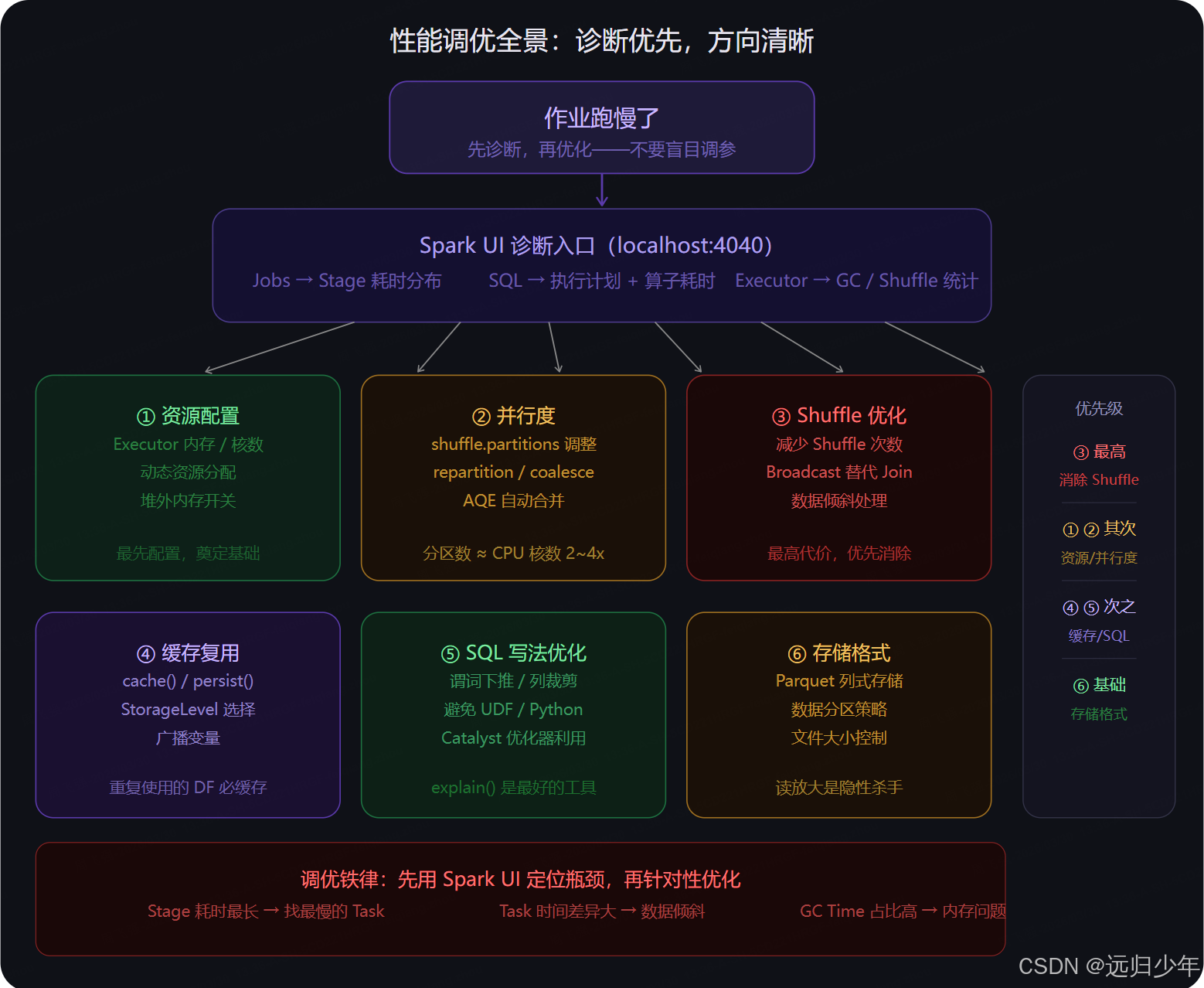
调优铁律:先用 Spark UI 定位瓶颈,再针对性优化------不要盲目调参。 性能问题 80% 来自数据倾斜和 Shuffle,20% 来自资源配置不当。本章覆盖六大调优方向,从诊断到实战,提供可直接落地的配置和代码。
目录
- [诊断优先:Spark UI 全解读](#诊断优先:Spark UI 全解读)
- 方向一:资源配置
- 方向二:并行度调优
- [方向三:Shuffle 优化](#方向三:Shuffle 优化)
- 方向四:数据倾斜
- 方向五:缓存与广播
- [方向六:SQL 写法与存储格式](#方向六:SQL 写法与存储格式)
- 调优决策流程
- 完整配置速查
诊断优先:Spark UI 全解读
调优的第一步永远是看 Spark UI,找到真正的瓶颈。盲目调参不仅无效,还可能引入新问题。

Spark UI 关键指标解读
python
# 代码级诊断:explain + 执行计划分析
df.explain("formatted") # 查看 *(N) 是否生效、Exchange 在哪
# 查看 Stage 统计
# Spark UI → Stages → 点击具体 Stage → 看 Summary Metrics:
# - Duration: 最大值远超中位数 → 倾斜
# - Shuffle Read Size: 某 Task 远大于其他 → 热点 Key
# - GC Time / Duration > 10% → 内存不足方向一:资源配置
资源配置是调优的地基,配错了后续所有优化都是事倍功半。

内存配置公式
python
# ── 内存三件套 ──
# executor.memory = JVM 堆内存(统一内存 60% + 用户内存 40%)
# memoryOverhead = executor.memory × 10%(JVM 堆外:线程栈、字符串等)
# offHeap.size = 独立配置,给 Tungsten 使用(可选)
#
# YARN 容器分配 = executor.memory × 1.1 + offHeap.size
# 不能超过 YARN 节点的容器上限,否则 Container 被 Kill
spark = SparkSession.builder \
.config("spark.executor.memory", "8g") # JVM 堆
.config("spark.executor.cores", "4") # 每 Executor 核数
.config("spark.executor.memoryOverhead", "2g") # 堆外开销(默认 10%)
.config("spark.memory.offHeap.enabled", "true") # 开启 Tungsten 堆外
.config("spark.memory.offHeap.size", "4g") # Tungsten 堆外大小
.config("spark.dynamicAllocation.enabled", "true") # 动态资源分配
.config("spark.dynamicAllocation.minExecutors", "2")
.config("spark.dynamicAllocation.maxExecutors", "50")
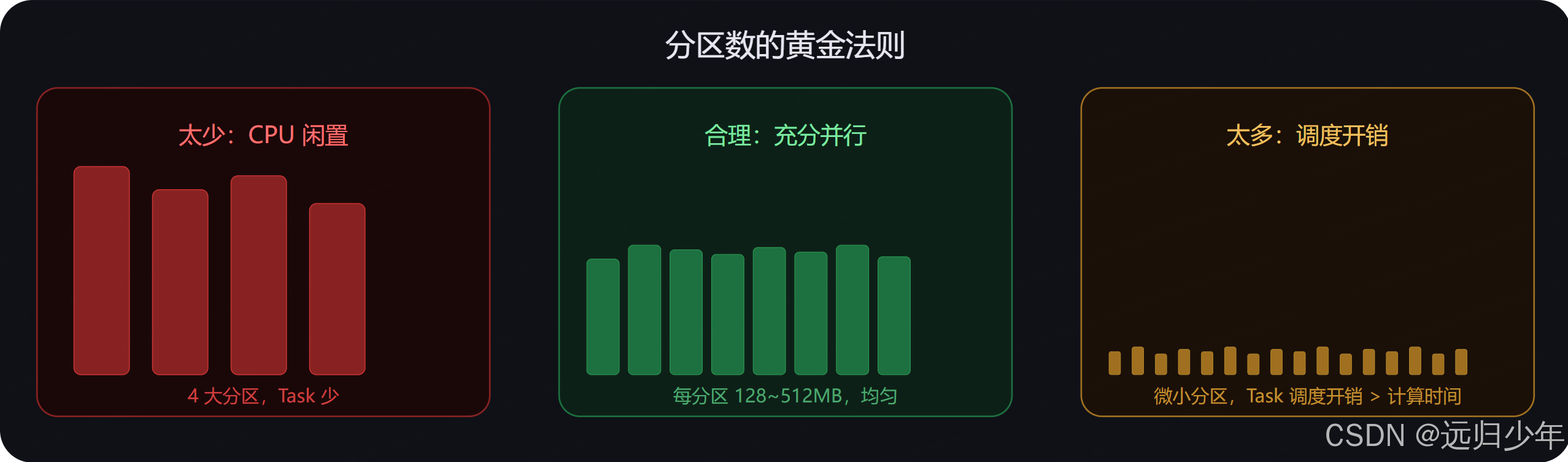
.getOrCreate()方向二:并行度调优
并行度不足和过高都会导致性能下降。

并行度调优代码
python
# ── Shuffle 后分区数(最重要的参数)──
# 默认 200,按数据量调整
# 目标:每分区 128~512 MB
spark.conf.set("spark.sql.shuffle.partitions", "400")
# ── AQE 自动合并(强烈推荐)──
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "128mb")
# AQE 会在运行时自动把小分区合并成目标大小
# ── 手动控制分区数 ──
# 增加分区(数据量大时)
df = df.repartition(800) # 全量 Shuffle,数据均匀
df = df.repartition(800, "city") # 按 key Hash 分区,同 key 在同分区
# 减少分区(写出前合并)
df = df.coalesce(10) # 不触发 Shuffle,合并相邻分区
df = df.repartition(10) # 触发 Shuffle,数据更均匀
# ── 经验公式 ──
# shuffle.partitions = max(集群总核数 × 2, 数据总大小MB / 200)
# 例如:200 核集群,500GB 数据 → max(400, 2500) = 2500方向三:Shuffle 优化
Shuffle 是 Spark 最贵的操作,优化的本质是减少 Shuffle 次数 和减少每次的数据量。

Shuffle 优化代码
python
# ── ① 先过滤再 Shuffle ──
# 差:join 涉及全量数据
result = orders_df.join(users_df, "user_id") \
.filter(col("city") == "BJ")
# 好:过滤后数据量小,Shuffle 传输少
result = orders_df.filter(col("city") == "BJ") \
.join(users_df, "user_id")
# ── ② Broadcast Join 消除 Shuffle ──
from pyspark.sql.functions import broadcast
# 强制广播小表(无论大小)
result = large_df.join(broadcast(dim_df), "key")
# 调大自动广播阈值(谨慎,广播太大会 OOM Driver)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "200mb")
# ── ③ reduceByKey 替代 groupByKey ──
# 差:所有数据先 Shuffle 到 Reduce 端再聚合
rdd.groupByKey().mapValues(sum)
# 好:Map 端先局部聚合,大幅减少 Shuffle 数据量
rdd.reduceByKey(lambda a, b: a + b)
# ── ④ AQE 配置 ──
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "128mb")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "5")方向四:数据倾斜
数据倾斜是 Spark 性能最大的敌人。一个超大分区会让整个 Stage 的完成时间等于这个分区的处理时间。


数据倾斜代码
python
# ── 方案三:Key 加盐(两表都大时)──
import random
from pyspark.sql.functions import concat, lit, col, floor, rand, explode, array
SALT_NUM = 10 # 盐的粒度,按倾斜程度调整
# Step 1:倾斜表加随机盐前缀
skewed_df = df_large.withColumn(
"salted_key",
concat(lit(str(int(random.random() * SALT_NUM))), lit("_"), col("key"))
)
# Step 2:小表/对侧表复制 SALT_NUM 份
replicated_df = df_other.withColumn(
"salt_idx", explode(array([lit(str(i)) for i in range(SALT_NUM)]))
).withColumn(
"salted_key", concat(col("salt_idx"), lit("_"), col("key"))
)
# Step 3:按 salted_key join(BJ 被拆成 10 个子分区并行)
result = skewed_df.join(replicated_df, "salted_key")
# ── 方案四:NULL Key 过滤处理 ──
non_null_df = df.filter(col("key").isNotNull())
null_df = df.filter(col("key").isNull())
result_non_null = non_null_df.groupBy("key").agg(...)
result_null = null_df.agg(...) # 单独处理 NULL
final = result_non_null.union(result_null)方向五:缓存与广播
缓存让重复使用的数据只计算一次;广播让小数据本地化,消除 Shuffle。
缓存的选择与时机
python
from pyspark import StorageLevel
# ── StorageLevel 选择 ──
# MEMORY_ONLY 最快,内存不足时自动丢弃(下次重算)
# MEMORY_AND_DISK 推荐:溢写磁盘,不丢失,适合大多数场景
# MEMORY_AND_DISK_SER 序列化存储,内存节省约 2x,CPU 稍高
# DISK_ONLY 内存极紧时用,慢
df.persist(StorageLevel.MEMORY_AND_DISK) # 推荐默认
# ── 什么时候缓存 ──
# ✓ 同一 DataFrame 后续被用 2 次以上
# ✓ 迭代算法中的基础数据集(ML 训练)
# ✗ 只用一次的 DataFrame(白白占内存)
# ✗ 数据量超过集群总内存(缓存反而更慢)
# ── 缓存 + 解缓存 ──
feature_df = spark.read.parquet("s3://bucket/features/").cache()
feature_df.count() # 触发缓存(lazy)
# ... 多次使用 feature_df ...
feature_df.unpersist() # 用完及时释放,避免挤占 Shuffle 内存
# ── 广播变量(比 broadcast() 更底层,适合非 Join 场景)──
from pyspark.sql.functions import broadcast
config_dict = {"BJ": "华北", "SH": "华东"}
bc = spark.sparkContext.broadcast(config_dict)
# Executor 端直接访问本地内存,无网络开销
def map_region(city):
return bc.value.get(city, "未知")
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
map_udf = udf(map_region, StringType())
df.withColumn("region", map_udf(col("city")))方向六:SQL 写法与存储格式

存储格式与分区策略
python
# ── 文件格式:首选 Parquet / Delta Lake ──
# Parquet = 列式存储 + 高压缩 + 谓词下推
# Delta = Parquet + ACID + 版本管理 + Z-Order
# 写出 Parquet,按日期分区
df.write \
.mode("overwrite") \
.partitionBy("dt", "country") # 低基数列!
.option("compression", "snappy") \
.parquet("s3://bucket/orders/")
# 写出 Delta Lake
df.write \
.format("delta") \
.mode("overwrite") \
.partitionBy("dt") \
.save("s3://bucket/delta/orders/")
# Delta Lake 小文件合并(生产定期执行)
from delta.tables import DeltaTable
DeltaTable.forPath(spark, "s3://bucket/delta/orders/") \
.optimize() \
.executeZOrderBy("user_id") # Z-Order 加速多列过滤
# ── 控制写出文件大小 ──
# 目标:每个文件 128MB~512MB
total_size_mb = 50_000 # 数据总量 MB
target_file_mb = 256 # 目标文件大小
num_files = total_size_mb // target_file_mb # = 195
df.coalesce(num_files) \ # 不触发 Shuffle,适合减少文件数
.write.parquet("s3://...")
# ── 分区列选择原则 ──
# ✓ 低基数(dt/city/country)+ 常用过滤条件
# ✗ 高基数(user_id/order_id)→ 百万目录,小文件地狱
# ✗ 从不用于过滤的列 → 分区形同虚设调优决策流程
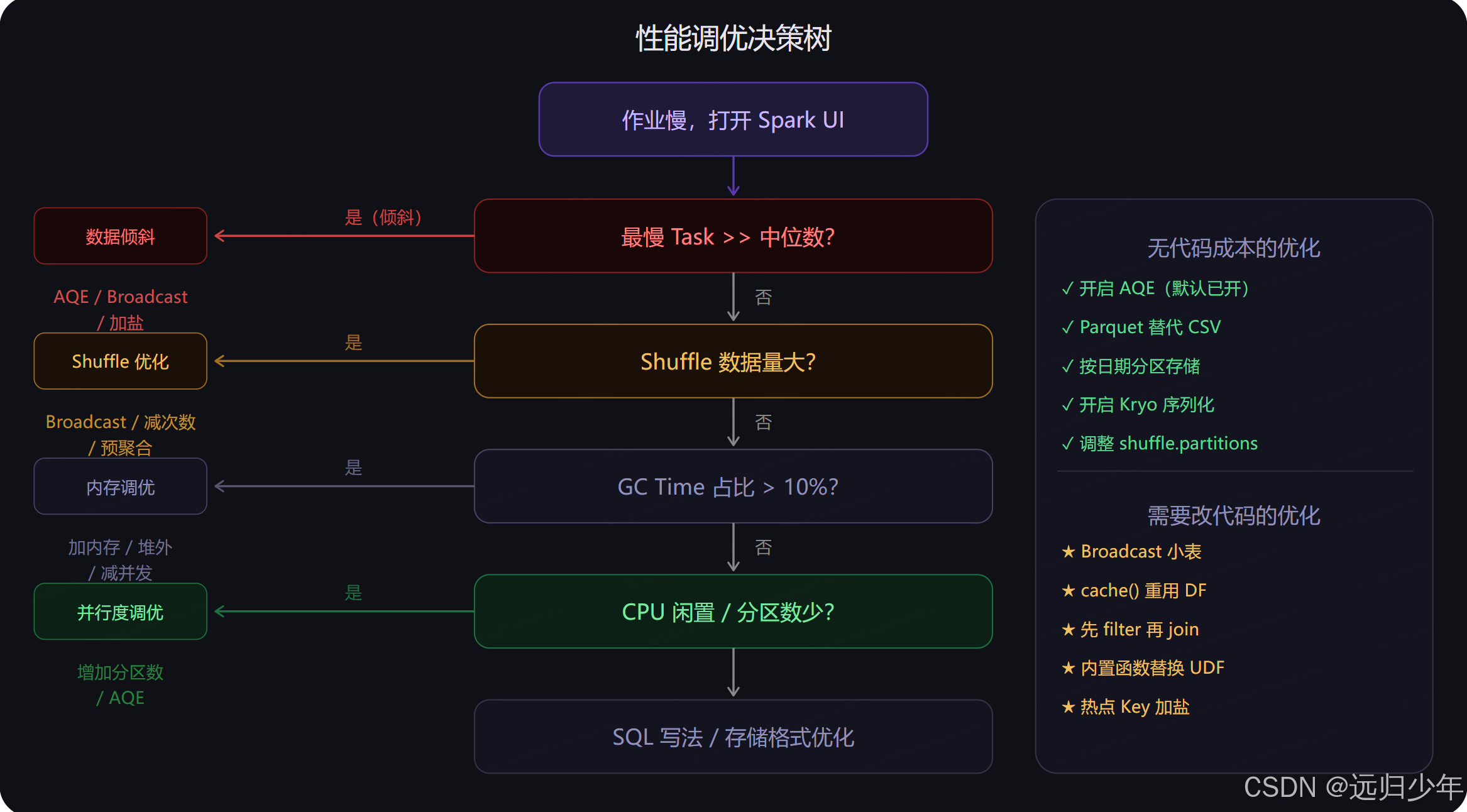
完整配置速查
python
spark = SparkSession.builder \
.appName("production_job") \
# ── 资源配置 ──
.config("spark.executor.memory", "8g") \
.config("spark.executor.cores", "4") \
.config("spark.executor.memoryOverhead", "2g") \
.config("spark.memory.offHeap.enabled", "true") \
.config("spark.memory.offHeap.size", "4g") \
.config("spark.memory.fraction", "0.6") \ # 统一内存占比
.config("spark.memory.storageFraction", "0.5") \ # 存储/执行内存初始比
# ── 动态资源分配 ──
.config("spark.dynamicAllocation.enabled", "true") \
.config("spark.dynamicAllocation.minExecutors","2") \
.config("spark.dynamicAllocation.maxExecutors","50") \
# ── 并行度 ──
.config("spark.sql.shuffle.partitions", "400") \ # 按数据量调整
.config("spark.default.parallelism", "400") \ # RDD 默认并行度
# ── Shuffle ──
.config("spark.shuffle.compress", "true") \
.config("spark.shuffle.spill.compress", "true") \
.config("spark.shuffle.file.buffer", "64k") \
.config("spark.reducer.maxSizeInFlight", "96m") \
.config("spark.shuffle.io.maxRetries", "10") \
# ── AQE(自适应查询)──
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.adaptive.coalescePartitions.enabled", "true") \
.config("spark.sql.adaptive.advisoryPartitionSizeInBytes", "128mb") \
.config("spark.sql.adaptive.skewJoin.enabled", "true") \
.config("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "5") \
.config("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", "256mb") \
# ── Join ──
.config("spark.sql.autoBroadcastJoinThreshold", "50mb") \ # 默认 10MB,适当调大
# ── 序列化 ──
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") \
.config("spark.kryo.registrationRequired", "false") \
# ── Tungsten / CodeGen ──
.config("spark.sql.codegen.wholeStage", "true") \ # 默认 true
.config("spark.sql.codegen.maxFields", "200") \ # 默认 100,宽表调大
.config("spark.sql.parquet.enableVectorizedReader", "true") \
.getOrCreate()总结
性能调优遵循三个优先级原则:
优先级一(效果最大):消除 Shuffle。能 Broadcast 就 Broadcast,能预聚合就不全量拉取,相同分区键操作合并执行。
优先级二(效果显著):解决数据倾斜。AQE 先开着,小表 Broadcast,两表都大时加盐,NULL Key 单独处理。
优先级三(效果稳定):资源与并行度。Executor 4~5 核、内存充足不 OOM、shuffle.partitions 匹配数据规模、AQE 自动合并兜底。
本章基于 Apache Spark 3.x / 4.x。AQE 在 Spark 3.0 后默认开启,是最低成本的优化手段,务必确认已启用。