python技术栈广度
- Web框架:熟练使用 Django(全功能)、Flask(轻量)、FastAPI(高性能异步)。
- 数据库:
- 关系型:MySQL、PostgreSQL(含索引优化、事务隔离。
- NoSQL:Redis(缓存)、MongoDB(文档存储)。
- 中间件与消息队列:RabbitMQ、Kafka、Celery。
- 容器化与编排:Docker、Kubernetes。
- DevOps工具链:CI/CD(GitHub Actions、Jenkins)、监控(Prometheus + Grafana)、日志(ELK)。
Web框架
Python Web 框架种类繁多,Django、Flask 和 FastAPI 是目前业界最主流且应用最广泛的三大框架 。根据功能定位与架构特性,主要可分为全栈框架、微框架及异步高性能框架三类。
主流全栈与微框架
- Django:高级全栈框架,遵循 MTV 模式,内置 ORM(全称Object Relational Mapping,中文名为对象关系映射)、后台管理及安全组件,适合快速开发大型复杂网站 。
- Flask:轻量级微框架,核心简单灵活,依赖插件扩展功能,适合中小型项目或微服务原型开发 。
- Bottle:单文件微框架,无外部依赖,极致轻量,适用于简单 API 或嵌入式应用 。
高性能与异步框架
- FastAPI:现代高性能框架,基于 Starlette 和 Pydantic,原生支持异步与自动 API 文档,适合构建高并发 API 服务 。
- Tornado:异步非阻塞框架,擅长处理长轮询与 WebSocket,适用于高并发实时应用场景 。
- Sanic:兼容 Flask 语法的异步框架,基于 asyncio,旨在提供极速的 HTTP 响应性能 。
其他特色框架
- Pyramid:扩展性强,适合中大型且需灵活设计的项目 。
- Falcon:专注于构建可靠、高性能的 REST API 与微服务 。
- Quart:Flask 的异步版本,支持 ASGI 标准,兼容 asyncio 。
- Robyn:结合 Rust 运行时的新兴框架,性能表现优异 。
数据库
基于 Python 的数据库主要分为两类:由 Python 实现的原生数据库 和 可通过 Python 连接操作的外部数据库。
由 Python 实现的原生数据库(轻量级/嵌入式)
这些数据库完全用 Python 编写,适合小型项目、原型开发或嵌入式场景:
- SQLite:Python 标准库自带,无需安装,单文件存储,零配置,适用于桌面应用、移动应用 。
- TinyDB:纯 Python 的 NoSQL 文档型数据库,数据以 JSON 文件存储,API 简单,适合小型项目 。
- PickleDB:基于 JSON 的键值存储,轻量易用,适合配置存储或临时数据 。
- ZODB (Zope Object Database):面向对象数据库,可直接持久化 Python 对象,支持事务和版本控制 。
- Shelve:Python 标准库,提供类似字典的键值存储,值可为任意可 pickle 对象 。
- DuckDB:高性能分析型列式存储数据库,支持 SQL,适合 OLAP 和数据分析,性能优于 SQLite 。
- Gadfly:纯 Python 实现的关系型 SQL 引擎,支持完整 SQL-92,适合教学或测试 。
- PyTables:基于 HDF5 的科学计算数据库,支持 TB 级数据存储,适用于高频交易、基因测序等 。
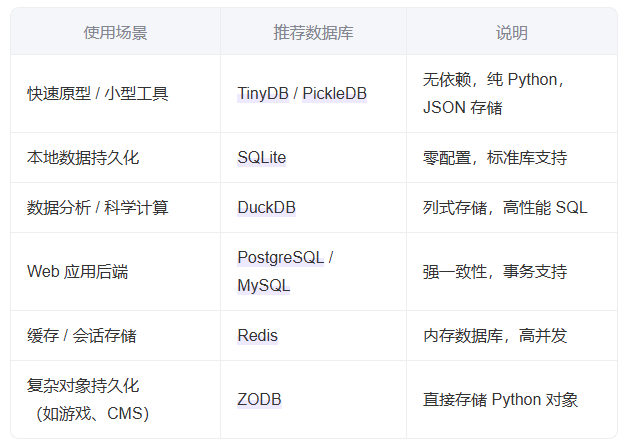
选择建议(按场景): - 小型项目 / 配置存储 → TinyDB 或 PickleDB
- 需要事务与复杂对象 → ZODB
- 数据分析 / OLAP → DuckDB
- 移动/桌面应用 → SQLite
可通过 Python 连接的主流外部数据库
Python 通过第三方库支持几乎所有主流数据库:
- 关系型数据库:
- MySQL:使用 pymysql 或 mysql-connector-python 。
- PostgreSQL:使用 psycopg2 。
- SQLite:使用内置 sqlite3 模块 。
- SQL Server:使用 pyodbc 或 pymssql 。
- NoSQL 数据库:(NoSQL数据库是一类非关系型数据库管理系统,其名称常被理解为"Not Only SQL"(不仅仅是SQL),旨在解决传统关系型数据库在处理大规模、高并发、非结构化或半结构化数据时的局限性。)
- MongoDB:使用 pymongo 。文档数据库:如MongoDB,数据以JSON或BSON等文档格式存储,文档内部可嵌套,适合内容管理系统和需要灵活数据模型的Web应用。
- Redis:使用 redis-py 。键值数据库:如Redis,通过简单的键(Key)来访问值(Value),适合高速缓存和会话存储等场景。
- 云数据库:
- 阿里云 RDS / 腾讯云 CynosDB:通过官方 SDK 或上述驱动连接 。
- ORM 框架(简化数据库操作):
- SQLAlchemy:通用 ORM,支持多种数据库 。
- Django ORM:集成于 Django 框架 。
快速选择
中间件与消息队列
在Python中,中间件和消息队列是实现分布式系统、微服务架构和异步通信的关键技术。中间件通常用于处理应用程序之间的通信、数据转换、协议转换等任务,而消息队列则用于在不同的应用程序或服务之间传递消息。以下是一些在Python生态系统中广泛使用的中间件和消息队列解决方案:
消息队列
- RabbitMQ是一个开源的消息队列系统,基于AMQP(高级消息队列协议)标准。它支持多种客户端库,包括Python。RabbitMQ具有高可靠性、灵活的路由、多种交换类型等特点。
安装:pip install pika
python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()- Apache Kafka是一个分布式流处理平台,主要用于处理高吞吐量的数据流。它支持多种编程语言,包括Python。Kafka适用于大规模数据流处理、日志收集和消息传递。
安装:pip install kafka-python
python
from kafka import KafkaProducer
import json
producer = KafkaProducer(bootstrap_servers='localhost:9092',
value_serializer=lambda m: json.dumps(m).encode('ascii'))
producer.send('my-topic', {'key': 'value'})
producer.flush()中间件
- Celery是一个分布式任务队列/作业队列,基于分布式消息传递。它支持任务调度、定期执行等特性,非常适合用于构建异步任务处理系统。
安装:pip install celeryredis
python
from celery import Celery
app = Celery('tasks', broker='redis://localhost:6379/0')
@app.task
def add(x, y):
return x + y- Apache Kafka Connect (用于Kafka)
虽然Kafka Connect本身不是一个中间件,但它是一个用于连接Kafka与外部系统的框架(如数据库、搜索引擎等)。它支持多种连接器,可以方便地与各种数据源和存储系统集成。
示例: 使用Kafka Connect连接JDBC数据库。
容器化与编排
容器化是指将 Python 应用及其依赖(如解释器、库、配置文件等)打包到一个轻量级、可移植的容器中,确保在任何环境中都能一致运行。
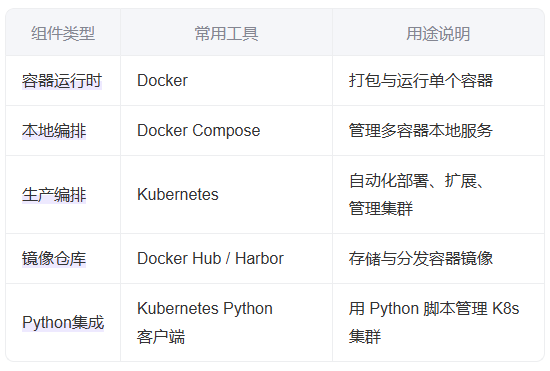
- 核心工具:Docker 是主流容器运行时。
- 关键文件:Dockerfile 定义镜像构建步骤。
- 典型优势:
- 环境隔离:避免"在我机器上能跑"的问题。
- 快速启动:秒级启动,适合微服务。
- 跨平台一致:开发、测试、生产环境行为一致。
编排是指自动化管理多个容器的部署、网络、扩展和监控,尤其在多服务或集群环境中至关重要。
- 核心目标:协调多个容器协同工作,实现高可用、弹性伸缩。
- 主流工具:
- Docker Compose:适用于单机多容器(如本地开发)。
- Kubernetes (K8s):生产级集群编排,支持自动扩缩容、服务发现等。
典型技术栈组合
DevOps工具链
DevOps工具链是指支持DevOps实践的一系列集成化工具的集合,覆盖软件开发生命周期(SDLC)的各个阶段,旨在实现自动化、协作和持续交付,从而提升软件交付的速度与质量。
核心定义
- DevOps工具链是一组紧密集成、协同工作的工具,用于支持开发(Development)与运维(Operations)之间的协作。
- 其目标是通过自动化减少人工干预,加快反馈循环,提高系统可靠性和部署频率 。
主要组成部分
DevOps工具链通常按软件交付流程划分为以下关键阶段,每个阶段对应特定类型的工具:
- 需求与计划管理
- 工具示例:Jira、Trello、Azure Boards
- 功能:跟踪需求、任务分配、优先级管理
- 版本控制(代码管理)
- 工具示例:Git、GitHub、GitLab、Azure Repos
- 功能:代码存储、协作开发、分支策略、代码审查
- 持续集成(CI)
- 工具示例:Jenkins、GitLab CI、GitHub Actions、Azure Pipelines
- 功能:自动构建、运行单元测试、代码质量检查(如SonarQube)
- 持续部署(CD)与自动化发布
- 工具示例:ArgoCD、Spinnaker、Ansible、Docker
- 功能:自动部署到不同环境(Dev/Test/Staging/Production),支持灰度发布
- 配置管理与基础设施即代码(IaC)
- 工具示例:Ansible、Puppet、Chef、Terraform
- 功能:自动化服务器配置、环境一致性保障
- 容器化与编排
- 工具示例:Docker、Kubernetes
- 功能:应用打包、弹性伸缩、高可用部署
- 监控与日志管理
- 工具示例:Prometheus、Grafana、Azure Monitor、Application Insights、ELK(ELK 是由 Elasticsearch、Logstash、Kibana 三个开源软件的组成的一个组合体,构建一个强大的、可扩展的日志分析平台,支持数据的快速检索、可视化和分析。)
- 功能:实时监控系统性能、用户行为、异常告警
- 测试自动化
- 工具示例:Selenium、JUnit、Xray(集成于Jira)
- 功能:功能测试、回归测试、端到端测试自动化
工具链类型
- 一体式(All-in-one)工具链
如:Azure DevOps完整堆栈
优点:开箱即用、集成度高、适合新手或快速启动项目
缺点:灵活性低,难以与现有第三方工具集成
- 可定制(Best-of-breed)工具链
如:Jira + GitHub + Jenkins + Kubernetes + Prometheus
优点:灵活、可按需选择最优工具、避免供应商锁定
缺点:需自行集成,管理复杂度较高