS_QUEUE = "business.queue";
// 死信交换机
public static final String DLX_EXCHANGE = "dlx.exchange";
// 死信队列(消息失败/过期,就进这里)
public static final String DEAD_LETTER_QUEUE = "dead.letter.queue";
// 路由 key(两个地方必须一样)
public static final String ROUTING_KEY = "key";
// ==================== 1. 业务队列(绑定死信交换机)====================
@Bean
public Queue businessQueue() {
Map<String, Object> args = new HashMap<>();
// 业务队列绑定死信交换机
args.put("x-dead-letter-exchange", DLX_EXCHANGE);
// 转发到死信队列用的 routingKey
args.put("x-dead-letter-routing-key", ROUTING_KEY);
return new Queue(BUSINESS_QUEUE, true, false, false, args);
}
// ==================== 2. 死信交换机 ====================
@Bean
public DirectExchange dlxExchange() {
return new DirectExchange(DLX_EXCHANGE);
}
// ==================== 3. 死信队列 ====================
@Bean
public Queue deadLetterQueue() {
return new Queue(DEAD_LETTER_QUEUE);
}
// ==================== 4. 死信交换机 绑定 死信队列 ====================
@Bean
public Binding deadLetterBinding() {
return BindingBuilder.bind(deadLetterQueue())
.to(dlxExchange())
.with(ROUTING_KEY);
}
}2. 这样配置后会发生什么?
-
消息发到
business.queue -
如果出现下面任意一种:
- 消息过期(TTL 到了)
- 消费失败、拒绝(reject/nack)
- 队列满了
-
消息就会变成死信
-
自动转发到
dlx.exchange -
再进入
dead.letter.queue -
你打开 RabbitMQ 控制台,能在死信队列里看到这条消息
-
消费者(监听业务队列)
java
@Component
public class BusinessConsumer {
@RabbitListener(queues = "business.queue")
public void consume(String msg) {
System.out.println("正在消费:" + msg);
// 模拟消费失败,消息会进入死信队列
// throw new RuntimeException("消费失败!");
}
}队列 → 绑定死信交换机 死信交换机 → 绑定死信队列
只要这么写:消息一失败 / 过期,就会跑到死信队列里,你能看得见!
Redis 过期时间监听(完整笔记版,面试 + 开发直接用):
一、核心概念
Redis 过期监听:监听 Redis 中所有 key 的过期事件 ,key 到期后 Redis 自动推送通知,程序监听到后执行自定义业务逻辑。不能单独监听某一个 key,只能监听全部过期 key → 通过判断 key 名称执行对应方法。
二、使用场景
- 订单超时未支付 → 自动取消订单
- 验证码过期 → 自动失效
- 优惠券过期 → 自动作废
- 限时活动结束 → 自动关闭
三、实现步骤
1. 开启 Redis 过期事件通知
修改 redis.conf 配置文件:
notify-keyspace-events Ex
- E:代表事件
- x:代表过期事件必须开启,否则无法接收过期通知。
(2)编写 Redis 过期监听器
java
import org.springframework.data.redis.connection.Message;
import org.springframework.data.redis.listener.KeyExpirationEventMessageListener;
import org.springframework.data.redis.listener.RedisMessageListenerContainer;
import org.springframework.stereotype.Component;
@Component
public class RedisKeyExpireListener extends KeyExpirationEventMessageListener {
// 构造方法
public RedisKeyExpireListener(RedisMessageListenerContainer listenerContainer) {
super(listenerContainer);
}
// key 过期后自动执行这个方法
@Override
public void onMessage(Message message, byte[] pattern) {
// 1. 获取过期的 key
String expireKey = message.toString();
System.out.println("已过期的key:" + expireKey);
// 2. 判断 key,执行不同业务逻辑
if (expireKey.startsWith("order:")) {
// 订单过期:执行取消订单方法
cancelOrder(expireKey);
} else if (expireKey.startsWith("code:")) {
// 验证码过期:执行验证码失效方法
invalidCode(expireKey);
} else if (expireKey.startsWith("coupon:")) {
// 优惠券过期:执行优惠券作废方法
invalidCoupon(expireKey);
}
}
// 取消订单
private void cancelOrder(String key) {
System.out.println("执行:订单" + key + "已超时取消");
}
// 验证码失效
private void invalidCode(String key) {
System.out.println("执行:验证码" + key + "已失效");
}
// 优惠券作废
private void invalidCoupon(String key) {
System.out.println("执行:优惠券" + key + "已过期作废");
}
}存储key的代码
java
@Autowired
private RedisTemplate<String, String> redisTemplate;
// 测试:存储 key 并设置过期时间
public void testSetKey() {
// 订单 key,30分钟过期
redisTemplate.opsForValue().set("order:1001", "未支付", 30, TimeUnit.MINUTES);
// 验证码 key,5分钟过期
redisTemplate.opsForValue().set("code:123456", "123456", 5, TimeUnit.MINUTES);
}四、核心流程(必背)
- 开启 Redis 过期事件通知
- 项目中编写过期监听器
- 存储 key 时设置过期时间
- key 到期 → Redis 自动推送通知
- 监听器获取过期 key 名称
- 判断 key → 执行对应业务方法
五、重点总结
- 监听所有过期 key,无法只监听单个 key
- 通过 key 前缀 / 名称判断 实现不同业务
- 必须开启
notify-keyspace-events Ex- key 只要设置过期时间,就会自动触发监听
1)普通锁(只给主节点加锁 → 不安全)
你平时写的就是这个:
java
// 普通分布式锁
RLock lock = redisson.getLock("lock:stock");
lock.lock();特点:只往主 Redis 写,从节点不同步 → 主挂了就丢锁
2)RedLock 红锁(所有节点都加锁 → 安全)
代码这么写:
java
// 1. 创建多个锁(对应集群里的多个主节点)
RLock lock1 = redisson.getLock("lock1");
RLock lock2 = redisson.getLock("lock2");
RLock lock3 = redisson.getLock("lock3");
// 2. 合成 RedLock
RedLock redLock = redisson.createRedLock(lock1, lock2, lock3);
// 3. 加锁 → 所有节点都会加
redLock.lock();一句话: 普通锁 = 加一个节点 RedLock = 加多个节点,过半成功才算成功
第 2 集剧本:用 RedLock 后,主挂了也不会超卖
角色
- Master1、Master2、Master3(3 个独立主节点)
- 线程 A、线程 B
剧情
-
线程 A 加 RedLock
- 给 Master1 加锁 ✅
- 给 Master2 加锁 ✅
- 给 Master3 加锁 ✅→ 3 个都成功,超过半数 → 锁成功
-
Master1 突然宕机
- 但 Master2、Master3 还有锁
-
线程 B 来抢锁
- 给 Master1 加锁:失败(挂了)
- 给 Master2 加锁:失败(已有锁)
- 给 Master3 加锁:失败(已有锁)→ 抢锁失败!
结局
超卖?不存在的!
最终超级大白话总结(你背这句)
- 普通锁:只给主 Redis 加锁 → 主挂 = 锁丢 → 不安全
- RedLock:给所有节点加锁 → 挂几个没事 → 安全
- 代码写法:创建多个 RLock,包成 RedLock 就行

GROUP BY和RANK() OVER(PARTITION BY ... ORDER BY ...)的区别:
GROUP BY:先分组,再聚合 → 每组只返回一行(汇总行)RANK() OVER(PARTITION BY ... ORDER BY ...):分组排名 → 每组所有行都保留,只是多一列排名
| 对比项 | GROUP BY | RANK() OVER(PARTITION BY ... ORDER BY ...) |
|---|---|---|
| 功能 | 分组聚合(求和、计数、平均等) | 分组内排序、排名 |
| 结果行数 | 每组 1 行 | 原表 所有行都保留 |
| 是否丢数据 | 会丢失明细,只留汇总 | 不丢明细,只加排名列 |
| 核心作用 | 统计、汇总、去重维度 | 排名、取 TopN、组内排序 |
| 执行时机 | 分组 → 聚合 → 输出 | 对查询结果集进行窗口计算 |
| 能否查明细 | 不能,只能查分组字段 + 聚合函数 | 能,所有字段都可以查 |
| 典型用法 | count(), sum(), max(), avg() | rank(), dense_rank(), row_number() |
| 是否排序 | 本身不保证排序 | 必须写 ORDER BY,自带排序 |
| 性能 | 聚合后数据量小,性能高 | 数据量不变,略耗资源 |
| 适用场景 | 统计每个部门工资总额、人数 | 每个部门工资前三名、成绩排名 |
三、举个一模一样的场景对比
假设有表:
先用一张通用的成绩表举例:
测试表:student_score
id name class score
1 张三 1 班 90
2 李四 1 班 90
3 王五 1 班 80
4 赵六 2 班 95
5 钱七 2 班 88
6 孙八 2 班 88
-
ROW_NUMBER () ------ 行号,不并列,连续不重复
SELECT
name, class, score,
ROW_NUMBER() OVER(PARTITION BY class ORDER BY score DESC) AS rn
FROM student_score;
| name | class | score | rn |
|---|---|---|---|
| 张三 | 1 班 | 90 | 1 |
| 李四 | 1 班 | 90 | 2 |
| 王五 | 1 班 | 80 | 3 |
| 赵六 | 2 班 | 95 | 1 |
| 钱七 | 2 班 | 88 | 2 |
| 孙八 | 2 班 | 88 | 3 |
GROUP BY:
sql
SELECT
class,
MAX(score) AS max_score
FROM student_score
GROUP BY class;| class | max_score |
|---|---|
| 1 班 | 90 |
| 2 班 | 95 |
这个就是class有几种就有几行
VOlatile关键字的应用:
volatile 关键字保证了变量是最新的(可见性), 同时防止 JVM 指令重排, 避免在懒汉单例模式下获取到只开辟了内存但还没初始化完成的烂对象
- volatile 保证可见性(读最新值)
java
public class VolatileVisibleDemo {
// 不加 volatile 会死循环,加了就能立刻读到最新值
private static volatile boolean flag = true;
public static void main(String[] args) throws InterruptedException {
// 线程1:一直检查 flag
new Thread(() -> {
while (flag) {
// 空循环
}
System.out.println("线程1 感知到 flag 变为 false");
}).start();
Thread.sleep(1000);
// 主线程修改 flag
flag = false;
System.out.println("主线程已把 flag 设为 false");
}
}结果:
- 不加 volatile :线程 1 一直读自己缓存的旧值
true,死循环 - 加 volatile :线程 1 立刻读到主内存最新值
false,正常退出
这就是你说的:保证读到的是最新数据。
- volatile 防止jvm/cpu指令重排(DCL 单例,避免烂对象)
java
public class Singleton {
// 必须加 volatile,禁止指令重排
private static volatile Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
// 第一次检查:不加锁,提高效率
if (instance == null) {
// 加锁
synchronized (Singleton.class) {
// 第二次检查:防止多线程同时进入第一次判断
if (instance == null) {
// 这行如果没有 volatile,会指令重排
instance = new Singleton();
}
}
}
return instance;
}
}new Singleton() 分为 3 步:
- 分配内存空间
- 初始化对象(构造方法、成员变量)
- instance 指向内存地址
没有 volatile 可能重排为:
1 → 3 → 2
后果:
- 线程 A 执行完 1、3,但还没执行 2
- 线程 B 进来,看到
instance != null - 直接拿去用 → 拿到一个仅实例化、没初始化的烂对象