文章目录
-
- 一、GRU
-
- [1.1 核心理论](#1.1 核心理论)
- [1.2 代码实现](#1.2 代码实现)
- 二、LSTM
-
- [2.1 核心理论原理解析](#2.1 核心理论原理解析)
- [2.2 代码实现](#2.2 代码实现)
- 三、深度循环神经网络
-
- [3.1 核心理论](#3.1 核心理论)
- [3.2 **从零开始实现 (Implementation from Scratch)**](#3.2 从零开始实现 (Implementation from Scratch))
- [3.3 简洁实现 (Concise Implementation)](#3.3 简洁实现 (Concise Implementation))
- [3.3 文本预测](#3.3 文本预测)
- 四、双向循环神经网络
-
- [4.1 核心理论](#4.1 核心理论)
- [4.2 从零开始实现 (Implementation from Scratch)](#4.2 从零开始实现 (Implementation from Scratch))
- 五、机器翻译数据集
-
- [5.1 机器翻译与数据集](#5.1 机器翻译与数据集)
- [5.2 代码实现](#5.2 代码实现)
- 六、编码器-解码器架构
-
- [6.1 编码器-解码器架构](#6.1 编码器-解码器架构)
- [6.2 编码器基类 (Encoder)](#6.2 编码器基类 (Encoder))
- [6.3 解码器基类 (Decoder)](#6.3 解码器基类 (Decoder))
- [6.4 将编码器和解码器组装起来 (EncoderDecoder)](#6.4 将编码器和解码器组装起来 (EncoderDecoder))
- 七、Seq2seq
-
- [7.1 核心思想概述](#7.1 核心思想概述)
- [7.2 Teacher Forcing](#7.2 Teacher Forcing)
- [7.3 衡量生成序列的好坏的BLEU](#7.3 衡量生成序列的好坏的BLEU)
- [7.4 代码实现](#7.4 代码实现)
-
- [7.4.1 embedding](#7.4.1 embedding)
- [7.4.2 Encoder 实现](#7.4.2 Encoder 实现)
- [7.4.3 Decoder 实现](#7.4.3 Decoder 实现)
- [7.4.4 Encoder-Decoder](#7.4.4 Encoder-Decoder)
- [7.4.5 带掩码的损失函数](#7.4.5 带掩码的损失函数)
- [7.4.6 训练](#7.4.6 训练)
- [7.4.7 预测](#7.4.7 预测)
- 八、束搜索
-
- [8.1 束搜索 (Beam Search)](#8.1 束搜索 (Beam Search))
- [8.2 scoring](#8.2 scoring)
一、GRU
GRU 是为了克服传统 RNN(循环神经网络)在处理长序列时容易出现的梯度消失 和遗忘问题而提出的一种强大变体。它的核心思想是引入了"门(Gate)"的机制来控制信息的流动。
1.1 核心理论
在传统的 RNN 中,当前时刻的隐藏状态 H t H_t Ht 是由前一时刻的隐藏状态 H t − 1 H_{t-1} Ht−1 和当前输入 X t X_t Xt 直接计算得出的,这导致模型很难记住很久以前的"重要信息",也很难忽略眼前的"垃圾信息"。
GRU 引入了两个特殊的"门"来解决这个问题,它们的值都在 0 , 1 0, 1 0,1 之间,就像水管上的阀门,0代表完全关闭,1代+表完全打开。
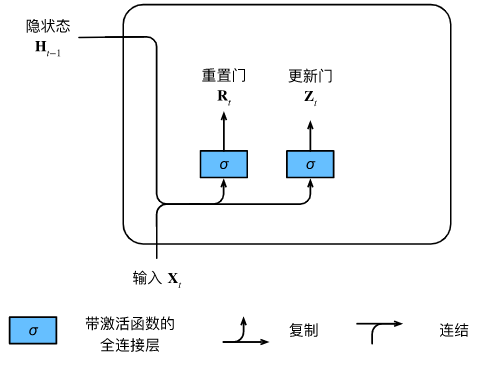
1. 重置门 (Reset Gate, R R R) 和 更新门 (Update Gate, Z Z Z)
- 重置门 R R R :决定了在计算当前的新状态时,要忽略多少过去的记忆 。
- 如果 R R R 接近 0,说明过去的记忆不重要,可以"重置"掉,只看当前输入。
- 这有助于捕获短期依赖。
- 更新门 Z Z Z :决定了在最终输出当前状态时,有多少旧的记忆需要被完整保留到新状态中 。
- 如果 Z Z Z 接近 1,说明过去的状态极其重要,直接把旧状态抄过来,忽略当前的计算。
- 这有助于捕获长期依赖。
数学公式:
R t = σ ( X t W x r + H t − 1 W h r + b r ) R_t = \sigma(X_t W_{xr} + H_{t-1} W_{hr} + b_r) Rt=σ(XtWxr+Ht−1Whr+br)
Z t = σ ( X t W x z + H t − 1 W h z + b z ) Z_t = \sigma(X_t W_{xz} + H_{t-1} W_{hz} + b_z) Zt=σ(XtWxz+Ht−1Whz+bz)
(注: σ \sigma σ 是 sigmoid 函数,它的作用就是把任意实数压缩到 0 到 1 之间,符合"门"的物理意义。)
2. 候选隐状态 (Candidate Hidden State, H ~ \tilde{H} H~)
这是我们尝试 要在当前时间步生成的新记忆。
H ~ t = tanh ( X t W x h + ( R t ⊙ H t − 1 ) W h h + b h ) \tilde{H}t = \tanh(X_t W{xh} + (R_t \odot H_{t-1}) W_{hh} + b_h) H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)
(注: ⊙ \odot ⊙ 代表按元素相乘。)
这里重置门 R t R_t Rt 发挥了作用:它直接乘在上一时刻的状态 H t − 1 H_{t-1} Ht−1 上。如果 R t R_t Rt 是 0,那么过去的状态完全被抹去,候选状态 H ~ t \tilde{H}_t H~t 就退化成一个只看当前输入 X t X_t Xt 的普通多层感知机。 tanh \tanh tanh 函数将值压缩到 − 1 , 1 -1, 1 −1,1 之间。
3. 最终隐状态 (Hidden State, H H H)
最后,我们使用更新门 Z t Z_t Zt 在旧记忆 H t − 1 H_{t-1} Ht−1 和新候选记忆 H ~ t \tilde{H}_t H~t 之间做权衡(凸组合):
H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t H_t = Z_t \odot H_{t-1} + (1 - Z_t) \odot \tilde{H}_t Ht=Zt⊙Ht−1+(1−Zt)⊙H~t
- 如果 Z t ≈ 1 Z_t \approx 1 Zt≈1: H t ≈ H t − 1 H_t \approx H_{t-1} Ht≈Ht−1,直接保留过去的状态,不仅记住了长期的信息,还在反向传播时让梯度直接传导,避免了梯度消失。
- 如果 Z t ≈ 0 Z_t \approx 0 Zt≈0: H t ≈ H ~ t H_t \approx \tilde{H}_t Ht≈H~t,完全使用当前步计算出的新状态。
1.2 代码实现
1. 导入库与准备数据
python
import torch
from torch import nn
from d2l import torch as d2l
# 设定批量大小为32,每个序列的时间步长度为35
batch_size, num_steps = 32, 35
# 读取《时间机器》文本数据集,获取数据迭代器和词表
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)2. 初始化模型参数 get_params
这个函数负责创建 GRU 内部所有的权重矩阵和偏置向量。
python
def get_params(vocab_size, num_hiddens, device):
# 输入和输出的维度都是词汇表的大小(One-hot编码)
num_inputs = num_outputs = vocab_size
# 辅助函数:生成均值为0,标准差为0.01的正态分布随机数矩阵
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01
# 辅助函数:一次性生成 3 个参数(输入权重、隐状态权重、偏置)
def three():
return (normal((num_inputs, num_hiddens)), # W_x
normal((num_hiddens, num_hiddens)), # W_h
torch.zeros(num_hiddens, device=device)) # b
# 1. 实例化 更新门 (Update Gate, Z) 的参数
W_xz, W_hz, b_z = three()
# 2. 实例化 重置门 (Reset Gate, R) 的参数
W_xr, W_hr, b_r = three()
# 3. 实例化 候选隐状态 (Candidate Hidden State, H_tilda) 的参数
W_xh, W_hh, b_h = three()
# 4. 实例化 输出层 的参数(用于将隐状态映射为对词表的预测)
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 将所有参数放入一个列表中
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
# 遍历所有参数,告诉 PyTorch 需要计算这些参数的梯度(用于反向传播更新)
for param in params:
param.requires_grad_(True)
return params3. 初始化隐状态 init_gru_state
在处理每个小批量的第一步时,我们需要一个初始的隐状态(通常全为0)。
python
def init_gru_state(batch_size, num_hiddens, device):
# 返回一个元组,里面包含一个全0的张量,形状为 (批量大小, 隐藏单元数)
# 使用元组是为了和 LSTM 等其他可能返回多个状态的 RNN 保持接口一致
return (torch.zeros((batch_size, num_hiddens), device=device), )4. 定义 GRU 的前向传播逻辑 gru
这里是核心。代码将前面讲的数学公式一行行翻译成了矩阵运算。
python
def gru(inputs, state, params):
# 1. 解包所有的权重和偏置参数
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
# 2. 解包上一时刻的隐状态 H
H, = state
# 3. 创建一个空列表,用于保存每个时间步的输出
outputs = []
# inputs 的形状是 (时间步长, 批量大小, 词表大小)
# 按时间步进行迭代,X 是当前时刻的输入,形状为 (批量大小, 词表大小)
for X in inputs:
# 公式 1:计算更新门 Z
# @ 代表矩阵乘法。X @ W_xz + H @ W_hz + b_z
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
# 公式 2:计算重置门 R
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
# 公式 3:计算候选隐状态 H_tilda (对应公式中的波浪号 H)
# 注意:(R * H) 是逐元素相乘(Hadamard积),表示重置门控制旧状态
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
# 公式 4:计算当前时刻的最终隐状态 H
# Z * H 表示保留多少旧状态,(1 - Z) * H_tilda 表示采纳多少新状态
H = Z * H + (1 - Z) * H_tilda
# 计算当前时刻的输出 Y (未经过 softmax 的 logits)
Y = H @ W_hq + b_q
# 将当前步的输出保存起来
outputs.append(Y)
# 将所有时间步的输出拼接在一起,返回拼接后的输出和最终的隐状态
return torch.cat(outputs, dim=0), (H,)5. 训练与预测
python
# 获取词汇表大小,设定隐藏单元数为256,尝试获取GPU
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1 # 训练500个轮次,学习率为1
# 实例化从零开始的 RNN 模型类,传入我们刚刚写的 get_params, init_gru_state, gru
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
# 调用 d2l 的训练函数开始训练
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)perplexity 1.1, 19911.5 tokens/sec on cuda:0
time traveller firenis i heidfile sook at i jomer and sugard are
travelleryou can show black is white by argument said filby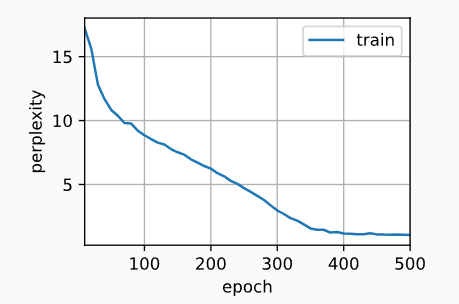
6. 简洁实现(调包版)
在实际工作中,我们绝对不会用 Python 写 for 循环来实现 GRU(太慢了)。PyTorch 提供了高度优化(基于 C++ 和 cuDNN)的 API nn.GRU。
python
# 词表大小即输入特征维度
num_inputs = vocab_size
# 直接调用 PyTorch 的 nn.GRU 层
# 这里实例化了一个 GRU 层,内部自动处理了那 11 个权重矩阵的初始化和前向传播逻辑
gru_layer = nn.GRU(num_inputs, num_hiddens)
# 将 GRU 层包装到 d2l 的高级模型类中,并添加输出全连接层
model = d2l.RNNModel(gru_layer, len(vocab))
model = model.to(device) # 将模型移至 GPU
# 开始训练。你会发现处理速度 (tokens/sec) 比从零实现版快了数倍!
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)perplexity 1.0, 109423.8 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
traveller with a slight accession ofcheerfulness really thi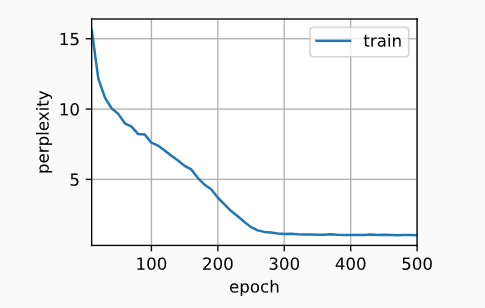
练习题
假设我们只想使用时间步 t ′ t' t′ 的输入来预测时间步 t t t ( t > t ′ t > t' t>t′) 的输出。对于每个时间步,重置门和更新门的最佳值是什么?
- 答: 在 t ′ t' t′ 时刻(想要记住信息的时刻):更新门 Z Z Z 应该接近 0(完全采纳当前输入作为新记忆),重置门 R R R 随意。
- 在 t ′ t' t′ 到 t t t 之间的所有时刻:更新门 Z Z Z 应该接近 1(彻底屏蔽后续输入,完美保留 t ′ t' t′ 时刻的记忆)。
- 这就完美体现了 GRU 解决长距离依赖的原理:通过 Z = 1 Z=1 Z=1 让记忆"穿越"时间步。
调整和分析超参数对运行时间、困惑度和输出顺序的影响。
- 提示: 增大
num_hiddens(如从 256 增加到 512)通常会降低困惑度(模型变聪明了),但运行时间会增加,且可能导致过拟合。降低学习率lr可能需要更多的num_epochs才能收敛。比较
rnn.RNN和rnn.GRU的不同实现对运行时间、困惑度和输出字符串的影响。
- 提示:
rnn.GRU的运行时间会稍慢于普通的rnn.RNN(因为每一层需要计算更多的门控矩阵),但是其困惑度会显著降低,生成的文本会更加通顺,因为它记住了长期的上下文,没有遇到严重的梯度消失问题。如果仅仅实现门控循环单元的一部分,例如,只有一个重置门或一个更新门会怎样?
- 只有更新门 Z Z Z :模型仍然可以缓解梯度消失问题(类似于简化的 LSTM)。它可以保留历史信息,但无法精准地"丢弃"不相关的历史片段(因为没有 R R R 门)。
- 只有重置门 R R R :模型退化成了带有"注意力"机制的普通 RNN。它能决定当前步参考多少过去信息,但由于没有更新门 Z Z Z 的直接残差连接 ( Z ⊙ H t − 1 Z \odot H_{t-1} Z⊙Ht−1),它依然无法解决深层梯度消失问题。
二、LSTM
LSTM 是深度学习在处理序列数据(NLP、时间序列等)时的一座极其重要的里程碑。虽然它比上一节讲的 GRU 早诞生了近20年,但它的设计更加复杂精妙。
2.1 核心理论原理解析
在普通的 RNN 中,长序列在反向传播时很容易产生梯度消失 ,导致模型"记不住"很久以前的信息。
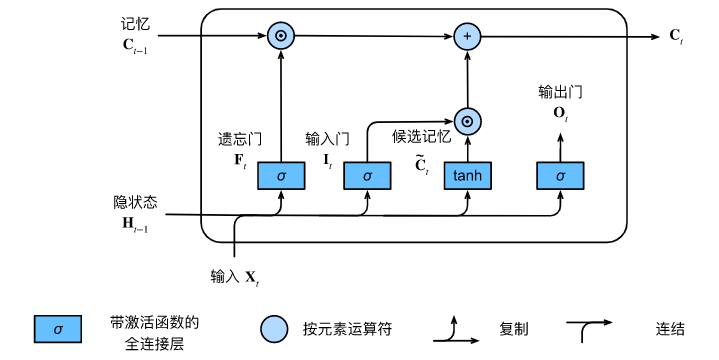
LSTM 的核心创新在于它引入了一个内部的**"记忆元(Memory Cell, C C C)",并且使用了三个"门(Gate)"**来精细控制这个记忆元的信息流动。

- 记忆元 C t C_t Ct:在内部传递,外界看不到。
- 隐状态 H t H_t Ht:对外输出的内容。基于记忆元生成,用来做当前步的预测,并传给下一时间步。
门机制有三个:
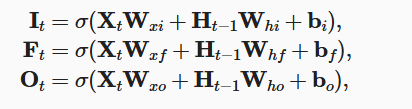
1. 遗忘门 (Forget Gate, F t F_t Ft) ------ 决定"丢弃什么旧信息"
它查看当前输入 X t X_t Xt 和上一时刻的隐状态 H t − 1 H_{t-1} Ht−1,输出一个 0 到 1 之间的数值。
- 0 代表"完全遗忘"。
- 1 代表"完全保留"。
2. 输入门 (Input Gate, I t I_t It) & 候选记忆元 ( C ~ t \tilde{C}_t C~t) ------ 决定"写入什么新信息"
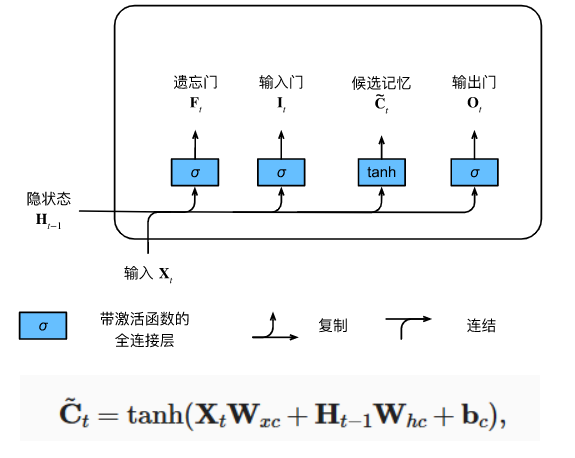
- 候选记忆元 C ~ t \tilde{C}_t C~t :根据 X t X_t Xt 和 H t − 1 H_{t-1} Ht−1 计算,但是用 tanh \tanh tanh 激活,值域在 − 1 , 1 -1, 1 −1,1。
- 输入门 I t I_t It:决定这份草稿有多大价值,有多少内容可以真正被写进核心档案柜里。
记忆元 C t C_t Ct的更新:
C t = F t ⊙ C t − 1 + I t ⊙ C ~ t C_t = F_t \odot C_{t-1} + I_t \odot \tilde{C}_t Ct=Ft⊙Ct−1+It⊙C~t
(注意:这里是加法。这是 LSTM 解决梯度消失的核心。梯度的反向传播可以通过这个加法形成一条畅通无阻的"高速公路",只要遗忘门 F t F_t Ft 接近 1,远古的记忆和梯度就能一直流传下来。)
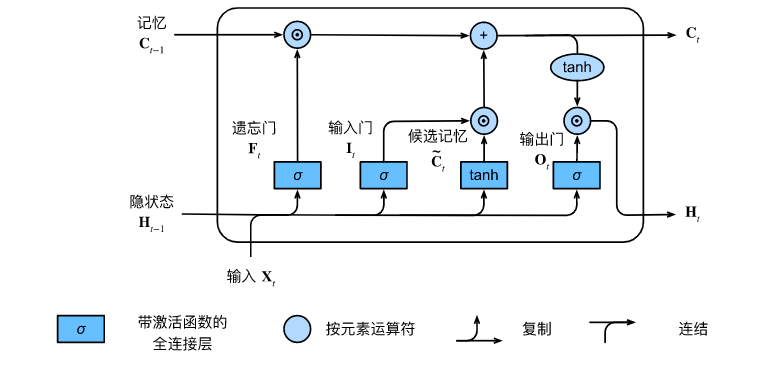
3. 输出门 (Output Gate, O t O_t Ot) & 隐状态 ( H t H_t Ht) ------ 决定"公开什么信息"
现在的档案柜 C t C_t Ct 已经更新完毕了,但我们不能把机密档案全给别人看。
- 输出门 O t O_t Ot:决定档案柜里的哪些部分需要对外公开。
- 隐状态 H t H_t Ht : H t = O t ⊙ tanh ( C t ) H_t = O_t \odot \tanh(C_t) Ht=Ot⊙tanh(Ct)。我们先用 tanh \tanh tanh 把档案数据压缩到 − 1 , 1 -1, 1 −1,1 保证数值稳定,然后用输出门进行过滤,得到最终对外公布的简报。
2.2 代码实现
1. 库
python
import torch
from torch import nn
from d2l import torch as d2l
# 设定批量大小为32,截断时间步长为35
batch_size, num_steps = 32, 35
# 加载《时间机器》数据集
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)2. 初始化模型参数 get_lstm_params
LSTM 有 3 个门和 1 个候选记忆元,它们都需要自己的权重矩阵,所以参数量比普通的 RNN 多得多(大约是普通的 4 倍)。
python
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
# 辅助函数:生成标准差为0.01的正态分布随机张量
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01
# 辅助函数:一次性生成包含 W_x, W_h, bias 三个参数的元组
def three():
return (normal((num_inputs, num_hiddens)), # 对应输入的权重
normal((num_hiddens, num_hiddens)), # 对应上一时序隐状态的权重
torch.zeros(num_hiddens, device=device)) # 偏置项初始化为0
# 为四个不同的模块实例化参数:
W_xi, W_hi, b_i = three() # 1. 输入门参数 (Input Gate)
W_xf, W_hf, b_f = three() # 2. 遗忘门参数 (Forget Gate)
W_xo, W_ho, b_o = three() # 3. 输出门参数 (Output Gate)
W_xc, W_hc, b_c = three() # 4. 候选记忆元参数 (Candidate Memory Cell)
# 5. 实例化最终输出层(全连接层)的参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 把所有参数打包到一个列表里
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q]
# 告诉 PyTorch 这些参数在训练时需要计算梯度
for param in params:
param.requires_grad_(True)
return params3. 初始化状态 init_lstm_state
注意这里的区别: 普通 RNN 和 GRU 只传递隐状态 H H H。而 LSTM 必须同时传递隐状态 H H H 和记忆元 C C C。
python
def init_lstm_state(batch_size, num_hiddens, device):
# 返回一个元组,包含两个全零张量:(H_0, C_0)
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))4. 前向传播核心逻辑 lstm
这就是把刚才的五个核心数学公式转化为代码。
python
def lstm(inputs, state, params):
# 1. 解包所有参数
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params
# 2. 解包上一时刻的状态,得到 隐状态 H 和 记忆元 C
(H, C) = state
outputs = [] # 用于保存每个时间步的预测结果
# inputs 形状为 (时间步数, 批量大小, 词表大小)
# 按时间步迭代
for X in inputs:
# 公式1:输入门 I (Sigmoid将值压缩到0~1)
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
# 公式2:遗忘门 F (Sigmoid将值压缩到0~1)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
# 公式3:输出门 O (Sigmoid将值压缩到0~1)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
# 公式4:候选记忆元 C_tilda (Tanh将值压缩到-1~1)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
# 公式5:更新真正的核心记忆元 C
# 遗忘门决定保留多少旧C,输入门决定写入多少新C_tilda
C = F * C + I * C_tilda
# 公式6:计算对外的隐状态 H
# 输出门决定将记忆元 C 的哪部分对外展示 (注意C在展示前还要过一次tanh)
H = O * torch.tanh(C)
# 计算当前时间步的输出(未归一化的 Logits)
Y = (H @ W_hq) + b_q
outputs.append(Y)
# 把所有时间步的输出在第0维拼接,并返回最新时刻的 (H, C) 状态对
return torch.cat(outputs, dim=0), (H, C)5. 训练与预测
python
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
# 使用 D2L 提供的框架包装我们自己写的底层代码
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params, init_lstm_state, lstm)
# 开始训练
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)perplexity 1.3, 17736.0 tokens/sec on cuda:0
time traveller for so it will leong go it we melenot ir cove i s
traveller care be can so i ngrecpely as along the time dime
简洁实现
python
# 输入特征维度
num_inputs = vocab_size
# 直接调用 PyTorch 的高级 API: nn.LSTM
# 它内部自动处理了那十几个权重矩阵和三个门、两个状态的复杂运算逻辑
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
# 将其包装到 D2L 的模型类中(包含了输出分类层)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
# 开始训练
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)(使用 nn.LSTM 后,吞吐量暴涨到了 23万 tokens/sec,速度提升了十几倍!)
perplexity 1.1, 234815.0 tokens/sec on cuda:0
time traveller for so it will be convenient to speak of himwas e
travelleryou can show black is white by argument said filby
一些练习
1. 调整和分析超参数对运行时间、困惑度和输出顺序的影响。
- 增加
num_hiddens:模型容量变大,困惑度(Perplexity,越小越好)通常会下降,生成的文本更像人话。但显存占用增加,运行时间变长,极度增加可能会导致过拟合。2. 如何更改模型以生成适当的单词,而不是字符序列?
- 目前的模型是 Character-level(字符级) 的(每次预测一个字母)。
- 要想变成 Word-level(单词级) ,需要在数据预处理阶段
load_data_time_machine改变分词方式(Tokenization)。用空格把句子拆成单词,构建单词级别的词汇表(Vocab)。模型的输入和输出维度vocab_size会显著增大。3. 比较 GRU、LSTM 和常规 RNN 的计算成本(参数量和推断成本)。
- 假设隐层维度为 h h h,输入维度为 d d d。
- RNN :1个权重组(针对当前输入和前一隐状态)。参数矩阵大小为 ( d × h + h × h ) (d \times h + h \times h) (d×h+h×h)。
- GRU :3个门(重置、更新、候选)。参数量是 RNN 的 3倍。
- LSTM :4个组件(3个门 + 1个候选)。参数量是 RNN 的 4倍。
- 训练/推断成本 :计算复杂度和内存消耗基本上是 L S T M > G R U > R N N LSTM > GRU > RNN LSTM>GRU>RNN。
4. 为什么隐状态 H 需要再次使用 tanh 函数( H = O ∗ tanh ( C ) H = O * \tanh(C) H=O∗tanh(C))来确保输出值在 -1, 1 之间?
- 极其重要的问题 :因为记忆元 C t = F ⋅ C t − 1 + I ⋅ C ~ t C_t = F \cdot C_{t-1} + I \cdot \tilde{C}_t Ct=F⋅Ct−1+I⋅C~t 是一个加法 更新。这意味着随着时间步的增加, C t C_t Ct 里面的数值完全有可能累加得非常大(绝对值大于 1)。
- 如果不套一层 tanh \tanh tanh,直接把巨大的值作为隐状态 H H H 输出并传给下一层,会导致后面的网络层发生数值爆炸 ,激活函数饱和失效。套一层 tanh \tanh tanh 起到了归一化和稳定数值的作用。
5. 实现一个能够基于时间序列进行预测而不是基于字符序列进行预测的LSTM。
- 字符预测 是一个分类任务 (预测下一个字母是哪个类别),所以最后使用了全连接层转成
vocab_size的输出,配合的是 CrossEntropy(交叉熵损失)。- 时间序列预测 (比如预测明天的股票价格、温度)通常是一个回归任务。
- 修改方法:
- 去掉
vocab,输入不再是 One-hot 向量,而是真实的连续数值(比如过去的温度值)。- 最后的输出层(
W_hq)不要映射到vocab_size,而是映射到num_outputs = 1(输出一个标量值)。- 损失函数从 CrossEntropy 改为 MSELoss (均方误差)。
三、深度循环神经网络
3.1 核心理论
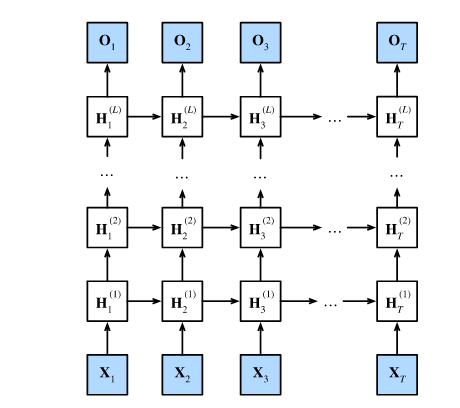
为什么需要"深度"的 RNN?
在之前的章节中,我们学习的 RNN 只有一个隐藏层。虽然从"时间"轴上看,由于时间步的展开(前一个时间步影响后一个时间步),RNN 已经显得很"深"了(可能包含成百上千个时间步的传递);但是,从**"空间/层次"轴**(即在一个特定的时间步,从输入到输出的过程)来看,它其实是很"浅"的。
为了让模型能够捕捉更复杂、更抽象的特征(就像在卷积神经网络 CNN 中堆叠多层卷积层一样),我们可以把多个 RNN 层堆叠起来。这种结构不仅在"时间"上是深度的,在"输入到输出的映射"上也是深度的。
架构与数学表达
想象一个有 L L L 个隐藏层的深度 RNN:
- 第一层:接收原始输入序列(如单词的词向量),输出第一层的隐藏状态序列。
- 中间层 :第 l l l 层的输入,正是上一层(第 l − 1 l-1 l−1 层)的输出(隐藏状态)。
- 输出层 :只利用最后一层(第 L L L 层)的隐藏状态来计算最终的预测结果。
数学公式:
在时间步 t t t,第 l l l 层的隐藏状态 H t ( l ) H_t^{(l)} Ht(l) 的计算公式为:
H t ( l ) = ϕ ( H t ( l − 1 ) W x h ( l ) + H t − 1 ( l ) W h h ( l ) + b h ( l ) ) H_t^{(l)} = \phi(H_t^{(l-1)} W_{xh}^{(l)} + H_{t-1}^{(l)} W_{hh}^{(l)} + b_h^{(l)}) Ht(l)=ϕ(Ht(l−1)Wxh(l)+Ht−1(l)Whh(l)+bh(l))
- H t ( l − 1 ) H_t^{(l-1)} Ht(l−1):同一时间步,上一层传上来的输入。
- H t − 1 ( l ) H_{t-1}^{(l)} Ht−1(l):同一层,上一个时间步传过来的隐藏状态。
- W W W 和 b b b:当前层专属的权重和偏置。
- ϕ \phi ϕ:激活函数(也可以替换为 LSTM 或 GRU 的门控机制)。
3.2 从零开始实现 (Implementation from Scratch)
这里我们将通过堆叠我们之前自己写的单层 RNNScratch 来构建深度 RNN。
定义多层 RNN 模型类
python
class StackedRNNScratch(d2l.Module):
def __init__(self, num_inputs, num_hiddens, num_layers, sigma=0.01):
# 初始化父类 d2l.Module
super().__init__()
# 保存传入的超参数到 self 中,方便后续调用
self.save_hyperparameters()
# 核心代码:使用 nn.Sequential 包含多个单层 RNN
# 列表推导式生成 num_layers 个 d2l.RNNScratch 实例
self.rnns = nn.Sequential(*[d2l.RNNScratch(
# 如果是第 0 层(第一层),输入维度是原始 num_inputs
# 如果是后续层,输入维度是上一层的输出维度,即 num_hiddens
num_inputs if i == 0 else num_hiddens,
num_hiddens, # 隐藏单元数保持一致
sigma) # 权重初始化的标准差
for i in range(num_layers)])定义前向传播 (Forward)
python
@d2l.add_to_class(StackedRNNScratch) # 将这个方法添加到刚才定义的类中
def forward(self, inputs, Hs=None):
outputs = inputs # 最开始的输入赋值给 outputs
# 如果没有传入初始的隐藏状态,则初始化一个长度为层数的列表,全填 None
if Hs is None: Hs = [None] * self.num_layers
# 逐层进行前向传播
for i in range(self.num_layers):
# self.rnns[i] 是第 i 层 RNN
# 它接收上一层的输出 (outputs) 和当前层上一个时间步的隐藏状态 (Hs[i])
# 返回更新后的 outputs 和当前层新的隐藏状态 Hs[i]
outputs, Hs[i] = self.rnns[i](outputs, Hs[i])
# 在底层的单层 RNNScratch 中,outputs 可能是一个列表(按时间步存储)
# 这里用 torch.stack 将列表沿着第 0 维度拼接成一个 Tensor
# 以便作为下一层的输入
outputs = torch.stack(outputs, 0)
# 返回最后一层的 outputs,以及包含所有层最新隐藏状态的列表 Hs
return outputs, Hs训练模型(从零实现版)
python
# 加载时光机器(Time Machine)数据集,批量大小1024,每个序列截取32个时间步
data = d2l.TimeMachine(batch_size=1024, num_steps=32)
# 实例化我们刚才写的深层 RNN 块
# num_inputs 是词汇表大小,隐藏层大小为32,层数设为2(这是一个2层的深度RNN)
rnn_block = StackedRNNScratch(num_inputs=len(data.vocab),
num_hiddens=32, num_layers=2)
# 将 RNN 块包装成语言模型 (Language Model, 负责将隐藏状态转为最终的词汇预测)
model = d2l.RNNLMScratch(rnn_block, vocab_size=len(data.vocab), lr=2)
# 设置训练器,最大迭代100轮,梯度裁剪阈值为1(防止梯度爆炸),使用1个GPU
trainer = d2l.Trainer(max_epochs=100, gradient_clip_val=1, num_gpus=1)
# 开始训练
trainer.fit(model, data)
3.3 简洁实现 (Concise Implementation)
幸运的是,在实际工程中,我们不需要像上面那样手动去写 for 循环堆叠层。PyTorch 等框架的高级 API 已经原生支持了深度 RNN。
定义基于高级 API 的多层 GRU 模型
python
class GRU(d2l.RNN): # 继承自 d2l.RNN 类(保存了一些通用的方法)
"""多层 GRU 模型"""
def __init__(self, num_inputs, num_hiddens, num_layers, dropout=0):
# 初始化父类
d2l.Module.__init__(self)
self.save_hyperparameters()
# 核心代码:直接调用 PyTorch 官方的 nn.GRU
# 注意这里的第三个参数就是 num_layers,直接告诉 PyTorch 你要几层!
# dropout 参数用于在层与层之间加入丢弃法,防止过拟合(默认0即不使用)
self.rnn = nn.GRU(num_inputs, num_hiddens, num_layers,
dropout=dropout)讲解 :nn.GRU 底层是用 C++ 和 CUDA 优化过的,它会自动帮你把多层的逻辑串联起来,不仅代码极其简洁,而且运行速度比我们刚才写的 for 循环快得多。
训练模型(简洁版)
python
# 实例化高级 GRU 模型,词汇表大小作为输入维度,隐藏层32,2个隐藏层
gru = GRU(num_inputs=len(data.vocab), num_hiddens=32, num_layers=2)
# 包装成语言模型,设置学习率为2 (RNN 语言模型学习率通常需要设置得稍大一点)
model = d2l.RNNLM(gru, vocab_size=len(data.vocab), lr=2)
# 使用同一个 trainer 开始训练
trainer.fit(model, data)
3.3 文本预测
python
# 让训练好的模型进行续写预测
# 提示词为 'it has',要求往后生成 20 个字符
model.predict('it has', 20, data.vocab, d2l.try_gpu())'it has for and the time th'模型学会了根据上下文胡诌一些看起来像英文的句子,虽然语义可能不连贯,因为只训练了 100 epoch,且数据集很小。
一些练习
1. 把 GRU 替换为 LSTM 并比较准确率和训练速度。
- 做法 :把简洁实现中的
nn.GRU换成nn.LSTM即可。- 结果:通常 LSTM 的训练速度会比 GRU 稍慢(因为 LSTM 有 3 个门和 1 个细胞状态,参数量更大,计算更复杂)。但是在某些复杂数据集上,LSTM 可能会达到更低的困惑度(更好的准确率)。
2. 增加训练数据包含多本书。你在困惑度(perplexity)尺度上能降到多低?
- 解析 :目前我们只用了《时光机器》一本很薄的小说。如果加入更多小说,词汇更丰富,语言规律更明显。随着数据量增加,在模型容量足够的前提下(可以尝试把
num_hiddens加大到 256 或 512),困惑度会显著下降,逼近 1.0(完美预测)。3. 在对文本建模时,你会希望组合不同作者的文本来源吗?为什么这是个好主意?可能会出什么问题?
- 好主意:混合不同作者的书,可以让模型学习到更通用、更稳健的英语语法规则和通用词汇,而不是局限于某一个作者的特定偏好(防止对单一语料的过拟合)。
- 坏主意(可能出的问题):不同作者的写作风格(Style)、时代背景下的用词习惯差异极大(比如莎士比亚的古英语 vs 海明威的极简现代英语)。如果把它们混在一起,模型在生成文本时可能会出现"风格分裂",导致写出的文章上下文风格极其突兀,不伦不类。如果目标是模仿特定风格,绝不能混用数据。
四、双向循环神经网络
在前几节中,我们学习的都是单向(Unidirectional) 的 RNN,它只能"从左到右"看数据。但在很多实际任务中,我们需要模型既能"看过去",也能"看未来"。这就是双向循环神经网络(Bidirectional RNN, 简称 BiRNN) 诞生的原因。
4.1 核心理论
为什么需要"双向"?
目前为止,我们做的序列任务主要是语言建模(预测下一个词)。在这种任务中,我们只能依靠"左侧上下文"(历史信息),因为未来还没发生。这种设定非常适合单向 RNN。
但是,在许多其他任务中,允许模型同时查看"左侧(过去)"和"右侧(未来)"的上下文是非常合理的。
一个非常生动的**"完形填空(Masked Language Modeling)"** 的例子:
I am ___.(我很 ___) -> 填happy(高兴) 很合理。I am ___ hungry.(我 ___ 饿) -> 填very(非常) 或not(不) 都合理。I am ___ hungry, and I can eat half a pig.(我 ___ 饿,我能吃下半头猪) -> 结合右侧(未来) 的句子,这里只能填very,填not就完全不合逻辑了。
这个例子证明:右侧的上下文(未来的词)对当前位置的预测起着决定性的作用。 词性标注(判断一个词是名词还是动词)、实体识别等任务同样极度依赖双向上下文。
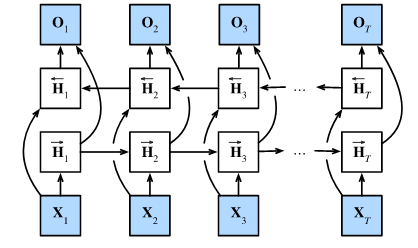
双向 RNN 的架构与数学原理
解决这个问题的方法惊人地简单(Schuster & Paliwal, 1997):直接用两个单向 RNN 拼起来。
- 正向 RNN :从左到右读取序列( x 1 , x 2 , . . . , x T x_1, x_2, ..., x_T x1,x2,...,xT)。
- 反向 RNN :从右到左读取同一个序列( x T , x T − 1 , . . . , x 1 x_T, x_{T-1}, ..., x_1 xT,xT−1,...,x1)。
- 合并输出 :在每一个时间步 t t t,把正向 RNN 的隐藏状态和反向 RNN 的隐藏状态拼接(Concatenate) 在一起,作为该时间步最终的特征表示。
数学公式表达:
假设隐藏单元个数为 h h h。
- 正向隐藏状态 H → t \overrightarrow{H}_t H t :依赖当前输入 X t X_t Xt 和上一步 的正向状态 H → t − 1 \overrightarrow{H}{t-1} H t−1。
H → t = ϕ ( X t W x h ( f ) + H → t − 1 W h h ( f ) + b h ( f ) ) \overrightarrow{H}t = \phi(X_t W{xh}^{(f)} + \overrightarrow{H}{t-1} W_{hh}^{(f)} + b_h^{(f)}) H t=ϕ(XtWxh(f)+H t−1Whh(f)+bh(f)) - 反向隐藏状态 H ← t \overleftarrow{H}_t H t :依赖当前输入 X t X_t Xt 和下一步 的反向状态 H ← t + 1 \overleftarrow{H}{t+1} H t+1(因为它是由右向左扫描的)。
H ← t = ϕ ( X t W x h ( b ) + H ← t + 1 W h h ( b ) + b h ( b ) ) \overleftarrow{H}t = \phi(X_t W{xh}^{(b)} + \overleftarrow{H}{t+1} W_{hh}^{(b)} + b_h^{(b)}) H t=ϕ(XtWxh(b)+H t+1Whh(b)+bh(b)) - 最终隐藏状态 H t H_t Ht :将两者在特征维度上拼接,所以现在的维度变成了 2 h 2h 2h。
H t = H → t , H ← t H_t = \\overrightarrow{H}_t, \\overleftarrow{H}_t Ht=H t,H t - 输出计算 :拿这个拼接后的 2 h 2h 2h 维的 H t H_t Ht 去乘以输出层的权重 W h q W_{hq} Whq,得到最终预测 O t O_t Ot。
O t = H t W h q + b q O_t = H_t W_{hq} + b_q Ot=HtWhq+bq
4.2 从零开始实现 (Implementation from Scratch)
在这里,我们将实例化两个我们之前写过的单向 RNNScratch,一个负责正向,一个负责反向。
定义模型类
python
class BiRNNScratch(d2l.Module):
def __init__(self, num_inputs, num_hiddens, sigma=0.01):
# 初始化父类
super().__init__()
self.save_hyperparameters()
# 实例化正向 RNN (f_rnn: forward RNN)
self.f_rnn = d2l.RNNScratch(num_inputs, num_hiddens, sigma)
# 实例化反向 RNN (b_rnn: backward RNN)
self.b_rnn = d2l.RNNScratch(num_inputs, num_hiddens, sigma)
# 极其重要的一步:因为我们会把正向和反向的输出拼接在一起,
# 所以最终暴露给外面(下一层或输出层)的隐藏维度大小是原本的 2 倍
self.num_hiddens *= 2 前向传播 (Forward)
python
@d2l.add_to_class(BiRNNScratch)
def forward(self, inputs, Hs=None):
# 1. 拆包初始隐藏状态。
# 如果 Hs 存在,解包为正向初始状态 f_H 和反向初始状态 b_H;否则设为 None
f_H, b_H = Hs if Hs is not None else (None, None)
# 2. 运行正向 RNN。
# inputs 按正常顺序按时间步喂入 f_rnn
f_outputs, f_H = self.f_rnn(inputs, f_H)
# 3. 运行反向 RNN。
# reversed(inputs) 将时间步的顺序翻转(例如从 1,2,3 变成 3,2,1),然后喂入 b_rnn
b_outputs, b_H = self.b_rnn(reversed(inputs), b_H)
# 4. 拼接输出(难点核心)。
# 注意:此时 f_outputs 的时间顺序是 1,2,3...
# 但 b_outputs 的生成顺序是 3,2,1... (因为我们输入时翻转了)
# 所以在拼接前,必须把 b_outputs 再次 reversed 翻转回 1,2,3...
# 这样 f 和 b 才是在同一个物理时间步上对齐的!
# torch.cat((f, b), -1) 表示在最后一个维度(特征维度)上进行拼接。
outputs = [torch.cat((f, b), -1) for f, b in zip(
f_outputs, reversed(b_outputs))]
# 返回拼接后的输出列表,以及包含最新正反向隐藏状态的元组
return outputs, (f_H, b_H)简洁实现 (Concise Implementation)
python
class BiGRU(d2l.RNN):
def __init__(self, num_inputs, num_hiddens):
# 初始化父类 d2l.RNN(包含外围的参数初始化逻辑)
d2l.Module.__init__(self)
self.save_hyperparameters()
# 核心代码:直接调用 nn.GRU,只需加入参数 bidirectional=True 即可
# 底层的 C++/CUDA 代码会自动帮你创建正向和反向两套权重,并处理翻转和拼接的逻辑。
self.rnn = nn.GRU(num_inputs, num_hiddens, bidirectional=True)
# 同样,由于 PyTorch 在 bidirectional=True 时输出特征维度会自动翻倍,
# 我们需要在类的属性中把 num_hiddens 乘 2,以便适配后续的输出层(如全连接层)。
self.num_hiddens *= 2一些练习
1. 如果正反向方向使用不同数量的隐藏单元, H t H_t Ht 的形状会如何变化?
- 解答 :假设正向 RNN 的隐藏单元数为 h f h_f hf,反向 RNN 的隐藏单元数为 h b h_b hb。由于我们在每一个时间步对两者的隐藏状态进行拼接(Concatenation),最终得到的隐藏状态 H t H_t Ht 的形状(特征维度大小)将会是 h f + h b h_f + h_b hf+hb。
2. 设计一个具有多个隐藏层的双向 RNN。
- 解答 :在深层(多层)双向 RNN 中,第 l l l 层的输出会作为第 l + 1 l+1 l+1 层的输入。
- 第一层:输入序列 X X X,产生正向和反向状态,拼接得到维度为 2 h 2h 2h 的输出序列 H ( 1 ) H^{(1)} H(1)。
- 第二层:将 H ( 1 ) H^{(1)} H(1) 作为输入,同时正向和反向 送入第二层,再次得到特征抽取后的输出 H ( 2 ) H^{(2)} H(2)。
- 在 PyTorch 中,只需
nn.GRU(..., num_layers=N, bidirectional=True)一行代码即可实现。3. 自然语言中一词多义(Polysemy)很常见。例如单词"bank"(银行/河岸)。我们如何设计网络,使得给定上下文和单词,返回正确的上下文向量表示?处理一词多义的首选网络架构是什么?
- 解答 :
- 痛点:传统的词向量(如 Word2Vec、GloVe)是静态的,无论在什么句子里,"bank" 对应同一个固定的向量,无法区分是一词多义。
- 解决方案 :我们需要动态上下文嵌入(Contextualized Embeddings)。将整个句子输入到模型中,模型在计算 "bank" 这个词的表示时,不仅提取 "bank" 本身的特征,还要融合句子中其他词(如 "deposit cash" 存现金 或 "sit down" 坐下)的特征。
- 首选架构 :双向网络架构 是处理一词多义的最佳选择!包括我们这里学的 BiLSTM/BiGRU (著名的 ELMo 模型就是用 BiLSTM 解决一词多义的),以及现在最主流的基于自注意力机制的 Transformer 编码器(如 BERT)。因为它们能同时看到目标词语前后的语境,从而精准锁定该词在当前句中的特定含义。
五、机器翻译数据集
从这一节开始,我们正式踏入自然语言处理(NLP)中最经典的任务之一:机器翻译(Machine Translation)。
与之前章节的"语言模型"(预测下一个词)不同,机器翻译属于典型的 Seq2Seq(Sequence-to-Sequence,序列到序列) 问题。输入一段英语序列,输出一段法语序列。由于两种语言的语法不同,输入和输出的长度可能不一致,词序也可能不同。
5.1 机器翻译与数据集
机器翻译的特殊性
处理机器翻译数据,与之前处理单语种文本有很大的不同,主要体现在需要引入几个特殊的标记(Tokens):
<eos>(End of Sequence) :句子结束符。因为机器翻译输出的长度不固定,模型在逐词生成翻译时,一旦生成了<eos>,就代表"我说完了",停止生成。<bos>(Beginning of Sequence):句子开头符。用于在解码器(生成翻译的部分)开始工作时,给它一个初始的启动信号。<pad>(Padding) :填充符。为了让不同长度的句子能拼成一个形状规则的矩阵(Minibatch)放进 GPU 训练,短句子需要在末尾补上<pad>。<unk>(Unknown) :未知词符。如果一个词在数据集中出现次数极少,为了减小词表体积,我们会把它当作<unk>处理。
5.2 代码实现
首先导入必要的库:
python
import os
import torch
from d2l import torch as d2l下载和预处理数据集
我们将使用一个英法双语数据集(Tatoeba Project)。每一行都是用制表符(\t)分隔的英语句子和对应的法语句子。
python
class MTFraEng(d2l.DataModule): # 继承 d2l 的数据模块基类
"""英法翻译数据集。"""
def _download(self):
# d2l.download 会下载 zip 包,d2l.extract 负责解压
d2l.extract(d2l.download(
d2l.DATA_URL+'fra-eng.zip', self.root,
'94646ad1522d915e7b0f9296181140edcf86a4f5'))
# 打开解压后的纯文本文件 fra.txt
with open(self.root + '/fra-eng/fra.txt', encoding='utf-8') as f:
return f.read() # 将所有文本作为一个巨大的字符串返回
data = MTFraEng()
raw_text = data._download()
print(raw_text[:75]) # 打印前75个字符看看长什么样预处理数据:主要是清理特殊空格,并在标点符号前加空格(这样标点符号就能作为一个独立的"词"被切分出来)。
python
@d2l.add_to_class(MTFraEng) # 把这个方法添加到 MTFraEng 类中
def _preprocess(self, text):
# 替换法语中常见的不可分断空格(\u202f 和 \xa0)为普通空格
text = text.replace('\u202f', ' ').replace('\xa0', ' ')
# 这是一个 lambda 匿名函数,判断当前字符如果是标点,且前一个字符不是空格时,返回 True
no_space = lambda char, prev_char: char in ',.!?' and prev_char != ' '
# 遍历文本:如果当前字符是标点且前面没空格,就在它前面插个空格;否则保持原样。
# 比如把 "Hello." 变成 "Hello .",同时把所有字母转为小写。
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text.lower())]
return ''.join(out) # 把列表重新拼接成字符串
text = data._preprocess(raw_text)
print(text[:80])词元化 (Tokenization)
我们使用词级(Word-level) 词元化,即以空格拆分单词,并在每个句子末尾加上 <eos>。
python
@d2l.add_to_class(MTFraEng)
def _tokenize(self, text, max_examples=None):
src, tgt = [], [] # src 存英语(源语言),tgt 存法语(目标语言)
# 按换行符分割每一行,遍历行
for i, line in enumerate(text.split('\n')):
# 如果设置了最大样本数,超过就停止读取
if max_examples and i > max_examples: break
# 按制表符 \t 分割,parts[0]是英语,parts[1]是法语
parts = line.split('\t')
if len(parts) == 2:
# 英语末尾加上 <eos>,然后按空格分割成列表,剔除空字符串
src.append([t for t in f'{parts[0]} <eos>'.split(' ') if t])
# 法语末尾加上 <eos>,同样按空格分割
tgt.append([t for t in f'{parts[1]} <eos>'.split(' ') if t])
return src, tgt
src, tgt = data._tokenize(text)
src[:6], tgt[:6] # 打印前6句话的词元列表绘制每个文本序列所包含的标记数量的直方图
python
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):
"""Plot the histogram for list length pairs."""
d2l.set_figsize()
_, _, patches = d2l.plt.hist(
[[len(l) for l in xlist], [len(l) for l in ylist]])
d2l.plt.xlabel(xlabel)
d2l.plt.ylabel(ylabel)
for patch in patches[1].patches:
patch.set_hatch('/')
d2l.plt.legend(legend)
show_list_len_pair_hist(['source', 'target'], '# tokens per sequence',
'count', src, tgt);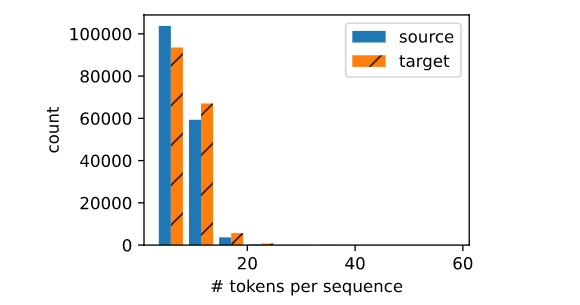
截断与填充 (Loading Sequences of Fixed Length)
这是深度学习 NLP 处理数据最关键的一步
为了进行矩阵运算,每一个 Batch 里的句子必须等长(设长度为 num_steps)。
- 截断(Truncation) :如果句子长度 >
num_steps,砍掉后面的部分。 - 填充(Padding) :如果句子长度 <
num_steps,在末尾一直补<pad>直到等长。
python
@d2l.add_to_class(MTFraEng)
def __init__(self, batch_size, num_steps=9, num_train=512, num_val=128):
super(MTFraEng, self).__init__()
self.save_hyperparameters() # 保存超参数
# 调用 _build_arrays 生成张量数据和词表
self.arrays, self.src_vocab, self.tgt_vocab = self._build_arrays(
self._download())
@d2l.add_to_class(MTFraEng)
def _build_arrays(self, raw_text, src_vocab=None, tgt_vocab=None):
# 定义一个内部函数,专门处理单语种的句子列表
def _build_array(sentences, vocab, is_tgt=False):
# 匿名函数:截断或填充。t 是设定的固定长度 num_steps
pad_or_trim = lambda seq, t: (
seq[:t] if len(seq) > t else seq + ['<pad>'] * (t - len(seq)))
# 对所有句子执行截断或填充
sentences = [pad_or_trim(s, self.num_steps) for s in sentences]
# 【核心逻辑】:如果是目标语言(法语),需要在句子最前面强行塞入一个 <bos>
if is_tgt:
sentences = [['<bos>'] + s for s in sentences]
# 如果还没建立词表,就根据当前句子建立,丢弃出现次数少于2次的词 (<unk>)
if vocab is None:
vocab = d2l.Vocab(sentences, min_freq=2)
# 将文本单词转化为词表中的数字索引,并转为 PyTorch Tensor
array = torch.tensor([vocab[s] for s in sentences])
# 记录每一个句子的"有效长度"(排除 <pad> 的真实长度),后续计算 Loss 时非常有用!
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
return array, vocab, valid_len
# 读取并切分数据集
src, tgt = self._tokenize(self._preprocess(raw_text),
self.num_train + self.num_val)
# 处理源语言(英语),不需要 <bos>
src_array, src_vocab, src_valid_len = _build_array(src, src_vocab)
# 处理目标语言(法语),需要 <bos>
tgt_array, tgt_vocab, _ = _build_array(tgt, tgt_vocab, True)
# 返回构建好的张量元组
# 注意目标语言的切片操作:
# tgt_array[:, :-1] 是解码器的输入 (包含 <bos>,不要最后一个词)
# tgt_array[:, 1:] 是解码器要预测的标签 (不包含 <bos>,正好往后错位一个词!)
return ((src_array, tgt_array[:,:-1], src_valid_len, tgt_array[:,1:]),
src_vocab, tgt_vocab)错位标签解释(极其重要) :
假设原始句子是 [ 'salut', '.', '<eos>', '<pad>' ]。
加上 <bos> 后变成 [ '<bos>', 'salut', '.', '<eos>', '<pad>' ]。
- 解码器输入(去掉最后):
[ '<bos>', 'salut', '.', '<eos>' ] - 模型目标标签(去掉最前):
[ 'salut', '.', '<eos>', '<pad>' ]
逻辑就是:看到<bos>,模型应该预测出salut;看到salut,模型应该预测出.,以此类推。这被称为Teacher Forcing(教师强制)。
读取数据集并验证
python
@d2l.add_to_class(MTFraEng)
def get_dataloader(self, train):
# 根据 train 布尔值划分训练集和验证集索引
idx = slice(0, self.num_train) if train else slice(self.num_train, None)
# 调用 D2L 底层的 Tensor 迭代器
return self.get_tensorloader(self.arrays, train, idx)
# 测试一下 DataLoader
data = MTFraEng(batch_size=3) # batch size 设为 3
src, tgt, src_valid_len, label = next(iter(data.train_dataloader()))
print('source:', src.type(torch.int32))
print('decoder input:', tgt.type(torch.int32))
print('source len excluding pad:', src_valid_len.type(torch.int32))
print('label:', label.type(torch.int32))打印出来全是数字。为了直观理解,把数字再变成单词:
python
# 提取一句话并转回字符串看看
src, tgt, _, _ = data.build(['hi .'], ['salut .'])
print('source:', data.src_vocab.to_tokens(src[0].type(torch.int32)))
print('target:', data.tgt_vocab.to_tokens(tgt[0].type(torch.int32)))
# 输出:
# source: ['hi', '.', '<eos>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']
# target: ['<bos>', 'salut', '.', '<eos>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']一些练习
1. 尝试在
_tokenize方法中使用不同的max_examples参数值。这会如何影响源语言和目标语言的词表大小?
- 解答 :
max_examples控制我们读取的句子总数。
- 设得越小 ,读取的句子越少,出现过的不重复单词数量就越少,生成的词表(Vocabulary Size)自然就越小。
- 设得越大 ,读入的语料越丰富,词表就会显著变大 。但由于长尾效应(很多词只出现过一次),大量罕见词会被我们通过
min_freq=2过滤掉并归为<unk>。2. 某些语言(如中文和日文)的文本没有词边界指示符(例如空格)。在这种情况下,词级标记化仍然是一个好主意吗?为什么?
- 解答 :直接进行按空格的词级标记化是绝对不行的 ,因为中日文一整句话中间根本没有空格(例如:"我爱深度学习")。
- 常规做法 :通常需要引入外部的分词工具(例如中文的
jieba分词),先切分成"我 / 爱 / 深度 / 学习",然后再应用本文的逻辑。- 现代深度学习的做法 :基于完整词的分词会导致中文词表极其庞大(几十万词)。现代模型(如 BERT, GPT)通常采用子词切分(Subword Tokenization,如 BPE) ,或者直接退化为字级别(Character-level) 标记化(将"我爱深度学习"直接拆成6个字元)。这样不仅词表小(中文常用汉字就几千个),且基本不会出现
<unk>未知词。
六、编码器-解码器架构
这一节非常重要,不涉及复杂的数学公式,而是建立现代深度学习(尤其是 NLP 和多模态领域)最核心的宏观架构思想:编码器-解码器架构(Encoder-Decoder Architecture)。
我们现在熟知的 Transformer、ChatGPT、Sora,其底层的骨架全都是基于这个架构演变而来的。
6.1 编码器-解码器架构
为什么要拆分成两部分?
在之前的章节中,我们处理的任务通常是"定长输入 -> 定长输出",或者"输入一个序列 -> 输出一个分类(情感分析)"。
但在机器翻译等 Seq2Seq(序列到序列)任务中,存在两个致命难点:
- 长度不对齐:输入是 4 个英文单词(They are watching .),输出可能是 3 个法语单词(Ils regardent .)。
- 语序不对齐:两种语言的语法倒装结构不同。
为了解决这个问题,研究人员巧妙地借鉴了人类翻译员的大脑工作模式,将网络拆成了两个独立的打工人:
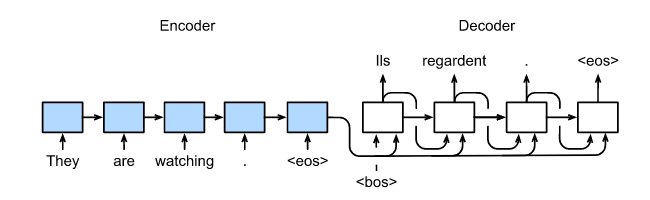
- 编码器(Encoder / "听力理解员") :
它的任务是接收长度可变的源语言输入序列,把所有的单词"嚼碎",提取出里面的语义信息,压缩成一个中间状态(State / Context Vector)。你可以把它理解为翻译员在听完一句话后,脑子里形成的那个"抽象的意思"。 - 解码器(Decoder / "口语表达员") :
它本身是一个条件语言模型。它的任务是接收编码器传过来的"抽象意思(State)",然后结合目标语言的语法结构,一个词一个词地把翻译结果"吐"出来。
6.2 编码器基类 (Encoder)
编码器的接口非常简单,只需要明确:它接收输入序列 X,并输出特征。
python
from torch import nn
from d2l import torch as d2l
class Encoder(nn.Module): # 继承自 PyTorch 的基础网络大类 nn.Module
"""编码器-解码器架构的基本编码器接口"""
def __init__(self):
super().__init__() # 初始化父类
# forward 是前向传播函数
# X 是输入的源语言张量(比如英语单词的索引)
# *args 允许传入不定数量的其他参数(比如上一节提到的序列有效长度 valid_length)
def forward(self, X, *args):
# 抛出 NotImplementedError 异常
# 意思是:这是一个抽象基类,不能直接运行!
# 后面如果我们写 RNNEncoder,必须继承这个类并自己重写 forward 方法。
raise NotImplementedError6.3 解码器基类 (Decoder)
解码器比编码器多了一个关键步骤:它必须先接收编码器送来的知识,转化为自己的初始状态。
python
class Decoder(nn.Module): # 同样继承自 nn.Module
"""编码器-解码器架构的基本解码器接口"""
def __init__(self):
super().__init__()
# 关键方法 1:初始化解码器的隐藏状态
# enc_all_outputs:这是编码器运行完毕后输出的所有信息。
# 它的任务是把编码器的输出,转换/包装成解码器在第 0 个时间步需要的初始状态 state。
def init_state(self, enc_all_outputs, *args):
raise NotImplementedError
# 关键方法 2:前向传播生成输出
# X:目标语言的输入序列(比如前面小节提到的带有 <bos> 的法语序列)
# state:当前解码器内部的记忆状态(包含了源语言的信息)
def forward(self, X, state):
raise NotImplementedError6.4 将编码器和解码器组装起来 (EncoderDecoder)
python
class EncoderDecoder(d2l.Classifier): # 继承 D2L 的分类器基类,方便后续算 Loss
"""编码器-解码器架构的基类"""
# 初始化时,要把实例化的 encoder 和 decoder 传进来
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder # 将编码器作为自己的一个子模块
self.decoder = decoder # 将解码器作为自己的一个子模块
# 总前向传播逻辑
# enc_X: 源语言输入(英语)
# dec_X: 目标语言输入(法语,用来做教师强制 Teacher Forcing 的)
def forward(self, enc_X, dec_X, *args):
# 第 1 步:把英语输入交给编码器,提取全部特征输出
enc_all_outputs = self.encoder(enc_X, *args)
# 第 2 步:解码器拿编码器的特征,初始化自己的大脑状态 (dec_state)
dec_state = self.decoder.init_state(enc_all_outputs, *args)
# 第 3 步:解码器结合法语输入 dec_X 和内部状态 dec_state,进行翻译预测
# 为什么要在最后加上 [0]?
# 因为后续我们写的具体的 decoder(dec_X, dec_state) 通常会返回一个元组:
# (预测的输出张量, 更新后的新 state)
# 对于外层整个网络来说,我们只需要"预测的输出张量"去算误差,所以取第 0 个元素。
return self.decoder(dec_X, dec_state)[0]一些练习
1. 假设我们使用神经网络实现编码器-解码器架构。编码器和解码器必须是同一种类型的神经网络吗?
- 解答:绝对不是。它们完全可以是不同类型的网络。
- 架构接口的设计精髓就在于解耦(Decoupling) 。只要编码器输出的张量形状,能被解码器的
init_state函数正确解析,它们内部到底是用什么算法,互相根本不在乎。- 比如在经典的"图像描述生成(Image Captioning)"任务中:
- 编码器 :通常是一个 CNN(如 ResNet),用来把图片压缩成一个特征向量。
- 解码器 :通常是一个 RNN 或 LSTM,用来根据这个图片向量逐字生成一句话。
- 再比如语音识别:编码器可能是处理音频的 Conformer,解码器是处理文本的 Transformer。
2. 除了机器翻译,你能想到编码器-解码器架构可以应用的其他应用场景吗?
- 解答:太多了。只要是输入和输出结构不对齐的任务,全都是它的应用场景:
- 文本摘要(Text Summarization):输入一篇 1000 字的长文章(Encoder 压缩),输出一句 50 字的总结(Decoder 生成)。
- 语音识别(Speech Recognition):输入一段连续的语音声波(Encoder 听写),输出对应的文字序列(Decoder 输出)。
- 对话机器人(Chatbot/QA System):输入用户的提问(Encoder 理解),输出 AI 的回答(Decoder 说话)。
- 手语翻译:输入一段手语动作的视频帧序列,输出翻译后的文本语言。
- 代码注释生成:输入一段 Python 代码,输出这段代码作用的中文解释。
七、Seq2seq
7.1 核心思想概述
在机器翻译中,输入(比如英语)和输出(比如法语)的句子长度往往是不同的,且词与词之间没有严格的对齐关系。为了解决这种"变长输入 -> 变长输出"的问题,我们使用 编码器-解码器 (Encoder-Decoder) 架构。
- Encoder (编码器):负责把变长的输入序列,压缩成一个固定长度的上下文变量(Context Variable,通常是RNN的最终隐藏状态)。
- Decoder (解码器) :根据这个上下文变量和之前生成的词,一个词一个词地生成目标序列,直到输出结束符
<eos>。
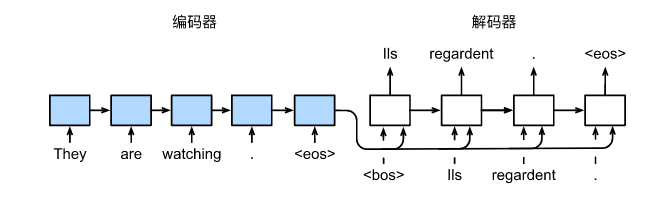
使用循环神经网络编码器和循环神经网络解码器的序列到序列学习
- 编码器是一个RNN,读取输入句子
- 可以是双向
- 解码器使用另外一个RNN来输出
编码器-解码器细节
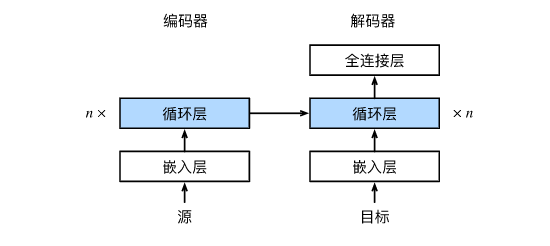
循环神经网络编码器-解码器模型中的层
- 编码器是没有输出的RNN
- 编码器最后时间步的隐状态用作解码器的初始隐状态
7.2 Teacher Forcing
这是 Seq2Seq 训练时使用的一种非常重要的技巧。
- 如果在预测时 :解码器在第 t t t 步的输入,是它自己在第 t − 1 t-1 t−1 步预测出来的词。
- 如果在训练时 :如果一开始模型很笨,第 t − 1 t-1 t−1 步预测错了,那么第 t t t 步及以后就全错了(一步错步步错)。为了加速收敛,我们使用教师强制 :在训练时,不管解码器上一步预测出了什么,我们在第 t t t 步都强行把真实的正确标签 (Ground Truth) 喂给它作为输入。
- 具体做法 :假设真实法语目标是
"Ils", "regardent", ".", "<eos>"。- 解码器的输入 序列是:
"<bos>", "Ils", "regardent", "." - 解码器的预测目标 (Label) 是:
"Ils", "regardent", ".", "<eos>"
- 解码器的输入 序列是:
7.3 衡量生成序列的好坏的BLEU
虽然 (Papineni et al., 2002) 提出的BLEU(bilingual evaluation understudy) 最先是用于评估机器翻译的结果, 但现在它已经被广泛用于测量许多应用的输出序列的质量。
原则上说,对于预测序列中的任意 n 元语法(n-grams),BLEU的评估都是这个 n 元语法是否出现在标签序列中。
我们将BLEU定义为:
e x p ( m i n ( 0 , 1 − l e n l a b e l l e n p r e d ) ) ∏ n = 1 k p n 1 / 2 n exp(min(0, 1-\frac{len_{label}}{len_{pred}}))\prod_{n=1}^{k}p_{n}^{1/2^n} exp(min(0,1−lenpredlenlabel))n=1∏kpn1/2n
如何计算pn?首先要了解n-gram
**n-gram(n元语法):**在评估时,我们不仅看单个词(1-gram / unigram)对不对,还要看连续的两个词(2-gram / bigram)、三个词(3-gram / trigram)对不对。
真实标签 (Label): A B C D E
预测输出 (Pred): A B E C D
1-gram 匹配: A, B, C, D, E 全部都在标签中存在,1-gram 准确率 5/5 = 100%(词都用对了)。
2-gram 匹配: 预测的 2-gram 有 AB, BE, EC, CD。但在真实标签中只有 AB 和 CD 存在。所以 2-gram 准确率只有 2/4 = 50%(语序有瑕疵)。截断机制
如果没有截断机制,模型可能会钻空子。
- 真实标签: The cat is on the mat (其中 'the' 出现了 2 次)
- 预测作弊输出: The the the the the the
如果不加限制,预测句子的 6 个 the 在真实标签中都能找到匹配!1-gram 准确率会变成 6/6 = 100%。这显然荒谬。
BLEU 的解决办法(截断):
- 一个词(或词组)在预测匹配中的最高得分次数,不能超过它在真实标签中出现的总次数。
- 在上面的例子中,The 在真实标签里只出现了 2 次,所以这 6 个 the 最多只能算匹配对上了 2 次。
- 真实的 1-gram 准确率 p1 = 2 / 6 = 33.3%。
短句惩罚 (Brevity Penalty)
模型还有另一种作弊方式:只翻译最有把握的短句。
- 真实标签: I love deep learning very much . (7个词)
- 预测作弊输出: I love . (3个词)
这个预测句子的 1-gram (I, love, .) 全部命中。2-gram (I love) 也命中。如果不做处理,这个极短的废话句子会拿到接近满分。
解决方案就是公式中的: e x p ( m i n ( 0 , 1 − l e n l a b e l l e n p r e d ) ) exp(min(0, 1 - \frac{len_{label}}{len_{pred}})) exp(min(0,1−lenpredlenlabel))
7.4 代码实现
7.4.1 embedding
我们通常会将token分配ID,但是为了避免ID大小对于训练的影响,所以会进一步的独热编码(One-Hot)。
独热编码有一些缺点:
- 浪费空间:10000 维的向量里只有一个 1,计算极其低效。
- 没有语义关联 :在 One-Hot 看来,
"cat"和"dog"的距离,与"cat"和"apple"的距离是一模一样的(它们的向量内积都是 0)。它完全没有"猫和狗都是动物"这种概念。
解决方案:Word Embedding (词嵌入):将 One-Hot 编码压缩成一个固定长度的、连续的浮点数向量。
pytorch提供了nn.Embedding(vocab_size, embed_size)
在底层其实就是创建了一个巨大的二维权重矩阵。
vocab_size(词表大小) :矩阵的行数。词表里有多少个不同的词,就有多少行。embed_size(嵌入维度) :矩阵的列数。你希望用多少个浮点数来表示一个词?(比如 D2L 代码里设置的是 256)。
例:
假设 vocab_size = 5(词表里只有5个词),embed_size = 3(用3维向量表示)。
nn.Embedding(5, 3) 就会在内存里随机初始化一个 5 行 3 列的表格:
| 词 ID (行索引) | 代表的词 | 维度1 (特征1) | 维度2 (特征2) | 维度3 (特征3) |
|---|---|---|---|---|
| 0 | <pad> |
0.12 | -0.54 | 0.88 |
| 1 | "I" |
-1.22 | 0.34 | 0.01 |
| 2 | "love" |
0.99 | -0.11 | -0.77 |
| 3 | "AI" |
0.45 | 1.05 | -0.33 |
| 4 | "<eos>" |
-0.05 | 0.22 | 0.19 |
值得注意的是,该矩阵是可学习的,并非一成不变
7.4.2 Encoder 实现
相关库
python
import collections
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l编码器的任务是提取输入句子的特征。这里使用的是多层 GRU (门控循环单元)。
python
def init_seq2seq(module):
"""初始化 Seq2Seq 模型的权重"""
if type(module) == nn.Linear:
nn.init.xavier_uniform_(module.weight) # 线性层使用 Xavier 初始化
if type(module) == nn.GRU:
for param in module._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(module._parameters[param]) # GRU 权重使用 Xavier 初始化
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列学习的 RNN 编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0):
super().__init__()
# 1. 嵌入层:将输入的词索引 (如 5) 转换为稠密向量 (维度为 embed_size)
self.embedding = nn.Embedding(vocab_size, embed_size)
# 2. 循环神经网络:这里使用的是 GRU。输入特征维度是 embed_size,隐藏层维度是 num_hiddens
self.rnn = d2l.GRU(embed_size, num_hiddens, num_layers, dropout)
# 3. 应用上面定义的初始化函数
self.apply(init_seq2seq)
def forward(self, X, *args):
# 此时 X 的形状是: (batch_size, num_steps) [批量大小, 时间步数/句子长度]
# 将 X 转置为 (num_steps, batch_size),然后传入 embedding 层
# 为什么转置?因为 PyTorch 的 RNN 默认期望输入的第一个维度是时间步 (Sequence Length)
embs = self.embedding(X.t().type(torch.int64))
# 此时 embs 的形状: (num_steps, batch_size, embed_size)
# 将词嵌入输入到 GRU 中
# outputs: 每一个时间步的顶层隐藏状态
# state: 最后一个时间步的所有层的隐藏状态
outputs, state = self.rnn(embs)
# outputs 形状: (num_steps, batch_size, num_hiddens)
# state 形状: (num_layers, batch_size, num_hiddens)
return outputs, state例:
我们初始化一个16层隐藏层的双层GRU。小批量的输入X
最后层的所有时间步的隐状态的shape:(number of time steps, batch size, number of hidden units)
python
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2
batch_size, num_steps = 4, 9
encoder = Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers)
X = torch.zeros((batch_size, num_steps))
enc_outputs, enc_state = encoder(X)
d2l.check_shape(enc_outputs, (num_steps, batch_size, num_hiddens))因为我们用的是GRU,最后一个时间步的隐状态为(number of hidden layers, batch size, number of hidden units).
python
d2l.check_shape(enc_state, (num_layers, batch_size, num_hiddens))7.4.3 Decoder 实现
解码器的任务是根据编码器传过来的 state 生成翻译。
为了强化上下文信息,论文中采用了一种设计:在解码的每一个时间步,都把编码器的最终隐藏状态 (Context Variable) 与解码器当前的输入拼接在一起。
python
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的 RNN 解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0):
super().__init__()
# 1. 目标语言的嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
# 2. 注意这里的输入维度是 embed_size + num_hiddens
# 因为我们会在每个时间步把上下文变量 (维度 num_hiddens) 和当前词嵌入 (维度 embed_size) 拼接
self.rnn = d2l.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout)
# 3. 输出的全连接层,用于预测下一个词在词表中的概率分布
self.dense = nn.LazyLinear(vocab_size)
self.apply(init_seq2seq)
def init_state(self, enc_all_outputs, *args):
# 使用编码器的输出初始化解码器的状态
# enc_all_outputs 包含了 [outputs, state], 这里只提取 state 返回
return enc_all_outputs
def forward(self, X, state):
# X 是目标序列 (如教师强制的输入), 形状: (batch_size, num_steps)
# 1. 获取词嵌入,转置以满足 RNN 要求
embs = self.embedding(X.t().type(torch.int32)) # embs: (num_steps, batch_size, embed_size)
# 2. 解包传递过来的状态
enc_output, hidden_state = state
# 3. 提取上下文变量 context
# enc_output 是编码器最后一层的全部状态,形状 (num_steps, batch_size, num_hiddens)
# enc_output[-1] 提取最后一个时间步的状态作为 context,形状 (batch_size, num_hiddens)
context = enc_output[-1]
# 4. 广播 context 使其在时间步维度上与 embs 对齐
# 形状变为 (num_steps, batch_size, num_hiddens)
context = context.repeat(embs.shape[0], 1, 1)
# 5. 将词嵌入和上下文拼接在特征维度 (最后一个维度 dim=-1)
# 拼接后形状: (num_steps, batch_size, embed_size + num_hiddens)
embs_and_context = torch.cat((embs, context), -1)
# 6. 将拼接后的输入和隐藏状态传入 RNN
outputs, hidden_state = self.rnn(embs_and_context, hidden_state)
# 7. 经过全连接层得到词汇表大小的输出,并将时间步和批量大小的维度换回来
# outputs 最终形状: (batch_size, num_steps, vocab_size)
outputs = self.dense(outputs).swapaxes(0, 1)
# 返回预测结果,并把当前的 hidden_state 传回以便下一步使用
return outputs, [enc_output, hidden_state]7.4.4 Encoder-Decoder
python
class Seq2Seq(d2l.EncoderDecoder): #@save
"""The RNN encoder--decoder for sequence to sequence learning."""
def __init__(self, encoder, decoder, tgt_pad, lr):
super().__init__(encoder, decoder)
self.save_hyperparameters()
def validation_step(self, batch):
Y_hat = self(*batch[:-1])
self.plot('loss', self.loss(Y_hat, batch[-1]), train=False)
def configure_optimizers(self):
# Adam optimizer is used here
return torch.optim.Adam(self.parameters(), lr=self.lr)7.4.5 带掩码的损失函数
计算损失(Loss)时有一个大问题:
为了打包成 Batch 进行矩阵运算,较短的句子都在末尾填充了 <pad> 标记。我们不应该让模型为了预测 <pad> 标记而更新权重.
因此,我们需要使用掩码 (Mask) 把填充部分过滤掉。
loss 函数
python
@d2l.add_to_class(Seq2Seq)
def loss(self, Y_hat, Y):
# 调用父类方法计算交叉熵损失,averaged=False 表示先不求平均
# l 的形状将是一维序列 (batch_size * num_steps)
l = super(Seq2Seq, self).loss(Y_hat, Y, averaged=False)
# 构造掩码 mask: 如果标签 Y 不是填充词 (<pad>),则掩码为 1,否则为 0
# Y.reshape(-1) 把标签展平为一维
mask = (Y.reshape(-1) != self.tgt_pad).type(torch.float32)
# l * mask:将预测 <pad> 产生的 loss 强行置为 0
# 然后求和,再除以有效标记 (1的数量) 的总数,求得平均有效 loss
return (l * mask).sum() / mask.sum()7.4.6 训练
python
data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab['<pad>'],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)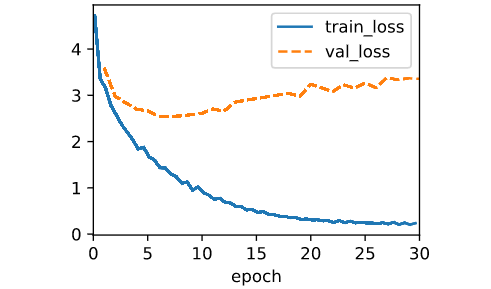
7.4.7 预测
训练时我们有Teacher Forcing,但测试/预测时,我们手里没有标准答案了。
我们只能:把当前步生成的词,当作下一步的输入。 (自回归 Auto-regressive 生成)。
python
@d2l.add_to_class(d2l.EncoderDecoder)
def predict_step(self, batch, device, num_steps, save_attention_weights=False):
# 将数据移到 GPU
batch = [a.to(device) for a in batch]
src, tgt, src_valid_len, _ = batch
# 1. 编码器处理输入源序列,获取上下文
enc_all_outputs = self.encoder(src, src_valid_len)
# 初始化解码器状态
dec_state = self.decoder.init_state(enc_all_outputs, src_valid_len)
# 2. 准备解码器的第一个输入:形状为 (batch_size, 1) 的 <bos> (句子开头标记)
# tgt[:, (0)] 提取的就是每个目标句子的第一个词 <bos>
outputs, attention_weights = [tgt[:, (0)].unsqueeze(1), ], []
# 3. 循环逐步生成词 (最多生成 num_steps 步)
for _ in range(num_steps):
# 喂入上一步预测出的词 outputs[-1],获取当前步输出 Y
Y, dec_state = self.decoder(outputs[-1], dec_state)
# Y.argmax(2) 找出概率最大的词的索引,作为这一步的预测结果
# 并把它追加到 outputs 列表中,供下一步使用
outputs.append(Y.argmax(2))
if save_attention_weights: # (给下一章注意力机制留的接口)
attention_weights.append(self.decoder.attention_weights)
# 将除第一个 <bos> 之外的预测词拼接成序列返回
return torch.cat(outputs[1:], 1), attention_weights一些课后练习
- 调整超参数来改进翻译结果 :可以通过增大隐藏层大小 (
num_hiddens)、层数 (num_layers),或者增加训练 Epoch 来尝试提升 BLEU。- loss不使用 Mask会怎样 :如果不使用 Mask,模型会花费大量精力去拟合那些
<pad>标记,导致对有效词汇的翻译能力下降,Loss 看起来会变小(因为很多0被算作预测正确),但实际翻译质量会变差。- 编码器/解码器层数不同如何初始化:不能直接把 Encoder 的 state 赋给 Decoder。需要通过一个全连接层(Linear Layer)对 Encoder 的 final state 进行线性变换(投影),映射到 Decoder 需要的形状。
- 取消Teacher Forcing:训练会变得非常不稳定,收敛极慢。因为前期预测几乎全是错的,模型拿着错的输入去学下一步,如同盲人摸象。
- 替换为 LSTM :LSTM 输出的状态包含
(hidden_state, cell_state)两个张量,只需在初始化和前向传播时确保这两个张量同时传递即可。
八、束搜索
8.1 束搜索 (Beam Search)
预测时的困境:
在seq2seq中,我们训练好了一个机器翻译模型。但在测试/预测阶段,我们没有真实的标签(Teacher Forcing 不能用了),我们需要一个词一个词地生成句子。
面临的问题是:在每一个时间步,词汇表里有上万个词,我们该选哪一个作为输出?
这就引出了三种搜索策略:贪心搜索、穷举搜索,以及本节的主角------束搜索。
1. 贪心搜索 (Greedy Search)
在每一个时间步 t t t,模型都会计算词汇表中所有词的概率,贪心搜索直接选择当前概率最高的那个词。
- y t ′ = argmax y ∈ Y P ( y ∣ y 1 , ... , y t − 1 , c ) y_t' = \operatorname*{argmax}{y \in \mathcal{Y}} P(y \mid y_1, \ldots, y{t-1}, \mathbf{c}) yt′=argmaxy∈YP(y∣y1,...,yt−1,c)
- 解释 :在给定上下文 c \mathbf{c} c 和之前生成的词的情况下,选出让当前概率 P P P 最大的词 y y y。
优点 :计算极快,时间复杂度是 O ( ∣ Y ∣ × T ) \mathcal{O}(|\mathcal{Y}| \times T) O(∣Y∣×T)(词表大小 × \times × 句子长度)。
致命缺点 :局部最优不等于全局最优。
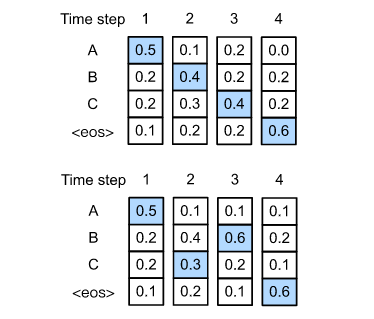
我们在第二步选择并非局部最优的决策反而得到了更好的结果
0.5 x 0.4 x 0.4 x 0.6 = 0.048 => 0.5 x 0.3 x 0.6 x 0.6 = 0.054
2. 穷举搜索 (Exhaustive Search)
思想 :既然贪心搜索会漏掉全局最优,那我就把所有可能的句子组合全算一遍,最后挑一个概率最大的。
优点 :绝对能找到全局最优解。
致命缺点:计算量大到宇宙毁灭。
- 假设词表大小 ∣ Y ∣ = 10000 |\mathcal{Y}| = 10000 ∣Y∣=10000,句子长度 T = 30 T = 30 T=30。
- 时间复杂度是 O ( ∣ Y ∣ T ) \mathcal{O}(|\mathcal{Y}|^T) O(∣Y∣T),即 10000 30 10000^{30} 1000030 种组合。现有的任何超级计算机都算不完。因此,这只存在于理论中,完全不实用。
3. 束搜索 (Beam Search) ------ 完美的折中方案
思想 :结合贪心和穷举的优点。我们不全搜,也不只看第一名。我们设定一个束宽 (Beam Size) k k k 。在每一步,我们永远保留当前概率最高的 k k k 个候选序列。
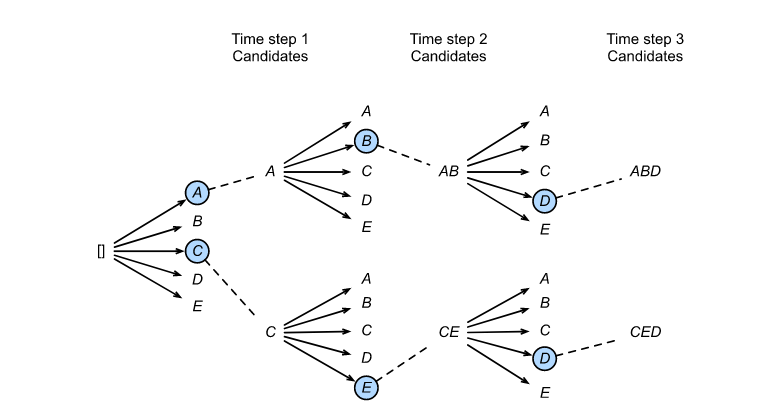
假设词表只有 5 个词,束宽 k = 2 k=2 k=2,最大长度 T = 3 T=3 T=3。
-
时间步 1 :
计算所有 5 个词的概率。选出概率最高的 k = 2 k=2 k=2 个词。假设是 A A A 和 C C C。
现在我们的候选篮子里有 2 个序列:
[A]和[C]。 -
时间步 2:
- 对于候选
[A],我们计算它后面接 5 个词的联合概率: P ( A , 后面接的词 ) = P ( A ) × P ( 后面接的词 ∣ A ) P(A, 后面接的词) = P(A) \times P(后面接的词|A) P(A,后面接的词)=P(A)×P(后面接的词∣A)。产生 5 个新候选。 - 对于候选
[C],同样计算: P ( C , 后面接的词 ) = P ( C ) × P ( 后面接的词 ∣ C ) P(C, 后面接的词) = P(C) \times P(后面接的词|C) P(C,后面接的词)=P(C)×P(后面接的词∣C)。产生 5 个新候选。 - 现在我们一共有了 2 × 5 = 10 2 \times 5 = 10 2×5=10 个候选序列。
- 关键裁剪 :我们只保留这 10 个中概率最高的 k = 2 k=2 k=2 个!假设保留下来的是
[A, B]和[C, E]。其他 8 个全部无情丢弃。
- 对于候选
-
时间步 3 (公式 10.8.3 解释) :
重复上面的操作。基于
[A, B]展开 5 个,基于[C, E]展开 5 个。在 10 个中再挑出最优的 2 个。
时间复杂度 : O ( k × ∣ Y ∣ × T ) \mathcal{O}(k \times |\mathcal{Y}| \times T) O(k×∣Y∣×T)。
这是一种非常可控的计算量。当 k = 1 k=1 k=1 时,束搜索就退化成了贪心搜索。在实际应用中,机器翻译通常将 k k k 设置在 5 5 5 到 10 10 10 之间。
8.2 scoring
当我们跑完束搜索,或者遇到 <eos> 结束符时,我们会得到一组(通常是 k k k 个)最终的候选句子。我们要从中选出一个真正的冠军。
我们用如下公式来计算得分:
1 L α log P ( y 1 , ... , y L ) = 1 L α ∑ t ′ = 1 L log P ( y t ′ ∣ y 1 , ... , y t ′ − 1 , c ) \frac{1}{L^\alpha} \log P(y_1, \ldots, y_L) = \frac{1}{L^\alpha} \sum_{t'=1}^L \log P(y_{t'} \mid y_1, \ldots, y_{t'-1}, \mathbf{c}) Lα1logP(y1,...,yL)=Lα1t′=1∑LlogP(yt′∣y1,...,yt′−1,c)
-
为什么要用 log \log log (对数) 和 ∑ \sum ∑ (求和)?
概率是 0 0 0 到 1 1 1 之间的小数。几十个小数连乘(比如 0.1 × 0.2 × ... 0.1 \times 0.2 \times \dots 0.1×0.2×...)会变得非常非常小,导致计算机出现数值下溢 (Underflow) 变成 0。
根据数学公式 log ( A × B ) = log ( A ) + log ( B ) \log(A \times B) = \log(A) + \log(B) log(A×B)=log(A)+log(B),取对数后,连乘变成了对数概率的连加,这在计算机中极其稳定。
-
为什么要除以 L α L^\alpha Lα? (长度惩罚 Length Penalty)
注意:因为概率小于 1,所以它们的对数全是负数 (比如 log ( 0.1 ) = − 2.3 \log(0.1) = -2.3 log(0.1)=−2.3)。
一个句子越长,加的负数就越多,它的总得分就越低。
如果不加任何限制,模型为了拿高分,会倾向于输出极短的句子(比如只输出一个 "OK" 就结束了)。
- L L L 是生成句子的实际长度。
- α \alpha α 是一个超参数,通常设为 0.75 0.75 0.75。
- 除以 L 0.75 L^{0.75} L0.75 的作用是:给长句子一些补偿。分数除以一个大于 1 的数,负数的绝对值变小了,相当于提高了长句子的得分,防止模型过度偏好短句。
一些练习
练习 1:我们可以把穷举搜索看作是一种特殊类型的束搜索吗?为什么?
解答:
可以。当我们将束搜索的束宽(Beam Size) k k k 设置得足够大,大到等于词汇表大小的 T T T 次方(即 k = ∣ Y ∣ T k = |\mathcal{Y}|^T k=∣Y∣T),或者在实际操作中,将 k k k 设置为词表大小 ∣ Y ∣ |\mathcal{Y}| ∣Y∣,并且在每个时间步不丢弃任何候选序列 (即把所有的分支都保留下来),那么束搜索就完全等同于穷举搜索。
因为穷举搜索本质上就是不加任何剪枝(Pruning)的树的广度优先遍历,而束搜索是一种带有 k k k 个节点容量限制的剪枝遍历。容量无限大时,两者等价。
练习 2:在 10.7 节的机器翻译问题中应用束搜索。束宽如何影响翻译结果和预测速度?
解答:
- 对翻译结果(BLEU 分数)的影响 :
- 增加束宽 k k k(比如从 1 增加到 5),通常会显著提高翻译质量和 BLEU 分数,因为模型探索了更多可能性,避开了贪心搜索造成的局部死胡同。
- 但是,当 k k k 继续增大(比如大于 10 或 20 后),翻译质量的提升会遇到瓶颈,甚至可能出现轻微下降。因为过大的 k k k 可能会让模型找出一个在语言模型上概率极高,但偏离了原文语义的短句(即使有长度惩罚)。
- 对预测速度的影响 :
- 计算时间与束宽 k k k 呈线性正相关 。 k = 5 k=5 k=5 时的预测时间大约是 k = 1 k=1 k=1 (贪心搜索) 的 5 倍。因为每次解码 RNN 都需要进行 k k k 次并行的前向传播计算。巨大的 k k k 会导致推理速度过慢,无法满足实时翻译的需求。
练习 3:我们在第 9.5 节中使用了语言模型来生成用户提供前缀后的文本。它使用的是哪种搜索策略?你能改进它吗?
解答:
- 第 9.5 节使用的策略 :
在之前的 RNN 语言模型生成文本时,代码中通常使用的是贪心搜索 (Greedy Search) (直接取argmax),或者使用了简单的温度采样 (Temperature Sampling / Multinomial Sampling)(按概率分布随机抽样)。- 如何改进?
- 引入束搜索 (Beam Search):可以生成语法更连贯、逻辑更严密的句子,非常适合翻译或摘要等需要"准确性"的任务。
- 引入 Top-k 采样 :在每一步不只取概率最高的一个,也不考虑所有词,而是只从概率排名前 k k k 的词中按权重随机抽取。
- 引入 Top-p 采样 (Nucleus Sampling, 核采样) :这是目前 ChatGPT 等大模型生成文本的主流方法。不固定选 k k k 个,而是将概率从高到低累加,直到累加概率达到 p p p(如 0.9 0.9 0.9),然后在这些词中随机抽样。这能保证生成的文本既有极高的质量,又充满了人类语言的多样性和创造性(比纯束搜索更生动)。